机器学习:详解什么是端到端的深度学习?(What is end-to-end deep learning?)
什么是端到端的深度学习?
深度学习中最令人振奋的最新动态之一就是端到端深度学习的兴起,那么端到端学习到底是什么呢?简而言之,以前有一些数据处理系统或者学习系统,它们需要多个阶段的处理。那么端到端深度学习就是忽略所有这些不同的阶段,用单个神经网络代替它。

来看一些例子,以语音识别为例,目标是输入\(x\),比如说一段音频,然后把它映射到一个输出\(y\),就是这段音频的听写文本。所以传统上,语音识别需要很多阶段的处理。首先会提取一些特征,一些手工设计的音频特征,也许听过MFCC,这种算法是用来从音频中提取一组特定的人工设计的特征。在提取出一些低层次特征之后,可以应用机器学习算法在音频片段中找到音位,所以音位是声音的基本单位,比如说“Cat”这个词是三个音节构成的,Cu-、Ah-和Tu-,算法就把这三个音位提取出来,然后将音位串在一起构成独立的词,然后将词串起来构成音频片段的听写文本。
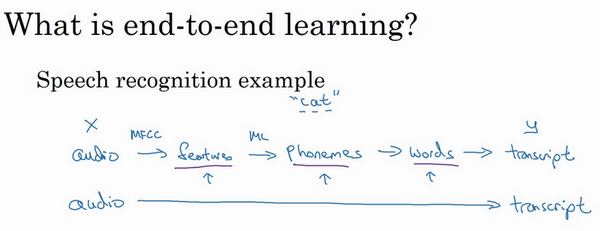
所以和这种有很多阶段的流水线相比,端到端深度学习做的是,训练一个巨大的神经网络,输入就是一段音频,输出直接是听写文本。AI的其中一个有趣的社会学效应是,随着端到端深度学习系统表现开始更好,有一些花了大量时间或者整个事业生涯设计出流水线各个步骤的研究员,还有其他领域的研究员,不只是语言识别领域的,也许是计算机视觉,还有其他领域,他们花了大量的时间,写了很多论文,有些甚至整个职业生涯的一大部分都投入到开发这个流水线的功能或者其他构件上去了。而端到端深度学习就只需要把训练集拿过来,直接学到了\(x\)和\(y\)之间的函数映射,直接绕过了其中很多步骤。对一些学科里的人来说,这点相当难以接受,他们无法接受这样构建AI系统,因为有些情况,端到端方法完全取代了旧系统,某些投入了多年研究的中间组件也许已经过时了。
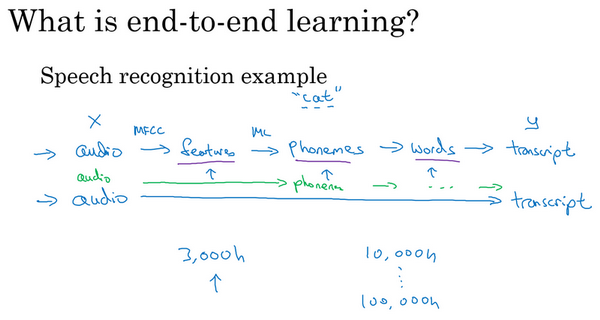
事实证明,端到端深度学习的挑战之一是,可能需要大量数据才能让系统表现良好,比如,只有3000小时数据去训练语音识别系统,那么传统的流水线效果真的很好。但当拥有非常大的数据集时,比如10,000小时数据或者100,000小时数据,这样端到端方法突然开始很厉害了。所以当数据集较小的时候,传统流水线方法其实效果也不错,通常做得更好。需要大数据集才能让端到端方法真正发出耀眼光芒。如果数据量适中,那么也可以用中间件方法,可能输入还是音频,然后绕过特征提取,直接尝试从神经网络输出音位,然后也可以在其他阶段用,所以这是往端到端学习迈出的一小步,但还没有到那里。

这张图上是一个研究员做的人脸识别门禁,是百度的林元庆研究员做的。这是一个相机,它会拍下接近门禁的人,如果它认出了那个人,门禁系统就自动打开,让他通过,所以不需要刷一个RFID工卡就能进入这个设施。系统部署在越来越多的办公室,可以接近门禁,如果它认出脸,它就直接让通过,不需要带RFID工卡。

