【ElasticSearch】突破深度分页限制的分页方案
一、场景需求
最近在忙一个新的项目,数据源是ES,但是功能就是对文档进行翻页查询
ES提供了分页查询,就是from + size深度查找,但是使用有限制,只能在1万条内
我和同事的意见是1万条之后的数据没有任何意义,就限制1万吧
但是后面内部测试后产品对这个方案是不满意的,既要又要
所以ES现有的几种分段查询是不满足了。。。
二、方案思路
老板提出了一个折中的方案,就是用 from,size + searchAfter来实现
分页和原来的正常分页不一样,不允许随机翻页,现在只有这些操作:
【总条数,总页数,当前页数,首页,上一页,下一页,尾页】
首页 : 正常查深度就行了对吧
下一页: 按照searchAfter的标记值查
上一页: 要拿到上两页的标记值才能查,但是没有上两页的,直接查首页
尾页: 按照searchAfter的排序字段倒序进行深度查询,计算最后一页的条数是多少,得到结果再逆序回来返回
上面就是讨论后知道的几个逻辑点。。。
随着方案落地,代码反复编写,我自己捋出来的结果是这样的:
其实 4个操作,【首页,上一页,下一页,尾页】
实际上变成6个操作 【首页,上一页,下一页, 尾页, 从尾页开始的上一页, 从尾页开始的下一页】
只是从界面上看不出后面两个的操作,我一直在纠结尾页的翻页是如何处理的...
然后我用实际列了一个例子就明白了
尾页向上一页跳转:
总条数:
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]
尾页查询结果:
[20, 19, 18, 17, 16, 15] -> [15, 16, 17, 18, 19, 20]
如果要查询上一页,就需要对应的标记
可以从上面的结果知道,对应的标记是15那条
[15(*), 16, 17, 18, 19, 20]
只要从当前页拿到标记就可以继续向下翻了
15(*) -> [14, 13, 12, 11, 10] -> [10, 11, 12, 13, 14]
尾页向下一页跳转:
那尾页的向下一页是怎样呢?就正好和首页的向上一页反了
向下两页拿到标记,就是下一页查询了,但是同样的,一页是尾页,就直接查询尾页了
思路总结:
到这里我就发现了,首页查询和尾页查询正好是一个对称关系
1、首页和尾页都需要一个游标来翻页,一个正序,一个反序
2、有6个查询状态
3、尾页、尾页上一页、尾页下一页、查询都是倒序的
三、技术实现
具体迭代的过程实在不能记住,这里贴代码来说吧
1、后端部分:
首先是SearchAfter接口的封装,下面是参数解释:
- tClass 索引对应的实体类
- capacity 容积,就是size大小
- BoolQueryBuilder,查询条件对象
- HighlightBuilder 高亮显示条件对象
- SortBuilders 排序条件对象集合,这个没想好就传入集合了, 其实这个方案只允许传入一个排序字段
- SearchAfterSetter 传入一个方法,告诉接口这个实体类是怎么放置标记值的
/**
* @author OnCloud9
* @date 2023/11/13 16:35
* @description searchAfter查询
* @params [tClass, capacity, saMarkArray, boolQueryBuilder, highlightBuilder, sortBuilders]
* @return java.util.List<Entity>
*/
<Entity> List<Entity> searchAfterQuery(
Class<Entity> tClass,
Integer capacity,
Object[] saMarkArray,
BoolQueryBuilder boolQueryBuilder,
HighlightBuilder highlightBuilder,
Collection<SortBuilder> sortBuilders,
BiFunction<Entity, Object[], Entity> searchAfterSetter
);
- from参数其实SearchAfter和FromSize可以混用,因为都是从0开始,首页,尾页,上一页下一页都是这样
- 判断SortValues是否传入, 传入了SortValues就会按照SearchAfter方式来查询
- 如果存在查询结果,就放入每一条记录的SortValues
/**
* @author OnCloud9
* @date 2023/11/13 17:04
* @description
* @params [tClass, capacity, saMarkArray, boolQueryBuilder, highlightBuilder, sortBuilders, searchAfterSetter]
* @return java.util.List<Entity>
*/
@Override
@SuppressWarnings("Duplicates")
public <Entity> List<Entity> searchAfterQuery(
Class<Entity> tClass,
Integer capacity,
Object[] saMarkArray,
BoolQueryBuilder boolQueryBuilder,
HighlightBuilder highlightBuilder,
Collection<SortBuilder> sortBuilders,
BiFunction<Entity, Object[], Entity> searchAfterSetter
) {
String indexName = getIndexName(tClass);
if (StringUtils.isBlank(indexName)) return Collections.emptyList();
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.from(0); /* 使用searchAfter必须指定from为0 */
searchSourceBuilder.size(Objects.isNull(capacity) ? 10 : capacity);
if (Objects.nonNull(highlightBuilder)) searchSourceBuilder.highlighter(highlightBuilder);
if (Objects.nonNull(boolQueryBuilder)) searchSourceBuilder.query(boolQueryBuilder);
if (CollectionUtils.isNotEmpty(sortBuilders)) sortBuilders.forEach(searchSourceBuilder::sort);
if (Objects.nonNull(saMarkArray) && saMarkArray.length > 0) searchSourceBuilder.searchAfter(saMarkArray); /* 根据排序顺序依次放置上一次的排序关键字段值 */
SearchRequest searchRequest = new SearchRequest(indexName);
searchRequest.searchType(SearchType.DFS_QUERY_THEN_FETCH);
searchRequest.preference("\"_primary_first\"");
SearchResponse searchResponse;
try (RestHighLevelClient restHighLevelClient = getEsClient()) {
searchRequest.source(searchSourceBuilder);
logger.info("query ES where... indexName = " + indexName + ":" + searchSourceBuilder.toString());
searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
if (Objects.isNull(searchResponse)) return Collections.emptyList();
} catch (Exception e) {
logger.error("查询ES数据信息失败", e);
return Collections.emptyList();
}
SearchHits searchHits = searchResponse.getHits();
SearchHit[] hits = searchHits.getHits();
List<Entity> entities = new ArrayList<>(hits.length);
for (SearchHit searchHit : searchHits.getHits()) {
Object[] sortValues = searchHit.getSortValues();
String recordJson = searchHit.getSourceAsString();
Entity t = JSON.parseObject(recordJson, tClass);
searchAfterSetter.apply(t, sortValues); /* 存放searchAfter值 */
entities.add(t);
}
return entities;
}
提供给业务的接口不关心翻页的实现细节,所以这里还需要再进行上一级的封装抽象
新增了几个参数:
- page就是翻页对象,虽然和正常翻页不一样,但是依然需要[当前页,每页条数]这几个参数
- pageFlag 翻页状态标记 [first, last, prev, next, last-prev, last-next]
- sortedField 指定一个SearchAfter排序的字段, 构建排序条件对象,交给内部处理
- sortOrder 指定正常查询的排序顺序
- comparator 指定比较方式,因为尾页翻页查询需要把结果反序回来,指定反序的逻辑实现
/**
* @author OnCloud9
* @date 2023/11/15 16:38
* @description
* @params [tClass, page, boolQueryBuilder, highlightBuilder, pageFlag, sortKey, comparator]
* @return com.baomidou.mybatisplus.core.metadata.IPage<Entity>
*/
<Entity> IPage<Entity> searchAfterPageQuery(
Class<Entity> tClass,
Page<Entity> page,
Object[] sortedValues,
BoolQueryBuilder boolQueryBuilder,
HighlightBuilder highlightBuilder,
String pageFlag,
String sortField,
SortOrder sortOrder,
Comparator<Entity> comparator,
BiFunction<Entity, Object[], Entity> searchAfterSetter
);
接口逻辑实现:
- 其实Page对象已经算好分页了,这里还是自己算一遍
- 尾页和尾页的翻页的区别在于,尾页一定需要知道最后一页的条数
- 首页和首页的翻页就简单了,闭着眼睛传参查就行了,searchAfter查询已经判断好了
/**
* @author OnCloud9
* @date 2023/11/15 16:39
* @description searchAfterPageQuery SearchAfter分页查询最终封装
* @params [tClass, page, boolQueryBuilder, highlightBuilder, pageFlag, sortKey, comparator]
* @return com.baomidou.mybatisplus.core.metadata.IPage<Entity>
*/
@Override
public <Entity> IPage<Entity> searchAfterPageQuery(
Class<Entity> tClass,
Page<Entity> page,
Object[] sortedValues,
BoolQueryBuilder boolQueryBuilder,
HighlightBuilder highlightBuilder,
String pageFlag,
String sortField,
SortOrder sortOrder,
Comparator<Entity> comparator,
BiFunction<Entity, Object[], Entity> searchAfterSetter
) {
Long pageTotal = 0L;
Long pageSize = page.getSize();
Long total = getCount(tClass, boolQueryBuilder);
List<SortBuilder> fieldSortBuildersX = Collections.singletonList(SortBuilders.fieldSort(sortField).order(sortOrder));
List<SortBuilder> fieldSortBuildersY = Collections.singletonList(SortBuilders.fieldSort(sortField).order(SortOrder.DESC.equals(sortOrder) ? SortOrder.ASC : SortOrder.DESC));
/* 总页数计算 */
boolean isRoundOut = total % pageSize == 0L;
pageTotal = total / pageSize;
if (!isRoundOut) pageTotal += 1L;
List<Entity> list = null;
switch (pageFlag) {
case "first":
case "prev":
case "next":
list = searchAfterQuery(tClass, pageSize.intValue(), sortedValues, boolQueryBuilder, highlightBuilder, fieldSortBuildersX, searchAfterSetter);
break;
case "last":
Long lastPageSize = isRoundOut ? pageSize : total - pageSize * (pageTotal - 1L);
list = searchAfterQuery(tClass, lastPageSize.intValue(), sortedValues, boolQueryBuilder, highlightBuilder, fieldSortBuildersY, searchAfterSetter);
list.sort(comparator);
break;
case "last-prev":
case "last-next":
list = searchAfterQuery(tClass, pageSize.intValue(), sortedValues, boolQueryBuilder, highlightBuilder, fieldSortBuildersY, searchAfterSetter);
list.sort(comparator);
break;
}
page.setRecords(list);
