3天上手Ascend C编程丨通过Ascend C编程范式实现一个算子实例
本文分享自华为云社区《3天上手Ascend C编程 | Day2 通过Ascend C编程范式实现一个算子实例》,作者:昇腾CANN 。
一、Ascend C编程范式
Ascend C编程范式把算子内部的处理程序,分成多个流水任务( stage ),以张量( Tensor)为数据载体,以队列 ( Queue ) 进行任务之间的通信与同步,以内存管理模块( Pipe ) 管理任务间的通信内存。
1、流水任务
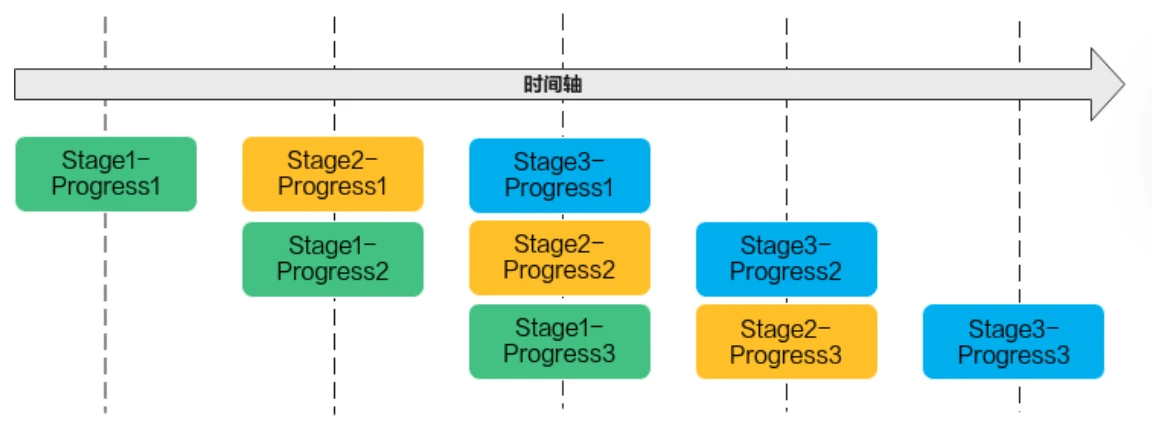
流水任务指的是单核处理程序中主程序调度的并行任务。在核函数内部,可以通过流水任务实现数据的并行处理,进一步提升性能。下面举例来说明,流水任务如何进行并行调度。以下面的流水任务示意图为例,单核处理程序的功能被拆分成3个流水任务:Stage1、Stage2、Stage3,每个任务专注于完成单一功能;需要处理的数据被切分成n片,使用Progress1~n表示,每个任务需要依次完成n个数据切片的处理。Stage间的箭头表达数据间的依赖关系,比如Stage1处理完Progress1之后,Stage2才能对Progress1进行处理。

若n=3,即待处理的数据被切分成3片,则上图中的流水任务运行起来的示意图如下,从运行图中可以看出,对于同一片数据,Stage1、Stage2、Stage3之间的处理具有依赖关系,需要串行处理;不同的数据切片,同一时间点,可以有多个任务在并行处理,由此达到任务并行、提升性能的目的。
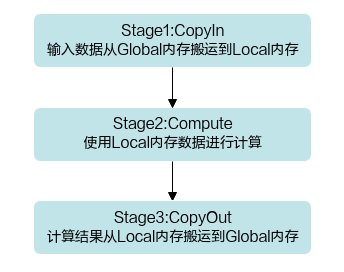
矢量(Vector)编程范式把算子的实现流程分为3个基本任务:CopyIn,Compute,CopyOut。CopyIn负责搬入操作,Compute负责矢量计算操作,CopyOut负责搬出操作。