那么,怎么搭建这样的系统呢?可以做的第一件事是,看看相机拍到的照片,对吧?想画的不太好,但也许这是相机照片,知道,有人接近门禁了,所以这可能是相机拍到的图像\(x\)。有件事可以做,就是尝试直接学习图像\(x\)到人物\(y\)身份的函数映射,事实证明这不是最好的方法。其中一个问题是,人可以从很多不同的角度接近门禁,他们可能在绿色位置,可能在蓝色位置。有时他们更靠近相机,所以他们看起来更大,有时候他们非常接近相机,那照片中脸就很大了。在实际研制这些门禁系统时,他不是直接将原始照片喂到一个神经网络,试图找出一个人的身份。
相反,迄今为止最好的方法似乎是一个多步方法,首先,运行一个软件来检测人脸,所以第一个检测器找的是人脸位置,检测到人脸,然后放大图像的那部分,并裁剪图像,使人脸居中显示,然后就是这里红线框起来的照片,再喂到神经网络里,让网络去学习,或估计那人的身份。
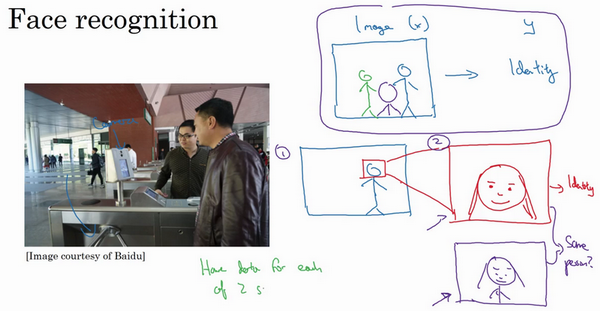
研究人员发现,比起一步到位,一步学习,把这个问题分解成两个更简单的步骤。首先,是弄清楚脸在哪里。第二步是看着脸,弄清楚这是谁。这第二种方法让学习算法,或者说两个学习算法分别解决两个更简单的任务,并在整体上得到更好的表现。
顺便说一句,如果想知道第二步实际是怎么工作的,这里其实省略了很多。训练第二步的方式,训练网络的方式就是输入两张图片,然后网络做的就是将输入的两张图比较一下,判断是否是同一个人。比如记录了10,000个员工ID,可以把红色框起来的图像快速比较……也许是全部10,000个员工记录在案的ID,看看这张红线内的照片,是不是那10000个员工之一,来判断是否应该允许其进入这个设施或者进入这个办公楼。这是一个门禁系统,允许员工进入工作场所的门禁。
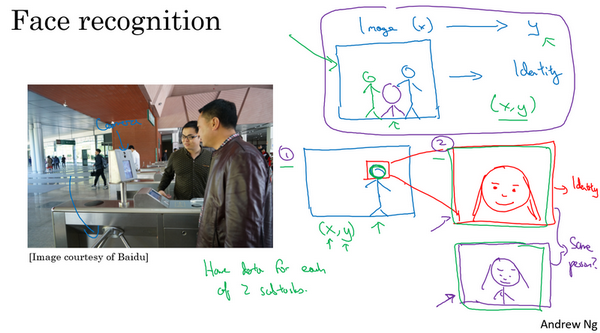
为什么两步法更好呢?实际上有两个原因。一是,解决的两个问题,每个问题实际上要简单得多。但第二,两个子任务的训练数据都很多。具体来说,有很多数据可以用于人脸识别训练,对于这里的任务1来说,任务就是观察一张图,找出人脸所在的位置,把人脸图像框出来,所以有很多数据,有很多标签数据\((x,y)\),其中\(x\)是图片,\(y\)是表示人脸的位置,可以建立一个神经网络,可以很好地处理任务1。然后任务2,也有很多数据可用,今天,业界领先的公司拥有,比如说数百万张人脸照片,所以输入一张裁剪得很紧凑的照片,比如这张红色照片,下面这个,今天业界领先的人脸识别团队有至少数亿的图像,他们可以用来观察两张图片,并试图判断照片里人的身份,确定是否同一个人,所以任务2还有很多数据。相比之下,如果想一步到位,这样\((x,y)\)的数据对就少得多,其中\(x\)是门禁系统拍摄的图像,\(y\)是那人的身份,因为没有足够多的数据去解决这个端到端学习问题,但却有足够多的数据来解决子问题1和子问题2。
实际上,把这个分成两个子问题,比纯粹的端到端深度学习方法,达到更好的表现。不过如果有足够多的数据来做端到端学习,也许端到端方法效果更好。但在今天的实践中,并不是最好的方法。
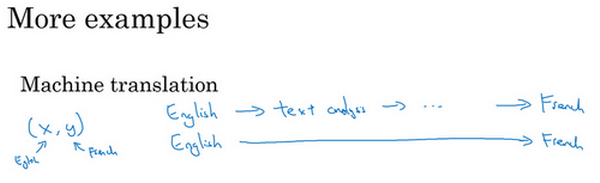