page.setPages(pageTotal);
page.setTotal(total);
return page;
}
业务调用案例:
@Resource
private IEsBaseService<ObuEtTrackDTO> esBaseService; @Override
public IPage<ObuEtTrackDTO> getEtcTrackPage(ObuEtTrackDTO dto) {
BoolQueryBuilder boolQueryBuilder = getCommonQueryBuilder(dto);
IPage<ObuEtTrackDTO> page = esBaseService.searchAfterPageQuery(
ObuEtTrackDTO.class,
dto.getPage(),
dto.getSortedValues(),
boolQueryBuilder,
null,
dto.getPagingFlag(),
"captureTime",
SortOrder.DESC,
(a, b) -> {
long timeA = a.getCaptureTime().getTime();
long timeB = b.getCaptureTime().getTime();
long diff = timeB - timeA;
if (diff == 0) return 0;
else if (diff > 0) return 1;
else return -1;
},
ObuEtTrackDTO::setSortedValues
);
page.getRecords().forEach(this::convert);
return page;
}
2、前端部分:
重点部分还是前端这里,前端组件要做的事情还挺多的...
EsPagination.vue
<template>
<div class="es-pagination">
<span class="page-total">共 {{ esPagination.total }} 条, {{ esPagination.pageTotal }} 页</span> <span class="page-select">
<el-select v-model="esPagination.pageSize" size="mini" style="width: 100px;" @change="whenPageSizeChange">
<el-option v-for="(val, idx) in pageSizes" :key="`pageSize${idx}`" :label="`${val}条/页`" :value="val" />
</el-select>
</span>
<span class="page-jump-bar">
<el-button size="mini" @click="toFirstPage">首页</el-button>
<el-button size="mini" :disabled="isFirstPage()" @click="toPrevPage">上一页</el-button>
<span class="page-current">第 {{ esPagination.pageCurrent }} 页</span>
<el-button size="mini" :disabled="isLastPage()" @click="toNextPage">下一页</el-button>
<el-button size="mini" @click="toLastPage">尾页</el-button>
</span>
</div>
</template> <script>
export default {
name: 'EsPagination',
props: {
/* 当前页数 */
pageCurrent: {
type: [String, Number],
required: false,
default: 1
},
/* 每页条数 */
pageSize: {
type: [String, Number],
required: false,
default: 10
},
/* 每页条数选项集合 */
pageSizes: {
type: Array,
required: false,
default: () => [10, 20, 30, 50, 100, 200]
},
/* 总条数 */
total: {
type: [String, Number],
required: false,
default: 0
}
},
data() {
return {
esPagination: {
pageCurrent: 1,
pageSize: 10,
pageTotal: 1,
pageCursorCache: [],
total: 0
}
}
},
watch: {
/**
* 监听total变化时重新计算总页数,因为框架原因不返回前端总页数
*/
total(val) {
this.esPagination.total = val
const isRoundOut = val % this.esPagination.pageSize === 0
this.esPagination.pageTotal = isRoundOut ? parseInt(val / this.esPagination.pageSize) : parseInt(val / this.esPagination.pageSize) + 1
},
/**
* 监听每页条数变化时重新计算总页数,因为框架原因不返回前端总页数
*/
pageSize(val) {
this.esPagination.pageSize = val
const isRoundOut = this.esPagination.total % val === 0
this.esPagination.pageTotal = isRoundOut ? parseInt(this.esPagination.total / val) : parseInt(this.esPagination.total / val) + 1
}
},
created() {
this.esPagination = {
pageCurrent: Number(this.pageCurrent),
pageSize: Number(this.pageSize),
pageTotal: 1,
pageCursorCache: [],
total: Number(this.total)
}
},
methods: {
/**
* 判断是否是第一页
*/
isFirstPage() {
return this.esPagination.pageCurrent === 1
},
/**
* 判断是否是最后一页
*/
isLastPage() {
return this.esPagination.pageCurrent === this.esPagination.pageTotal
},
/**
* 当页码调整时触发, 应该重新回到首页设置
*/
whenPageSizeChange(val) {
this.esPagination.pageCursorCache = []
this.$emit('size-change', [val, 1, 'first', []])
},
/**
* 首页跳转
* Flag标记:first
* 当前页: 1
* 游标缓存:无
*/
toFirstPage() {
this.esPagination.pageCurrent = 1
this.$emit('to-first', [1, 'first', []])
},
/**
* 上一页
* 跳转时,一定有首页或者尾页的游标存在
* 可以从游标缓存中知道是从首页还是尾页开始的
* @returns {ElMessageComponent}
*/
toPrevPage() {
if (this.isFirstPage()) return this.$message.error('已经是第一页了!')