2、任务间通信与同步
不同的流水任务之间存在数据依赖,需要进行数据传递。Ascend C中使用Queue队列完成任务之间的数据通信和同步,提供EnQue、DeQue等基础API。Queue队列管理NPU上不同层级的物理内存时,用一种抽象的逻辑位置(QuePosition)来表达各级别的存储,代替了片上物理存储的概念,开发者无需感知硬件架构。
矢量编程中使用到的逻辑位置(QuePosition)定义如下:
搬入数据的存放位置:VECIN搬出数据的存放位置:VECOUT矢量编程主要分为CopyIn、Compute、CopyOut三个任务:
CopyIn任务中将输入数据从Global内存搬运至Local内存后,需要使用EnQue将LocalTensor放入VECIN的Queue中;
Compute任务等待VECIN的Queue中LocalTensor出队之后才可以完成矢量计算,计算完成后使用EnQue将计算结果LocalTensor放入到VECOUT的Queue中;
CopyOut任务等待VECOUT的Queue中LocalTensor出队,再将其拷贝到Global内存。

Ascend C使用GlobalTensor和LocalTensor作为数据的基本操作单元,它是各种指令API直接调用的对象,也是数据的载体。
3、内存管理机制
任务间数据传递使用到的内存统一由内存管理模块Pipe进行管理。Pipe作为片上内存管理者,通过InitBuffer接口对外提供Queue内存初始化功能,开发者可以通过该接口为指定的Queue分配内存。
Queue队列内存初始化完成后,需要使用内存时,通过调用AllocTensor来为LocalTensor分配内存,当创建的LocalTensor完成相关计算无需再使用时,再调用FreeTensor来回收LocalTensor的内存。
