深度学习应用篇-元学习[14]:基于优化的元学习-MAML模型、LEO模型、Reptile模型
深度学习应用篇-元学习[14]:基于优化的元学习-MAML模型、LEO模型、Reptile模型
1.Model-Agnostic Meta-Learning
Model-Agnostic Meta-Learning (MAML):
与模型无关的元学习,可兼容于任何一种采用梯度下降算法的模型。
MAML 通过少量的数据寻找一个合适的初始值范围,从而改变梯度下降的方向,
找到对任务更加敏感的初始参数,
使得模型能够在有限的数据集上快速拟合,并获得一个不错的效果。
该方法可以用于回归、分类以及强化学习。
该模型的Paddle实现请参考链接:PaddleRec版本
1.1 MAML
MAML 是典型的双层优化结构,其内层和外层的优化方式如下:
1.1.1 MAML 内层优化方式
内层优化涉及到基学习器,从任务分布 $p(T)$ 中随机采样第 $i$ 个任务 $T_{i}$。任务 $T_{i}$ 上,基学习器的目标函数是:
$$
\min {\phi} L{T_{i}}\left(f_{\phi}\right)
$$
其中,$f_{\phi}$ 是基学习器,$\phi$ 是基学习器参数,$L_{T_{i}}\left(f_{\phi}\right)$ 是基学习器在 $T_{i}$ 上的损失。更新基学习器参数:
$$
\theta_{i}{N}=\theta_{i}-\alpha\left[\nabla_{\phi}
L_{T_{i}}\left(f_{\phi}\right)\right]{\phi=\theta^{N-1}}
$$
其中,$\theta$ 是元学习器提供给基学习器的参数初始值 $\phi=\theta$,在任务 $T_{i}$ 上更新 $N$ 后 $\phi=\theta_{i}^{N-1}$.
1.1.2 MAML 外层优化方式
外层优化涉及到元学习器,将 $\theta_{i}^{N}$ 反馈给元学匀器,此时元目标函数是:
$$
\min {\theta} \sum\sim p(T)} L_{T_{i}}\left(f_{\theta_{i}^{N}}\right)
$$
元目标函数是所有任务上验证集损失和。更新元学习器参数:
$$
\theta \leftarrow \theta-\beta \sum_{T_{i} \sim p(T)} \nabla_{\theta}\left[L_{T_{i}}\left(f_{\phi}\right)\right]{\phi=\theta^{N}}
$$
1.2 MAML 算法流程
- randomly initialize $\theta$
- while not done do:
- sample batch of tasks $T_i \sim p(T)$
- for all $T_i$ do:
- evaluate $\nabla_{\phi}L_{T_{i}}\left(f_{\phi}\right)$ with respect to K examples
- compute adapted parameters with gradient descent: $\theta_{i}{N}=\theta_{i} -\alpha\left[\nabla_{\phi}L_{T_{i}}\left(f_{\phi}\right)\right]{\phi=\theta^{N-1}} $
- end for
- update $\theta \leftarrow \theta-\beta \sum_{T_{i} \sim p(T)} \nabla_{\theta}\left[L_{T_{i}}\left(f_{\phi}\right)\right]{\phi=\theta^{N}} $
- end while
MAML 中执行了两次梯度下降 (gradient by gradient),分别作用在基学习器和元学习器上。图1给出了 MAML 中特定任务参数 $\theta_{i}^{*}$ 和元级参数 $\theta$ 的更新过程。
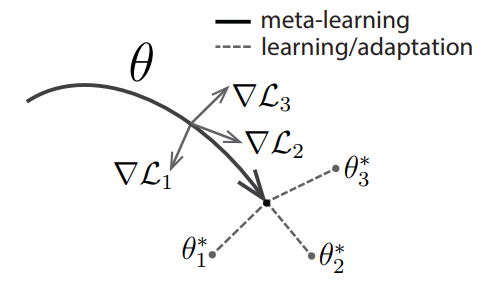
图1 MAML 示意图。灰色线表示特定任务所产生的梯度值(方向);黑色线表示元级参数选择更新的方向(黑色线方向是几个特定任务产生方向的平均值);虚线代表快速适应,不同的方向代表不同任务更新的方向。
1.3 MAML 模型结构
MAML 是一种与模型无关的元学习方法,可以适用于任何基于梯度优化的模型结构。
基准模型:4 modules with a 3 $\times$ 3 convolutions and 64 filters,
followed by batch normalization,
a ReLU nonlinearity,
and 2 $\times$ 2 max-pooling。
1.4 MAML 分类结果
表1 MAML 在 Omniglot 上的分类结果。
| Method | 5-way 1-shot | 5-way 5-shot | 20-way 1-shot | 20-way 5-shot |
|---|---|---|---|---|
| MANN, no conv (Santoro et al., 2016) | 82.8 $%$ | 94.9 $%$ | -- | -- |
| MAML, no conv | 89.7 $\pm$ 1.1 $%$ | 97.5 $\pm$ 0.6 $%$ | -- | -- |
