Kafka-合理设置broker、partition、consumer数量
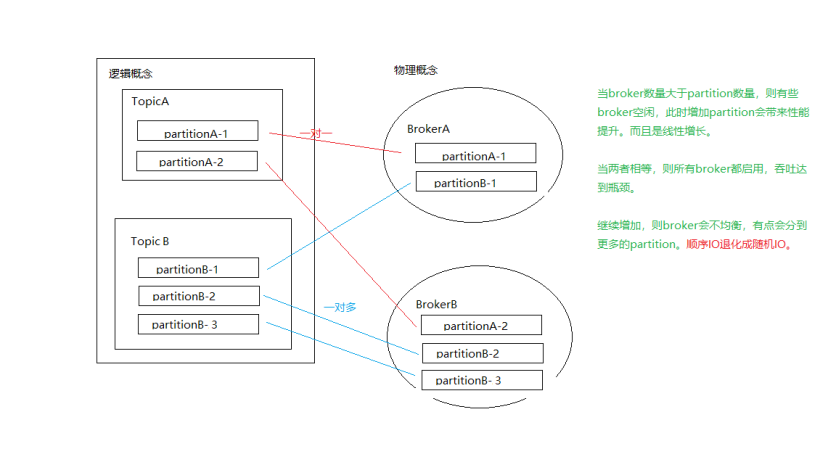
1.broker的数量最好大于等于partition数量
一个partition最好对应一个硬盘,这样能最大限度发挥顺序写的优势。
一个broker如果对应多个partition,需要随机分发,顺序IO会退化成随机IO。
实验条件:3个 Broker,1个 Topic,无Replication,异步模式,3个 Producer,消息 Payload 为100字节:
场景1:partition数量 < Broker个数
当 Partition 数量小于 Broker个数时,Partition 数量越大,吞吐率越高,且呈线性提升。
Kafka 会将所有 Partition 均匀分布到所有Broker 上,所以当只有2个 Partition 时,会有2个 Broker 为该 Topic 服务。
3个 Partition 时,同理会有3个 Broker 为该 Topic 服务。
场景2:partition数量 > Broker个数
当 Partition 数量多于 Broker 个数时,总吞吐量并未有所提升,甚至还有所下降。
可能的原因是,当 Partition 数量为4和5时,不同 Broker 上的 Partition 数量不同,而 Producer 会将数据均匀发送到各 Partition 上,这就造成各Broker 的负载不同,不能最大化集群吞吐量。
总结:
• 当broker数量大于partition数量,则有些broker空闲,此时增加partition会带来性能提升。而且是线性增长。
• 当两者相等,则所有broker都启用,吞吐达到瓶颈。
• 继续增加,则broker会不均衡,有点会分到更多的partition。
顺序IO退化成随机IO。
2.consumer数量最好和partition数量一致
场景1:consumer数量 < partition数量
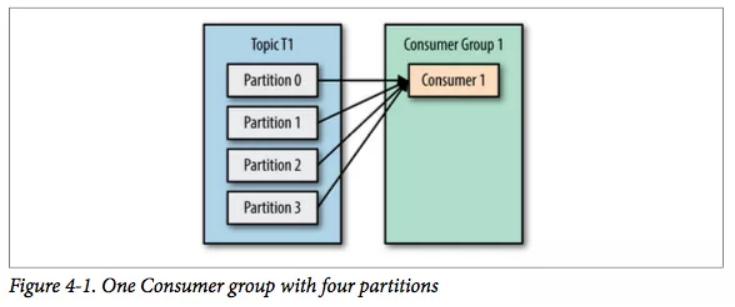
假设有一个 T1 主题,该主题有 4 个分区;同时我们有一个消费组 G1,这个消费组只有一个消费者 C1。
那么消费者 C1 将会收到这 4 个分区的消息。
如果我们增加新的消费者 C2 到消费组 G1,那么每个消费者将会分别收到两个分区的消息。
相当于 T1 Topic 内的 Partition 均分给了 G1 消费的所有消费者,在这里 C1 消费 P0 和 P2,C2 消费 P1 和 P3。
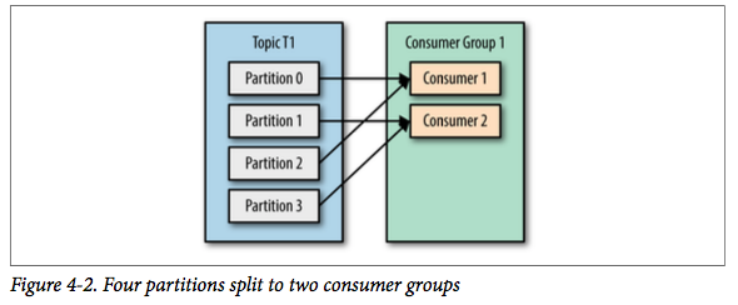