const cursorCache = this.esPagination.pageCursorCache
const isFromFirst = cursorCache.some(cursor => cursor.pageFlag === 'first') /* 1、需要得知是从首页还是尾页出发的 */
let sortedValues = []
let pageFlag = ''
let pageCurrent = 0 if (isFromFirst) {
/* 首页的上一页有两种情况,一个是正常取上两页的游标缓存,一个是直接上一页到首页了 */
const cursorCurrent = this.esPagination.pageCurrent - 2
const hasPrev = cursorCurrent > 0
if (hasPrev) {
/* 上一页从游标缓存中提取searchAfter标记 */
const targetCursor = cursorCache.find(x => x.pageCurrent === cursorCurrent)
sortedValues = targetCursor.sortedValuesX /* 取尾游标 */
pageFlag = 'prev'
this.esPagination.pageCurrent -= 1
pageCurrent = this.esPagination.pageCurrent
} else {
/* 当向上翻页的游标标记越界时,直接调首页查询 */
this.esPagination.pageCursorCache = []
sortedValues = []
pageFlag = 'first'
this.esPagination.pageCurrent -= 1
pageCurrent = this.esPagination.pageCurrent
}
} else {
/* 尾页的向上一页,即去当前页的第一个记录的游标 */
const targetCurrent = this.esPagination.pageCurrent
const targetCursor = cursorCache.find(cursor => cursor.pageCurrent === targetCurrent)
sortedValues = targetCursor.sortedValuesY /* 取首游标 */ this.esPagination.pageCurrent -= 1
pageCurrent = this.esPagination.pageCurrent
pageFlag = 'last-prev'
} this.$emit('to-prev', [
pageCurrent,
pageFlag,
sortedValues
])
},
/**
* 下一页
* 跳转时,一定有首页或者尾页的游标存在
* 可以从游标缓存中知道是从首页还是尾页开始的
* @returns {ElMessageComponent}
*/
toNextPage() {
if (this.isLastPage()) return this.$message.error('已经是最后一页了!')
const cursorCache = this.esPagination.pageCursorCache
const isFromFirst = cursorCache.some(cursor => cursor.pageFlag === 'first') /* 1、需要得知是从首页还是尾页出发的 */
let sortedValues = []
let pageFlag = ''
let pageCurrent = 0 if (isFromFirst) {
/* 从首页出发的下一页,只需要获取当前页的游标, 如果到了尾页就是尾页,不需要额外处理 */
const targetCurrent = this.esPagination.pageCurrent
const targetCursor = cursorCache.find(cursor => cursor.pageCurrent === targetCurrent)
sortedValues = targetCursor.sortedValuesX /* 取尾游标 */ this.esPagination.pageCurrent += 1
pageCurrent = this.esPagination.pageCurrent
pageFlag = 'next'
} else {
/* 尾页的下一页有两种情况,一个是正常取上两页的游标缓存,一个是直接上一页到首页了 */
const cursorCurrent = this.esPagination.pageCurrent + 2
const hasNext = cursorCurrent < this.esPagination.pageTotal + 1
if (hasNext) {
/* 下一页从游标缓存中提取searchAfter标记 */
const targetCursor = cursorCache.find(x => x.pageCurrent === cursorCurrent)
sortedValues = targetCursor.sortedValuesY /* 取首游标 */
pageFlag = 'last-next'
this.esPagination.pageCurrent += 1
pageCurrent = this.esPagination.pageCurrent
} else {
/* 当向下翻页的游标标记越界时,直接调尾页查询 */
this.esPagination.pageCursorCache = []
sortedValues = []
pageFlag = 'last'
this.esPagination.pageCurrent += 1
pageCurrent = this.esPagination.pageCurrent
}
} this.$emit('to-next', [
pageCurrent,
pageFlag,
sortedValues
])
},
/**
* 尾页跳转
* Flag标记:last
* 当前页: 1
* 游标缓存:无
*/
toLastPage() {
this.esPagination.pageCursorCache = []
this.esPagination.pageCurrent = this.esPagination.pageTotal
console.log('尾页')
