阿里千万实例可观测采集器-iLogtail正式开源
简介:11月23日,阿里正式开源可观测数据采集器iLogtail。作为阿里内部可观测数据采集的基础设施,iLogtail承载了阿里巴巴集团、蚂蚁的日志、监控、Trace、事件等多种可观测数据的采集工作。iLogtail运行在服务器、容器、K8s、嵌入式等多种环境,支持采集数百种可观测数据,目前已经有千万级的安装量,每天采集数十PB的可观测数据,广泛应用于线上监控、问题分析/定位、运营分析、安全分析等多种场景。

作者 | 元乙
来源 | 阿里技术公众号
11月23日,阿里正式开源可观测数据采集器iLogtail。作为阿里内部可观测数据采集的基础设施,iLogtail承载了阿里巴巴集团、蚂蚁的日志、监控、Trace、事件等多种可观测数据的采集工作。iLogtail运行在服务器、容器、K8s、嵌入式等多种环境,支持采集数百种可观测数据,目前已经有千万级的安装量,每天采集数十PB的可观测数据,广泛应用于线上监控、问题分析/定位、运营分析、安全分析等多种场景。
一 iLogtail与可观测性

可观测性并不是一个全新的概念,而是从IT系统中的监控、问题排查、稳定性建设、运营分析、BI、安全分析等逐渐演化而来,可观测性相比传统监控,最核心的演进是尽可能多的收集各类可观测数据,来实现目标的白盒化。而iLogtail的核心定位就是可观测数据的采集器,能够尽可能多的采集各类可观测性数据,助力可观测平台打造各种上层的应用场景。
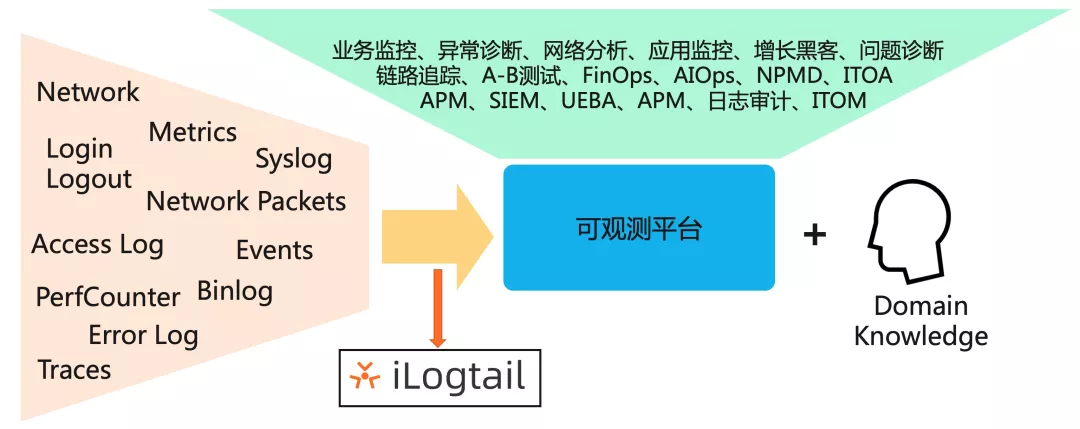
二 阿里可观测数据采集的挑战

对于可观测数据的采集,有很多开源的Agent,例如Logstash、Filebeats、Fluentd、Collectd、Telegraf等。这些Agent的功能非常丰富,使用这些Agent的组合再进行一定的扩展,基本可以满足内部各类数据的采集需求。但由于一些性能、稳定性、管控能力等关键性的挑战无法满足,最终我们还是选择自研:
1、资源消耗:目前阿里内部有数百万的主机(物理机/虚拟机/容器),每天会产生几十PB的可观测数据,每1M的内存减少、每1M/s的性能提升对于我们的资源节省都是巨大的,带来的成本节约可能是数百万甚至上千万。目前众多开源Agent的设计更多的是偏重功能而非性能,基于现有开源Agent改造基本不可行。例如:
- 开源Agent普遍单核处理性能在2-10M/s左右,而我们希望有一个能达到100M/s的性能
- 在采集目标增加、数据量增加、采集延迟、服务端异常等情况下,开源Agent内存都会呈现爆炸式增长,而我们希望即使在各种环境下,内存也能处在较低的水位
- 开源Agent的资源消耗没办法控制,只能通过cgroup强行限制,最终的效果就是不断OOM,不断重启,数据一直采集不上来。而我们希望在指定一个CPU、内存、流量等资源限制后,Agent能一直在这个限制范围内正常工作
2、稳定性:稳定性是永恒的话题,数据采集的稳定性,除了保证数据本身采集的准确性外,还需要保证采集的Agent不能影响业务应用,否则带来的影响将是灾难性的。而稳定性建设,除了Agent自身的基础稳定性外,还有很多特性目前开源的Agent还没有提供:
- Agent自恢复:Agent遇到Critical的事件后能够自动恢复,并且提供多个维度的自恢复能力,例如进程自身、父子进程、守护进程
- 全局的多维度监控:能够从全局的角度监控各个不同版本、不同采集配置、不同压力、不同地域/网络等属性的Agent的稳定性问题
- 问题隔离:作为Agent,无论怎样出现问题,都需要尽可能的隔离问题,例如一个Agent上有多个采集配置,一个配置出问题,不能影响其他配置;Agent自身出现问题,不能影响机器上的应用进程的稳定性
- 回滚能力:版本更新和发布是再所难免的问题,在出现问题的时候如何快速回滚,而且保证出问题和回滚期间的数据采集还是at least once甚至是exactly once。
3、可管控:可观测数据的应用范围非常的广,几乎所有的业务、运维、BI、安全等部门都会要用,而一台机器上也会产生各种数据,同一台机器产生的数据上也会有多个部门的人要去使用,例如在2018年我们统计,平均一台虚拟机上有100多个不同类型的数据需要采集,设计10多个不同部门的人要去使用这些数据。除了这些之外,还会有其他很多企业级的特性需要支持,例如:
- 配置的远程管理:在大规模场景下,手工登录机器修改配置基本没有可行性,因此需要一套配置的图形化管理、远程存储、自动下发的机制,而且还要能够区分不同的应用、不同的Region、不同的归属方等信息。同时因为涉及到远程配置的动态加卸载,Agent还需要能够保证配置Reload期间数据不丢不重
- 采集配置优先级:当一台机器上有多个采集配置在运行时,如果遇到资源不足的情况,需要区分每个不同的配置优先级,资源优先供给高优先级的配置,同时还要确保低优先级的配置不被“饿死”
- 降级与恢复能力:在阿里,大促、秒杀是家常便饭,在这种波峰期间,可能有很多不重要的应用被降级,同样对应应用的数据也需要降级,降级后,在凌晨波峰过后,还需要有足够的Burst能力快速追齐数据
- 数据采集齐全度:监控、数据分析等场景都要求数据准确度,数据准确的前提是都能及时采集到服务端,但如何在计算前确定每台机器、每个文件的数据都采集到了对应的时间点,需要一套非常复杂的机制去计算
基于以上的背景和挑战下,我们从2013年开始,不断逐渐优化和改进iLogtail来解决性能、稳定性、可管控等问题,并经历了阿里多次双十一、双十二、春晚红包等项目的考验。目前iLogtail支持包括Logs、Traces、Metrics多种类型数据的统一收集,核心的特点主要如下:
- 支持多种Logs、Traces、Metrics数据采集,尤其对容器、Kubernetes环境支持非常友好
- 数据采集资源消耗极低,单核采集能力100M/s,相比同类可观测数据采集的Agent性能好5-20倍
- 高稳定性,在阿里巴巴以及数万阿里云客户生产中使用验证,部署量近千万,每天采集数十PB可观测数据
- 支持插件化扩展,可任意扩充数据采集、处理、聚合、发送模块
- 支持配置远程管理,支持以图形化、SDK、K8s Operator等方式进行配置管理,可轻松管理百万台机器的数据采集
- 支持自监控、流量控制、资源控制、主动告警、采集统计等多种高级管控特性
三 iLogtail发展历程