| Siamese nets (Koch, 2015) | 97.3 $%$ | 98.4 $%$ | 88.2 $%$ | 97.0 $%$ |
| matching nets (Vinyals et al., 2016) | 98.1 $%$ | 98.9 $%$ | 93.8 $%$ | 98.5 $%$ |
| neural statistician (Edwards & Storkey, 2017) | 98.1 $%$ | 99.5 $%$ | 93.2 $%$ | 98.1 $%$ |
| memory mod. (Kaiser et al., 2017) | 98.4 $%$ | 99.6 $%$ | 95.0 $%$ | 98.6 $%$ |
| MAML | 98.7 $\pm$ 0.4 $%$ | 99.9 $\pm$ 0.1 $%$ | 95.8 $\pm$ 0.3 $%$ | 98.9 $\pm$ 0.2 $%$ |
表1 MAML 在 miniImageNet 上的分类结果。
| Method | 5-way 1-shot | 5-way 5-shot |
|---|---|---|
| fine-tuning baseline | 28.86 $\pm$ 0.54 $%$ | 49.79 $\pm$ 0.79 $%$ |
| nearest neighbor baseline | 41.08 $\pm$ 0.70 $%$ | 51.04 $\pm$ 0.65 $%$ |
| matching nets (Vinyals et al., 2016) | 43.56 $\pm$ 0.84 $%$ | 55.31 $\pm$ 0.73 $%$ |
| meta-learner LSTM (Ravi & Larochelle, 2017) | 43.44 $\pm$ 0.77 $%$ | 60.60 $\pm$ 0.71 $%$ |
| MAML, first order approx. | 48.07 $\pm$ 1.75 $%$ | 63.15 $\pm$ 0.91 $%$ |
| MAML | 48.70 $\pm$ 1.84 $%$ | 63.11 $\pm$ 0.92 $%$ |
1.5 MAML 的优缺点
优点
适用于任何基于梯度优化的模型结构。
双层优化结构,提升模型精度和泛化能力,避免过拟合。
缺点
- 存在二阶导数计算
1.6 对 MAML 的探讨
每个任务上的基学习器必须是一样的,对于差别很大的任务,最切合任务的基学习器可能会变化,那么就不能用 MAML 来解决这类问题。
MAML 适用于所有基于随机梯度算法求解的基学习器,这意味着参数都是连续的,无法考虑离散的参数。对于差别较大的任务,往往需要更新网络结构。使用 MAML 无法完成这样的结构更新。
MAML 使用的损失函数都是可求导的,这样才能使用随机梯度算法来快速优化求解,损失函数中不能有不可求导的奇异点,否则会导致优化求解不稳定。
MAML 中考虑的新任务都是相似的任务,所以没有对任务进行分类,也没有计算任务之间的距离度量。对每一类任务单独更新其参数初始值,每一类任务的参数初始值不同,这些在 MAML 中都没有考虑。
- 参考文献
[1] Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks.
2.Latent Embedding Optimization
Latent Embedding Optimization (LEO) 学习模型参数的低维潜在嵌入,并在这个低维潜在空间中执行基于优化的元学习,将基于梯度的自适应过程与模型参数的基础高维空间分离。
2.1 LEO
在元学习器中,使用 SGD 最小化任务验证集损失函数,
使得模型的泛化能力最大化,计算元参数,元学习器将元参数输入基础学习器,
继而,基础学习器最小化任务训练集损失函数,快速给出任务上的预测结果。
LEO 结构如图1所示。
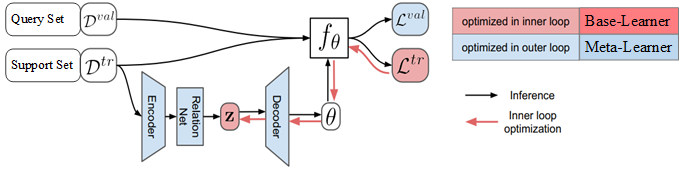
图1 LEO 结构图。$D^{\mathrm{tr}}$ 是任务 $\varepsilon$ 的 support set,
$D^{\mathrm{val}}$ 是任务 $\varepsilon$ 的 query set,
$z$ 是通过编码器计算的 $N$ 个类别的类别特征,$f_{\theta}$ 是基学习器,
$\theta$ 是基学习器参数,
$L^{\mathrm{tr}}=f_{\theta}\left( D^{\mathrm{tr}}\right)$, $L^{\mathrm{val}}=f_{\theta}\left( D^{\mathrm{val}}\right)$。
LEO 包括基础学习器和元学习器,还包括编码器和解码器。
在基础学习器中,编码器将高维输入数据映射成特征向量,
解码器将输入数据的特征向量映射成输入数据属于各个类别的概率值,
基础学习器使用元学习器提供的元参数进行参数更新,给出数据标注的预测结果。
元学习器为基础学习器的编码器和解码器提供元参数,
元参数包括特征提取模型的参数、编码器的参数、解码器的参数等,
通过最小化所有任务上的泛化误差,更新元参数。
2.2 基础学习器
编码器和解码器都在基础学习器中,用于计算输入数据属于每个类别的概率值,
进而对输入数据进行分类。
元学习器提供编码器和解码器中的参数,基础学习器快速的使用编码器和解码器计算输入数据的分类。
任务训练完成后,基础学习器将每个类别数据的特征向量和任务 $\varepsilon$ 的基础学习器参数 $\boldsymbol{\theta}_{\varepsilon}$ 输入元学习器,