this.$emit('to-last', [this.esPagination.pageCurrent, 'last'])
},
/**
* 装载游标缓存
* @param tableData es表格集合
* @param pageFlag 查询状态位 [first, prev, next, last, last-prev, last-next]
*/
loadCursorCache(tableData, pageFlag) {
if (!tableData || tableData.length === 0) return
this.esPagination.pageCurrent = this.pageCurrent + 0
const pageCurrent = Number(this.esPagination.pageCurrent)
const sortedValuesX = tableData[tableData.length - 1].sortedValues
const sortedValuesY = tableData[0].sortedValues
const cursorCache = this.esPagination.pageCursorCache
const existCursor = cursorCache.find(x => x.pageCurrent === pageCurrent)
if (existCursor) return
this.esPagination.pageCursorCache.push({
pageCurrent,
pageFlag,
sortedValuesX,
sortedValuesY
})
}
}
}
</script> <style scoped>
.es-pagination {
float: right;
}
.es-pagination::after {
content: '';
height: 0;
clear: both;
}
.page-current,
.page-total {
color: #606266;
font-size: 14px;
}
.page-current { margin: 0 10px; } .page-select,
.page-jump-bar {
margin-left: 10px;
}
.el-button--default {
background: none;
border-radius: 0px;
color: rgba(255, 255, 255, 0.6);
border-color: rgba(255, 255, 255, 0.3) !important;
}
.el-button--default.is-disabled {
background: none;
}
</style>
组件给业务使用方法:
- 首先引用后,交代的参数信息
<es-pagination
:ref="esPaginationRef"
:page-current="page.current"
:page-size="page.size"
:total="page.total"
@size-change="sizeChange"
@to-first="toFirst"
@to-prev="toPrev"
@to-next="toNext"
@to-last="toLast"
/>
- data参数:
data() {
return {
esPaginationRef: 'esPaginationRefKey',
page: {
current: 1,
size: 10,
total: 0,
pageTotal: 1
},
queryForm: {
pagingFlag: '',
sortedValues: [],
// 其它查询条件 ....
}
}
}
钩子方法:
我感觉这里基本不用做啥,就是接参调用查询就行了哈哈哈
但是要注意一个,每次查询得到结果后让组件调用下标记装填方法
methods: {
sizeChange([size, current, flag, sortedValues]) {
this.queryForm.sortedValues = sortedValues
this.queryForm.pagingFlag = flag
this.page.current = current
this.page.size = size
this.getPageData()
},
toFirst([current, flag, sortedValues]) {
this.queryForm.sortedValues = sortedValues
this.queryForm.pagingFlag = flag
this.page.current = current
this.getPageData()
},
toPrev([current, flag, sortedValues]) {
this.queryForm.sortedValues = sortedValues
this.queryForm.pagingFlag = flag
this.page.current = current
this.getPageData()
},
toNext([current, flag, sortedValues]) {
this.queryForm.sortedValues = sortedValues
this.queryForm.pagingFlag = flag
this.page.current = current
this.getPageData()
},
toLast([current, flag, sortedValues]) {
this.queryForm.sortedValues = sortedValues
this.queryForm.pagingFlag = flag
this.page.current = current
this.getPageData()
},
async getPageData() {
this.loadingFlag = true
const postData = { ... this.queryForm, page: this.page }
const { data, total, pages } = await getEtcTrackPage(postData)
this.tableData = data
this.page.total = total
this.page.pageTotal = pages
this.$refs[this.esPaginationRef].loadCursorCache(data, this.queryForm.pagingFlag)