再来看几个例子,比如机器翻译。传统上,机器翻译系统也有一个很复杂的流水线,比如英语机翻得到文本,然后做文本分析,基本上要从文本中提取一些特征之类的,经过很多步骤,最后会将英文文本翻译成法文。因为对于机器翻译来说的确有很多(英文,法文)的数据对,端到端深度学习在机器翻译领域非常好用,那是因为在今天可以收集\(x-y\)对的大数据集,就是英文句子和对应的法语翻译。所以在这个例子中,端到端深度学习效果很好。
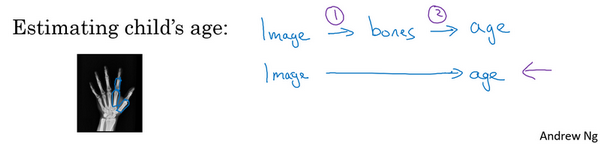
最后一个例子,比如说希望观察一个孩子手部的X光照片,并估计一个孩子的年龄。知道,当第一次听到这个问题的时候,以为这是一个非常酷的犯罪现场调查任务,可能悲剧的发现了一个孩子的骨架,想弄清楚孩子在生时是怎么样的。事实证明,这个问题的典型应用,从X射线图估计孩子的年龄,是想太多了,没有想象的犯罪现场调查脑洞那么大,结果这是儿科医生用来判断一个孩子的发育是否正常。
处理这个例子的一个非端到端方法,就是照一张图,然后分割出每一块骨头,所以就是分辨出那段骨头应该在哪里,那段骨头在哪里,那段骨头在哪里,等等。然后,知道不同骨骼的长度,可以去查表,查到儿童手中骨头的平均长度,然后用它来估计孩子的年龄,所以这种方法实际上很好。
相比之下,如果直接从图像去判断孩子的年龄,那么需要大量的数据去直接训练。据所知,这种做法今天还是不行的,因为没有足够的数据来用端到端的方式来训练这个任务。
可以想象一下如何将这个问题分解成两个步骤,第一步是一个比较简单的问题,也许不需要那么多数据,也许不需要许多X射线图像来切分骨骼。而任务二,收集儿童手部的骨头长度的统计数据,不需要太多数据也能做出相当准确的估计,所以这个多步方法看起来很有希望,也许比端对端方法更有希望,至少直到能获得更多端到端学习的数据之前。
所以端到端深度学习系统是可行的,它表现可以很好,也可以简化系统架构,让不需要搭建那么多手工设计的单独组件,但它也不是灵丹妙药,并不是每次都能成功。
机器学习:详解什么是端到端的深度学习?(What is end-to-end deep learning?)的更多相关文章
- 【机器学习详解】SMO算法剖析(转载)
[机器学习详解]SMO算法剖析 转载请注明出处:http://blog.csdn.net/luoshixian099/article/details/51227754 CSDN−勿在浮沙筑高台 本文力 ...
- 机器学习 | 详解GBDT在分类场景中的应用原理与公式推导
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第31篇文章,我们一起继续来聊聊GBDT模型. 在上一篇文章当中,我们学习了GBDT这个模型在回归问题当中的原理.GBD ...
- 代码详解:TensorFlow Core带你探索深度神经网络“黑匣子”
来源商业新知网,原标题:代码详解:TensorFlow Core带你探索深度神经网络“黑匣子” 想学TensorFlow?先从低阶API开始吧~某种程度而言,它能够帮助我们更好地理解Tensorflo ...
- TVM:一个端到端的用于开发深度学习负载以适应多种硬件平台的IR栈
TVM:一个端到端的用于开发深度学习负载以适应多种硬件平台的IR栈 本文对TVM的论文进行了翻译整理 深度学习如今无处不在且必不可少.这次创新部分得益于可扩展的深度学习系统,比如 TensorFlo ...