元学习器使用这些信息更新元参数。
2.2.1 编码器
编码器模型包括两个主要部分:编码器和关系网络。
编码器 $g_{\phi_{e}}$ ,其中 $\phi_{e}$ 是编码器的可训练参数,
其功能是将第 $n$ 个类别的输入数据映射成第 $n$ 个类别的特征向量。
关系网络 $g_{\phi_{r}}$ ,其中 $\phi_{r}$ 是关系网络的可训练参数,
其功能是计算特征之间的距离。
第 $n$ 个类别的输入数据的特征记为 $z_{n}$ 。
对于输入数据,首先,使用编码器 $g_{\phi_{e}}$ 对属于第 $n$ 个类别的输入数据进行特征提取;
然后,使用关系网络 $g_{\phi_r}$ 计算特征之间的距离,
综合考虑训练集中所有样本点之间的距离,计算这些距离的平均值和离散程度;
第 $n$ 个类别输入数据的特征 $z_{n}$ 服从高斯分布,
且高斯分布的期望是这些距离的平均值,高斯分布的方差是这些距离的离散程度,
具体的计算公式如下:
$$
\begin{aligned}
&\mu_{n}^{e}, \sigma_{n}^{e}=\frac{1}{N K^{2}} \sum_{k_{n}=1}^{K} \sum_{m=1}^{N} \sum_{k_{m}=1}^{K} g_{\phi_{r}}\left[g_{\phi_{e}}\left(x_{n}^{k_{n}}\right), g_{\phi_{e}}\left(x_{m}^{k_{m}}\right)\right] \
&z_{n} \sim q\left(z_{n} \mid D_{n}{\mathrm{tr}}\right)=N\left{\mu_{n}, \operatorname{diag}\left(\sigma_{n}{e}\right)\right}
\end{aligned}
$$
其中,$N$ 是类别总数, $K$ 是每个类别的图片总数,
${D}{n}^{\mathrm{tr}}$ 是第 $n$ 个类别的训练数据集。
对于每个类别的输入数据,每个类别下有 $K$ 张图片,
计算这 $K$ 张图片和所有已知图片之间的距离。
总共有 $N$ 个类别,通过编码器的计算,形成所有类别的特征,
记为 $z=\left(z, \cdots, z_{N}\right)$。
2.2.2 解码器
解码器 $g_{\phi_{d}}$ ,其中 $\phi_{d}$ 是解码器的可训练参数,
其功能是将每个类别输入数据的特征向量 $z_{n}$
映射成属于每个类别的概率值 $\boldsymbol{w}_{n}$:
$$
\begin{aligned}
&\mu_{n}^{d}, \sigma_{n}^{d}=g_{\phi_{d}}\left(z_{n}\right) \
&w_{n} \sim q\left(w \mid z_{n}\right)=N\left{\mu_{n}^{d}, \operatorname{diag}\left(\sigma_{n}{d}\right)\right}
\end{aligned}
$$
其中,任务 $\varepsilon$ 的基础学习器参数记为 $\theta_{\varepsilon}$,
基础学习器参数由属于每个类别的概率值组成,
记为 $\theta_{\varepsilon}=\left(w_{1}, w_{2}, \cdots, w_{N}\right)$,
基础学习器参数 $\boldsymbol{w}{n}$ 指的是输入数据属于第 $n$ 个类别的概率值,
$g{\phi_{d}}$ 是从特征向量到基础学习器参数的映射。
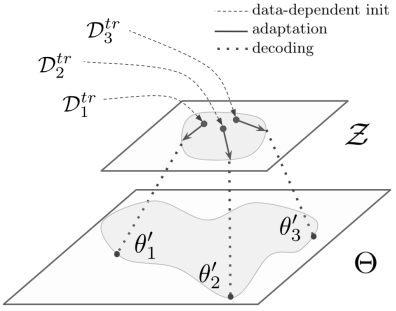
图2 LEO 基础学习器工作原理图。
2.2.3 基础学习器更新过程
在基础学习器中,任务 $\varepsilon$ 的交叉熵损失函数是:
$$
L_{\varepsilon}^{\mathrm{tr}}\left(f_{\theta_{\varepsilon}}\right)=\sum_{(x, y) \in D_{\varepsilon}^{\mathrm{tr}}}\left[-w_{y} \boldsymbol{x}+\log \sum_{j=1}^{N} \mathrm{e}^{w_{j} x}\right]
$$
其中,$(x, y)$ 是任务 $\varepsilon$ 训练集 $D_{\varepsilon}^{\mathrm{tr}}$ 中的样本点,$f_{\theta_{\varepsilon}}$ 是任务 $\varepsilon$ 的基础学习器,
最小化任务 $\varepsilon$ 的损失函数更新任务专属参数 $\theta_{\varepsilon}$ 。
在解码器模型中,任务专属参数为 $w_{n} \sim q\left(w \mid z_{n}\right)$,
更新任务专属参数 $\theta_{\varepsilon}$ 意味着更新特征向量 $z_{n}$:
$$
z_{n}^{\prime}=z_{n}-\alpha \nabla_{z_{n}} L_{\varepsilon}^{t r}\left(f_{\theta_{\varepsilon}}\right),
$$
其中,$\boldsymbol{z}{n}^{\prime}$ 是更新后的特征向量,
对应的是更新后的任务专属参数 $\boldsymbol{\theta}^{\prime}$。
基础学习器使用 $\theta_{\varepsilon}^{\prime}$ 来预测任务验证集数据的标注,
