机器学习:详解多任务学习(Multi-task learning)
详解多任务学习
在迁移学习中,步骤是串行的,从任务\(A\)里学习只是然后迁移到任务\(B\)。在多任务学习中,是同时开始学习的,试图让单个神经网络同时做几件事情,然后希望这里每个任务都能帮到其他所有任务。

来看一个例子,假设在研发无人驾驶车辆,那么无人驾驶车可能需要同时检测不同的物体,比如检测行人、车辆、停车标志,还有交通灯各种其他东西。比如在左边这个例子中,图像里有个停车标志,然后图像中有辆车,但没有行人,也没有交通灯。

如果这是输入图像\(x^{(i)}\),那么这里不再是一个标签 \(y^{(i)}\),而是有4个标签。在这个例子中,没有行人,有一辆车,有一个停车标志,没有交通灯。然后如果尝试检测其他物体,也许 \(y^{(i)}\)的维数会更高,现在就先用4个吧,所以 \(y^{(i)}\)是个4×1向量。如果从整体来看这个训练集标签和以前类似,将训练集的标签水平堆叠起来,像这样\(y^{(1)}\)一直到\(y^{(m)}\):
| & | & | & \ldots & | \\
y^{(1)} & y^{(2)} & y^{(3)} & \ldots & y^{(m)} \\
| & | & | & \ldots & | \\
\end{bmatrix}
\]
不过现在\(y^{(i)}\)是4×1向量,所以这些都是竖向的列向量,所以这个矩阵\(Y\)现在变成\(4×m\)矩阵。而之前,当\(y\)是单实数时,这就是\(1×m\)矩阵。
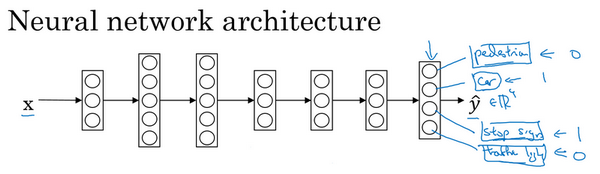
那么现在可以做的是训练一个神经网络,来预测这些\(y\)值,就得到这样的神经网络,输入\(x\),现在输出是一个四维向量\(y\)。请注意,这里输出画了四个节点,所以第一个节点就是想预测图中有没有行人,然后第二个输出节点预测的是有没有车,这里预测有没有停车标志,这里预测有没有交通灯,所以这里\(\hat y\)是四维的。
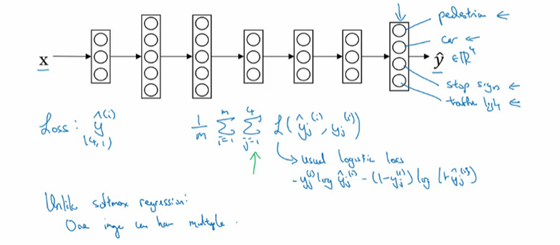
要训练这个神经网络,现在需要定义神经网络的损失函数,对于一个输出\(\hat y\),是个4维向量,对于整个训练集的平均损失:
\(\frac{1}{m}\sum_{i = 1}^{m}{\sum_{j = 1}^{4}{L(\hat y_{j}^{(i)},y_{j}^{(i)})}}\)
\(\sum_{j = 1}^{4}{L(\hat y_{j}^{(i)},y_{j}^{(i)})}\)这些单个预测的损失,所以这就是对四个分量的求和,行人、车、停车标志、交通灯,而这个标志L指的是logistic损失,就这么写:
\(L(\hat y_{j}^{(i)},y_{j}^{(i)}) = - y_{j}^{(i)}\log\hat y_{j}^{(i)} - (1 - y_{j}^{(i)})log(1 - \hat y_{j}^{(i)})\)
整个训练集的平均损失和之前分类猫的例子主要区别在于,现在要对\(j=1\)到4求和,这与softmax回归的主要区别在于,与softmax回归不同,softmax将单个标签分配给单个样本。
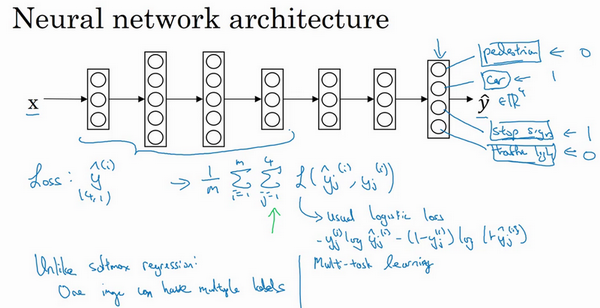