编程过程中使用到的临时变量内存同样通过Pipe进行管理。临时变量可以使用TBuf数据结构来申请指定QuePosition上的存储空间,并使用Get()来将分配到的存储空间分配给新的LocaLTensor从TBuf上获取全部长度,或者获取指定长度的LocalTensor。
使用TBuf申请的内存空间只能参与计算,无法执行Queue队列的入队出队操作。
二、使用Ascend C编程范式实现一个算子实例
矢量算子开发一般开发流程如下:
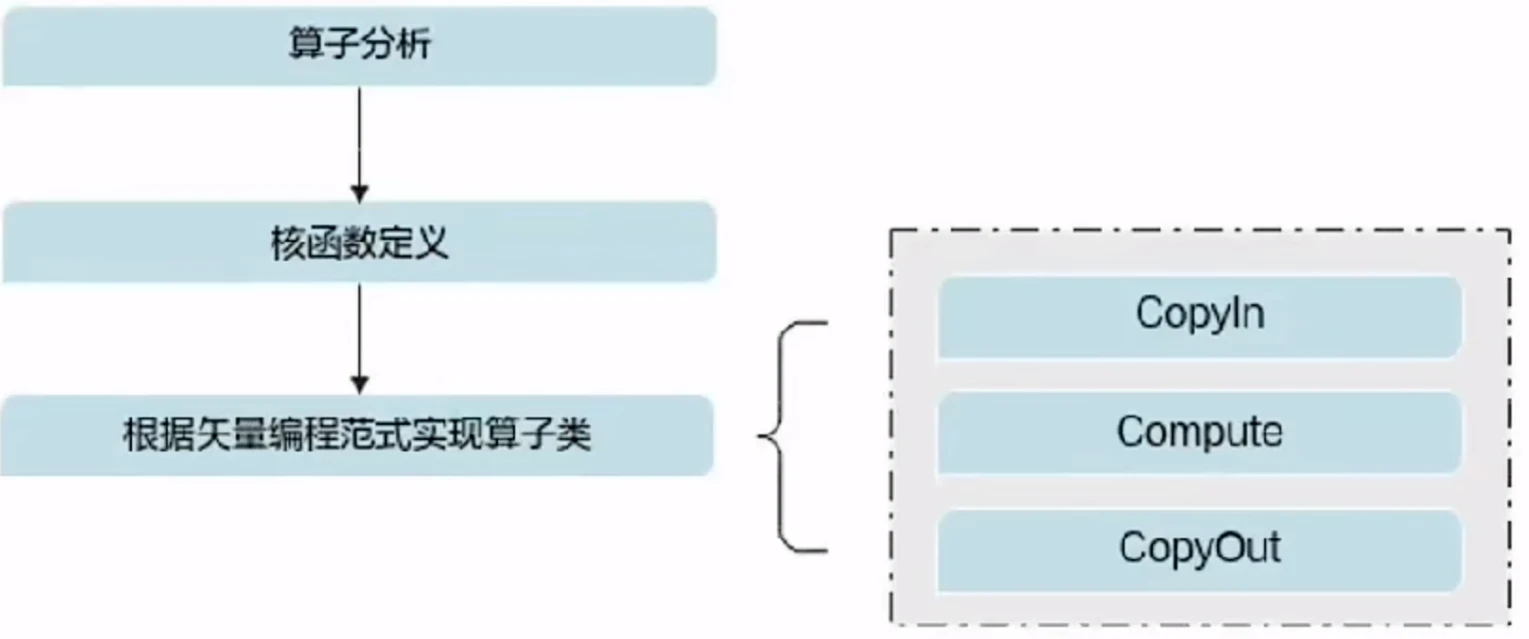
下面以add作为例子介绍Ascend C矢量算子的开发流程。完整样例大家可以参考代码样例。
1、算子分析
分析算子的数学表达式、输入、输出以及计算逻辑的实现,明确需要调用的Ascend C接口。
例子以Add算子为例,数学公式:z= x+y,为简单起见,设定输入张量x, y,z为固定shape(8,2048),数据类型dtype为half类型,数据排布类型format为ND,核函数名称为add_custom。

算子的数学表达式及计算逻辑。Add算子的数学表达式为:z = x + y;计算逻辑:输入数据需要先搬入到片上存储,然后使用计算接口完成两个加法运算,得到最终结果,再搬出到外部存储。
输入和输出。Add算子有两个输入:x与y,输出为z。输入数据类型为half,输出数据类型与输入数据类型相同。输入支持固定shape(8,2048)输出shape与输入shape相同,输入数据排布类型为ND。
确定核函数名称和参数。自定义核函数名,如add_custom。根据输入输出,确定核函数有3个入参x,y,z。x,y为输入在Global Memory上的内存地址,z为输出在Global Memory上的内存地址。
