scrapy_redis使用介绍
scrapy_redis是一个基于redis的scrapy组件,通过它可以快速实现简单的分布式爬虫程序,该组件主要提供三大功能:
(1)dupefilter——URL去重规则(被调度器使用)
(2)scheduler——调度器
(3)pipeline——数据持久化
一、安装redis
去官网下载redis并安装到电脑上
二、安装scrapy_redis组件
打开终端输入:pip install scrapy-redis 即可 (os/linux)
组件默认被安装在相应的Python文件夹的site-packages里面。如/usr/local/lib/python3.7/site-packages/scrapy_redis
三、scrapy_redis功能详解
(一)URL去重
1、源码 /usr/local/lib/python3.7/site-packages/scrapy_redis/dupefilter.py
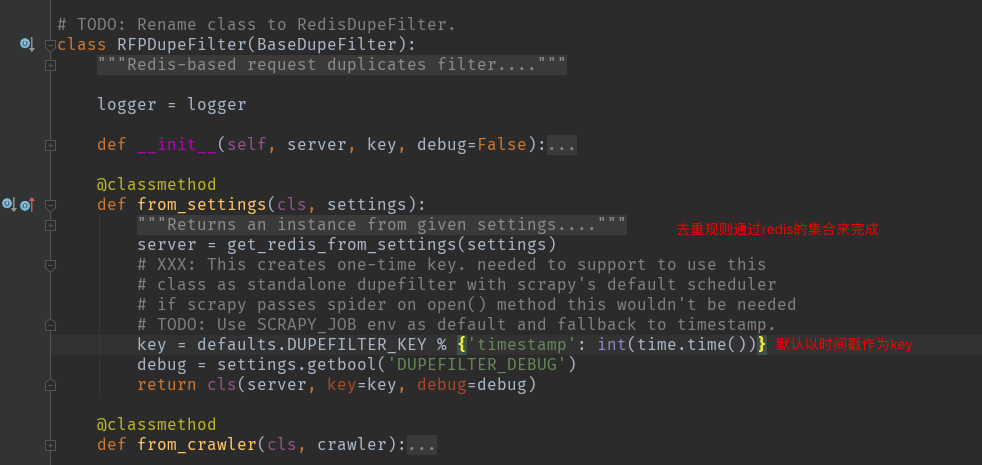
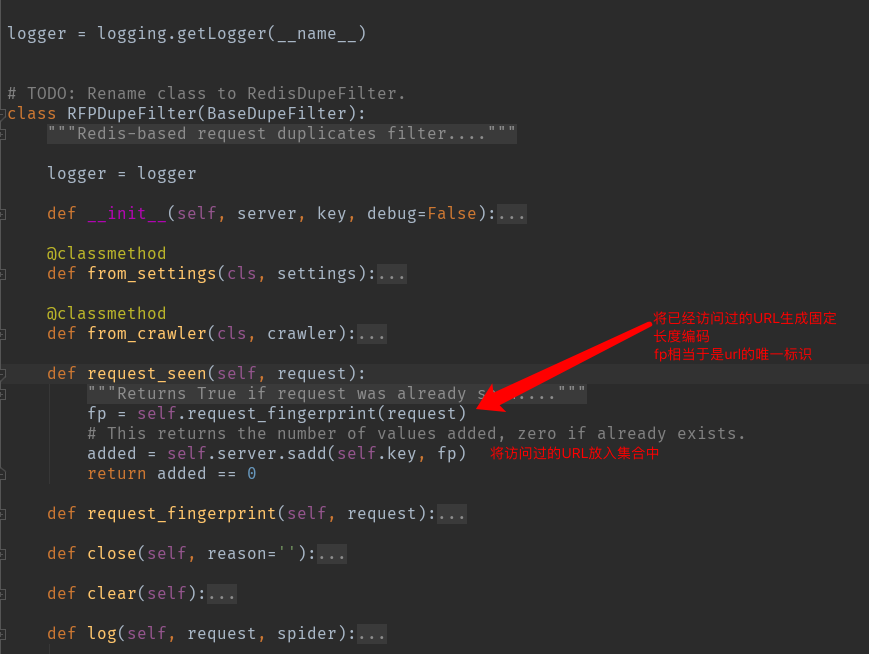
setting.py中的配置信息:
# redis配置
REDIS_HOST = "127.0.0.1"
REDIS_PORT = 6379
REDIS_PARAMS = {}
REDIS_ENCODING = "utf-8" DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
DUPEFILTER_KEY = "dupefilter:%(timestamp)s"
2、重写dupefilter
可以根据自己的需求自定制dupefilter
在spiders的同级目录新建文件dupefilter.py,写入代码:
"""
重写dupefilter
"""
from scrapy_redis.dupefilter import RFPDupeFilter
from scrapy_redis.connection import get_redis_from_settings class MyDupeFilter(RFPDupeFilter):
@classmethod
def from_settings(cls, settings):
server = get_redis_from_settings(settings)
key = "my_scrapy_2_dupfilter" # 重写key
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(server, key=key, debug=debug)
在settings.py中进行相关配置:
# redis配置
REDIS_HOST = "127.0.0.1" # 主机
REDIS_PORT = 6379 # 端口号
REDIS_PARAMS = {} # 连接参数
REDIS_ENCODING = "utf-8" # 编码规则
#配置自己的dupefilter路径
DUPEFILTER_CLASS = "my_scrapy_2.dupefilter.MyDupeFilter"
(二)调度器
1、广度优先和深度优先
(1)栈——后进先出——广度优先——LifoQueue(列表)
(2) 队列——先进先出——深度优先——FifoQueue(列表)
(3) 优先级集合——PriorityQueue(有序集合)
2、在settings.py中:
# redis配置
REDIS_HOST = "127.0.0.1"
REDIS_PORT = 6379
REDIS_PARAMS = {}
REDIS_ENCODING = "utf-8" # 去重规则
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' # 默认使用优先级队列(默认),其他:PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表)
SCHEDULER_QUEUE_KEY = '%(spider)s:requests' # 调度器中请求存放在redis中的key chouti:requests
SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat" # 对保存到redis中的数据进行序列化,默认使用pickle
SCHEDULER_PERSIST = True # 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空
SCHEDULER_FLUSH_ON_START = True # 是否在开始之前清空 调度器和去重记录,True=清空,False=不清空
# SCHEDULER_IDLE_BEFORE_CLOSE = 10 # 去调度器中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)。
SCHEDULER_DUPEFILTER_KEY = '%(spider)s:dupefilter' # 去重规则,在redis中保存时对应的key