而这张图可以有很多不同的标签,所以不是说每张图都只是一张行人图片,汽车图片、停车标志图片或者交通灯图片。要知道每张照片是否有行人、或汽车、停车标志或交通灯,多个物体可能同时出现在一张图里。实际上,那张图同时有车和停车标志,但没有行人和交通灯,所以不是只给图片一个标签,而是需要遍历不同类型,然后看看每个类型,那类物体有没有出现在图中。所以就说在这个场合,一张图可以有多个标签。如果训练了一个神经网络,试图最小化这个成本函数,做的就是多任务学习。因为现在做的是建立单个神经网络,观察每张图,然后解决四个问题,系统试图告诉,每张图里面有没有这四个物体。另外也可以训练四个不同的神经网络,而不是训练一个网络做四件事情。但神经网络一些早期特征,在识别不同物体时都会用到,然后发现,训练一个神经网络做四件事情会比训练四个完全独立的神经网络分别做四件事性能要更好,这就是多任务学习的力量。
另一个细节,到目前为止,是这么描述算法的,好像每张图都有全部标签。事实证明,多任务学习也可以处理图像只有部分物体被标记的情况。所以第一个训练样本,说有人,给数据贴标签的人告诉里面有一个行人,没有车,但他们没有标记是否有停车标志,或者是否有交通灯。也许第二个例子中,有行人,有车。但是,当标记人看着那张图片时,他们没有加标签,没有标记是否有停车标志,是否有交通灯等等。也许有些样本都有标记,但也许有些样本他们只标记了有没有车,然后还有一些是问号。
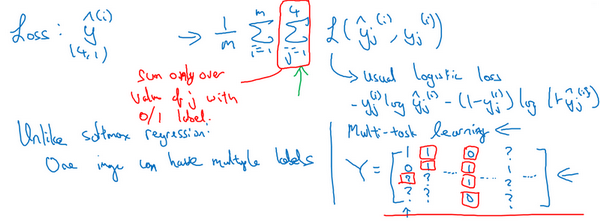
即使是这样的数据集,也可以在上面训练算法,同时做四个任务,即使一些图像只有一小部分标签,其他是问号或者不管是什么。然后训练算法的方式,即使这里有些标签是问号,或者没有标记,这就是对\(j\)从1到4求和,就只对带0和1标签的\(j\)值求和,所以当有问号的时候,就在求和时忽略那个项,这样只对有标签的值求和,于是就能利用这样的数据集。
那么多任务学习什么时候有意义呢?当三件事为真时,它就是有意义的。
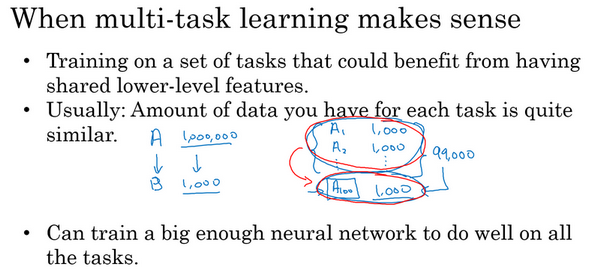
第一,如果训练的一组任务,可以共用低层次特征。对于无人驾驶的例子,同时识别交通灯、汽车和行人是有道理的,这些物体有相似的特征,也许能帮识别停车标志,因为这些都是道路上的特征。
第二,这个准则没有那么绝对,所以不一定是对的。但从很多成功的多任务学习案例中看到,如果每个任务的数据量很接近,还记得迁移学习时,从\(A\)任务学到知识然后迁移到\(B\)任务,所以如果任务\(A\)有1百万个样本,任务\(B\)只有1000个样本,那么从这1百万个样本学到的知识,真的可以帮增强对更小数据集任务\(B\)的训练。那么多任务学习又怎么样呢?在多任务学习中,通常有更多任务而不仅仅是两个,所以也许有,以前有4个任务,但比如说要完成100个任务,而要做多任务学习,尝试同时识别100种不同类型的物体。可能会发现,每个任务大概有1000个样本。所以如果专注加强单个任务的性能,比如专注加强第100个任务的表现,用\(A100\)表示,如果试图单独去做这个最后的任务,只有1000个样本去训练这个任务,这是100项任务之一,而通过在其他99项任务的训练,这些加起来可以一共有99000个样本,这可能大幅提升算法性能,可以提供很多知识来增强这个任务的性能。不然对于任务\(A100\),只有1000个样本的训练集,效果可能会很差。如果有对称性,这其他99个任务,也许能提供一些数据或提供一些知识来帮到这100个任务中的每一个任务。所以第二点不是绝对正确的准则,但通常会看的是如果专注于单项任务,如果想要从多任务学习得到很大性能提升,那么其他任务加起来必须要有比单个任务大得多的数据量。要满足这个条件,其中一种方法是,比如右边这个例子这样,或者如果每个任务中的数据量很相近,但关键在于,如果对于单个任务已经有1000个样本了,那么对于所有其他任务,最好有超过1000个样本,这样其他任务的知识才能帮改善这个任务的性能。
