Hologres如何支持亿级用户UV计算
背景介绍
在用户行为分析和圈人场景中,经常需要从亿级甚至十亿级用户中快速筛选出符合特定标签的用户统计,很多企业会使用Apache Kylin(下文简称Kylin)来支持这样的场景。但是Apache Kylin的核心是预计算,当遇上设计不合理的Cube,或者需求维度多的场景时,会遇到维度爆炸,Cube构建时间长,SQL函数不支持等问题。
本文将介绍阿里云Hologres如何基于RoaringBitmap进行UV等高复杂度计算的方案,实现亿级用户万级标签亚秒级分析,帮助用户从Kylin平滑迁移到Hologres,实现更实时、开发更灵活、功能更完善的多维分析能力。
Apache Kylin与Hologres的对比
|
对比项 |
Apache Kylin |
Hologres |
差异点 |
|
定位 |
MOLAP on Hadoop |
Real-Time MPP Data Warehouse |
- |
|
建模方式 |
星型、雪花模型 |
宽表模型、主题模型 |
Hologres无需复杂建模理论和建模过程,数据导入即可查 |
|
核心原理 |
空间换时间,减少运行时计算,预计算Cube,依赖Hadoop |
并行计算、列存、向量化,充分利用多节点,多核计算资源 |
Hologres没有存储爆炸问题,无需预构建等待 |
|
运维方式 |
依赖YARN,HBase,ZK等,外部依赖多 |
计算存储分离,弹性伸缩,升级平滑,无外部依赖 |
Hologres托管式运维,运维简单,无需Hadoop技能 |
|
使用场景 |
固定报表,固定维度组合,固定指标服务,秒级响应 |
敏捷自助报表、自助式分析、探索式分析、自助取数、在线数据服务,秒级响应 |
Hologres分析更敏捷,无限制,支持完善的SQL Join,嵌套查询,窗口函数等 |
|
查询接口 |
自定义JDBC,ODBC,有限SQL能力 |
兼容PostgreSQL,标准JDBC、ODBC,支持标准SQL |
Hologres兼容开源生态,SQL标准 |
|
开发效率 |
依赖于建模人员的熟练度,掌握Kylin的复杂建模技巧 |
针对“表”设计,概念简单 |
Hologres上手容易,学习门槛低 |
|
数据时效性 |
T+1,加工流程长,数据修正慢,模型修改成本非常高 |
实时,写入即可查,数据可更新,模型可变更 |
Hologres T+0,全实时 |
使用Hologres方案的收益:实时、灵活、简单
基于上述的比较,我们看到Kylin和Hologres拥有一些共同的场景:海量数据交互式分析、亚秒级响应、横向扩展能力。Kylin有很多优点,包括:最小化查询开销,以点查的性能完成多维分析,查询性能更稳定,利用Bitmap支持全局精确去重。同时也发现了一些Kylin的使用难点,包括:建模复杂(主要由IT团队负责建模),Cube膨胀(存储成本高),构建Cube时间长(业务不实时,构建任务资源消耗大),模型不可变(业务不敏捷),SQL支持能力弱(固定的Join连接条件、有限的SUM COUNT算子,BI兼容度低,SQL协议不标准),可扩展能力弱(UDF少)。
迁移到Hologres之后,可以获得的收益包括:建模简单(面向表,DWD&DWS),SQL能力强(兼容PostgreSQL11,支持Ad-Hoc Query),数据链路实时(写入即可见),运维简单(无Hadoop依赖)
如何从Kylin迁移到Hologres
- 架构调整:从Hadoop/HBase架构,调整到MPP数据仓库Hologres,去Hadoop,ZK等依赖
