Hadoop面试题总结(二)——HDFS
1、 HDFS 中的 block 默认保存几份?
默认保存3份
2、HDFS 默认 BlockSize 是多大?
默认64MB
3、负责HDFS数据存储的是哪一部分?
DataNode负责数据存储
4、SecondaryNameNode的目的是什么?
他的目的使帮助NameNode合并编辑日志,减少NameNode 启动时间
5、文件大小设置,增大有什么影响?
HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M。
思考:为什么块的大小不能设置的太小,也不能设置的太大?
HDFS的块比磁盘的块大,其目的是为了最小化寻址开销。如果块设置得足够大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。
因而,传输一个由多个块组成的文件的时间取决于磁盘传输速率。
如果寻址时间约为10ms,而传输速率为100MB/s,为了使寻址时间仅占传输时间的1%,我们要将块大小设置约为100MB。默认的块大小128MB。
块的大小:10ms×100×100M/s = 100M,如图
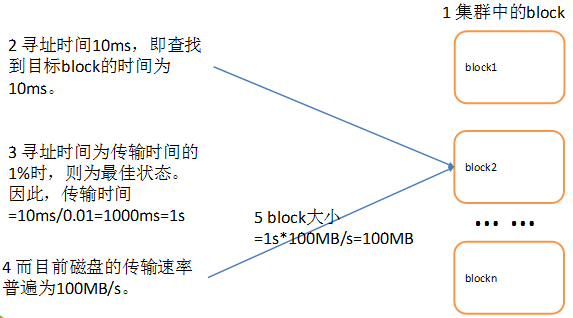
增加文件块大小,需要增加磁盘的传输速率。
6、hadoop的块大小,从哪个版本开始是128M
Hadoop1.x都是64M,hadoop2.x开始都是128M。
7、HDFS的存储机制(☆☆☆☆☆)
HDFS存储机制,包括HDFS的写入数据过程和读取数据过程两部分
HDFS写数据过程
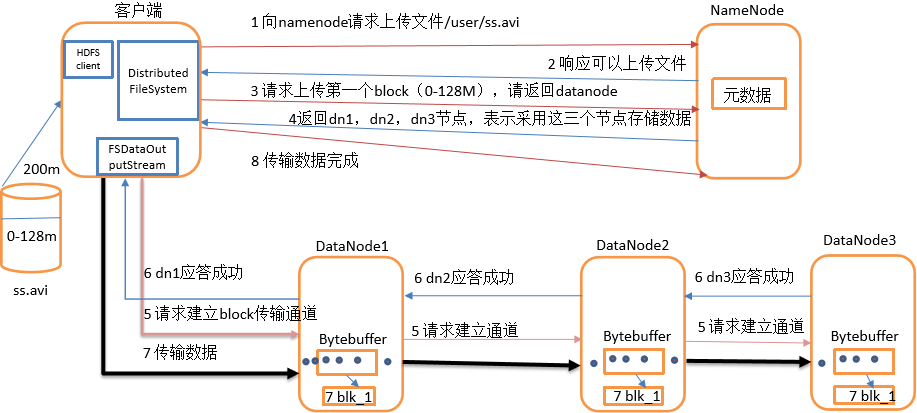
1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
2)NameNode返回是否可以上传。
3)客户端请求第一个 block上传到哪几个datanode服务器上。
4)NameNode返回3个datanode节点,分别为dn1、dn2、dn3。
5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
6)dn1、dn2、dn3逐级应答客户端。
7)客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;
dn1每传一个packet会放入一个应答队列等待应答。
8)当一个block传输完成之后,客户端再次请求NameNode上传第二个block的服务器。(重复执行3-7步)。
HDFS读数据过程
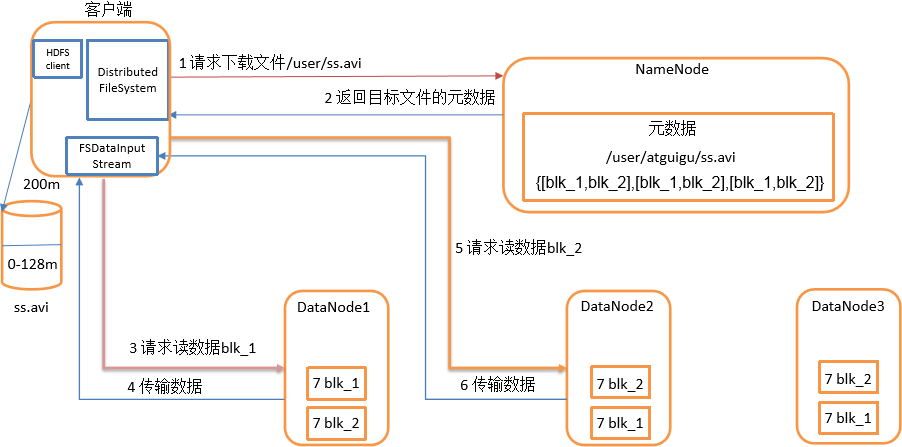
1)客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以packet为单位来做校验)。