将任务 $\varepsilon$ 的验证集 $\mathrm{D}{\varepsilon}^{\mathrm{val}}$
损失函数 $L{\mathrm{val}}\left(f_{\theta_{\varepsilon}{\prime}}\right)$ 、
更新后的特征向量 $z_{n}^{\prime}$、
更新后的任务专属参数 $\theta_{\varepsilon}^{\prime}$ 输入元学习器,
在元学习器中更新元参数。
2.3 元学习器更新过程
在元学习器中,最小化所有任务 $\varepsilon$ 的验证集的损失函数的求和,
最小化任务上的模型泛化误差:
$$
\min {\phi, \phi_{r}, \phi_{d}} \sum_{\varepsilon}\left[L_{\varepsilon}{\mathrm{val}}\left(f_{\theta_{\varepsilon}{\prime}}\right)+\beta D_{\mathrm{KL}}\left{q\left(z_{n} \mid {D}{n}^{\mathrm{tr}}\right) | p\left(z\right)\right}+\gamma\left|s\left(\boldsymbol{z}_{n}{\prime}\right)-\boldsymbol{z}_{n}\right|_{2}\right]+R
$$
其中, $L_{\varepsilon}{\mathrm{val}}\left(f_{\theta_{\varepsilon}{\prime}}\right)$ 是任务 $\varepsilon$ 验证集的损失函数,
衡量了基础学习器模型的泛化误差,损失函数越小,模型的泛化能力越好。
$p\left(z_{n}\right)=N(0, I)$ 是高斯分布,$D_{\mathrm{KL}}\left{q\left(z_{n} \mid {D}{n}^{\mathrm{tr}}\right) | p\left(z\right)\right}$ 是近似后验分布 $q\left(z_{n} \mid D_{n}^{\text {tr }}\right)$ 与先验分布 $p\left(z_{n}\right)$ 之间的 KL 距离 (KL-Divergence),
最小化 $\mathrm{KL}$ 距离可使后验分布 $q\left(z_{n} \mid {D}{n}^{\text {tr}}\right)$ 的估计尽可能准确。
最小化距离 $\left|s\left(z^{\prime}\right)-z_{n}\right|$ 使得参数初始值 $z_{n}$ 和训练完成后的参数更新值 $z_{n}^{\prime}$ 距离最小,
使得参数初始值和参数最终值更接近。
$R$ 是正则项, 用于调控元参数的复杂程度,避免出现过拟合,正则项 $R$ 的计算公式如下:
$$
R=\lambda_{1}\left(\left|\phi_{e}\right|{2}{2}+\left|\phi_{r}\right|_{2}+\left|\phi\right|{2}^{2}\right)+\lambda\left|C_{d}-\mathbb{I}\right|_{2}
$$
其中, $\left|\phi_{r}\right|{2}^{2}$ 指的是调控元参数的个数和大小,
${C}$ 是参数 $\phi_{d}$ 的行和行之间的相关性矩阵,
超参数 $\lambda_{1},\lambda_{2}>0$,
$\left|C_{d}-\mathbb{I}\right|{2}$ 使得 $C$ 接近单位矩阵,
使得参数 $\phi_{d}$ 的行和行之间的相关性不能太大,
每个类别的特征向量之间的相关性不能太大,
属于每个类别的概率值之间的相关性也不能太大,分类要尽量准确。
2.4 LEO 算法流程
LEO 算法流程
- randomly initialize $\phi_{e}, \phi_{r}, \phi_{d}$
- let $\phi=\left{\phi_{e}, \phi_{r}, \phi_{d}, \alpha\right}$
- while not converged do:
- for number of tasks in batch do:
- sample task instance $\mathcal{T}_{i} \sim \mathcal{S}^{t r}$
- let $\left(\mathcal{D}^{t r}, \mathcal{D}^{v a l}\right)=\mathcal{T}_{i}$
- encode $\mathcal{D}^{t r}$ to z using $g_{\phi_{e}}$ and $g_{\phi_{r}}$
- decode $\mathbf{z}$ to initial params $\theta_{i}$ using $g_{\phi_{d}}$
- initialize $\mathbf{z}^{\prime}=\mathbf{z}, \theta_{i}^{\prime}=\theta_{i}$
- for number of adaptation steps do:
- compute training loss $\mathcal{L}{\mathcal{T}{i}}^{t r}\left(f_{\theta_{i}^{\prime}}\right)$
- perform gradient step w.r.t. $\mathbf{z}^{\prime}$:
- $\mathbf{z}^{\prime} \leftarrow \mathbf{z}^{\prime}-\alpha \nabla_{\mathbf{z}^{\prime}} \mathcal{L}{\mathcal{T}{i}}^{t r}\left(f_{\theta_{i}^{\prime}}\right)$
- decode $\mathbf{z}^{\prime}$ to obtain $\theta_{i}^{\prime}$ using $g_{\phi_{d}}$
- end for
- compute validation loss $\mathcal{L}{\mathcal{T}{i}}^{v a l}\left(f_{\theta_{i}^{\prime}}\right)$
- end for
- perform gradient step w.r.t $\phi$:$\phi \leftarrow \phi-\eta \nabla_{\phi} \sum_{\mathcal{T}{i}} \mathcal{L}{i}}^{v a l}\left(f^{\prime}}\right)$
- end while
(1) 初始化元参数:编码器参数 $\phi_{e}$、关系网络参数 $\phi_{r}$、解码器参数 $\phi_{d}$,
在元学习器中更新的元参数包括 $\phi=\left{\phi_e, \phi_r,\phi_d \right}$。
(2) 使用片段式训练模式,
随机抽取任务 $\varepsilon$, ${D}{\varepsilon}^{\mathrm{tr}}$ 是任务 $\varepsilon$ 的训练集,
${D}^{\mathrm{val}}$ 是任务 $\varepsilon$ 的验证集。
(3) 使用编码器 $g_{\phi_{e}}$ 和关系网络 $g_{\phi_{r}}$ 将任务 $\varepsilon$ 的训练集 $D_{\varepsilon}^{\mathrm{tr}}$ 编码成特征向量 $z$,
使用 解码器 $g_{\phi_{d}}$ 从特征向量映射到任务 $\varepsilon$ 的基础学习器参数 ${\theta}{\varepsilon}$,
基础学习器参数指的是输入数据属于每个类别的概率值向量;
计算任务 $\varepsilon$ 的训练集的损失函数 $L^{\mathrm{tr}}\left(f_{\theta_{\varepsilon}}\right)$,
最小化任务 $\varepsilon$ 的损失函数,更新每个类别的特征向量:
$$
z_{n}^{\prime}=z_{n}-\alpha \nabla_{z_{n}} L_{\varepsilon}^{\mathrm{tr}}\left(f_{\theta_{\varepsilon}}\right)
$$
使用解码器 $g_{\phi_{d}}$ 从更新后的特征向量映射到更新后的任务 $\varepsilon$ 的基础学习器参数 ${\theta}{\varepsilon}^{\prime}$;
计算任务 $\varepsilon$ 的验证集的损失函数 $L^{\text {val}}\left(f_{\theta_{s}^{\prime}}\right)$;
基础学习器将更新后的参数和验证集损失函数值输入元学习器。
(4) 更新元参数, $\phi \leftarrow \phi-\eta \nabla_{\phi} \sum_{\varepsilon} L_{\varepsilon}^{\text {val}}\left(f_{\theta_{\varepsilon}^{\prime}}\right)$,
最小化所有任务 $\varepsilon$ 的验证集的损失和,
将更新后的元参数输人基础学习器,继续处理新的分类任务。
2.5 LEO 模型结构
LEO 是一种与模型无关的元学习,[1] 中给出的各部分模型结构及参数如表1所示。
表1 LEO 各部分模型结构及参数。
| Part of the model | Architecture | Hiddenlayer | Shape of the output |
|---|---|---|---|
| Inference model ($f_{\theta}$) | 3-layer MLP with ReLU | 40 | (12, 5, 1) |
| Encoder | 3-layer MLP with ReLU | 16 | (12, 5, 16) |
| Relation Network | 3-layer MLP with ReLU | 32 | (12, $2\times 16$) |
| Decoder | 3-layer MLP with ReLU | 32 | (12, $2\times 1761$) |
2.6 LEO 分类结果
表1 LEO 在 miniImageNet 上的分类结果。
| Model | 5-way 1-shot | 5-way 5-shot |
|---|---|---|
| Matching networks (Vinyals et al., 2016) | 43.56 $\pm$ 0.84 $%$ | 55.31 $\pm$ 0.73 $%$ |
| Meta-learner LSTM (Ravi & Larochelle, 2017) | 43.44 $\pm$ 0.77 $%$ | 60.60 $\pm$ 0.71 $%$ |
| MAML (Finn et al., 2017) | 48.70 $\pm$ 1.84 $%$ | 63.11 $\pm$ 0.92 $%$ |