秉承着阿里人简单的特点,iLogtail的命名也非常简单,我们最开始期望的就是能够有一个统一去Tail日志的工具,所以就叫做Logtail,添加上“i”的原因主要当时使用了inotify的技术,能够让日志采集的延迟控制在毫秒级,因此最后叫做iLogtail。从2013年开始研发,iLogtail整个发展历程概括起来大致可以分为三个阶段,分别是飞天5K阶段、阿里集团阶段和云原生阶段。

1 飞天5K阶段
作为中国云计算领域的里程碑,2013年8月15日,阿里巴巴集团正式运营服务器规模达到5000(5K)的“飞天”集群,成为中国第一个独立研发拥有大规模通用计算平台的公司,也是世界上第一个对外提供5K云计算服务能力的公司。
飞天5K项目从2009年开始,从最开始的30台逐渐发展到5000,不断解决系统核心的问题,比如说规模、稳定性、运维、容灾等等。而iLogtail在这一阶段诞生,最开始就是要解决5000台机器的监控、问题分析、定位的工作(如今的词语叫做“可观测性”)。从30到5000的跃升中,对于可观测问题有着诸多的挑战,包括单机瓶颈、问题复杂度、排查便捷性、管理复杂度等。
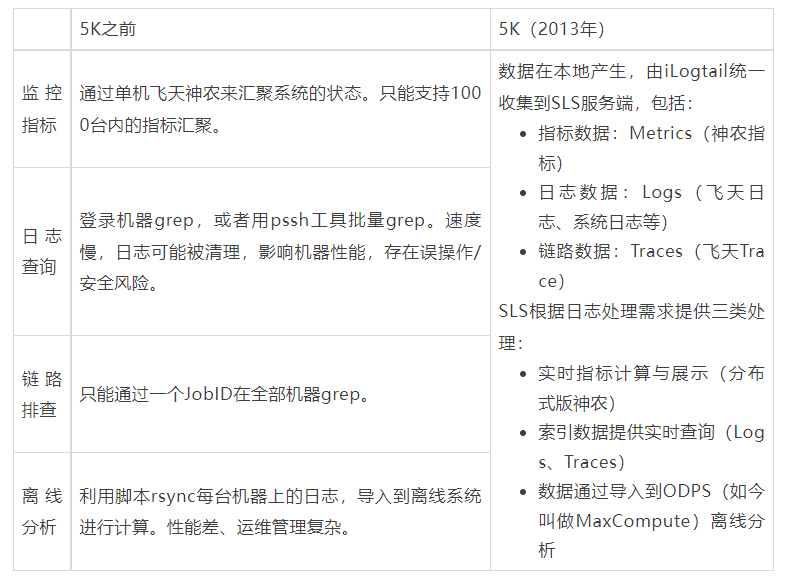
在5K阶段,iLogtail本质上解决的是从单机、小规模集群到大规模的运维监控挑战,这一阶段iLogtail主要的特点有:
- 功能:实时日志、监控采集,日志抓取延迟毫秒级
- 性能:单核处理能力10M/s,5000台集群平均资源占用0.5%CPU核
- 可靠性:自动监听新文件、新文件夹,支持文件轮转,处理网络中断
- 管理:远程Web管理,配置文件自动下发
- 运维:加入集团yum源,运行状态监控,异常自动上报
- 规模:3W+部署规模,上千采集配置项,日10TB数据
2 阿里集团阶段
iLogtail在阿里云飞天5K项目中的应用解决了日志、监控统一收集的问题,而当时阿里巴巴集团、蚂蚁等还缺少一套统一、可靠的日志采集系统,因此我们开始推动iLogtail作为集团、蚂蚁的日志采集基础设施。从5K这种相对独立的项目到全集团应用,不是简单复制的问题,而我们要面对的是更多的部署量、更高的要求以及更多的部门:
- 百万规模运维问题:此时整个阿里、蚂蚁的物理机、虚拟机超过百万台,我们希望只用1/3的人力就可以运维管理百万规模的Logtail
