图的深度优先遍历&广度优先遍历
将具有n(n-1)/2条边的无向图称为无向完全图(完全图就是任意两个顶点都存在边)。
将具有n(n-1)条边的有向图称为有向完全图。
3.顶点的度
对于无向图,顶点的度表示以该顶点作为一个端点的边的数目。比如,图(a)无向图中顶点V3的度D(V3)=3
对于有向图,顶点的度分为入度和出度。入度表示以该顶点为终点的入边数目,出度是以该顶点为起点的出边数目,该顶点的度等于其入度和出度之和。比如,顶点V1的入度ID(V1)=1,出度OD(V1)=2,所 以D(V1)=ID(V1)+OD(V1)=1+2=3
记住,不管是无向图还是有向图,顶点数n,边数e和顶点的度数有如下关系:
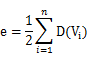

因此,就拿有向图(b)来举例,由公式可以得到图G的边数e=(D(V1)+D(V2)+D(V3))/2=(3+2+3)/2=4
邻接表是图的一种链式存储结构。这种存储结构类似于树的孩子链表。对于图(g)中每个顶点Vi,把所有邻接于Vi的顶点Vj链成一个单链表,这个单链表称为顶点Vi的邻接表。
顶点用一个一维数组存储,每个顶点的所有邻接点用单链表存储。
4.图的两种遍历(从图中某一顶点出发访遍图中其余顶点,且使每一个顶点仅被访问一次)
(1)深度优先搜索遍历(DFS)
深度优先搜索DFS遍历类似于树的前序遍历。其基本思路是:
a) 假设初始状态是图中所有顶点都未曾访问过,则可从图G中任意一顶点v为初始出发点,首先访问出发点v,并将其标记为已访问过。
b) 然后依次从v出发搜索v的每个邻接点w,若w未曾访问过,则以w作为新的出发点出发,继续进行深度优先遍历,直到图中所有和v有路径相通的顶点都被访问到。
c) 若此时图中仍有顶点未被访问,则另选一个未曾访问的顶点作为起点,重复上述步骤,直到图中所有顶点都被访问到为止。
图示如下:

注:红色数字代表遍历的先后顺序,所以图(e)无向图的深度优先遍历的顶点访问序列为:V0,V1,V2,V5,V4,V6,V3,V7,V8
如果采用邻接矩阵存储,则时间复杂度为O(n2);当采用邻接表时时间复杂度为O(n+e)。
(2)广度优先搜索遍历(BFS)
广度优先搜索遍历BFS类似于树的按层次遍历。其基本思路是:
a) 首先访问出发点Vi
b) 接着依次访问Vi的所有未被访问过的邻接点Vi,Vi,Vi,…,Vit并均标记为已访问过。
c) 然后再按照Vi1,Vi2,… ,Vit的次序,访问每一个顶点的所有未曾访问过的顶点并均标记为已访问过,依此类推,直到图中所有和初始出发点Vi有路径相通的顶点都被访问过为止。
图示如下:
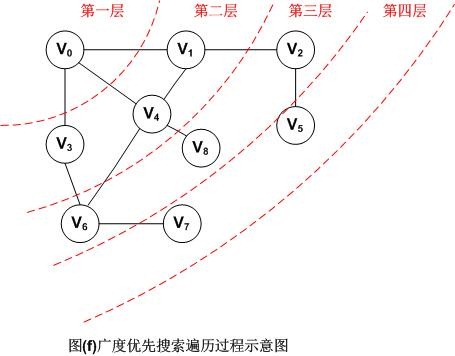
因此,图(f)采用广义优先搜索遍历以V0为出发点的顶点序列为:V0,V1,V3,V4,V2,V6,V8,V5,V7
如果采用邻接矩阵存储,则时间复杂度为O(n2),若采用邻接表,则时间复杂度为O(n+e)。
代码展示:
//Vertex
package com.graph;
//顶点类
public class Vertex {
//顶点
char label;
//用来标识是否被访问过了
public boolean wasVisited;
public Vertex(char label) {
this.label=label;
}
} //Graph
package com.graph;
//图
public class Graph {
//顶点数组
private Vertex[] vertexList; //邻接矩阵
private int[][] adjMat; //顶点的最大数目,数组初试化时用的
private int maxSize = 20; //当前顶点
private int nVertex; //栈
private MyStack stack;
//构造函数
public Graph() {
vertexList=new Vertex[maxSize];
adjMat=new int[maxSize][maxSize];
for (int i = 0; i < maxSize; i++) {
for (int j = 0; j < maxSize; j++) {
adjMat[i][j]=0;
}
}
nVertex=0;
}
//添加顶点
public void addVertex(char label) {
vertexList[nVertex++]=new Vertex(label);
}
//添加边
public void addEdge(int start,int end) {
adjMat[start][end]=1;
adjMat[end][start]=1;//这样能够构造对称矩阵 }
//获得邻接的未被访问过的结点