| LLAMA (Grant et al., 2018) | 49.40 $\pm$ 1.83 $%$ | -- |
| REPTILE (Nichol & Schulman, 2018) | 49.97 $\pm$ 0.32 $%$ | 65.99 $\pm$ 0.58 $%$ |
| PLATIPUS (Finn et al., 2018) | 50.13 $\pm$ 1.86 $%$ | -- |
| Meta-SGD (our features) | 54.24 $\pm$ 0.03 $%$ | 70.86 $\pm$ 0.04 $%$ |
| SNAIL (Mishra et al., 2018) | 55.71 $\pm$ 0.99 $%$ | 68.88 $\pm$ 0.92 $%$ |
| (Gidaris & Komodakis, 2018) | 56.20 $\pm$ 0.86 $%$ | 73.00 $\pm$ 0.64 $%$ |
| (Bauer et al., 2017) | 56.30 $\pm$ 0.40 $%$ | 73.90 $\pm$ 0.30 $%$ |
| (Munkhdalai et al., 2017) | 57.10 $\pm$ 0.70 $%$ | 70.04 $\pm$ 0.63 $%$ |
| DEML+Meta-SGD (Zhou et al., 2018) | 58.49 $\pm$ 0.91 $%$ | 71.28 $\pm$ 0.69 $%$ |
| TADAM (Oreshkin et al., 2018) | 58.50 $\pm$ 0.30 $%$ | 76.70 $\pm$ 0.30 $%$ |
| (Qiao et al., 2017) | 59.60 $\pm$ 0.41 $%$ | 73.74 $\pm$ 0.19 $%$ |
| LEO | 61.76 $\pm$ 0.08 $%$ | 77.59 $\pm$ 0.12 $%$ |
表1 LEO 在 tieredImageNet 上的分类结果。
| Model | 5-way 1-shot | 5-way 5-shot |
|---|---|---|
| MAML (deeper net, evaluated in Liu et al. (2018)) | 51.67 $\pm$ 1.81 $%$ | 70.30 $\pm$ 0.08 $%$ |
| Prototypical Nets (Ren et al., 2018) | 53.31 $\pm$ 0.89 $%$ | 72.69 $\pm$ 0.74 $%$ |
| Relation Net (evaluated in Liu et al. (2018)) | 54.48 $\pm$ 0.93 $%$ | 71.32 $\pm$ 0.78 $%$ |
| Transductive Prop. Nets (Liu et al., 2018) | 57.41 $\pm$ 0.94 $%$ | 71.55 $\pm$ 0.74 $%$ |
| Meta-SGD (our features) | 62.95 $\pm$ 0.03 $%$ | 79.34 $\pm$ 0.06 $%$ |
| LEO | 66.33 $\pm$ 0.05 $%$ | 81.44 $\pm$ 0.09 $%$ |
2.7 LEO 的优点
新任务的初始参数以训练数据为条件,这使得任务特定的适应起点成为可能。
通过将关系网络结合到编码器中,该初始化可以更好地考虑所有输入数据之间的联合关系。通过在低维潜在空间中进行优化,该方法可以更有效地适应模型的行为。
此外,通过允许该过程是随机的,可以表达在少数数据状态中存在的不确定性和模糊性。
3.Reptile
Reptil 是 MAML 的特例、近似和简化,主要解决 MAML 元学习器中出现的高阶导数问题。
因此,Reptil 同样学习网络参数的初始值,并且适用于任何基于梯度的模型结构。
在 MAML 的元学习器中,使用了求导数的算式来更新参数初始值,
导致在计算中出现了任务损失函数的二阶导数。
在 Reptile 的元学习器中,参数初始值更新时,
直接使用了任务上的参数估计值和参数初始值之间的差,
来近似损失函数对参数初始值的导数,进行参数初始值的更新,从而不会出现任务损失函数的二阶导数。
Peptile 有两个版本:Serial Version 和 Batched Version,两者的差异如下:
3.1 Serial Version Reptile
单次更新的 Reptile,每次训练完一个任务的基学习器,就更新一次元学习器中的参数初始值。
(1) 任务上的基学习器记为 $f_{\phi}$ ,其中 $\phi$ 是基学习器中可训练的参数,
$\theta$ 是元学习器提供给基学习器的参数初始值。
在任务 $T_{i}$ 上,基学习器的损失函数是 $L_{T_{i}}\left(f_{\phi}\right)$ ,
基学习器中的参数经过 $N$ 次迭代更新得到参数估计值:
$$
\theta_{i}^{N}=\operatorname{SGD}\left(L_{T_{i}}, {\theta}, {N}\right)
$$
(2) 更新元学习器中的参数初始值:
$$
\theta \leftarrow \theta+\varepsilon\left(\theta_{i}^{N}-\theta\right)
$$
Serial Version Reptile 算法流程