this.loadingFlag = false
}
}
3、效果预览:
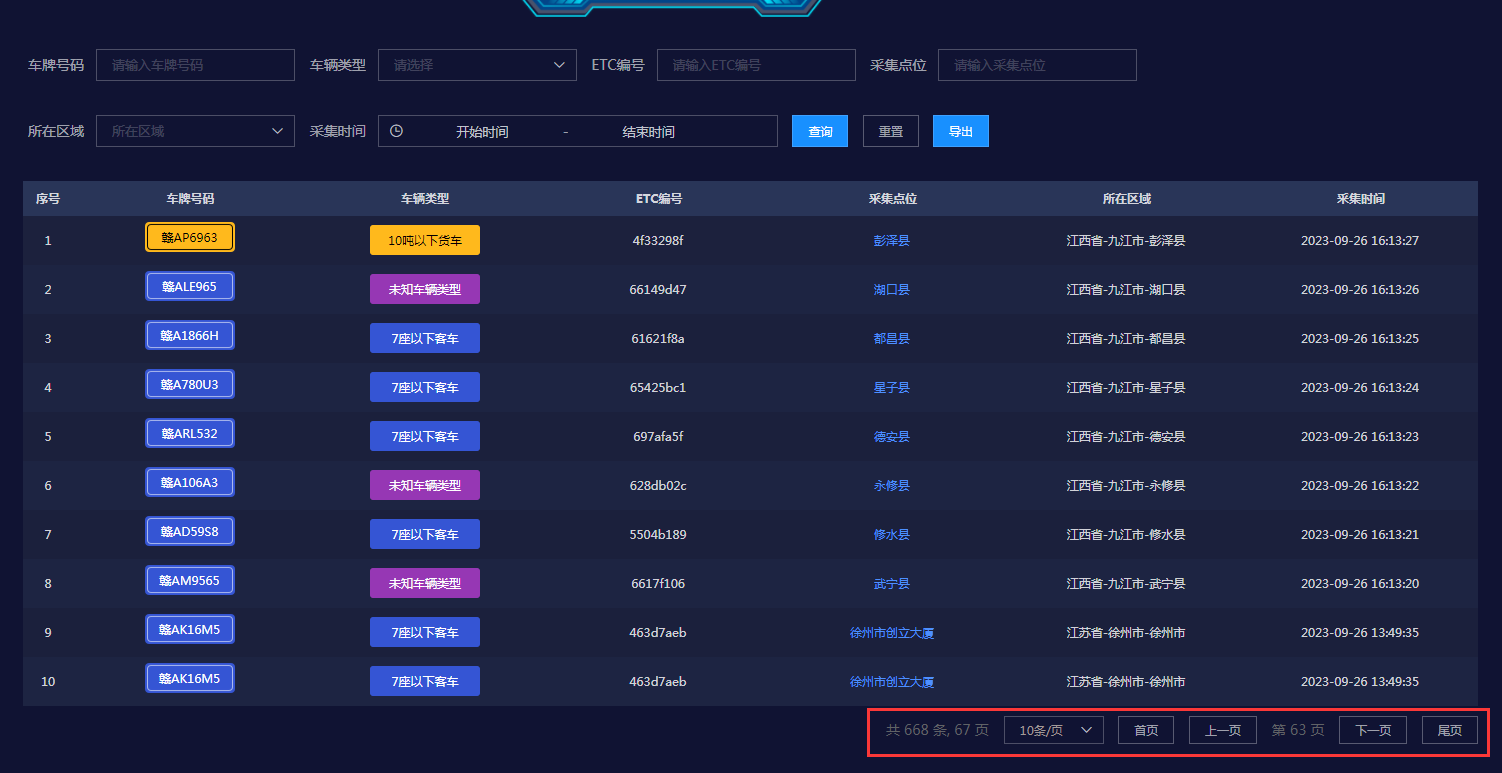
四、 使用限制:
1、只能但字段排序
目前没试过多个字段排序... 虽然接口开的方法是支持多个字段排序,实际上用起来只允许一个字段,不然searchAfter根本不准确
2、排序字段不是唯一
这将影响分页的查询结果,因为尾页使用反序排序时,重复记录顺序不固定
2023年11月17日16时36分更新:
前面跟同事讨论了下,说这个排序Comparator对象不需要传
意思是让我用反射读取字段的类型,自动创建Comparator对象实现
写起来挺麻烦的,能用,没报什么错...
/* 用反射自动推断排序对象 */
Comparator<Entity> reflectionComparator = EsComparatorUtil.createReflectionComparator(tClass, sortField, sortOrder);
代码量太多了,所以就单独写个工具类放了
引用类型的暂时想到这些,如果还要支持别的类型,再加就可以了
package cn.ymcd.perception.common; import cn.hutool.core.util.ReflectUtil;
import org.elasticsearch.search.sort.SortOrder; import java.lang.reflect.Field;
import java.math.BigDecimal;
import java.util.Arrays;
import java.util.Comparator;
import java.util.Date;
import java.util.List; /**
* @author OnCloud9
* @version 1.0
* @project road-perception-server
* @date 2023年11月16日 15:19
*/
public class EsComparatorUtil { private static final List<String> PrimitiveWrapperTypeList = Arrays.asList(
"Boolean",
"Byte",
"Character",
"Short",
"Integer",
"Long",
"Float",
"Double"
); /**
* @author OnCloud9
* @date 2023/11/16 13:52
* @description
* @params [tClass, sortField, sortOrder]
* @return java.util.Comparator<Entity>
*/
public static <Entity> Comparator<Entity> createReflectionComparator(Class<Entity> tClass, String sortField, SortOrder sortOrder) {
final Field field = ReflectUtil.getField(tClass, sortField);
field.setAccessible(true);
final Class<?> typeClass = field.getType();
final String typeName = typeClass.getSimpleName(); /* 类型名称 */
final boolean isPrimitive = typeClass.isPrimitive(); /* 是否原型类型 */
final boolean isAsc = SortOrder.ASC.equals(sortOrder); /* 判断排序顺序 */ if (isPrimitive || PrimitiveWrapperTypeList.contains(typeName)) {
return primitiveComparator(typeName, field, isAsc);
} else {
switch (typeName) {
case "BigDecimal":
return (a, b) -> {
try {
BigDecimal valA = (BigDecimal)field.get(a);
BigDecimal valB = (BigDecimal)field.get(b);
int compare = valA.compareTo(valB);
return isAsc ? compare : -compare;
} catch (IllegalAccessException e) {
e.printStackTrace();
return 0;
}
};
case "Date":
return (a, b) -> {
try {
Date valA = (Date)field.get(a);
Date valB = (Date)field.get(b);
int compare = Long.compare(valA.getTime(), valB.getTime());
return isAsc ? compare : -compare;
} catch (IllegalAccessException e) {
e.printStackTrace();
return 0;
}
};
case "String":
return (a, b) -> {
try {
Object valA = field.get(a);
Object valB = field.get(b);
int compare = valA.toString().compareTo(valB.toString());
return isAsc ? compare : -compare;
} catch (IllegalAccessException e) {
e.printStackTrace();
return 0;
}
};
default:
return getEntityDefaultComparator(field, isAsc);
}
}
} /**
* @author OnCloud9
* @date 2023/11/16 15:35
* @description 如果找不到类型,按默认排序执行,对象hash值排
* @params [field, isAsc]
* @return java.util.Comparator<Entity>
*/