- 建模上:从面向指标的多维建模,调整为面向表的DWD、DWS分层建模,DWD为主,性能敏感时补充DWS甚至ADS,关注Query SLA,避免超大Query,通过基础聚合结果集作为轻量汇总的DWS,满足95%场景。
- 学习上:学习Cube优化技巧到学习Hologres索引设计、查询优化、资源监控
- 存储上:从单一的HBase存储,到冷热数据分层存储(Hologres+MaxCompute)
- 场景上:通过Hologres提供更敏捷、更灵活的自助式分析,加速数据产品创新
- 分工上:IT从关注建模的构建质量到关注平台的开发效率,更多服务业务价值
实现原理
在场景迁移之前,首先介绍以下精确去重和累加计算在Kylin和Hologres上不同的实现方式,以便于根据不同场景选用不同的方式去迁移原有业务。
如下图所示,Kylin根据维度和度量,进行多次预计算生成2^n个cuboid(n为维度数量)来构建cube。查询时,根据查询的维度,映射到相应的cuboid得到度量结果。Cube相比原始明细数据会有N倍的数据膨胀,且非常不灵活。
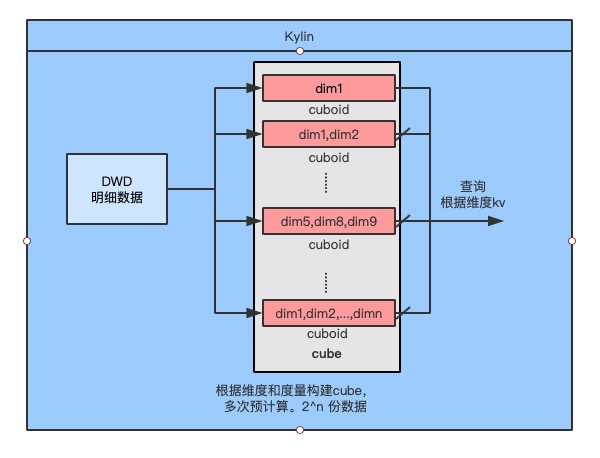
图1 Kylin精确去重和累加计算实现
对于Hologres来说,去做精确去重和累加计算则更为灵活:
- 明细数据不多或者QPS要求不高的场景:直接利用SQL语句从明细表中对统计维度进行Group by,对指标用聚合函数计算度量结果。这种方法可以获得最大的灵活性,能充分利用Hologres强大的计算能力,可进行任意复杂的查询,实现数亿条记录的毫秒级分析。
- 数据量大且高QPS场景:在Hologres中将明细表按照基础维度最细粒度做Group by,对指标进行预聚合运算生成一份DWS表。查询时对DWS表按照统计维度Group by,对指标的预聚合结果进行聚合计算即可。通过DWS层,极大的减少数据量,从而实现高QPS的查询要求。相比于DWD(明细层),DWS层的数据量正常只有DWD层的1/100甚至更少,这点类似于Kylin中的Base Cuboid结构。
- 当然在Hologres上也可以采用类似Kylin构建Cube的方式:将明细表按照所需的各种维度组合做Group by,或者Cube、Rollup、Grouping Sets等原生表达式,对指标进行预聚合运算。但是同样也会存在数据膨胀问题,一般情况下按照上述方案即可。
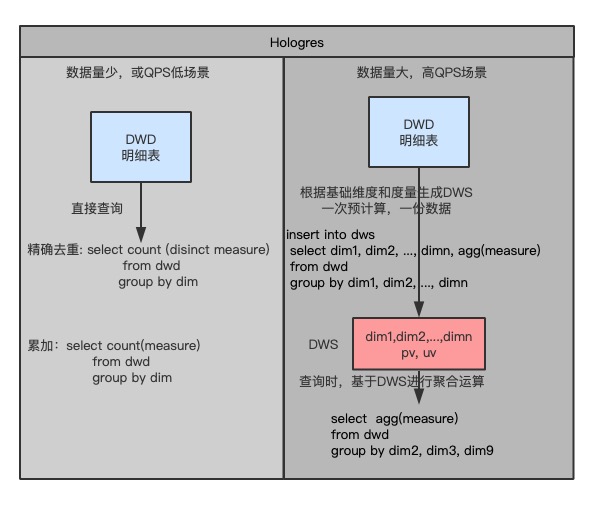
图2 Hologres不同场景下精确去重和累加计算
综上所述,Kylin对可累加指标或精确去重指标的查询时,需构建Cube才能获取较高性能,这将引入额外的预计算和数据膨胀。而Hologres则更为灵活:
- 对于DWD层数据量不大或者查询QPS要求不高的场景,无需预计算,可直接在DWD层上进行查询,即可获得很好的性能与最大的灵活性;
- 对于DWD层数据量较大且有高QPS查询的场景,可根据基础维度进行一次预计算,并只生成一份DWS表,查询时按需选取维度查询即可。不会引入过多的预计算和数据膨胀问题。
本文下面将会介绍基于Hologres的DWS层构造和查询方案。
迁移可累加指标
- 明细数据导入Hologres,数据结构采用原始Hive中的事实表、维度表结构,可以通过“DataWorks数据集成批量同步”完成数据迁移。
- 数据源数据对应DWD层,包含明细数据和维度数据,如果数据是行为数据,根据日期字段建成分区表,如果是订单数据,不需要分区表。
- 对于QPS要求不高的场景:DWD表通过JDBC、ODBC暴露给BI应用。
- 对于QPS要求高的场景:继续加工DWD生成DWS表,在Hologres中,针对Cube的连接条件,生成基础聚合表