- initialize $\theta$, the vector of initial parameters
- for iteration=1, 2, ... do:
- sample task $T_i$, corresponding to loss $L_{T_i}$ on weight vectors $\theta$
- compute $\theta_{i}^{N}=\operatorname{SGD}\left(L_{T_{i}}, {\theta}, {N}\right)$
- update $\theta \leftarrow \theta+\varepsilon\left(\theta_{i}^{N}-\theta\right)$
- end for
3.2 Batched Version Reptile
批次更新的 Reptile,每次训练完多个任务的基学习器之后,才更新一次元学习器中的参数初始值。
(1) 在多个任务上训练基学习器,每个任务从参数初始值开始,迭代更新 $N$ 次,得到参数估计值。
(2) 更新元学习器中的参数初始值:
$$
\theta \leftarrow \theta+\varepsilon \frac{1}{n} \sum_{i=1}{n}\left(\theta_{i}-\theta\right)
$$
其中,$n$ 是指每次训练完 $n$ 个任务上的基础学习器后,才更新一次元学习器中的参数初始值。
Batched Version Reptile 算法流程
- initialize $\theta$
- for iteration=1, 2, ... do:
- sample tasks $T_1$, $T_2$, ... , $T_n$,
- for i=1, 2, ... , n do:
- compute $\theta_{i}^{N}=\operatorname{SGD}\left(L_{T_{i}}, {\theta}, {N}\right)$
- end for
- update $\theta \leftarrow \theta+\varepsilon \frac{1}{n} \sum_{i=1}{n}\left(\theta_{i}-\theta\right)$
- end for
3.3 Reptile 分类结果
表1 Reptile 在 Omniglot 上的分类结果。
| Algorithm | 5-way 1-shot | 5-way 5-shot | 20-way 1-shot | 20-way 5-shot |
|---|---|---|---|---|
| MAML + Transduction | 98.7 $\pm$ 0.4 $%$ | 99.9 $\pm$ 0.1 $%$ | 95.8 $\pm$ 0.3 $%$ | 98.9 $\pm$ 0.2 $%$ |
| $1^{st}$-order MAML + Transduction | 98.3 $\pm$ 0.5 $%$ | 99.2 $\pm$ 0.2 $%$ | 89.4 $\pm$ 0.5 $%$ | 97.9 $\pm$ 0.1 $%$ |
| Reptile | 95.32 $\pm$ 0.05 $%$ | 98.87 $\pm$ 0.02 $%$ | 88.27 $\pm$ 0.30 $%$ | 97.07 $\pm$ 0.12 $%$ |
| Reptile + Transduction | 97.97 $\pm$ 0.08 $%$ | 99.47 $\pm$ 0.04 $%$ | 89.36 $\pm$ 0.20 $%$ | 97.47 $\pm$ 0.10 $%$ |
表1 Reptile 在 miniImageNet 上的分类结果。
| Algorithm | 5-way 1-shot | 5-way 5-shot |
|---|---|---|
| MAML + Transduction | 48.70 $\pm$ 1.84 $%$ | 63.11 $\pm$ 0.92 $%$ |
| $1^{st}$-order MAML + Transduction | 48.07 $\pm$ 1.75 $%$ | 63.15 $\pm$ 0.91 $%$ |
| Reptile | 45.79 $\pm$ 0.44 $%$ | 61.98 $\pm$ 0.69 $%$ |
| Reptile + Transduction | 48.21 $\pm$ 0.69 $%$ | 66.00 $\pm$ 0.62 $%$ |
更多优质内容请关注公重号:汀丶人工智能

深度学习应用篇-元学习[14]:基于优化的元学习-MAML模型、LEO模型、Reptile模型的更多相关文章
- Linux学习初级篇-鸟哥的Linux私房菜 基础学习篇(第四版)
0.1.2 一切设计的起点:CPU的架构 由于CPU的内部是有一些微指令组成的,所以我们所使用的软件都是要经过CPU内部的微指令集来达成才行.那这些指令集的设计主要又被分为两种设计理念,这是目前世界上 ...
- 从.Net到Java学习第一篇——开篇
以前我常说,公司用什么技术我就学什么.可是对于java,我曾经一度以为“学java是不可能的,这辈子不可能学java的.”结果,一遇到公司转java,我就不得不跑路了,于是乎,回头一看N家公司交过社保 ...
- 深度学习实战篇-基于RNN的中文分词探索
深度学习实战篇-基于RNN的中文分词探索 近年来,深度学习在人工智能的多个领域取得了显著成绩.微软使用的152层深度神经网络在ImageNet的比赛上斩获多项第一,同时在图像识别中超过了人类的识别水平 ...