场景2:consumer数量 = partition数量
如果增加到 4 个消费者,那么每个消费者将会分别收到一个分区的消息。 这时候每个消费者都处理其中一个分区,满负载运行。

场景3:consumer数量 > partition数量
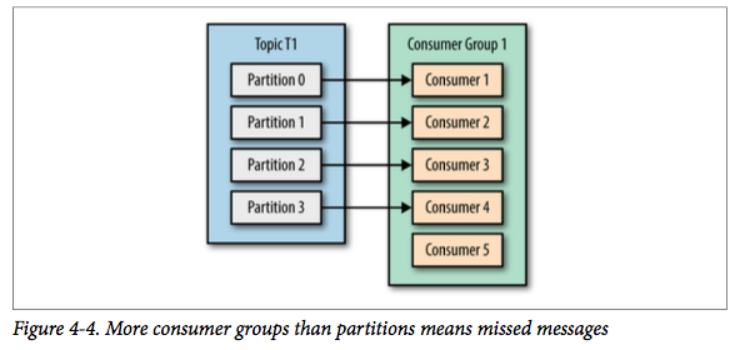
但如果我们继续增加消费者到这个消费组,剩余的消费者将会空闲,不会收到任何消息。
总而言之,我们可以通过增加消费组的消费者来进行水平扩展提升消费能力。
这也是为什么建议创建主题时使用比较多的分区数,这样可以在消费负载高的情况下增加消费者来提升性能。
另外,消费者的数量不应该比分区数多,因为多出来的消费者是空闲的,没有任何帮助。
如果我们的 C1 处理消息仍然还有瓶颈,我们如何优化和处理?
把 C1 内部的消息进行二次 sharding,开启多个 goroutine worker 进行消费,为了保障 offset 提交的正确性,需要使用 watermark 机制,保障最小的 offset 保存,才能往 Broker 提交。
保证顺序性,避免大的offest先提交,小的offest挂了,重启后会消息丢失。
解决:开一个协程专门提交offest,保证只提交最小的,重复消费代替消息丢失。
场景4:添加consumer group支持多个应用消费partition的数据
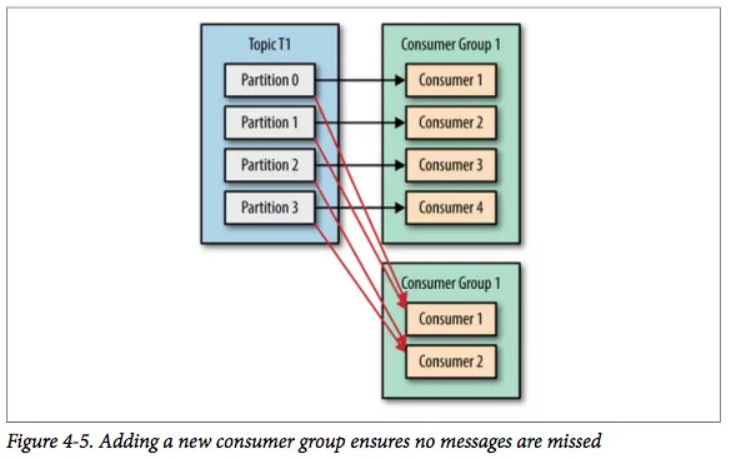
Kafka 一个很重要的特性就是,只需写入一次消息,可以支持任意多的应用读取这个消息。 换句话说,每个应用都可以读到全量的消息。为了使得每个应用都能读到全量消息,应用需要有不同的消费组。
对于上面的例子,假如我们新增了一个新的消费组 G2,而这个消费组有两个消费者如图。 在这个场景中,消费组 G1 和消费组 G2 都能收到 T1 主题的全量消息,在逻辑意义上来说它们属于不同的应用。
3.总结
如果应用需要读取全量消息,那么请为该应用设置一个消费组;如果该应用消费能力不足,那么可以考虑在这个消费组里增加消费者。
1)broker的数量最好大于等于partition数量
2)consumer数量最好和partition数量一致
Kafka-合理设置broker、partition、consumer数量的更多相关文章
- 【kafka学习笔记】合理安排broker、partition、consumer数量
broker的数量最好大于等于partition数量 一个partition最好对应一个硬盘,这样能最大限度发挥顺序写的优势. broker如果免得是多个partition,需要随机分发,顺序IO会退 ...