确定算子实现所需接口。涉及内外部存储间的数据搬运,使用数据搬移接口:Datacopy实现;涉及矢量计算的加法操作,使用矢量双目指令:Add实现;使用到LocalTensor,使用Queue队列管理,会使用到EnQue、DeQue等接口。
2、核函数定义
在add_custom核函数的实现中实例化kernelAdd算子类,调用Init()数完成内存初始化,调用Process()函数完成核心逻辑。
// 实现核函数
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{
// 初始化算子类,算子类提供算子初始化和核心处理等方法
KernelAdd op;
// 初始化函数,获取该核函数需要处理的输入输出地址,同时完成必要的内存初始化工作
op.Init(x, y, z);
// 核心处理函数,完成算子的数据搬运与计算等核心逻辑
op.Process();
}
3、根据矢量编程范式实现算子类
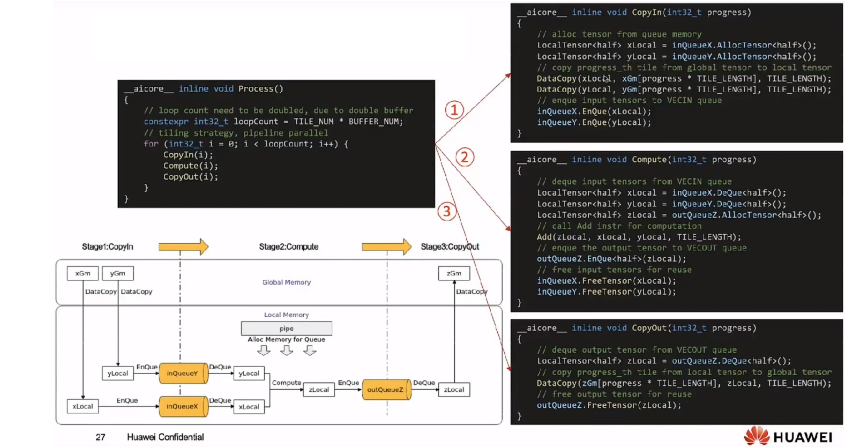
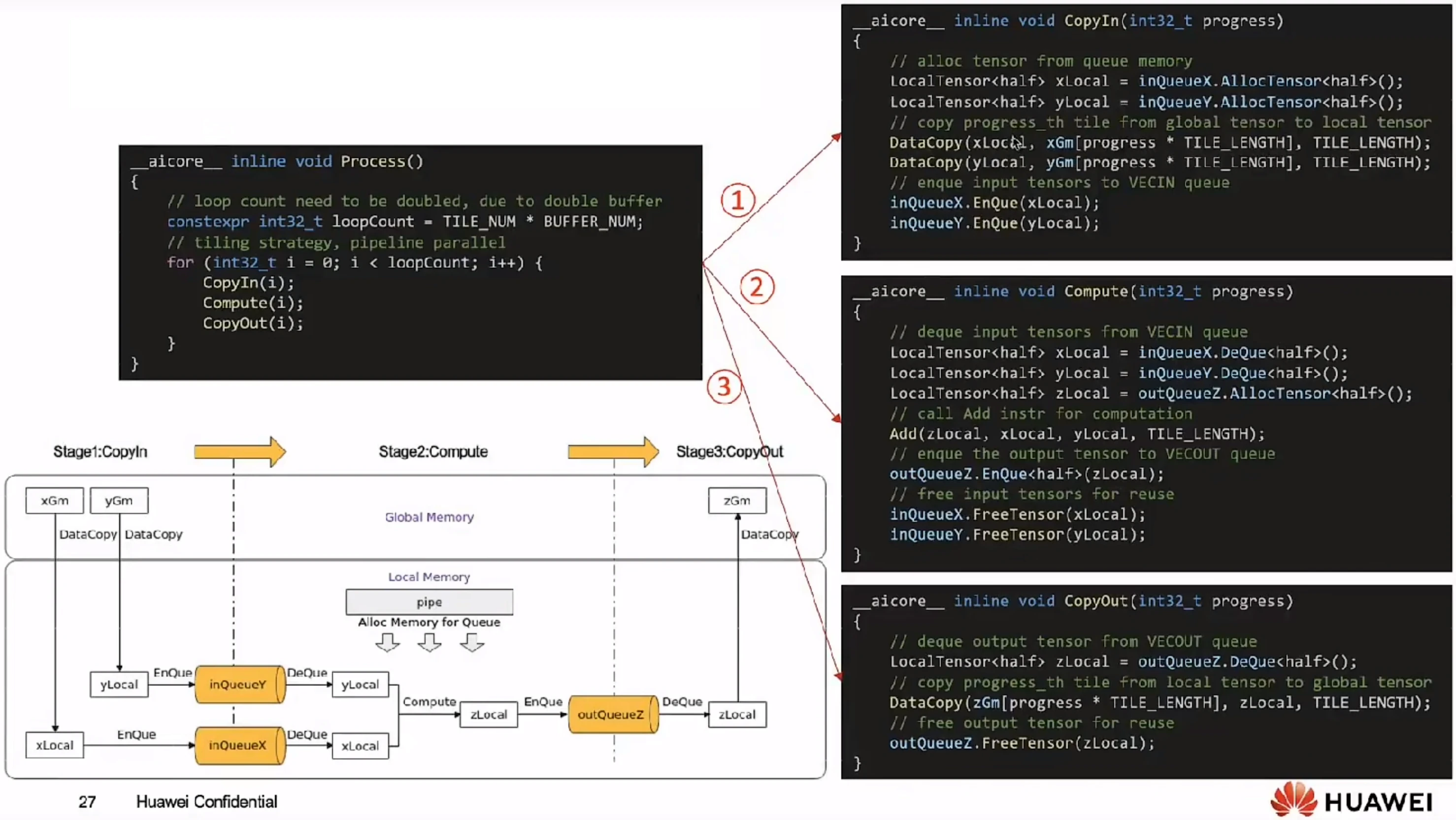
根据前面的知识,算子实现三个流水任务CopyIn、Compute、CopyOut。任务间通过队列VECIN、VECOUT进行通信和同步,由pipe内存管理对象对任务间交互使用到的内存、临时变量使用到的内存统一进行管理。如下图所示:
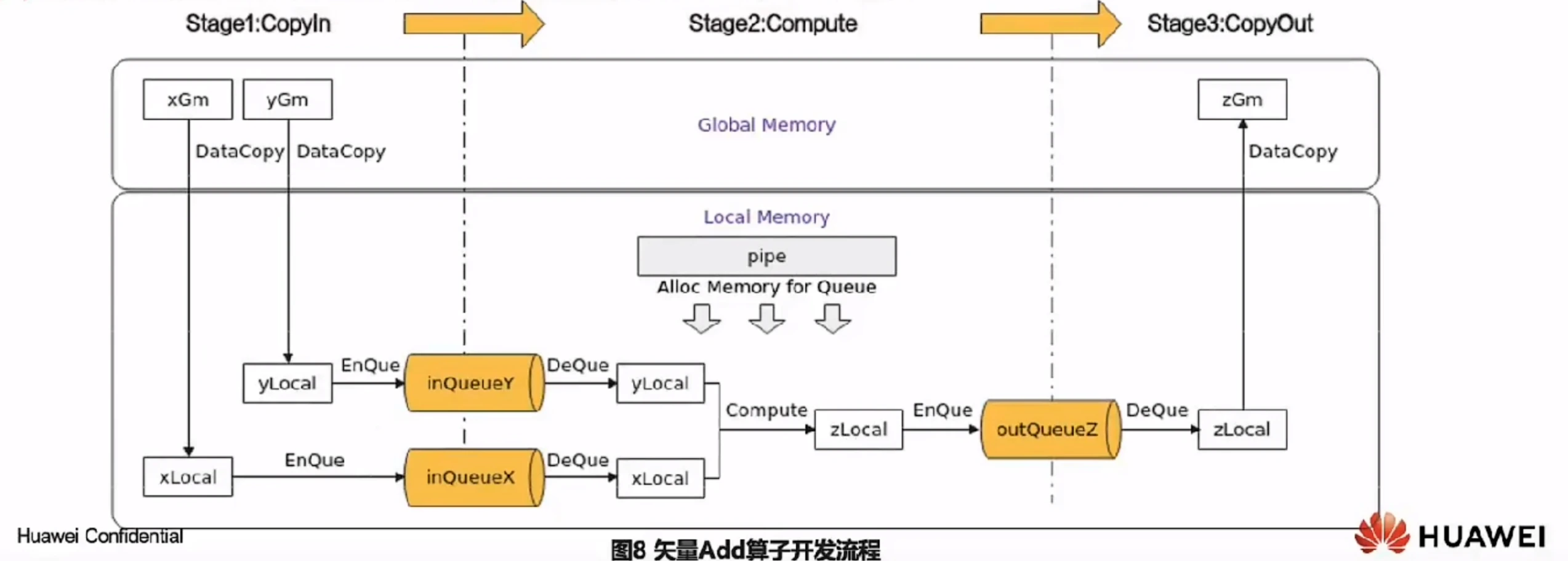
CopyIn任务:将Global Memory上的输入Tensor xGm和yGm搬运至Local Memory,分别存储在xLocal,yLocal;
Compute任务:对xLocal,yLocal执行加法操作,计算结果存储在zLocal中;
CopyOut任务:将输出数据从zLocal搬运至Global Memory上的输出Tensor zGm中