- 更高的稳定性:iLogtail最开始采集的数据主要用于问题排查,集团广泛的应用场景对于日志可靠性要求越来越高,例如计费计量数据、交易数据,而且还需要满足双十一、双十二等超大数据流量的压力考验。
- 多部门、团队:从服务5K团队到近千个团队,会有不同的团队使用不同的iLogtail,而一个iLogtail也会被多个不同的团队使用,在租户隔离上对iLogtail是一个新的挑战。
经过几年时间和阿里集团、蚂蚁同学的合作打磨,iLogtail在多租户、稳定性等方面取得了非常大的进步,这一阶段iLogtail主要的特点有:
- 功能:支持更多的日志格式,例如正则、分隔符、JSON等,支持多种日志编码方式,支持数据过滤、脱敏等高级处理
- 性能:极简模式下提升到单核100M/s,正则、分隔符、JSON等方式20M/s+
- 可靠性:采集可靠性支持Polling、轮转队列顺序保证、日志清理保护、CheckPoint增强;进程可靠性增加Critical自恢复、Crash自动上报、多级守护
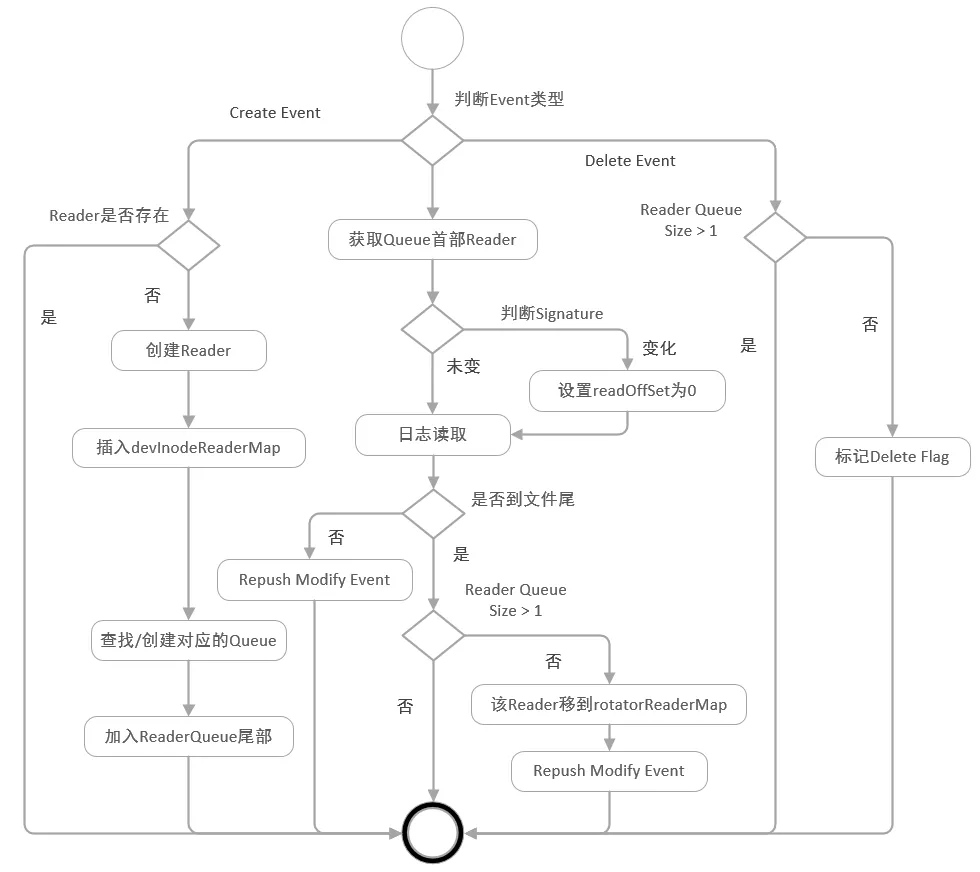
日志保序采集方案原理(细节可参考《iLogtail技术分享(一) : Polling + Inotify 组合下的日志保序采集方案》)
- 多租户:支持全流程多租户隔离、多级高低水位队列、采集优先级、配置级/进程级流量控制、临时降级机制
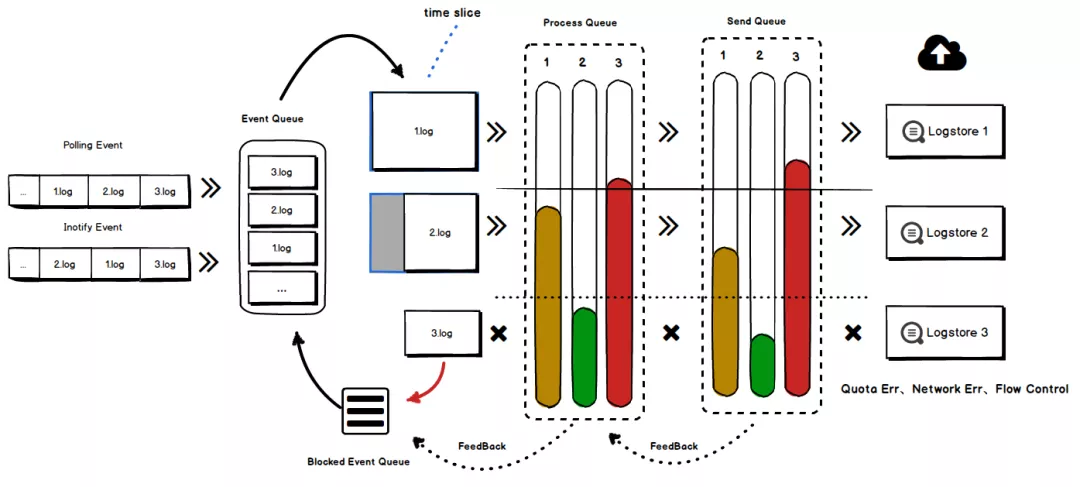
多租户隔离整体流程(细节可参考《iLogtail技术分享(二):多租户隔离技术+双十一实战效果》)
- 运维:基于集团StarAgent自动安装与守护,异常主动通知,提供多种问题自查工具
- 规模:百万+部署规模,千级别内部租户,10万+采集配置,日采集PB级数据
3 云原生阶段
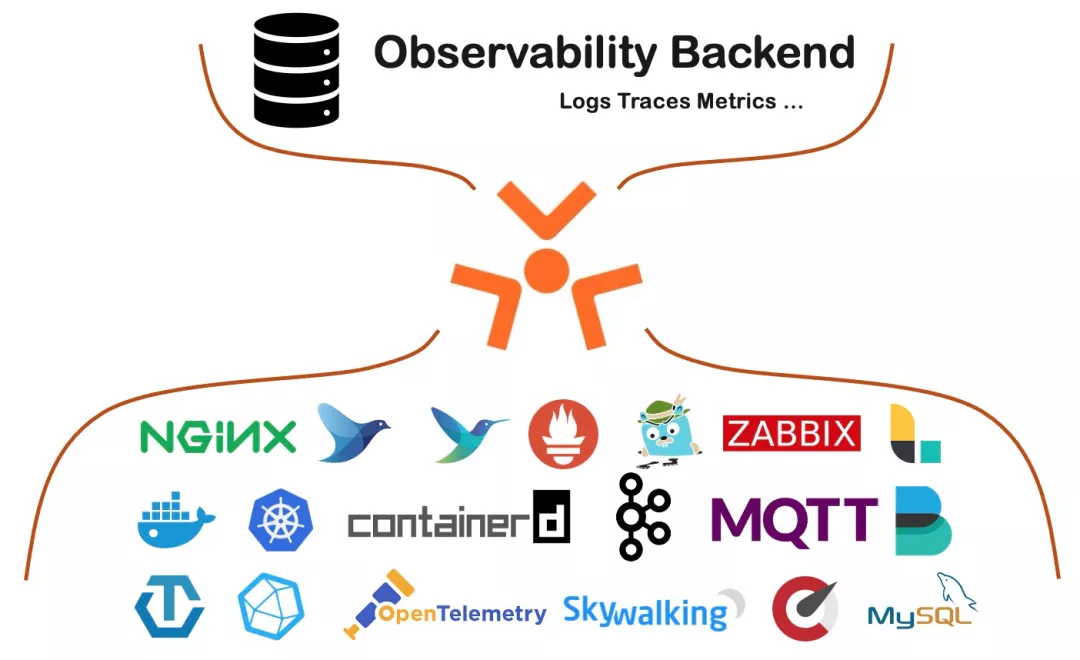
