jQuery 2.0.3 源码分析Sizzle引擎 - 超级匹配
声明:本文为原创文章,如需转载,请注明来源并保留原文链接Aaron,谢谢!
通过Expr.find[ type ]我们找出选择器最右边的最终seed种子合集
通过Sizzle.compile函数编译器,我们把tokenize词法元素编译成闭包函数
超级匹配superMatcher,用佳的方式从seed种子集合筛选出需要的数据
也就是通过seed与compile的匹配,得出最终的结果了
superMatcher 函数
这个方法并不是一个直接定义的方法,通过matcherFromGroupMatchers( elementMatchers, setMatchers )方法return出来的一个curry化的函数,但是最后执行起重要作用的是它。
注意是compile()().
compile( selector, match )(
seed,
context,
!documentIsHTML,
results,
rsibling.test( selector ) && testContext( context.parentNode ) || context
);
superMatcher方法会根据参数seed 、expandContext和context确定一个起始的查询范围
elems = seed || byElement && Expr.find["TAG"]( "*", outermost ),
有可能是直接从seed中查询过滤,也有可能在context或者context的父节点范围内。如果不是从seed开始,那只能把整个DOM树节点取出来过滤了,把整个DOM树节点取出来过滤了,它会先执行Expr.find["TAG"]( "*", outermost )这句代码等到一个elems集合(数组合集)
context.getElementsByTagName( tag );
可以看出对于优化选择器,最右边应该写一个作用域的搜索范围context比较好
开始遍历这个seed种子合集了
while ( (matcher = elementMatchers[j++]) ) {
if ( matcher( elem, context, xml ) ) {
results.push( elem );
break;
}
}
elementMatchers:就是通过分解词法器生成的闭包函数了,也就是“终极匹配器”
为什么是while?
前面就提到了,tokenize选择器是可以用过 “,”逗号分组 group,所以就就会有个合集的概念了
matcher就得到了每一个终极匹配器
通过代码很能看出来matcher方法运行的结果都是bool值
对里面的元素逐个使用预先生成的matcher方法做匹配,如果结果为true的则直接将元素堆入返回结果集里面。
matcher
matcher 就是 elementMatcher函数的包装
整个匹配的核心就在这个里面了
function( elem, context, xml ) {
var i = matchers.length;
while ( i-- ) {
if ( !matchers[i]( elem, context, xml ) ) {
return false;
}
}
return true;
} :
我们先来回顾下这个matchers的组合原理
这个地方是最绕的,也是最晕的,所以还是要深入的理解才行哦
先上个简单的流程图:
画的不好 哈哈
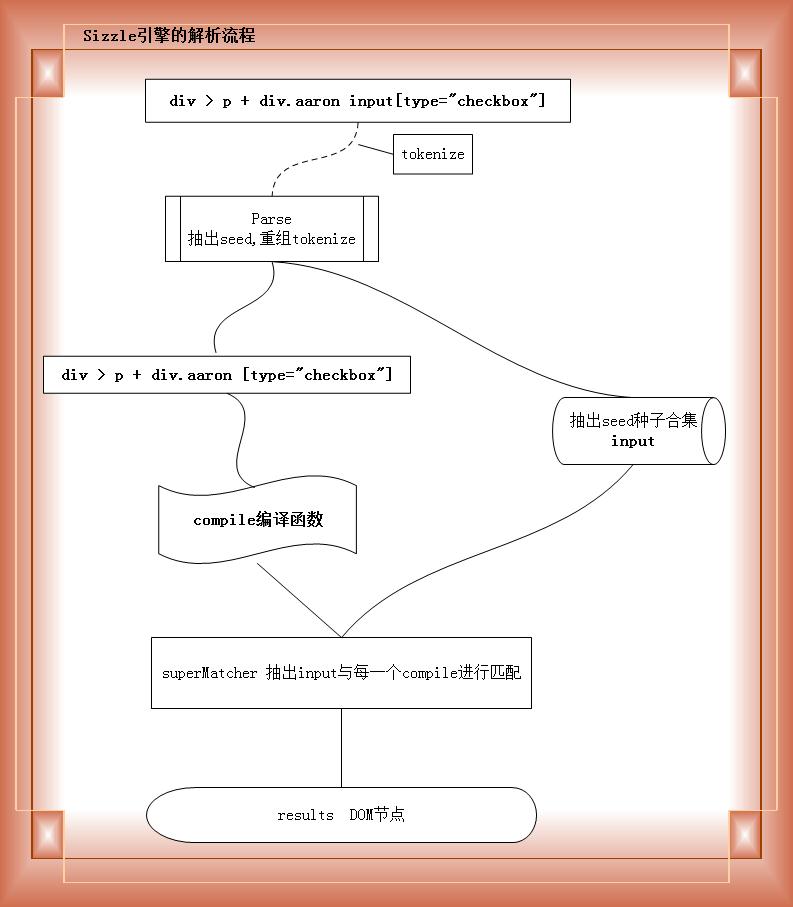
执行分解:
第一步:
div > p + div.aaron input[type="checkbox"]
从右边剥离出原生API能使用的接口属性
context.getElementsByTagName( input )
所以找到了input ,因为只可以用 tag是查询,但是此时结果是个合集,引入seed的概念,称之为种子合集
第二步:
div > p + div.aaron [type="checkbox"]'
重组选择器,踢掉input,得到新的tokens词法元素哈希表
第三步:
通过matcherFromTokens函数,然后根据 关系选择器 【'>',"空","~","+"】拆分分组,因为DOM中的节点都是存在关系的,所以引入
Expr.relative -> first:true 两个关系的“紧密”程度, 用于组合最佳的筛选
一次按照如下顺序解析并且编译闭包函数
编译规则:div > p + div.aaron [type="checkbox"]'
编译成4组闭包函数,然后在前后在合并组合成一组