最后多任务学习往往在以下场合更有意义,当可以训练一个足够大的神经网络,同时做好所有的工作,所以多任务学习的替代方法是为每个任务训练一个单独的神经网络。所以不是训练单个神经网络同时处理行人、汽车、停车标志和交通灯检测。可以训练一个用于行人检测的神经网络,一个用于汽车检测的神经网络,一个用于停车标志检测的神经网络和一个用于交通信号灯检测的神经网络。那么研究员Rich Carona几年前发现的是什么呢?多任务学习会降低性能的唯一情况,和训练单个神经网络相比性能更低的情况就是神经网络还不够大。但如果可以训练一个足够大的神经网络,那么多任务学习肯定不会或者很少会降低性能,都希望它可以提升性能,比单独训练神经网络来单独完成各个任务性能要更好。
所以这就是多任务学习,在实践中,多任务学习的使用频率要低于迁移学习。看到很多迁移学习的应用,需要解决一个问题,但训练数据很少,所以需要找一个数据很多的相关问题来预先学习,并将知识迁移到这个新问题上。但多任务学习比较少见,就是需要同时处理很多任务,都要做好,可以同时训练所有这些任务,也许计算机视觉是一个例子。在物体检测中,看到更多使用多任务学习的应用,其中一个神经网络尝试检测一大堆物体,比分别训练不同的神经网络检测物体更好。但说,平均来说,目前迁移学习使用频率更高,比多任务学习频率要高,但两者都可以成为强力工具。
所以总结一下,多任务学习能让训练一个神经网络来执行许多任务,这可以给更高的性能,比单独完成各个任务更高的性能。但要注意,实际上迁移学习比多任务学习使用频率更高。看到很多任务都是,如果想解决一个机器学习问题,但数据集相对较小,那么迁移学习真的能帮到,就是如果找到一个相关问题,其中数据量要大得多,就能以它为基础训练神经网络,然后迁移到这个数据量很少的任务上来。
机器学习:详解多任务学习(Multi-task learning)的更多相关文章
- 【论文笔记】多任务学习(Multi-Task Learning)
1. 前言 多任务学习(Multi-task learning)是和单任务学习(single-task learning)相对的一种机器学习方法.在机器学习领域,标准的算法理论是一次学习一个任务,也就 ...
- zz详解深度学习中的Normalization,BN/LN/WN
详解深度学习中的Normalization,BN/LN/WN 讲得是相当之透彻清晰了 深度神经网络模型训练之难众所周知,其中一个重要的现象就是 Internal Covariate Shift. Ba ...
- 机器学习 | 详解GBDT在分类场景中的应用原理与公式推导
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第31篇文章,我们一起继续来聊聊GBDT模型. 在上一篇文章当中,我们学习了GBDT这个模型在回归问题当中的原理.GBD ...
- 《Node.js开发实战详解》学习笔记
<Node.js开发实战详解>学习笔记 ——持续更新中 一.NodeJS设计模式 1 . 单例模式 顾名思义,单例就是保证一个类只有一个实例,实现的方法是,先判断实例是否存在,如果存在则直 ...