SCHEDULER_DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter' # 去重规则对应处理的类 DEPTH_PRIORITY = -1 # 如果是使用优先级集合(PriorityQueue)就用做该配置参数 DEPTH_PRIORITY可以设为-1或者1
(三)数据持久化
1、源码

以爬取抽屉新热榜的新闻标题与连接为例:
爬虫 chouti.py:
# -*- coding: utf-8 -*-
"""
爬取抽屉新热榜的新闻标题以及url 并保存
"""
import scrapy
from scrapy.http import Request
from ..items import MyScrapy3Item class ChoutiSpider(scrapy.Spider):
name = 'chouti'
allowed_domains = ['chouti.com']
start_urls = ['http://chouti.com/'] def parse(self, response):
# print(response, response.request.priority, response.meta.get('depth'))
items = response.xpath("//div[@id='content-list']/div[@class='item']")
for item in items:
title = item.xpath(".//div[@class='part1']/a/text()").extract_first().strip() # 标题
href = item.xpath(".//div[@class='part1']/a/@href").extract_first().strip() # 连接
yield MyScrapy3Item(title=title, href=href) # yield一个item对象
# 翻页
page_list = response.xpath('//*[@id="dig_lcpage"]//a/@href').extract()
for url in page_list:
url = "https://dig.chouti.com" + url
yield Request(url=url, callback=self.parse)
items.py:
import scrapy class MyScrapy3Item(scrapy.Item):
title = scrapy.Field()
href = scrapy.Field()
settings.py中做相关的配置:
ITEM_PIPELINES = {
"scrapy_redis.pipelines.RedisPipeline": 300, # 设置使用scrapy_redis的持久化类
}
# -----------其他配置----------------------
DEPTH_LIMIT = 2 # 爬取深度 # redis配置 (必须的)
REDIS_HOST = "127.0.0.1"
REDIS_PORT = 6379
REDIS_PARAMS = {}
REDIS_ENCODING = "utf-8" # 去重规则
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.FifoQueue' # 默认使用优先级队列(默认),其他:PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表)
SCHEDULER_QUEUE_KEY = '%(spider)s:requests' # 调度器中请求存放在redis中的key chouti:requests
SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat" # 对保存到redis中的数据进行序列化,默认使用pickle
SCHEDULER_PERSIST = True # 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空
SCHEDULER_FLUSH_ON_START = True # 是否在开始之前清空 调度器和去重记录,True=清空,False=不清空
# SCHEDULER_IDLE_BEFORE_CLOSE = 10 # 去调度器中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)
SCHEDULER_DUPEFILTER_KEY = '%(spider)s:dupefilter' # 去重规则,在redis中保存时对应的key
SCHEDULER_DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter' # 去重规则对应处理的类
在项目根目录新建文件start_chouti.py用于运行爬虫(也可以直接在终端输命令来运行):
from scrapy.cmdline import execute if __name__ == "__main__":
execute(["scrapy", "crawl", "chouti", "--nolog"])
可以新建一个py文件用于查看保存在Redis中的数据:
# 3种方式查看数据 import redis conn = redis.Redis(host="127.0.0.1", port=6379) # conn.flushall() # 清空Redis print(conn.keys()) # 查看所有key [b'chouti:dupefilter', b'chouti:items']
# 1、获取指定范围的数据
# res = conn.lrange('chouti:items', 0, 3) # 获取持久化的数据 取3条
# print(res)
"""
结果:
[b'{"title": "\\u3010\\u56fe\\u96c6\\u30112018\\u5e74\\u5ea6\\u5929\\u6587\\u6444\\u5f71\\u5e08\\u5927\\u8d5b\\u83b7\\u5956\\u4f5c\\u54c1\\u516c\\u5e03",
"href": "https://mp.weixin.qq.com/s/eiWj7ky53xEDoMRFXC1EGg"}', b'{"title": "\\u3010\\u201c\\u4eba\\u76f4\\u5230\\u5165\\u571f\\u4e3a\\u5b89\\u90a3\\u4e00\\u5929\\uff0c\\u90fd\\u5728\\u8d70\\u53f0\\u9636\\u201d \\u3011\\u674e\\u548f\\u5728\\u63a5\\u53d7\\u91c7\\u8bbf\\u65f6\\u66fe\\u8fd9\\u6837\\u5f62\\u5bb9\\u81ea\\u5df1\\u7684\\u4eba\\u751f\\uff1a\\u201c\\u4eba\\u76f4\\u5230\\u5165\\u571f\\u4e3a\\u5b89\\u90a3\\u4e00\\u5929\\uff0c\\u90fd\\u5728\\u8d70\\u53f0\\u9636\\u3002\\u8ddf\\u767b\\u9ec4\\u5c71\\u4e00\\u6837\\uff0c\\u767b\\u7684\\u65f6\\u5019\\u4f60\\u4e0d\\u89c9\\u5f97\\u6709\\u4e91\\uff0c\\u5230\\u4e00\\u5b9a\\u9ad8\\u5ea6\\u7684\\u65f6\\u5019\\uff0c\\u65c1\\u8fb9\\u6709\\u4eba\\u63d0\\u9192\\u4f60\\u56de\\u5934\\u770b\\u4e00\\u4e0b\\uff0c\\u4e91\\u5c31\\u5728\\u773c\\u524d\\u3002\\u201d", "href": "https://mp.weixin.qq.com/s/erLgWmL1GhpyWqwOTIlRvQ"}', b'{"title": "\\u3010\\u6e38\\u620f\\u673a\\u5236
\\u6e17\\u900f\\u5e76\\u6e10\\u6e10\\u5851\\u9020\\u4e86\\u73b0\\u5b9e\\u4e16\\u754c\\uff0c\\u4f60\\u662f\\u5426\\u4e5f\\u4e00\\u6837\\u8ba4\\u4e3a\\u7406\\u6240\\u5f53\\u7136\\uff1f\\u3011\\u5728\\u667a\\u80fd\\u624b\\u673a\\u666e\\u53ca\\u4ee5\\u540e\\uff0c\\u79fb\\u52a8\\u6280\\u672f\\u80fd\\u591f\\u4e0e\\u73b0\\u5b9e\\u4e16\\u754c\\u53d1\\u751f\\u8d8a\\u6765\\u8d8a\\u591a\\u7684\\u4ea4\\u4e92\\uff0c\\u56e0\\u6b64\\u6e38\\u620f\\u5316\\u7684\\u5c1d\\u8bd5\\u5e76\\u6ca1\\u6709\\u51cf\\u5c11\\u53cd\\u800c\\u589e\\u591a\\u4e86\\u3002\\u6709\\u6bcf\\u5929\\u8bb0\\u5f55\\u4f60\\u7684\\u6b65\\u884c\\u8ddd\\u79bb\\uff0c\\u7136\\u540e\\u9881\\u53d1\\u5956\\u7ae0\\u7684\\u3002\\u6709\\u8bb0\\u5f55\\u4f60\\u7684\\u4e60\\u60ef\\uff0c\\u5e76\\u53ef\\u4ee5\\u5efa\\u8bbe\\u4e00\\u5ea7\\u57ce\\u5e02\\u7684\\u3002",