CopyIn,Compute任务间通过VECIN队列inQueuex,inQueuer进行通信和同步;compute,copyout任务间通过VECOUT队列outQueuez进行通信和同步。
第一步,我们进行算子类定义:
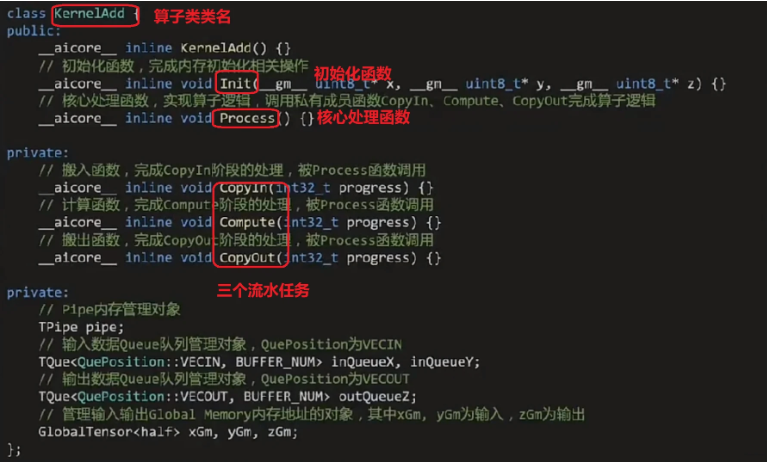
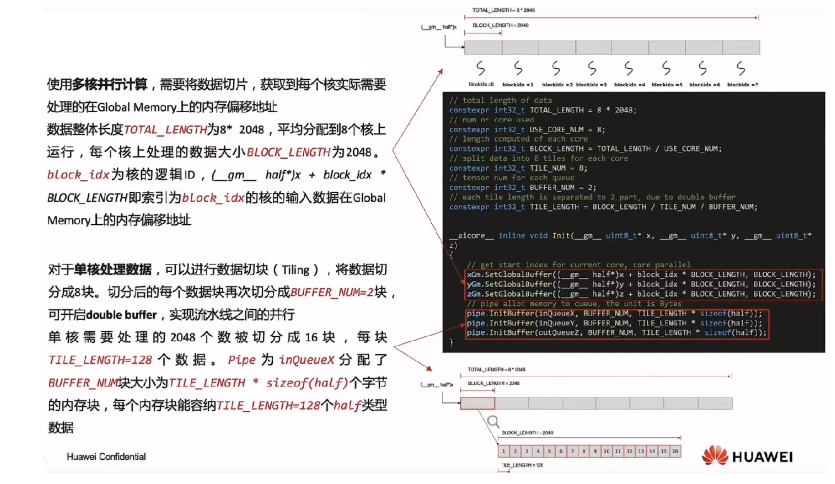
第二步,实现Init()函数:多核并行+单核处理数据:
第三步,实现Process()函数——CopyIn,Compute、CopyOut三个流水任务:
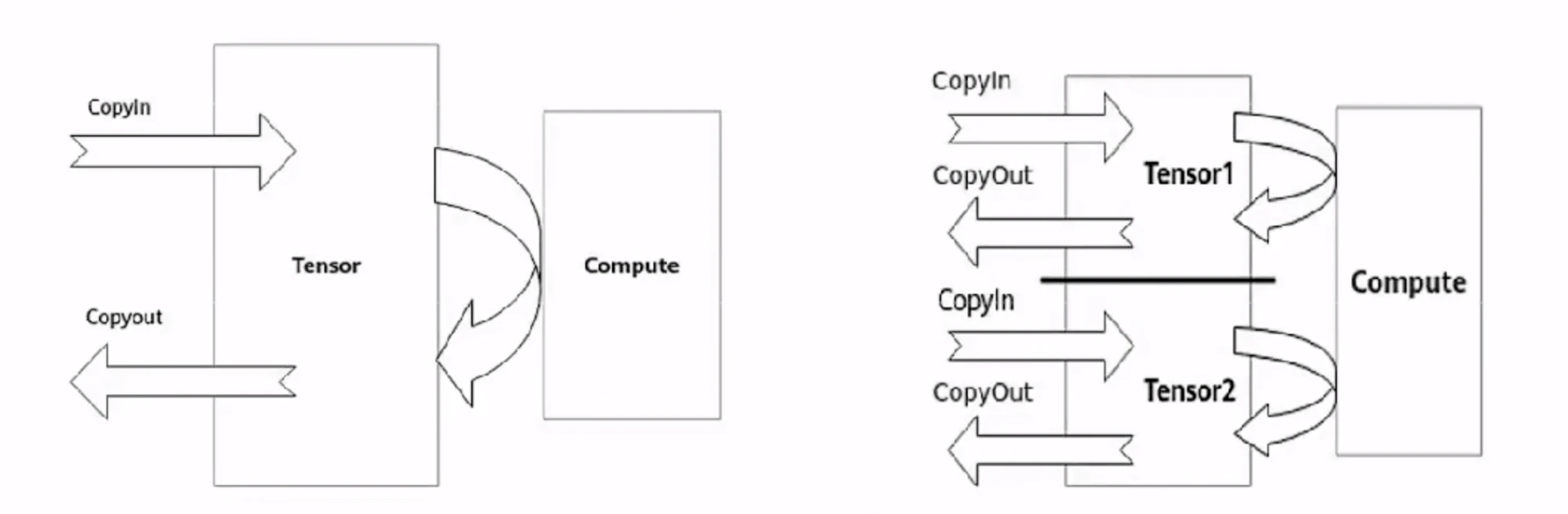
第四步,通过double buffer机制进一步提升性能
double buffer通过将数据搬运与矢量计算并行执行以隐藏数据搬运时间并降低矢量指令的等待时间,最终提高矢量计算单元的利用效率1个Tensor同一时间只能进行搬入、计算和搬出三个流水任务中的一个,其他两个流水任务涉及的硬件单元则处于ldle状态如果将待处理的数据一分为二,比如Tensor1、Tensor2:
当矢量计算单元对Tensor1进行Compute时,Tensor2可以执行CopvIn的任务
当矢量计算单元对Tensor2进行Compute时,Tensor1可以执行CopyOut的任务
当矢量计算单元对Tensor2进行CopyOut时,Tensor1可以执行CopyIn的任务。由此,数据的进出搬运和矢量计算之间实现并行,硬件单元闲置问题得以有效缓解
最后,基于内核调用符方式进行算子验证
先使用python脚本生成x,y,并计算出z(golden)并落盘。然后再用相同的x,y,在cpu和npu模式下调用add算子,计算出结果z,并与python脚本采用计算md5sum的方式进行对比,完全一样,则表示结果正确。