4)客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
8、secondary namenode工作机制(☆☆☆☆☆)
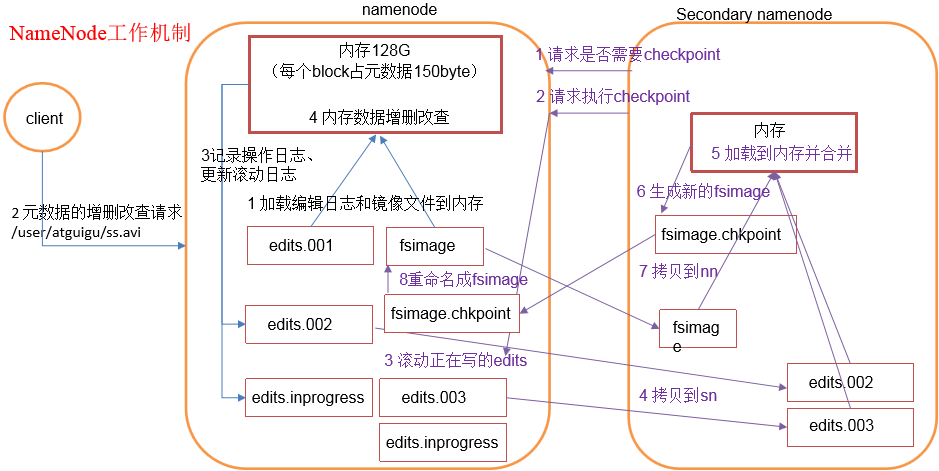
1)第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建fsimage和edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对数据进行增删改查。
2)第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要checkpoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行checkpoint。
(3)NameNode滚动正在写的edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。
9、NameNode与SecondaryNameNode 的区别与联系?(☆☆☆☆☆)
机制流程看第7题
1)区别
(1)NameNode负责管理整个文件系统的元数据,以及每一个路径(文件)所对应的数据块信息。
(2)SecondaryNameNode主要用于定期合并命名空间镜像和命名空间镜像的编辑日志。
2)联系:
(1)SecondaryNameNode中保存了一份和namenode一致的镜像文件(fsimage)和编辑日志(edits)。
(2)在主namenode发生故障时(假设没有及时备份数据),可以从SecondaryNameNode恢复数据。
10、HDFS组成架构(☆☆☆☆☆)
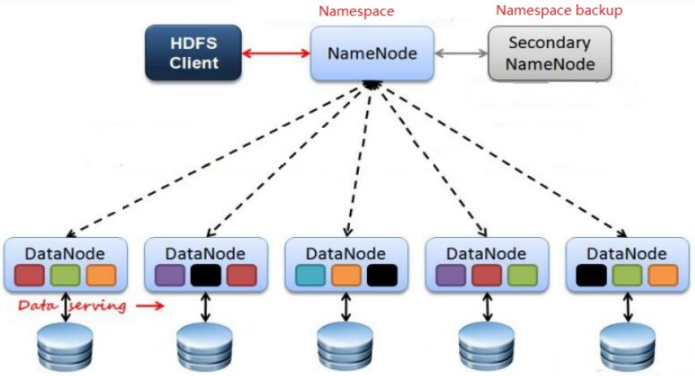
架构主要由四个部分组成,分别为HDFS Client、NameNode、DataNode和Secondary NameNode。下面我们分别介绍这四个组成部分。
1)Client:就是客户端。
(1)文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行存储;
(2)与NameNode交互,获取文件的位置信息;
(3)与DataNode交互,读取或者写入数据;
(4)Client提供一些命令来管理HDFS,比如启动或者关闭HDFS;
(5)Client可以通过一些命令来访问HDFS;
2)NameNode:就是Master,它是一个主管、管理者。
(1)管理HDFS的名称空间;
(2)管理数据块(Block)映射信息;
(3)配置副本策略;
(4)处理客户端读写请求。
3)DataNode:就是Slave。NameNode下达命令,DataNode执行实际的操作。
(1)存储实际的数据块;