public int getadjUnvisitedVertex(int v) {
for (int i = 0; i < nVertex; i++) {//遍历邻接矩阵里面有效的结点数
if (adjMat[v][i]==1 && vertexList[i].wasVisited==false) {//adjMat[v][i]就表示邻接,
//vertexList[i].wasVisited==false表示未被访问过的
return i;//i结点就是要访问的结点
}
}
return -1;
} public void dfs() {
//首先访问0号顶点
vertexList[0].wasVisited = true;
//显示该顶点
displayVertex(0);
//压入栈中
stack.push(0);
while (!stack.isEmpty()) {
//获得一个未访问过的邻接点
int v=getadjUnvisitedVertex((int)stack.peek());
if (v == -1) {
//弹出一个顶点
stack.pop();
}else {
//标记它
vertexList[v].wasVisited = true;
//显示它
displayVertex(v);
//压入栈中
stack.push(v);
}
}
//搜索完以后,要将访问信息修改复原
for (int i = 0; i < nVertex; i++) {
vertexList[i].wasVisited = false;
} }
public void displayVertex(int v) {
System.out.print(vertexList[v].label);
}
}
//MyStack
package com.graph; public class MyStack {
//底层实现是一个数组
private long[] arr;
private int top;//设置栈顶
/*
* 默认构造函数*/
public MyStack(){
arr=new long[10];
top=-1;
}
/*
* 带参数的构造方法,参数为数组初始化大小*/
public MyStack(int maxsize){
arr=new long[maxsize];
top=-1;
} /*添加数据*/
public void push(int value){
arr[++top]=value;//首先要对top进行递增,因为初始的top为-1
} /*移除数据*/
public long pop(){
return arr[top--];
} /*查找数据*/
public long peek(){
return arr[top];
} /*判断是否为空*/
public boolean isEmpty(){
return top==-1;
} /*判断是否满了*/
public boolean isFull(){
return top==arr.length-1;
}
} // TestGraph
package com.graph;
public class TestGraph { public static void main(String[] args) {
Graph g = new Graph();
g.addVertex('A');
g.addVertex('B');
g.addVertex('C');
g.addVertex('D');
g.addVertex('E'); g.addEdge(0, 1);
g.addEdge(1, 2);
g.addEdge(0, 3);
g.addEdge(3, 4); g.dfs();
} }
参考文档:http://www.cnblogs.com/mcgrady/p/3335847.html
图的深度优先遍历&广度优先遍历的更多相关文章
- 图的深度优先和广度优先遍历(图以邻接表表示,由C++面向对象实现)
学习了图的深度优先和广度优先遍历,发现不管是教材还是网上,大都为C语言函数式实现,为了加深理解,我以C++面向对象的方式把图的深度优先和广度优先遍历重写了一遍. 废话不多说,直接上代码: #inclu ...
- 图的理解:深度优先和广度优先遍历及其 Java 实现
遍历 图的遍历,所谓遍历,即是对结点的访问.一个图有那么多个结点,如何遍历这些结点,需要特定策略,一般有两种访问策略: 深度优先遍历 广度优先遍历 深度优先 深度优先遍历,从初始访问结点出发,我们知道 ...
- 存储结构与邻接矩阵,深度优先和广度优先遍历及Java实现
如果看完本篇博客任有不明白的地方,可以去看一下<大话数据结构>的7.4以及7.5,讲得比较易懂,不过是用C实现 下面内容来自segmentfault 存储结构 要存储一个图,我们知道图既有 ...