"href": "http://www.qdaily.com/articles/57753.html"}', b'{"title": "\\u3010\\u53c8\\u5931\\u4e00\\u57ce\\uff01\\u9ed8\\u514b\\u5c14\\u7684\\u201c\\u9ec4\\u91d1\\u914d\\u89d2\\u201d\\u5728\\u9ed1\\u68ee\\u5dde\\u906d\\u9047\\u60e8\\u8d25\\u3011\\u4eca\\u5e74\\u4e09\\u6708\\u8270\\u96be\\u5b8c\\u6210\\u7b2c\\u56db\\u6b21\\u7ec4\\u9601\\u7684\\u5fb7\\u56fd\\u603b\\u7406\\u9ed8\\u514b\\u5c14\\uff0c\\u572810\\u6708\\u5fb7\\u56fd\\u4e24\\u4e2a\\u5173\\u952e\\u5dde\\u2014\\u2014\\u5df4\\u4f10\\u5229\\u4e9a\\u5dde\\u548c\\u9ed1\\u68ee\\u5dde\\u7684\\u9009\\u4e3e\\u4e2d\\uff0c\\u63a5\\u8fde\\u906d\\u9047\\u5386\\u53f2\\u6027\\u60e8\\u8d25\\u3002\\u9ed8\\u514b\\u5c14\\u7684\\u201c\\u9ec4\\u91d1\\u914d\\u89d2\\u201d\\u2014\\u2014\\u793e\\u6c11\\u515a\\uff08SPD\\uff09\\u5728\\u4e24\\u6b21\\u9009\\u4e3e\\u4e2d\\u7684\\u5f97\\u7968\\u7387\\u5448\\u73b0\\u81ea\\u7531\\u843d\\u4f53\\u72b6\\u6001\\u3002",
"href": "https://wallstreetcn.com/articles/3428455"}'] """
# 2、一条一条的将数据取走
# item = conn.lpop('chouti:items')
# print(item)
"""
结果:
b'{"title": "\\u3010\\u56fe\\u96c6\\u30112018\\u5e74\\u5ea6\\u5929\\u6587\\u6444\\u5f71\\u5e08\\u5927\\u8d5b\\u83b7\\u5956\\u4f5c\\u54c1\\u516c\\u5e03",
"href": "https://mp.weixin.qq.com/s/eiWj7ky53xEDoMRFXC1EGg"}'
"""
# 3、做成一个生产者-消费者模型
while True:
item = conn.blpop('chouti:items') # 一条一条的将数据取走 如果没有了就阻塞住
print(item)
通过使用scrapy_redis的持久化数据功能,可以将生产数据和获取数据作为两件互不影响的事情并发的运行。
2、如果还想要将数据存入其他地方,可以继承和重写scrapy_redis的pipelines
四、起始URL的定制
让爬虫像永动机一样一直处于备战状态,如果没有请求就处于等待状态,当有新的URL进来时就开始爬取数据。
在爬虫文件中:
"""
爬取抽屉新热榜的新闻标题以及url 并保存
让爬虫一直爬数据,如果没有就处于等待状态
"""
from scrapy_redis.spiders import RedisSpider class ChoutiSpider(RedisSpider): # 继承RedisSpider
name = 'chouti'
allowed_domains = ['chouti.com'] def parse(self, response):
print(response)
配置文件中:
# 起始url
REDIS_START_URLS_AS_SET = True # True:在Redis里面按照集合去存,False:按照列表来存储
START_URLS_KEY = '%(name)s:start_urls' # 在源码中默认的起始URL的key为 chouti:start_urls
再写一个py文件来设置url:
import redis
conn = redis.Redis(host="127.0.0.1", port=6379)
# conn.flushall() # 清空Redis
print(conn.keys()) # 查看所有key [b'chouti:start_url']
item = conn.sadd("chouti:start_url", "https://dig.chouti.com/r/pic/hot/1") # 设置起始url
print(item)
scrapy_redis使用介绍的更多相关文章
- scrapy-redis介绍(一)
scrapy是python里面一个非常完善的爬虫框架,实现了非常多的功能,比如内存检测,对象引用查看,命令行,shell终端,还有各种中间件和扩展等,相信开发过scrapy的朋友都会觉得这个框架非常的 ...
- scrapy爬虫系列之七--scrapy_redis的使用
功能点:如何发送携带cookie访问登录后的页面,如何发送post请求登录 简单介绍: 安装:pip3 install scrapy_redis 在scrapy的基础上实现了更多的功能:如reques ...