随着阿里所有IT基础设施全面云化,以及iLogtail所属产品SLS(日志服务)正式在阿里云上商业化,iLogtail开始全面拥抱云原生。从阿里内部商业化并对外部各行各业的公司提供服务,对于iLogtail的挑战的重心已经不是性能和可靠性,而是如何适应云原生(容器化、K8s,适应云上环境)、如何兼容开源协议、如何去处理碎片化需求。这一阶段是iLogtail发展最快的时期,经历了非常多重要的变革:
- 统一版本:iLogtail最开始的版本还是基于GCC4.1.2编译,代码还依赖飞天基座,为了能适用更多的环境,iLogtail进行了全版本的重构,基于一套代码实现Windows/Linux、X86/Arm、服务器/嵌入式等多种环境的编译发版
- 全面支持容器化、K8s:除了支持容器、K8s环境的日志、监控采集外,对于配置管理也进行了升级,支持通过Operator的方式进行扩展,只需要配置一个AliyunLogConfig的K8s自定义资源就可以实现日志、监控的采集
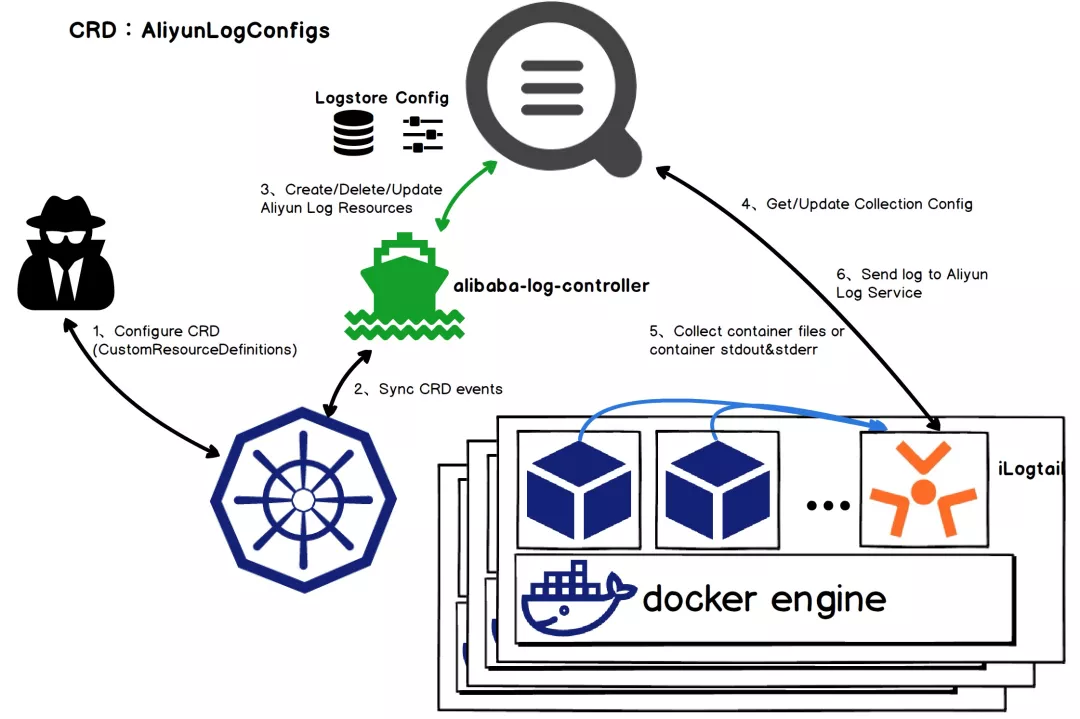
iLogtail Kubernetes日志采集原理(细节可参考《Kubernetes日志采集原理剖析》)
- 插件化扩展:iLogtail增加插件系统,可自由扩展Input、Processor、Aggregator、Flusher插件用以实现各类自定义的功能
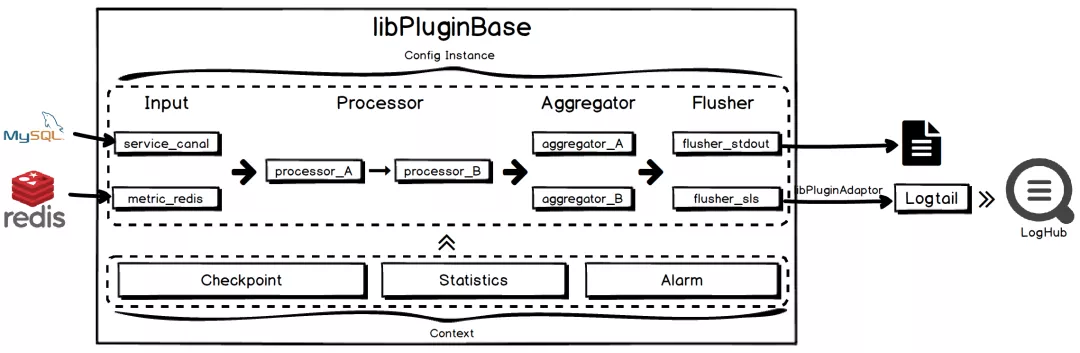

iLogtail插件系统整体流程(细节可参考《iLogtail插件系统简介》)
- 规模:千万部署规模,数万内外部客户,百万+采集配置项,日采集数十PB数据
四 开源背景与期待
闭源自建的软件永远无法紧跟时代潮流,尤其在当今云原生的时代,我们坚信开源才是iLogtail最优的发展策略,也是释放其最大价值的方法。iLogtail作为可观测领域最基础的软件,我们将之开源,也希望能够和开源社区一起共建,持续优化,争取成为世界一流的可观测数据采集器。对于未来iLogail的发展,我们期待:
- iLogtail在性能和资源占用上相比其他开源采集软件具备一定优势,相比开源软件,在千万部署规模、日数十PB数据的规模性下为我们减少了100TB的内存和每年1亿的CPU核小时数。我们也希望这款采集软件可以为更多的企业带来资源效率的提升,实现可观测数据采集的“共同富裕”。