BasicSummaryTable,如Kylin中Fact A left join Fact B,指标:Sum(a), count(b),Hologres中执行insert into BasicSummaryTable(col1, col2, ..., coln, sum_a, count_b) select col1, col2, ..., coln, sum(a), count(b) from A left join b group by col1, col2, ..., coln. 结果保存为BasicSummaryTable表。 - Hologres通过JDBC、ODBC暴露
BasicSummaryTable表给BI应用。
DWS层的构造中,最重要的就是各种度量数据(指标)的聚合,需要保证各指标都是可累计的。对于SUM、COUNT、MIN、MAX、AVG(可通过保留两个字段:sum和count来解决),指标的可累计是非常简单的。
但对于COUNT DISTINCT类的指标(需要精确去重的指标,例如UV),也需要保证在DWS中,这个指标是可累计的,可通过Hologres原生支持的RoaringBitmap数据类型来进行计算和保存。
迁移不可累加指标(精确去重场景)
下面通过一个案例介绍Hologres中通过DWS来计算大时间范围的PV、UV的最佳实践。
PV (Page View): 字面含义页面访问量,比如一天内页面的累计访问量。其实也可引申为某段时间内某个指标的累加量。比如:双十一期间某件商品的点击量,活动促销期间某个地区的订单量等。
UV (Unique Visitor) : 访问网页的自然人,如果有20个人一天访问某个页面100次,这一天就是20个UV。可以引申为某段时间内某个指标精确去重后的量。
PV和UV是分析场景中比较重要的两个指标,下面将以T+1离线场景为案例,进行PV UV计算的介绍。
案例背景
每天有几亿条数据,客户总量千万级,每日UV在百万级,需要T+1根据十个左右维度(支持维度间任意组合)查询一天,一周,或者一个月甚至半年期间相应的用户数去重统计信息,得出用户数精确去重指标UV,以及访问量PV。
一般方式的UV PV计算
如果不采取任何预聚合运算,上述场景计算用户数精确去重指标UV和访问量PV,SQL如下:
select count(distinct uid) as uv, count(1) as pv
from src_t
group by dim1, dim2
where ymd ='20210426'; select count(distinct uid) as uv, count(1) as pv
from src_t
group by dim1, dim5, dim9
where ymd like '202103%'; --查询区间为3月份 --group by的字段是固定维度的中任意维度的组合
--where 过滤的区间范围 从一天到半年不等 --因此有多少维度和时间的组合需求,就需要查询多少个这样count distinct sql,每条在查询时都需要大量计算
这种方式下,根据查询区间,每次查询要对几亿条到几十亿甚至几百亿条数据进行多个维度的Group by,然后再使用COUNT DISTINCT进行精确去重,会产生大量的数据交换计算,实时地得到结果需要一定量的计算资源,大大增加用户的成本。
基于Bitmap方式计算精确去重
Hologres内置Bitmap类型,通过计算一定维度组合条件下的Bitmap结果集,把维度的所有组合生成预计算的结果表,简单原理如下:
查询时,根据查询时的维度,查询对应的预计算结果表对桶进行聚合运算即可达到亚秒级查询。
--计算bitmap insert into result_t select RB_BUILD_AGG(uid) as uv_bitmap, count(1) as pv