div > p + div.aaron input[type="checkbox"]
先看构造一组编译函数
A: 抽出div元素, 对应的是TAG类型
B: 通过Expr.filter找到对应匹配的处理器,返回一个闭包处理器
如:TAG方法
"TAG": function( nodeNameSelector ) {
var nodeName = nodeNameSelector.replace( runescape, funescape ).toLowerCase();
return nodeNameSelector === "*" ?
function() { return true; } :
function( elem ) {
return elem.nodeName && elem.nodeName.toLowerCase() === nodeName;
};
},
C:将返回的curry方法放入到matchers匹配器组中,继续分解
D:抽出子元素选择器 '>' ,对应的类型 type: ">"
E:通过Expr.relative找到elementMatcher方法分组合并多个词素的的编译函数
function( elem, context, xml ) {
var i = matchers.length;
while ( i-- ) {
if ( !matchers[i]( elem, context, xml ) ) {
return false;
}
}
所以这里其实就是执行了各自Expr.filter匹配中的的判断方法了,看到这里matcher方法原来运行的结果都是bool值,
所以这里只返回了一个组合闭包,通过这个筛选闭包,各自处理自己内部的元素
F:返回的这个匹配器还是不够的,因为没有规范搜索范围的优先级,所以这时候还要引入addCombinator方法
G:根据Expr.relative -> first:true 两个关系的“紧密”程度
如果是是亲密关系addCombinator返回
function( elem, context, xml ) {
while ( (elem = elem[ dir ]) ) {
if ( elem.nodeType === 1 || checkNonElements ) {
return matcher( elem, context, xml );
}
}
}
所以可见如果是紧密关系的位置词素,找到第一个亲密的节点,立马就用终极匹配器判断这个节点是否符合前面的规则
这是第一组终极匹配器的生成流程了
可见过程极其复杂,被包装了三层
依次
addCombinator
elementMatcher
Expr.relative
三个方法嵌套处理出来的结构

然后继续分解下一组,遇到关系选择器又继续依照以上的过程分解
但是有一个不同的地方,下一个分组会把上一个分组给一并合并了
所以整个关系就是一个依赖嵌套很深的结构
最终暴露出来的终极匹配器其实只有一个闭包,但是有内嵌很深的分组闭包了
依照从左边往右依次生成闭包,然后把上一组闭包又push到下一组闭包
就跟栈是一种后进先出的数据结构一样处理了
所以在最外层也就是
type=["checkbox"]
我们回到superMatcher方法的处理了
在遍历seed种子合集,依次匹配matchers闭包函数,传入每一个seed的元素与之匹配(这里就是input),在对应的编译处理器中通过对input的处理,找到最优匹配结果
function( elem, context, xml ) {
var i = matchers.length;
while ( i-- ) {
if ( !matchers[i]( elem, context, xml ) ) {
return false;
}
}
return true;
} :
这里注意了,是i--,从后往前找
所以第一次开始匹配的就是
check: "checkbox"
name: "type"
operator: "="
那么就找到对应的Attr处理方法
//属性元匹配器工厂
//name :属性名
//operator :操作符
//check : 要检查的值
//例如选择器 [type="checkbox"]中,name="type" operator="=" check="checkbox"
Expr.filter["ATTR"] = function( name, operator, check ) { //返回一个元匹配器
return function( elem ) {
//先取出节点对应的属性值
var result = Sizzle.attr( elem, name ); //看看属性值有木有!