- 目前iLogtail还只是在阿里内部以及很小一部分云上企业(虽然有几万家,但是面对全球千万的企业,这个数字还很小),面对的场景相对还较少,我们希望有更多不同行业、不同特色的公司可以使用iLogtail并对其提出更多的数据源、处理、输出目标的需求,丰富iLogtail支持的上下游生态。
- 性能、稳定性是iLogtail的最基本追求,我们也希望能够通过开源社区,吸引更多优秀的开发者,一起共建iLogtail,持续提升这款可观测数据采集器的性能和稳定性。
原文链接
本文为阿里云原创内容,未经允许不得转载。
阿里千万实例可观测采集器-iLogtail正式开源的更多相关文章
- Hawk 3. 网页采集器
1.基本入门 1. 原理(建议阅读) 网页采集器的功能是获取网页中的数据(废话).通常来说,目标可能是列表(如购物车列表),或是一个页面中的固定字段(如JD某商品的价格和介绍,在页面中只有一个).因此 ...
- 火车采集器 帝国CMS7.2免登录发布模块
帝国cms7.2增加了金刚模式,登录发布有难度.免登录发布模块配合火车采集器,完美解决你遇到的问题. 免登录直接获取栏目列表 通过文件内设置密码免登录发布数据 帝国cms7.2免登陆文章发布接口使用说 ...
- WEB页面采集器编写经验之一:静态页面采集器
严格意义来说,采集器和爬虫不是一回事:采集器是对特定结构的数据来源进行解析.结构化,将所需的数据从中提取出来:而爬虫的主要目标更多的是页面里的链接和页面的TITLE. 采集器也写过不少了,随便写一点经 ...
- centos创建监控宝采集器及添加插件任务
官方的说明文档很不详细操作也有点小问题,故把操作记录如下. 操作系统环境: centos 5.8 python 2.4.3 创建采集器等操作这里就不说了,见官方文档:http://blog.jiank ...
- WP开发-Toolkit组件 列表采集器(ListPicker)的使用
列表采集器ListPicker在作用上与html中的<select/>标签一样 都是提供多选一功能,区别在于ListPicker可以自定义下拉状态和非下拉状态的样式. 1.模板设置 Lis ...