- JavaScript实现树深度优先和广度优先遍历搜索
1.前置条件 我们提前构建一棵树,类型为 Tree ,其节点类型为 Note.这里我们不进行过多的实现,简单描述下 Note 的结构: class Node{ constructor(data){ t ...
- python 实现图的深度优先和广度优先搜索
在介绍 python 实现图的深度优先和广度优先搜索前,我们先来了解下什么是"图". 1 一些定义 顶点 顶点(也称为"节点")是图的基本部分.它可以有一个名称 ...
- 图的建立(邻接矩阵)+深度优先遍历+广度优先遍历+Prim算法构造最小生成树(Java语言描述)
主要参考资料:数据结构(C语言版)严蔚敏 ,http://blog.chinaunix.net/uid-25324849-id-2182922.html 代码测试通过. package 图的建 ...
- 深度优先遍历&广度优先遍历
二叉树的前序遍历,中序遍历,后序遍历 树的遍历: 先根遍历--访问根结点,按照从左至右顺序先根遍历根结点的每一颗子树. 后根遍历--按照从左至右顺序后根遍历根结点的每一颗子树,访问根结点. 先根:AB ...
- 数据结构5_java---二叉树,树的建立,树的先序、中序、后序遍历(递归和非递归算法),层次遍历(广度优先遍历),深度优先遍历,树的深度(递归算法)
1.二叉树的建立 首先,定义数组存储树的data,然后使用list集合将所有的二叉树结点都包含进去,最后给每个父亲结点赋予左右孩子. 需要注意的是:最后一个父亲结点需要单独处理 public stat ...
- tree的遍历--广度优先遍历
一.二叉树demo var tree = { value: '一', left: { value: '二', left: { value: '四', right: { value: '六' } } } ...
随机推荐
- Java获取Date类型-针对SQL语句
简便使用Date类型: import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedState ...
- 初识Python(三)
一.作用域 对于变量的作用域,执行声明并在内存中存在,该变量就可以在后续的代码中使用: 外层变量,可以被内层变量使用:内层变量,也可以被外层变量使用: 如下示例: #!/usr/bin/env pyt ...
- MySQL入门很简单: 15 java访问MySQL数据库
1. 连接数据库 1.1 下载安装驱动 java通过JDBC(Java Database Connectivity,Java数据库连接)来访问MySQL数据库.JDBC的编程接口提供的接口和类与MyS ...
- POJ-3190 Stall Reservations---优先队列+贪心
题目链接: https://vjudge.net/problem/POJ-3190 题目大意: 有N头奶牛,每头奶牛都会在[1,1000000]的时间区间内的子区间进行挤奶.挤奶的时候奶牛一定要单独放 ...
- mac home brew install go
mac利器home brew安装Go 首先你得需要安装home brew和ruby环境(因为home brew依赖ruby) 如果没有请自行到链接安装 准备好之后就开始安装go了 brew updat ...
- Linux下C程序进程地址空间布局[转]
我们在学习C程序开发时经常会遇到一些概念:代码段.数据段.BSS段(Block Started by Symbol) .堆(heap)和栈(stack).先看一张教材上的示意图(来源,<UNIX ...
- IIS 处理程序“PageHandlerFactory-Integrated”
出现这种错误是因为先安装了.net framework 4.0然后才安装了iis,此种情况下iis默认只支持.net framewrok 2.0,要解决此问题,需要在iis中注册.net framew ...
- Large-scale Scene Understanding (LSUN)
Large-scale Scene Understanding (LSUN) http://lsun.cs.princeton.edu/#organizers http://sunw.csail.mi ...
- fcc初级算法方法总结
var arr = str.split("分隔符"): var newArr = arr.reverse(); var str = arr.join("连接符" ...
- python读写dbf数据库
dbf数据库作为一种简单的数据库,曾经广泛使用.现在在金融领域还是有很多的应用之处,工作中遇到此类的问题,在此记录一下. 1. 读取dbf ''' 读取DBF文件 ''' def readDbfFil ...