from src_t
group by dim, ymd; --存在跨天查询的需求,日期也必须加到group by维度中 --查询时
select RB_CARDINALITY(RB_OR_AGG(uv_bitmap)), pv from result_t where ymd = '20210426' select RB_CARDINALITY(RB_OR_AGG(uv_bitmap)), pv
from result_t
where ymd >= '20210301' and ymd <= '20210331'
后面我们将会陆续推出Hologres基于RoaringBitmap的高效UV计算最佳实践,主要内容如下,敬请期待:
- Hologres使用RoaringBitmap实现高效UV计算
- Hologres使用Flink+RoaringBitmap实现实时UV计算
参考文档
Apache Kylin:http://kylin.apache.org/
Kylin精确去重:https://blog.bcmeng.com/post/kylin-distinct-count-global-dict.html
Hologres RoaringBitmap函数:https://help.aliyun.com/document_detail/216945.htm
本文为阿里云原创内容,未经允许不得转载。
Hologres如何支持亿级用户UV计算的更多相关文章
- 亿级用户下的新浪微博平台架构 前端机(提供 API 接口服务),队列机(处理上行业务逻辑,主要是数据写入),存储(mc、mysql、mcq、redis 、HBase等)
https://mp.weixin.qq.com/s/f319mm6QsetwxntvSXpKxg 亿级用户下的新浪微博平台架构 炼数成金前沿推荐 2014-12-04 序言 新浪微博在2014年3月 ...
- 腾讯正式开源图计算框架Plato,十亿级节点图计算进入分钟级时代
腾讯开源再次迎来重磅项目,14日,腾讯正式宣布开源高性能图计算框架Plato,这是在短短一周之内,开源的第五个重大项目. 相对于目前全球范围内其它的图计算框架,Plato可满足十亿级节点的超大规模图计 ...
- 腾讯开源进入爆发期,Plato助推十亿级节点图计算进入分钟级时代
腾讯开源再次迎来重磅项目,14日,腾讯正式宣布开源高性能图计算框架Plato,这是在短短一周之内,开源的第五个重大项目. 相对于目前全球范围内其它的图计算框架,Plato可满足十亿级节点的超大规模图计 ...
- Redis系列9:Geo 类型赋能亿级地图位置计算
Redis系列1:深刻理解高性能Redis的本质 Redis系列2:数据持久化提高可用性 Redis系列3:高可用之主从架构 Redis系列4:高可用之Sentinel(哨兵模式) Redis系列5: ...
- 文章翻译:Recommending items to more than a billion people(面向十亿级用户的推荐系统)
Web上数据的增长使得在完整的数据集上使用许多机器学习算法变得更加困难.特别是对于个性化推荐问题,数据采样通常不是一种选择,需要对分布式算法设计进行创新,以便我们能够扩展到这些不断增长的数据集. 协同 ...
- no.9亿级用户下的新浪微博平台架构读后感
微博平台的第三代技术体系,使用正交分解法建立模型:在水平方向,采用典型的三级分层模型,即接口层.服务层与资源层:在垂直方向,进一步细分为业务架构.技术架构.监控平台与服务治理平台. 水平分层 (1)接 ...