- zabbix配置文件详解--服务(server)端、客户(agent)端、代理(proxy)端
在zabbix服务(server)端.客户(agent)端.代理(proxy)端分别对应着一个配置文件,即:zabbix_server.conf,zabbix_agentd.conf,zabbix_p ...
- 详解APM数据采样与端到端
高驰涛 云智慧首席架构师 据云智慧统计,APM从客户端采集的性能数据可能占到业务数据的50%,而企业要做到从Request到Response整个链路中涉及到的所有数据的准确采集,并进行有效串接,进而实 ...
- 机器学习--详解人脸对齐算法SDM-LBF
引自:http://blog.csdn.net/taily_duan/article/details/54584040 人脸对齐之SDM(Supervised Descent Method) 人脸对齐 ...
- 机器学习——详解经典聚类算法Kmeans
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第12篇文章,我们一起来看下Kmeans聚类算法. 在上一篇文章当中我们讨论了KNN算法,KNN算法非常形象,通过距离公 ...
- 机器学习 | 详解GBDT梯度提升树原理,看完再也不怕面试了
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第30篇文章,我们今天来聊一个机器学习时代可以说是最厉害的模型--GBDT. 虽然文无第一武无第二,在机器学习领域并没有 ...
- ActiveMQ基本详解与总结& 消息队列-推/拉模式学习 & ActiveMQ及JMS学习
转自:https://www.cnblogs.com/Survivalist/p/8094069.html ActiveMQ基本详解与总结 基本使用可以参考https://www.cnblogs.co ...
随机推荐
- Django——form组件的局部钩子
如果对字段的校验条件太少,不能满足我们的需求,那么,我们可以对每个字段自定义校验的内容,就可以使用局部钩子. 局部钩子的使用方法: (1)导入错误类型 ----> 我们自己定义的钩子抛出的错误也 ...
- C# wpf 实现Converter定义与使用
1. 本身的值0, 如何转换为"男" 或"女"呢,可以定义sexConverter继承自IValueConverter即可,代码如下: [ValueConve ...
- .Net6 winform 程序使用依赖注入
.net Blazor webassembly 和 webAPI 内建支持依赖注入, Winform 和 Console 应用虽然不带有依赖注入功能, 但增加依赖注入也很简单. 本文将示例如何为 Wi ...
- 用 AI 速读海量文档!5款 AI 阅读工具推荐
在当今信息爆炸的时代,我们在手动搜集和处理信息时面临着几个挑战: 浩如烟海的信息量远远超出了我们的阅读能力. 信息的复杂性要求我们重复筛选和过滤. 专业或难以理解的内容需要被翻译成易懂的语言. 需要从 ...
- 腾讯蓝鲸平台部署v5.1版本[去坑]
腾讯蓝鲸平台部署 1. 环境准备 #1. 基础优化 ulimit -SHn 655360 yum remove mysql-devel -y && yum install mysql- ...
- NOIP模拟58
T1 Lesson5 ! 解题思路 首先对于整张图求出拓扑序,然后顺着拓扑序其实也就是顺着边的方向,更新最长路,也就是从 1 节点到达这个节点的最长路. 然后再逆着拓扑序,反向求一下最长路,也就是从这 ...
- NOIP模拟55
T1 Skip 解题思路 正解给的是线段树维护单调栈,但是我不会.. CDQ 维护斜率可做!!! 先得出一个朴素的 DP 方程:设 \(f_i\) 表示最后一场是 i 的最优解. 转移方程就是 \(f ...
- c#使用webView2 访问本地静态html资源跨域Cors问题 (附带代理服务helper帮助类)
背景 在浏览器中访问本地静态资源html网页时,可能会遇到跨域问题如图. 是因为浏览器默认启用了同源策略,即只允许加载与当前网页具有相同源(协议.域名和端口)的内容. WebView2默认情况下启用了 ...
- SDL3 入门(2):第一个窗口
在上一篇文章中我们已经利用 SDL 的日志接口实现了简单的字符串输出,实际上是解决了开发环境搭建问题,接下来我们将在已有代码的基础上继续开发,实现第一个窗口的创建和背景色绘制. 初始化 首先设置日志输 ...
- R语言求取大量遥感影像的平均值、标准差:raster库
本文介绍基于R语言中的raster包,批量读取多张栅格图像,对多个栅格图像计算平均值.标准差,并将所得新的栅格结果图像保存的方法. 在文章基于R语言的raster包读取遥感影像中,我们介绍了基 ...