if ( result == null ) {
//如果操作符是不等号,返回真,因为当前属性为空 是不等于任何值的
return operator === "!=";
}
//如果没有操作符,那就直接通过规则了
if ( !operator ) {
return true;
} //转成字符串
result += ""; return
//如果是等号,判断目标值跟当前属性值相等是否为真
operator === "=" ? result === check : //如果是不等号,判断目标值跟当前属性值不相等是否为真
operator === "!=" ? result !== check : //如果是起始相等,判断目标值是否在当前属性值的头部
operator === "^=" ? check && result.indexOf( check ) === 0 : //这样解释: lang*=en 匹配这样 <html lang="xxxxenxxx">的节点
operator === "*=" ? check && result.indexOf( check ) > -1 : //如果是末尾相等,判断目标值是否在当前属性值的末尾
operator === "$=" ? check && result.slice( -check.length ) === check : //这样解释: lang~=en 匹配这样 <html lang="zh_CN en">的节点
operator === "~=" ? ( " " + result + " " ).indexOf( check ) > -1 : //这样解释: lang=|en 匹配这样 <html lang="en-US">的节点
operator === "|=" ? result === check || result.slice( 0, check.length + 1 ) === check + "-" :
//其他情况的操作符号表示不匹配
false;
};
},
Sizzle.attr( elem, name )
传入elem元素就是seed中的input元素,找到是否有'type'类型的属性,
比如
<input type="text">"
所以第一次匹配input就出错了,返回的type是text,而不是我们需要的'checkbox'
这里返回的结果就是false,所以整个之后的处理就直接return了
继续拿出第二个input
继续上一个流程,这时候发现检测到的属性
var result = Sizzle.attr( elem, name );
result: "checkbox"
此时满足第一条匹配,然后继续 i = 0
!matchers[i]( elem, context, xml )
找到第0个编译函数
addCombinator
while ( (elem = elem[ dir ]) ) {
if ( elem.nodeType === 1 || checkNonElements ) {
outerCache = elem[ expando ] || (elem[ expando ] = {});
if ( (cache = outerCache[ dir ]) && cache[0] === dirkey ) {
if ( (data = cache[1]) === true || data === cachedruns ) {
return data === true;
}
} else {
cache = outerCache[ dir ] = [ dirkey ];
cache[1] = matcher( elem, context, xml ) || cachedruns;
if ( cache[1] === true ) {
return true;
}
}
}
}
如果是不紧密的位置关系
那么一直匹配到true为止
如祖宗关系的话,就一直找父亲节点直到有一个祖先节点符合规则为止
直接递归调用
matcher( elem, context, xml )
其实就是下一组闭包队列了,传入的上下文是 div.aaron,也就是<input type="checkbox"的父节点
function (elem, context, xml) {
var i = matchers.length;
//从右到左开始匹配
while (i--) {
//如果有一个没匹配中,那就说明该节点elem不符合规则
if (!matchers[i](elem, context, xml)) {
return false;
}
}
return true;
}
依照上面的规则,这样递归下去了,一层一层的匹配
可见它原来不是一层一层往下查,却有点倒回去向上做匹配、过滤的意思。Expr里面只有find和preFilter返回的是集合。
尽管到这里暂时还带着一点疑问,就是最后它为什么用的是逐个匹配、过滤的方法来得到结果集,但是我想Sizzle最基本的“编译原理”应该已经解释清楚了。
哥们,别光看不顶啊!
jQuery 2.0.3 源码分析Sizzle引擎 - 超级匹配的更多相关文章
- jQuery 2.0.3 源码分析Sizzle引擎解析原理
jQuery 2.0.3 源码分析Sizzle引擎 - 解析原理 声明:本文为原创文章,如需转载,请注明来源并保留原文链接Aaron,谢谢! 先来回答博友的提问: 如何解析 div > p + ...
- jQuery 2.0.3 源码分析Sizzle引擎 - 词法解析
声明:本文为原创文章,如需转载,请注明来源并保留原文链接Aaron,谢谢! 浏览器从下载文档到显示页面的过程是个复杂的过程,这里包含了重绘和重排.各家浏览器引擎的工作原理略有差别,但也有一定规则. 简 ...
- jQuery 2.0.3 源码分析Sizzle引擎 - 解析原理
声明:本文为原创文章,如需转载,请注明来源并保留原文链接Aaron,谢谢! 先来回答博友的提问: 如何解析 div > p + div.aaron input[type="checkb ...