- 【机器学习详解】SMO算法剖析(转载)
[机器学习详解]SMO算法剖析 转载请注明出处:http://blog.csdn.net/luoshixian099/article/details/51227754 CSDN−勿在浮沙筑高台 本文力 ...
- .NET 云原生架构师训练营(模块二 基础巩固 RabbitMQ Masstransit 详解)--学习笔记
2.6.7 RabbitMQ -- Masstransit 详解 Consumer 消费者 Producer 生产者 Request-Response 请求-响应 Consumer 消费者 在 Mas ...
- Android Binder IPC详解-Android学习之旅(96)
linux内存空间与BInder Driver Android进程和linux进程一样,他们只运行在进程固有的虚拟空间中.一个4GB的虚拟地址空间,其中3GB是用户空间,1GB是内核空间 ,用户空间是 ...
- Android系统服务详解-android学习之旅(95)
本文是看完android框架揭秘第六章后的总结 android系统服务提供最基本的,最稳定的核心功能,如设备控制,信息通知,通知设定,以及消息显示等,存在于Android Framework与Andr ...
- Kubernetes 部署策略详解-转载学习
Kubernetes 部署策略详解 参考:https://www.qikqiak.com/post/k8s-deployment-strategies/ 在Kubernetes中有几种不同的方式发布应 ...
- 机器学习--详解人脸对齐算法SDM-LBF
引自:http://blog.csdn.net/taily_duan/article/details/54584040 人脸对齐之SDM(Supervised Descent Method) 人脸对齐 ...
随机推荐
- 解读注意力机制原理,教你使用Python实现深度学习模型
本文分享自华为云社区<使用Python实现深度学习模型:注意力机制(Attention)>,作者:Echo_Wish. 在深度学习的世界里,注意力机制(Attention Mechanis ...
- Django——form组件的局部钩子
如果对字段的校验条件太少,不能满足我们的需求,那么,我们可以对每个字段自定义校验的内容,就可以使用局部钩子. 局部钩子的使用方法: (1)导入错误类型 ----> 我们自己定义的钩子抛出的错误也 ...
- MySQL学习笔记-数据控制语言
SQL-数据控制语言(DCL) DCL语句用于管理数据库用户,控制数据库的访问权限 一. 管理用户 1. 查询用户 # 访问mysql数据库 use mysql; #查询user表 select * ...
- 代码审计——基础(JAVAWEB)
JAVAWEB 目录 JAVAWEB Servlet技术 JavaWeb概述 Servelt与Servlet容器 Servlet概念 Tomcat Web程序结构 Servlet容器响应客户请求的过程 ...
- 纯css+html做emoji动态表情
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8& ...
- INFINI Easysearch 与华为鲲鹏完成产品兼容互认证
何为华为鲲鹏认证 华为鲲鹏认证是华为云围绕鲲鹏云服务(含公有云.私有云.混合云.桌面云)推出的一项合作伙伴计划,旨在为构建持续发展.合作共赢的鲲鹏生态圈,通过整合华为的技术.品牌资源,与合作伙伴共享商 ...
- Easysearch压缩模式深度比较:ZSTD+source_reuse的优势分析
引言 在使用 Easysearch 时,如何在存储和查询性能之间找到平衡是一个常见的挑战.Easysearch 具备多种压缩模式,各有千秋.本文将重点探讨一种特别的压缩模式:zstd + source ...
- ssh基础
SSH安全登录 机器准备 什么是SSH SSH 或 Secure Shell 协议是一种远程管理协议,允许用户通过 Internet 访问.控制和修改其远程服务器. SSH 服务是作为未加密 Teln ...
- 小白也能玩转Git:从入门到实战详细教程
Git介绍 Git是一种分布式版本控制系统,它广泛应用于软件开发中.通过Git,开发人员可以追踪文件的变化.协作工作.管理代码库等.与集中式版本控制系统(如SVN)不同,Git使每个开发人员都具有完整 ...
- ps top命令查看内存空间
[root@VM-4-3-centos local]# ps aux --sort -rss | head USER PID %CPU %MEM VSZ RSS TTY STAT START TIME ...