- 【RSYSLOG】rsyslog作为日志采集器安装配置说明
RSYSLOG is the rocket-fast system for log processing. About 由于环境基于CentOS 6.7 x64,rsyslog本身就是OS的组件,由于 ...
- JMeter学习-011-JMeter 后置处理器实例之 - 正则表达式提取器(三)多参数获取进阶引用篇
前两篇文章分表讲述了 后置处理器 - 正则表达式提取器概述及简单实例.多参数获取,相应博文敬请参阅 简单实例.多参数获取. 此文主要讲述如何引用正则表达式提取器获取的数据信息.其实,正则表达式提取器获 ...
- JMeter学习-009-JMeter 后置处理器实例之 - 正则表达式提取器(二)多参数获取
前文简述了通过后置处理器 - 正则表达式提取器 获取 HTTP请求 响应结果中的特定数据,未看过的亲,敬请参阅 JMeter学习-008-JMeter 后置处理器实例之 - 正则表达式提取器(一). ...
- JMeter学习-008-JMeter 后置处理器实例之 - 正则表达式提取器(一)概述及简单实例
上文我们讲述了如何对 HTTP请求 的响应数据进行断言,以判断响应是否符合我们的预期,敬请参阅:JMeter学习-007-JMeter 断言实例之一 - 响应断言 那么我们如何获取 HTTP请求 响应 ...
- 淘宝IP地址库采集器c#代码
这篇文章主要介绍了淘宝IP地址库采集器c#代码,有需要的朋友可以参考一下. 最近做一个项目,功能类似于CNZZ站长统计功能,要求显示Ip所在的省份市区/提供商等信息.网上的Ip纯真数据库,下载下来一看 ...
随机推荐
- using用法总结
一.命名空间的使用 不再赘述. 二.在子类中改变基类成员的访问权限 using可以将public和protected的基类成员的访问权限改为public.protected.private,注意,us ...
- Ubuntu 16.04 LAMP(PHP7.0) 环境搭建并测试
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- python基础四(字符编码)
一 了解字符编码的知识储备 计算机基础知识 文本编辑器存取文件的原理(nodepad++,pycharm,word) #1.打开编辑器就打开了启动了一个进程,是在内存中的,所以,用编辑器编写的内容也都 ...
- 大场景的倾斜摄影三维模型OBJ格式轻量化处理处理关键处理技术分析
大场景的倾斜摄影三维模型OBJ格式轻量化处理处理关键处理技术分析 大场景的倾斜摄影三维模型是指通过航空或地面摄影获取的大范围.高分辨率的地理环境数据.为了在虚拟环境中加载和渲染这些模型,需要对其进行O ...
- 性能测试系列:Jmeter使用记录
jmeter配置环境变量vi /etc/profileexport PATH=$PATH:/tmp/jmeter/apache-jmeter-5.4.1/binsource /etc/profile ...
- es搜索优化
1.V1版本:仅做了分词的查询,使用ik分词器ik_max_word POST /t_sku/_search { "size": 10, "query": { ...
- 鸿蒙HarmonyOS实战-ArkUI组件(mediaquery)
一.mediaquery 1.概述 媒体查询(mediaquery)它允许根据设备的不同特性(如屏幕大小.屏幕方向.分辨率.颜色深度等)来动态地调整网页的样式和布局. 通过媒体查询,可以为不同的设备定 ...
- NetAdapt:MobileNetV3用到的自动化网络简化方法 | ECCV 2018
NetAdapt的思想巧妙且有效,将优化目标分为多个小目标,并且将实际指标引入到优化过程中,能够自动化产生一系列平台相关的简化网络,不仅搜索速度快,而且得到简化网络在准确率和时延上都于较好的表现 ...
- KingbaseES 支持自定义异常
KingbaseES PLSQL 从 V8R6C4 版本开始,支持用户自定义异常.具体例子如下: create or replace procedure p_test() as error_numbe ...
- Java对象序列化和反序列化
Java类的序列化和反序列化 序列化:指将对象转换为字节序列的过程,也就是将对象的信息转换成文件保存. 反序列化:将字节序列转换成目标对象的过程,也就是读取文件,并转换为对象. 几个关键点: 必须实现 ...