- Python爬虫教程-34-分布式爬虫介绍
Python爬虫教程-34-分布式爬虫介绍 分布式爬虫在实际应用中还算是多的,本篇简单介绍一下分布式爬虫 什么是分布式爬虫 分布式爬虫就是多台计算机上都安装爬虫程序,重点是联合采集.单机爬虫就是只在一 ...
- 浅析scrapy与scrapy_redis区别
最近在工作中写了很多 scrapy_redis 分布式爬虫,但是回想 scrapy 与 scrapy_redis 两者区别的时候,竟然,思维只是局限在了应用方面,于是乎,搜索了很多相关文章介绍,这才搞 ...
- CSS3 background-image背景图片相关介绍
这里将会介绍如何通过background-image设置背景图片,以及背景图片的平铺.拉伸.偏移.设置大小等操作. 1. 背景图片样式分类 CSS中设置元素背景图片及其背景图片样式的属性主要以下几个: ...
- MySQL高级知识- MySQL的架构介绍
[TOC] 1.MySQL 简介 概述 MySQL是一个关系型数据库管理系统,由瑞典MySQL AB公司开发,目前属于Oracle公司. MySQL是一种关联数据库管理系统,将数据保存在不同的表中,而 ...
- Windows Server 2012 NIC Teaming介绍及注意事项
Windows Server 2012 NIC Teaming介绍及注意事项 转载自:http://www.it165.net/os/html/201303/4799.html Windows Ser ...
- Linux下服务器端开发流程及相关工具介绍(C++)
去年刚毕业来公司后,做为新人,发现很多东西都没有文档,各种工具和地址都是口口相传的,而且很多时候都是不知道有哪些工具可以使用,所以当时就想把自己接触到的这些东西记录下来,为后来者提供参考,相当于一个路 ...
- JavaScript var关键字、变量的状态、异常处理、命名规范等介绍
本篇主要介绍var关键字.变量的undefined和null状态.异常处理.命名规范. 目录 1. var 关键字:介绍var关键字的使用. 2. 变量的状态:介绍变量的未定义.已定义未赋值.已定义已 ...
随机推荐
- python3_linux安装
python安装包地址 https://www.python.org/ftp/python/ 如果没有c complie,就安装: yum -y install gcc gcc-c++ 在编译安装之前 ...
- 转 多个版本的数据库在同一服务器上ORA-12557
http://blog.chinaunix.net/uid-42518-id-3153473.html 问题描述:当同一台机子上安装了多个版本的数据库,可能在连接库或ASM时会报以下错误.ORA-12 ...
- 150 Evaluate Reverse Polish Notation 逆波兰表达式求值
求在 逆波兰表示法 中算术表达式的值.有效的运算符号包括 +, -, *, / .每个运算对象可以是整数,也可以是另一个逆波兰计数表达.例如: ["2", "1&quo ...
- FACVSPOW - Factorial vs Power 数学方法 + 二分
http://www.spoj.com/problems/FACVSPOW/ 求解n! > a^n最小的整数n 对于有n!和a^n的东西,一般是取ln 然后就是求解 (ln(1) + ln(2) ...
- ES--在windows上快速安装
环境准备 java环境部署: Java下载路径:http://download.oracle.com/otn-pub/java/jdk/8u181-b13/96a7b8442fe848ef90c96a ...
- Error: IO_ERROR : java.io.IOException: Error while connecting Oozie server. No of retries = 5. Exception = Connection refused (Connection refused)解决办法(图文详解)
不多说,直接上干货! 问题详情 解决办法 Copy/Paste oozie.services property tag set from oozie-default.xml to oozie-site ...
- neo4j(图数据库)是什么?
不多说,直接上干货! 作为一款强健的,可伸缩的高性能数据库,Neo4j最适合完整的企业部署或者用于一个轻量级项目中完整服务器的一个子集存在. 它包括如下几个显著特点: 完整的ACID支持 高可用性 轻 ...
- js修改物理返回键功能
preventBack: function(theurl){ var pushState = window.history.pushState; //点击物理返回键时,退出到跳转定义首页 if(pus ...
- canvas 平移&缩放
1.平移 canvas其实只是一个包装器,真正起着重要作用的部分是2D渲染上下文,这才是我们真正绘制图形的地方. 然而2D渲染上下文是一种基于屏幕的标准绘制平台.它采用屏幕的笛卡尔坐标系统,以左上角( ...
- FileZilla Server 端设置passive模式注意事项
1,需求和问题的产生 实践中需要分布在各地的各个客户端向云端服务器上传文件,因此在阿里云服务器上安装了FileZilla Server软件作为文件FTP服务端. 客户端程序采用FTP方式向服务端传输文 ...