(2)执行数据块的读/写操作。
4)Secondary NameNode:并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
(1)辅助NameNode,分担其工作量;
(2)定期合并Fsimage和Edits,并推送给NameNode;
(3)在紧急情况下,可辅助恢复NameNode。
11、HAnamenode 是如何工作的? (☆☆☆☆☆)
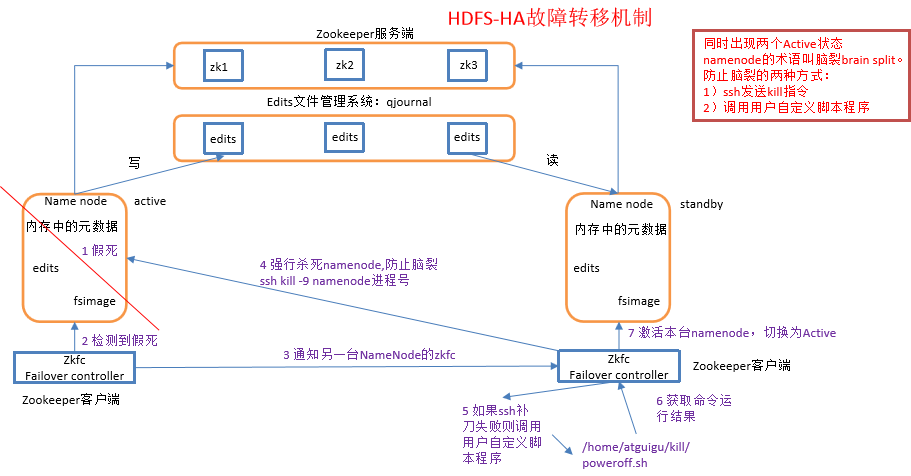
ZKFailoverController主要职责
1)健康监测:周期性的向它监控的NN发送健康探测命令,从而来确定某个NameNode是否处于健康状态,如果机器宕机,心跳失败,那么zkfc就会标记它处于一个不健康的状态。
2)会话管理:如果NN是健康的,zkfc就会在zookeeper中保持一个打开的会话,如果NameNode同时还是Active状态的,那么zkfc还会在Zookeeper中占有一个类型为短暂类型的znode,当这个NN挂掉时,这个znode将会被删除,然后备用的NN,将会得到这把锁,升级为主NN,同时标记状态为Active。
3)当宕机的NN新启动时,它会再次注册zookeper,发现已经有znode锁了,便会自动变为Standby状态,如此往复循环,保证高可靠,需要注意,目前仅仅支持最多配置2个NN。
4)master选举:如上所述,通过在zookeeper中维持一个短暂类型的znode,来实现抢占式的锁机制,从而判断那个NameNode为Active状态
Hadoop面试题总结(二)——HDFS的更多相关文章
- Hadoop学习之旅二:HDFS
本文基于Hadoop1.X 概述 分布式文件系统主要用来解决如下几个问题: 读写大文件 加速运算 对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整 ...
- hadoop(二):hdfs HA原理及安装
早期的hadoop版本,NN是HDFS集群的单点故障点,每一个集群只有一个NN,如果这个机器或进程不可用,整个集群就无法使用.为了解决这个问题,出现了一堆针对HDFS HA的解决方案(如:Linux ...
- 【Todo】找出共同好友 & Spark & Hadoop面试题
找了这篇文章看了一下面试题<Spark 和hadoop的一些面试题(准备)> http://blog.csdn.net/qiezikuaichuan/article/details/515 ...
- Spark面试题(二)
首发于我的个人博客:Spark面试题(二) 1.Spark有哪两种算子? Transformation(转化)算子和Action(执行)算子. 2.Spark有哪些聚合类的算子,我们应该尽量避免什么类 ...