为了运行方便,我们使用一个run.sh,写有cpu和npu模式的编译命令,通过输入参数进行选择cpu或npu模式进行编译,运行。
1)CPU模式下:
使用ICPU_RUN_KF宏进行CPU调试。
ICPU_RUN_KF(add_custom, blockDim, x, y, z); // use this macro for cpu debug
bash run.sh add_custom ascend910 AiCore cpu运行结果:


2)NPU模式下:
NPU模式使用<<<>>>方式调用,由于CPU模式g++没有<<<>>>的表达,需要使用内置宏 __CCE_KT_TEST。
#ifndef __CCE_KT_TEST__
//call of kernel function
void add_custom_do(uint32_t blockDim, void* l2ctrl, void* stream, uint8_t* x, uint8_t* y, uint8_t* z);
{
add_custom<<<blockDim, l2ctrl, stream>>> (x, y, z);
}
#endif
bash run.sh add_custom ascend910 AiCore npu运行结果:
更多学习资源
好啦,本次分享结束啦,Ascend C的学习资源还有很多,想深入学习的可以参考官网教程:Ascend C官方教程。
3天上手Ascend C编程 | Day1 Ascend C基本概念及常用接口3天上手Ascend C编程 | Day2 通过Ascend C编程范式实现一个算子实例3天上手Ascend C编程 | Day3 Ascend C算子调试调优方法
3天上手Ascend C编程丨通过Ascend C编程范式实现一个算子实例的更多相关文章
- 《网络安全编程基础》之Socket编程