- jQuery 2.0.3 源码分析Sizzle引擎 - 编译函数(大篇幅)
声明:本文为原创文章,如需转载,请注明来源并保留原文链接Aaron,谢谢! 从Sizzle1.8开始,这是Sizzle的分界线了,引入了编译函数机制 网上基本没有资料细说这个东东的,sizzle引入这 ...
- jQuery 2.0.3 源码分析Sizzle引擎 - 高效查询
为什么Sizzle很高效? 首先,从处理流程上理解,它总是先使用最高效的原生方法来做处理 HTML文档一共有这么四个API: getElementById 上下文只能是HTML文档 浏览器支持情况:I ...
- jQuery 2.0.3 源码分析 Deferred(最细的实现剖析,带图)
Deferred的概念请看第一篇 http://www.cnblogs.com/aaronjs/p/3348569.html ******************构建Deferred对象时候的流程图* ...
- jQuery 2.0.3 源码分析core - 选择器
声明:本文为原创文章,如需转载,请注明来源并保留原文链接Aaron,谢谢! 打开jQuery源码,一眼看去到处都充斥着正则表达式,jQuery框架的基础就是查询了,查询文档元素对象 ...
- jQuery 2.0.3 源码分析 Deferred概念
JavaScript编程几乎总是伴随着异步操作,传统的异步操作会在操作完成之后,使用回调函数传回结果,而回调函数中则包含了后续的工作.这也是造成异步编程困难的主要原因:我们一直习惯于“线性”地编写代码 ...
- jQuery 2.0.3 源码分析 事件绑定 - bind/live/delegate/on
事件(Event)是JavaScript应用跳动的心脏,通过使用JavaScript ,你可以监听特定事件的发生,并规定让某些事件发生以对这些事件做出响应 事件的基础就不重复讲解了,本来是定位源码分析 ...
随机推荐
- 弱省互测#0 t3
Case 1 题意 要求给出下面代码的答案然后构造输入. 给一个图, n 个点 m 条边 q 次询问,输出所有点对之间最大权值最小的路径. 题解 把每一个询问的输出看成一条边,建一棵最小生成树. Ca ...
- 【枚举】POJ 3279
直达–>POJ 3279 Fliptile 题意:poj的奶牛又开始作孽了,这回他一跺脚就会让上下左右的砖块翻转(1->0 || 0->1),问你最少踩哪些砖块才能让初始的砖块全部变 ...
- 新入门node.js必须要知道的概念
一.对于一个刚入门node.js的朋友来说,一定要了解一些基础概念: 今年我正式进入社会后,发现自己所知道的IT方面的知识,真的只是牛毛,原来人外有人,山外有山,还需要继续努力.下面是一些我的自学习心 ...
- 谈 CSS 模块化
以前看过模块化的相关资料以及解释,对模块化有了一个表皮的了解,自己也做了一些相关的实践,由于接触到的项目交小,所以也没能更好的去体现和理解模块化,但总体还是有那么一些感悟,但是如果要说怎么才能算是好的 ...
- Hive_配置远程Metastore
注 : 待测试 一.准备两三台linux机器,最好是hadoop集群环境 机器A:10.0.0.2 机器B:10.0.0.3 机器C:10.0.0.4 二.个机器安装信息 机器A安装mysql(用于存 ...
- *HDU1907 博弈
John Time Limit: 5000/1000 MS (Java/Others) Memory Limit: 65535/32768 K (Java/Others)Total Submis ...
- mysql 连接慢的问题(超过了1秒)
http://www.cnblogs.com/isenhome/p/5133547.html 症状描述 本机连接mysql速度很快 远程ping mysql主机速度正常 远程连接mysql速度需要等待 ...
- canvas初探1
刚申请的博客,当然这也是第一篇.对于canvas也是刚开始着手进行学习,有哪些不对的地方,还望看到本篇博文的朋友指正. 1.canvas的历史 首先,它是HTML5的一个标签. 它是为了客户端矢量图形 ...
- myeclipse中导入js报如下错误Syntax error on token "Invalid Regular Expression Options", no accurate correc
今天在使用bootstrap的时候引入的js文件出现错误Syntax error on token "Invalid Regular Expression Options", no ...
- 非常全面的SQL Server巡检脚本来自sqlskills团队的Glenn Berry 大牛
非常全面的SQL Server巡检脚本来自sqlskills团队的Glenn Berry 大牛 Glenn Berry 大牛会对这个脚本持续更新 -- SQL Server 2012 Diagnost ...