- 深度学习与计算机视觉(12)_tensorflow实现基于深度学习的图像补全
深度学习与计算机视觉(12)_tensorflow实现基于深度学习的图像补全 原文地址:Image Completion with Deep Learning in TensorFlow by Bra ...
- [源码解析] 深度学习分布式训练框架 horovod (14) --- 弹性训练发现节点 & State
[源码解析] 深度学习分布式训练框架 horovod (14) --- 弹性训练发现节点 & State 目录 [源码解析] 深度学习分布式训练框架 horovod (14) --- 弹性训练 ...
- 【深度学习 论文篇 02-1 】YOLOv1论文精读
原论文链接:https://gitee.com/shaoxuxu/DeepLearning_PaperNotes/blob/master/YOLOv1.pdf 笔记版论文链接:https://gite ...
- 深度学习入门篇--手把手教你用 TensorFlow 训练模型
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~ 作者:付越 导语 Tensorflow在更新1.0版本之后多了很多新功能,其中放出了很多用tf框架写的深度网络结构(https://git ...
- 基于sklearn的集成学习实战
集成学习投票法与bagging 投票法 sklearn提供了VotingRegressor和VotingClassifier两个投票方法.使用模型需要提供一个模型的列表,列表中每个模型采用tuple的 ...
- 第五篇 Getting Started with ORACLE EBS(开始学习ORACLE EBS)
第一篇介绍了ERP软件是供应链管理软件.告诉你这个软件改善或提升企业管理的切入点和着力点.有了着力点才能给力. 第二篇介绍了什么是咨询以及咨询工作共通的章法,告诉了你咨询的套路是什么,就像练习一套拳, ...
- Docker虚拟化实战学习——基础篇(转)
Docker虚拟化实战学习——基础篇 2018年05月26日 02:17:24 北纬34度停留 阅读数:773更多 个人分类: Docker Docker虚拟化实战和企业案例演练 深入剖析虚拟化技 ...
随机推荐
- Unable to create tempDir. java.io.tmpdir is set to /tmp
磁盘挂载后,启动报错 Unable to create tempDir. java.io.tmpdir is set to /tmp [2022-03-30 17:12:06.596] WARN [m ...
- 浅谈locust 性能压测使用
1. 基本介绍 Locust是一个开源的负载测试工具,用于模拟大量用户并发访问一个系统或服务,以评估其性能和稳定性.编写语言为Python,可通过Python来自定义构建性能压测场景脚本.Locust ...
- coredump文件生成,以及GDB工具使用
一.core dump文件生成 Core文件其实就是内存的映像,当程序崩溃时,存储内存的相应信息,主用用于对程序进行调试.当程序崩溃时便会产生core文件,其实准确的应该说是core dump 文件, ...
- Beyond Compare常用快捷键
[会话]菜单的功能与快捷键 [文件]菜单的功能与快捷键 [编辑]菜单的功能与快捷键 [搜索]菜单的功能与快捷键
- 采购订单创建、修改、审批增强ME21N/ME22N/ME28/ME29N
一.采购订单创建修改增强 BADI:ME_PROCESS_PO_CUST 通过POST方法中的参数im_header,获取对应的数据 订单头 "----------------------- ...
- #2102:A计划(DFS和BFS剪枝搜索)
题意: 有几个比较坑的地方总结一下, 很容易误解: 遇到#就必须走 #不消耗时间 #对面如果也是#也不能走, 要不然无限循环了 最短路径剪枝时, 发现不能走的#是要把两步都标注为-1并跳出 题解: 一 ...
- 版本升级 | v3.0.0卷起来了!多种特殊情况解析轻松拿捏!
在过往发行版的基础上,结合社区用户提供的大量反馈及研发小伙伴的积极探索,项目组对OpenSCA的解析引擎做了全方位的优化,v3.0.0版本正式发布啦~ 感谢所有用户的支持和信任~是很多人的一小步聚在一 ...
- 数字孪生智慧物流之 Web GIS 地图应用
前言 随着数字经济时代的来临,新一轮全球化进程速度加快,在大数据.人工智能.物联网等高新技术深度融合下,加快催化智慧物流发展,引领物流行业划入全新时代. 从物流运输到货物分拣再到站点配送,图扑软件数据 ...
- citespace 文献计量工具初探
先放几个教程: 知乎 - CiteSpace 使用教程 - 312 赞同 知乎 - CiteSpace 入门教程 - 949 赞同 简书 - 研究方法 | 用 CiteSpace 进行科学文献可视化分 ...
- SD-Host控制器设计架构
SD Host功能列表 SD Host挂接在SoC中,与外部的SD card进行交互 有控制寄存器和状态寄存器,SoC往往有CPU,通过CPU进行配置寄存器,有些SoC没有CPU,需要使用I2C或者S ...