<网络安全编程基础>之Socket编程 我的代码 server.c // server.cpp : Defines the entry point for the console appl ...
- [.net 面向对象编程基础] (2) 关于面向对象编程
[.net 面向对象编程基础] (2) 关于面向对象编程 首先是,面向对象编程英文 Object-Oriented Programming 简称 OOP 通俗来说,就是 针对对象编程的意思 那么问 ...
- 5天玩转C#并行和多线程编程 —— 第五天 多线程编程大总结
5天玩转C#并行和多线程编程系列文章目录 5天玩转C#并行和多线程编程 —— 第一天 认识Parallel 5天玩转C#并行和多线程编程 —— 第二天 并行集合和PLinq 5天玩转C#并行和多线程编 ...
- linux tcp/ip编程和windows tcp/ip编程差别以及windows socket编程详解
最近要涉及对接现有应用visual c++开发的tcp客户端,花时间了解了下windows下tcp开发和linux的差别,从开发的角度而言,最大的差别是头文件(早期为了推广尽可能兼容,后面越来越扩展, ...
- Scala 编程(一)Scala 编程总览
Scala 简介 Scala 属于“可伸展语言”,源于它可以随使用者的需求而改变和成长.Scala 可以应用在很大范围的编程任务上,小到脚本大到建立系统均可以. Scala 跑在标准 Java 平台上 ...
- 4 kafka集群部署及kafka生产者java客户端编程 + kafka消费者java客户端编程
本博文的主要内容有 kafka的单机模式部署 kafka的分布式模式部署 生产者java客户端编程 消费者java客户端编程 运行kafka ,需要依赖 zookeeper,你可以使用已有的 zo ...