private static <Entity> Comparator<Entity> getEntityDefaultComparator(Field field, boolean isAsc) {
return (a, b) -> {
try {
Object valA = field.get(a);
Object valB = field.get(b);
int A = valA.hashCode();
int B = valB.hashCode();
int compare = Integer.compare(A, B);
return isAsc ? compare : -compare;
} catch (IllegalAccessException e) {
e.printStackTrace();
}
return 0;
};
} private static <Entity> Comparator<Entity> primitiveComparator(String typeName, Field field, Boolean isAsc) {
switch (typeName) {
case "Boolean":
case "boolean":
return (a, b) -> {
try {
Boolean valA = field.getBoolean(a);
Boolean valB = field.getBoolean(b);
int compare = Boolean.compare(valA, valB);
return isAsc ? compare : -compare;
} catch (IllegalAccessException e) {
e.printStackTrace();
return 0;
}
};
case "Byte":
case "byte":
return (a, b) -> {
try {
Byte valA = field.getByte(a);
Byte valB = field.getByte(b);
int compare = Byte.compare(valA, valB);
return isAsc ? compare : -compare;
} catch (IllegalAccessException e) {
e.printStackTrace();
return 0;
}
};
case "Character":
case "char":
return (a, b) -> {
try {
Character valA = field.getChar(a);
Character valB = field.getChar(b);
int compare = Character.compare(valA, valB);
return isAsc ? compare : -compare;
} catch (IllegalAccessException e) {
e.printStackTrace();
return 0;
}
};
case "Short":
case "short":
return (a, b) -> {
try {
Short valA = field.getShort(a);
Short valB = field.getShort(b);
int compare = Short.compare(valA, valB);
return isAsc ? compare : -compare;
} catch (IllegalAccessException e) {
e.printStackTrace();
return 0;
}
};
case "Integer":
case "int":
return (a, b) -> {
try {
Integer valA = field.getInt(a);
Integer valB = field.getInt(b);
int compare = Integer.compare(valA, valB);
return isAsc ? compare : -compare;
} catch (IllegalAccessException e) {
e.printStackTrace();
return 0;
}
};
case "Long":
case "long":
return (a, b) -> {
try {
Long valA = field.getLong(a);
Long valB = field.getLong(b);
int compare = Long.compare(valA, valB);
return isAsc ? compare : -compare;
} catch (IllegalAccessException e) {
e.printStackTrace();
return 0;
}
};
case "Float":
case "float":
return (a, b) -> {
try {
Float valA = field.getFloat(a);
Float valB = field.getFloat(b);
int compare = Float.compare(valA, valB);
return isAsc ? compare : -compare;
} catch (IllegalAccessException e) {
e.printStackTrace();
return 0;
}
};
case "Double":
case "double":
return (a, b) -> {
try {
Double valA = field.getDouble(a);
Double valB = field.getDouble(b);
int compare = Double.compare(valA, valB);
return isAsc ? compare : -compare;
} catch (IllegalAccessException e) {
e.printStackTrace();
return 0;
}
};
default:
return getEntityDefaultComparator(field, isAsc);
}
}
}
【ElasticSearch】突破深度分页限制的分页方案的更多相关文章
- Elasticsearch from/size-浅分页查询-深分页 scroll-深分页search_after深度查询区别使用及应用场景
Elasticsearch调研深度查询 1.from/size 浅分页查询 一般的分页需求我们可以使用from和size的方式实现,但是这种的分页方式在深分页的场景下应该是避免使用的.深分页的页次增加 ...