- 亿级用户百TB级数据的AIOps 技术实践之路
关于面临的挑战 "因为专业性强,我认为反而让交互方式变简单了,打个点餐的比方,软件1.0阶段是,我要吃鱼香肉丝,我要吃辣的或是素一点的,根据清晰的接口上菜.而软件2.0阶段就是,我今天想吃开 ...
- Redis实战:如何构建类微博的亿级社交平台
微博及 Twitter 这两大社交平台都重度依赖 Redis 来承载海量用户访问.本文介绍如何使用 Redis 来设计一个社交系统,以及如何扩展 Redis 让其能够承载上亿用户的访问规模. 虽然单台 ...
- 从100PV到1亿级PV网站架构演变
如果你对项目管理.系统架构有兴趣,请加微信订阅号"softjg",加入这个PM.架构师的大家庭 一个网站就像一个人,存在一个从小到大的过程.养一个网站和养一个人一样,不同时期需要不 ...
- [转载]从100PV到1亿级PV网站架构演变
原文地址:http://www.uml.org.cn/zjjs/201307172.asp 一个网站就像一个人,存在一个从小到大的过程.养一个网站和养一个人一样,不同时期需要不同的方法,不同的方法下有 ...
随机推荐
- CMake 用法总结(转载)
原文地址 什么是 CMake All problems in computer science can be solved by another level of indirection. David ...
- 项目升级到Android31版本dlopen找不到系统so库文件
简介 最近有个海外项目需要把之前项目从30版本升级到31版本,升级后发现就发现一个问题: 因为我们的项目是系统签名的apk,所以集成到系统中后是没有任何问题的,但是当我们手动安装后就会出现使用dlop ...
- 常用命令rsyncscp-1
常用命令:rsync/scp scp scp命令文件传输 scp命令用于在Linux下进行远程拷贝文件的命令,和它类似的命令有cp,不过cp只是在本机进行拷贝不能跨服务器,而且scp传输是加密的.可能 ...
- Android 开发Day8
/* AUTO-GENERATED FILE. DO NOT MODIFY. * * This class was automatically generated by the * gradle pl ...
- (3)安装完python之后需要安装的Spyder集成开发环境教程
步骤一: 首先,在网站上下载你所需要的压缩文件,网址为https://files.pythonhosted.org/packages/5e/a0/ab7f29e32479d15663eab9afd1d ...
- 【LeetCode刷题】239.滑动窗口最大值
239.滑动窗口最大值(点击跳转LeetCode) 给你一个整数数组nums,有一个大小为k的滑动窗口从数组的最左侧移动到数组的最右侧.你只可以看到在滑动窗口内的k个数字.滑动窗口每次只向右移动一位. ...
- EVENG导入Win7镜像以后可以启动无法VNC打开
原因:未安装支持 eveng 的 vncviewer 解决方法:下载 vncviewer: https://pan.eve-ng.cn/Tools/EVE-NG/Client/EVE-NG-Win-C ...
- 基于proteus的4026的二分频计数
基于proteus的4026的二分频计数 1.芯片原理 4026还是一个CMOS芯片,是直接输出段码的计数器.显然,这个芯片的作用就是和七段数码管配合,直接将计数结果显示在数码管上.这里只是用于分频, ...
- KingbaseES错误unsupported for database link处理
KingbaseES使用dblink查询报错:unsupported for database link 适用于: KingbaseES所有版本. 问题现象: KingbaseES创建kingbase ...
- 参数 ora_input_emptystr_isnull 对于数据存储的影响
原生的PG 对于 '' 和 null 认为是不同值:空值 和不确定值:而oracle 认为二者都是不确定的值.KingbaseES 为了兼容Oracle,增加了参数ora_input_emptystr ...