- Linux系统编程:文件I/O编程
文件I/O操作在Linux编程时是经常会使用到的一个内容,通常可以把比较大的数据写到一个文件中来进行存储或者与其他进程进行数据传输,这样比写到一个全局数组或指针参数来实现还要方便好多. 一.文件常用操 ...
- ZT 针对接口编程而不是针对实现编程
java中继承用extends 实现接口用 implements 针对接口编程而不是针对实现编程 2009-01-08 10:23 zhangrun_gz | 分类:其他编程语言 老听说这句,不知道到 ...
- Linux网络编程——原始套接字编程
原始套接字编程和之前的 UDP 编程差不多,无非就是创建一个套接字后,通过这个套接字接收数据或者发送数据.区别在于,原始套接字可以自行组装数据包(伪装本地 IP,本地 MAC),可以接收本机网卡上所有 ...
- Java网络编程 -- BIO 阻塞式网络编程
阻塞IO的含义 阻塞(blocking)IO :阻塞是指结果返回之前,线程会被挂起,函数只有在得到结果之后(或超时)才会返回 非阻塞(non-blocking)IO :非阻塞和阻塞的概念相对应,指在不 ...
随机推荐
- Singleton 单例模式简介与 C# 示例【创建型】【设计模式来了】
〇.简介 1.什么是单例模式? 一句话解释: 单一的类,只能自己来创建唯一的一个对象. 单例模式(Singleton Pattern)是日常开发中最简单的设计模式之一.这种类型的设计模式属于创建型 ...
- ODOO13之六:Odoo 13开发之模型 – 结构化应用数据
在本系列文章第三篇Odoo 13 开发之创建第一个 Odoo 应用中,我们概览了创建 Odoo 应用所需的所有组件.本文及接下来的一篇我们将深入到组成应用的每一层:模型层.视图层和业务逻辑层. 本文中 ...
- Galaxy v-21.01 发布,新的流程和历史栏体验
Galaxy Project(https://galaxyproject.org/)是在云计算背景下诞生的一个生物信息学可视化分析开源项目. 该项目由美国国家科学基金会(NSF).美国国家人类基因组研 ...
- PicoRV32-on-PYNQ-Z2: An FPGA-based SoC System——RISC-V On PYNQ项目复现
本文参考: 1️⃣ 原始工程 2️⃣ 原始工程复现教程 3️⃣ RISCV工具链安装教程 本文工程: https://bhpan.buaa.edu.cn:443/link/4B08916BF2CDB4 ...
- React SSR - 写个 Demo 一学就会
React SSR - 写个 Demo 一学就会 今天写个小 Demo 来从头实现一下 react 的 SSR,帮助理解 SSR 是如何实现的,有什么细节. 什么是 SSR SSR 即 Server ...
- 云上使用 Stable Diffusion ,模型数据如何共享和存储
随着人工智能技术的爆发,内容生成式人工智能(AIGC)成为了当下热门领域.除了 ChatGPT 之外,文本生成图像技术更令人惊艳. Stable Diffusion,是一款开源的深度学习模型.与 Mi ...
- Python编程和数据科学中的数据处理:如何从数据中提取有用的信息和数据
目录 引言 数据分析和数据处理是数据科学和人工智能领域的核心话题之一.数据科学家和工程师需要从大量的数据中提取有用的信息和知识,以便更好地理解和预测现实世界中的事件.本文将介绍Python编程和数据科 ...
- k3s 基础 —— 配置 loki
官方文档 核心组件 3 个 chart: promtail 这是一个 agent 代理客户端,用于收集日志,将日志传送给 loki loki 核心组件,主要功能是日志数据的写入与分析.包含 gatew ...
- go网络编程(一)
[B站最深度的Golang学习到实战 up主强力推荐] https://www.bilibili.com/video/BV1TK4y1a7ex/?p=101&share_source=copy ...
- windows内核情景分析-毛德操(第一章)
微内核操作系统的特点内核尽量缩小 windows内核包括了两大部分 操作系统内核(ntoskrnl.exe),另一部分则是迁移到了内核中即系统空间中的视窗服务(win32k.sys) 用户空间和系统空 ...