- ElasticSearch 实现分词全文检索 - Scroll 深分页
目录 ElasticSearch 实现分词全文检索 - 概述 ElasticSearch 实现分词全文检索 - ES.Kibana.IK安装 ElasticSearch 实现分词全文检索 - Rest ...
- Linux分页机制之分页机制的演变--Linux内存管理(七)
1 页式管理 1.1 分段机制存在的问题 分段,是指将程序所需要的内存空间大小的虚拟空间,通过映射机制映射到某个物理地址空间(映射的操作由硬件完成).分段映射机制解决了之前操作系统存在的两个问题: 地 ...
- [转帖]Linux分页机制之分页机制的演变--Linux内存管理(七)
Linux分页机制之分页机制的演变--Linux内存管理(七) 2016年09月01日 20:01:31 JeanCheng 阅读数:4543 https://blog.csdn.net/gatiem ...
- pagebean pagetag java 后台代码实现分页 demo 前台标签分页 后台java分页
java 后台代码实现分页 demo 实力 自己写的 标签分页 package com.cszoc.sockstore.util; import java.util.HashMap;import ja ...
- 【jQuery 分页】jQuery分页功能的实现
自写的jQuery实现分页功能的分页组件: 功能效果如下: 分页组件就是上图中的三部分, 分别放在表格上部 和下部 . 其中, 1>>>页面的代码如下: product.jsp 其 ...
- 数据分页 THINKPHP3.2 分页 三种分页方法
数据分页 复制本页链接 opensns 通常在数据查询后都会对数据集进行分页操作,ThinkPHP也提供了分页类来对数据分页提供支持. 下面是数据分页的两种示例. 第一种:利用Page类和limit方 ...
- PHP实现分页:文本分页和数字分页
来源:http://www.ido321.com/1086.html 最近,在项目中要用到分页.分页功能是经常使用的一个功能,所以,对其以函数形式进行了封装. // 分页分装 /** * $pageT ...
- Jsp分页实例---真分页
网页的分页功能的实现比较简单,实现方法也多种多样. 今天总结一个简单的Jsp真分页实例. 首先,提到分页就要先明确一个概念,何为真分页何谓假分页. 假分页:一次性从数据库读出表的所有数据一次性的返回给 ...
- PHP实现仿Google分页效果的分页函数
本文实例讲述了PHP实现仿Google分页效果的分页函数.分享给大家供大家参考.具体如下: /** * 分页函数 * @param int $total 总页数 * @param int $pages ...
随机推荐
- java 中 pop 和 peek 方法区别
相同点:都返回栈顶的值. 不同点:peek 不改变栈的值(不删除栈顶的值),pop会把栈顶的值删除. 下面通过代码展现 /* * 文 件 名: TestPeekAndPopDiff.java */ i ...
- INFINI Labs 产品更新 | Easysearch 新增快照搜索功能,Console 支持 OpenSearch 存储
INFINI Labs 产品又更新啦~,包括 Easysearch v1.7.0.Console v1.13.0.本次各产品更新了 Easysearch 快照搜索功能:Console 支持 OpenS ...
- (二)requests-爬取国家药监局生产许可证数据
首先访问这个页面 url = 'http://125.35.6.84:81/xk/' 我们的目标是抓取这里的每一个企业的详情页数据,但是可以发现这里只有企业的简介信息,所以这就意味着我们要发送两次ge ...
- ObjectMapper Json字符串的转换处理
package com.example.demo; import com.example.pojo.User; import com.fasterxml.jackson.annotation.Json ...
- Apollo quick start SampleApp demo Java
<!--配置中心--> <dependency> <groupId>com.ctrip.framework.apollo</groupId> <a ...
- Task2 -- 关于Lecture3
Smiling & Weeping ---- 玲珑骰子安红豆, 入骨相思知不知. 1. 学习Git分支管理: Git分支是灵活开发的关键.创建.切换和合并分支是基础操作.使用如下命令: bas ...
- 解决git 区分文件名大小写
问题:两人协作开发同一分支时,由于一方将组件文件名小写开头,并且推送到远程分支,导致我每次拉取代码会将我本地文件名改成小写,并且我手动改成大写后推送到远端仓库,远端仓库文件名无变化,还是小写. 查证后 ...
- Linux信号量
查看信号量 [root@localhost ~]# kill -l 1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP 6) SIGABRT 7) ...
- Wireshark找不到接口
在管理员权限下的命令行窗口输入net start npf即可. 注意是管理员权限下的,否则会拒绝访问.
- hive第二课:Hive3.1.2分区与排序以及分桶(内置函数)
Hive3.1.2分区与排序(内置函数) 1.Hive分区(十分重要!!) 分区的目的:避免全表扫描,加快查询速度! 在大数据中,最常见的一种思想就是分治,我们可以把大的文件切割划分成一个个的小的文件 ...