- kafka学习(四)-Topic & Partition
topic中partition存储分布 Topic在逻辑上可以被认为是一个queue.每条消费都必须指定它的topic,可以简单理解为必须指明把这条消息放进哪个queue里.为了使得 Kafka的吞吐 ...
- Kafka学习之broker配置(0.8.1版)(转)
broker.id 默认值:无 每一个broker都有一个唯一的id,这是一个非负整数,这个id就是broker的"名字",这样就允许broker迁移到别的机器而不会影响消费者. ...
- Kafka权威指南——broker的常用配置
前面章节中的例子,用来作为单个节点的服务器示例是足够的,但是如果想要把它应用到生产环境,就远远不够了.在Kafka中有很多参数可以控制它的运行和工作.大部分的选项都可以忽略直接使用默认值就好,遇到一些 ...
- Kafka的Topic、Partition和Message
Kafka的Topic和Partition Topic Topic是Kafka数据写入操作的基本单元,可以指定副本 一个Topic包含一个或多个Partition,建Topic的时候可以手动指定Par ...
- Kafka:Configured broker.id 2 doesn't match stored broker.id 0 in meta.properties.
在安装Kafka集群的时候,碰到这个问题. 我们知道在搭建Kafka集群的时候,我们需要设置broker.id,以作为当前服务器在整个集群的唯一标志. 网上搜查资料是说,log.dirs目录下的met ...
- kafka offset 设置
from kafka import KafkaConsumer from kafka import TopicPartition from kafka.structs import OffsetAnd ...
- Kafka 0.10.0.1 consumer get earliest partition offset from Kafka broker cluster - scala code
Return: Map[TopicPartition, Long] Code: val props = new Properties() props.put(ConsumerConfig.BOOTST ...
- [bigdata] kafka基本命令 -- 迁移topic partition到指定的broker
版本 0.9.2 创建topic bin/kafka-topics.sh --create --topic topic_name --partition 6 --replication-factor ...
- 【server.properties】kafka服务设置
每个kafka broker中配置文件server.properties默认必须配置的属性如下: broker.id=0 num.network.threads=2 num.io.threads=8 ...
随机推荐
- docker查看日志:docker service logs 与 docker container logs
转载请注明出处: docker service logs 和 docker container logs 是两个不同的命令,用于查看 Docker 服务和容器的日志.以下是它们之间的区别: 1.doc ...
- idea 配置 service 服务,多模块同时启动
转载请注明出处: 1,打开IDEA项目 .idea 下 的workspace.xml 2,查找"RunDashboard" 节点 3,添加如下内容 <option name= ...
- 基于html+javascript开发的base64解码工具
base64在线解码工具可以帮助你将Base64编码的字符串解码为原始的文本或数据. 预览入口 以下是一个简单的base64在线解码工具的示例: html <!DOCTYPE html> ...
- 【MicroPython】生成模块表py\objmodule.c中结构mp_rom_map_elem_t - py\makemoduledefs.py
查找文件中的模块注册标记MP_REGISTER_MODULE pattern = re.compile(r"[\n;]\s*MP_REGISTER_MODULE\((.*?),\s*(.*? ...
- 【TouchGFX】visua studio 自定义路径宏
很好奇 touchgfx 的 visual studio 工程文件中路径符号 $(TouchGFXReleasePath)是哪里定义的,经查这就是一个宏替换 自定义宏方式
- Jquery - 获取所有子节点 ( 并删除 )
1,获取所有子节点 $(".parent").find('.child') 2,获取所有子节点,通过上层 div 的类名 , 获取上层 div 节点 $(".pare ...
- [转帖]crontab 定时任务,免交互式编写任务文件
https://www.jianshu.com/p/8eab68bcfc8e 正常添加定时任务是在命令行使用命令 crontab -ecrontab -e编写完的文件怎么找到?文件默认保存在/var/ ...
- [转帖]手摸手搭建简单的jmeter+influxdb+grafana性能监控平台
我安装的机器是阿里云的centos8机器,其他的系统暂未验证 1.安装influxdb influxdb 下载地址https://portal.influxdata.com/downloads/,也可 ...
- [转帖]Jmeter学习笔记(六)——使用badboy录制脚本
https://www.cnblogs.com/pachongshangdexuebi/p/11506274.html 1.下载安装 可以去badboy官网下载地址:http://www.badboy ...
- [转帖]3.3.7. 自动诊断和建议报告SYS_KDDM
https://help.kingbase.com.cn/v8/perfor/performance-optimization/performance-optimization-6.html#sys- ...