- Hadoop阅读笔记(二)——利用MapReduce求平均数和去重
前言:圣诞节来了,我怎么能虚度光阴呢?!依稀记得,那一年,大家互赠贺卡,短短几行字,字字融化在心里:那一年,大家在水果市场,寻找那些最能代表自己心意的苹果香蕉梨,摸着冰冷的水果外皮,内心早已滚烫.这一 ...
- Hadoop 面试题之Hbase
Hadoop 面试题之九 16.Hbase 的rowkey 怎么创建比较好?列族怎么创建比较好? 答: 19.Hbase 内部是什么机制? 答: 73.hbase 写数据的原理是什么? 答: 75.h ...
- hadoop面试题答案
Hadoop 面试题,看看书找答案,看看你能答对多少(2) 1. 下面哪个程序负责 HDFS 数据存储.a)NameNode b)Jobtracker c)Datanode d)secondary ...
- Apache Hadoop 2.9.2 的HDFS High Available模式部署
Apache Hadoop 2.9.2 的HDFS High Available 模式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们知道,当NameNode进程挂掉后,可 ...
- Hadoop生态集群之HDFS
一.HDFS是什么 HDFS是hadoop集群中的一个分布式的我文件存储系统.他将多台集群组建成一个集群,进行海量数据的存储.为超大数据集的应用处理带来了很多便利. 和其他的分布式文件存储系统相比他有 ...
- Hadoop开发第6期---HDFS的shell操作
一.HDFS的shell命令简介 我们都知道HDFS 是存取数据的分布式文件系统,那么对HDFS 的操作,就是文件系统的基本操作,比如文件的创建.修改.删除.修改权限等,文件夹的创建.删除.重命名等. ...
随机推荐
- (Good topic)单词的压缩编码(leetcode3.28每日打卡)
给定一个单词列表,我们将这个列表编码成一个索引字符串 S 与一个索引列表 A. 例如,如果这个列表是 ["time", "me", "bell&quo ...
- 递归+记忆化递归+DP:斐波那契数列
递归:算法复杂度O(2^N) 1 int fib(int n) 2 { 3 if (n == 0) 4 { 5 return 0; 6 } 7 if (n == 1) 8 { 9 return 1; ...
- 【Javaweb】Servlet六 | HttpServletRequest类的含义及其使用方法【详解】
HttpServletRequest类的作用 每次只要有请求进入Tomcat服务器,Tomcat服务器就会把请求过来的Http协议信息解析好封装到Request对象中.然后传递到Service方法(d ...
- UNCTF-Crypto wp
2020年 easy_rsa 题目 from Crypto.Util import number import gmpy2 from Crypto.Util.number import bytes_t ...
- STM32外设:专用定时器 IWDG、WWDG、RTC
主要外设: IWDG:Independent Watch DoG 独立看门狗 WWDG:Window Watch DoG 窗口看门狗 RTC: Real-Time Clock 实时时钟 IWDG 主要 ...
- 【总结】IntelliJ IDEA 插件
1..iBATIS/MyBatis plugin轻松通过快捷键找到MyBatis中对应的Mapper和XML,CTRL+ALT+B 2.iBATIS/MyBatis plugin轻松通过快捷键找到My ...
- C# 获取系统DPI缩放比例以及分辨率大小
一般方法 System.Windows.Forms.Screen类 // 获取当前主屏幕分辨率 int screenWidth = Screen.PrimaryScreen.Bounds.Width; ...
- Excel对比两张表的某一列,匹配上则进行数据copy
VLOOKUP(参数1,参数2,参数3,参数4) 参数1: 查找值 参数2:指定查找数据源的范围 参数3:返回查找区域的第几列数据 参数4:精确查找输入参数"0"or"f ...
- 2023年国家基地“楚慧杯”网络安全实践能力竞赛初赛-Crypto+Misc WP
Misc ez_zip 题目 4096个压缩包套娃 我的解答: 写个脚本直接解压即可: import zipfile name = '附件路径\\题目附件.zip' for i in range(40 ...
- 从Redis读取.NET Core配置
在本文中,我们将创建一个自定义的.NET Core应用配置源和提供程序,用于从Redis中读取配置.在此之前,您需要稍微了解一些.NET Core配置提供程序的工作原理,相关的内容可以在Microso ...