Hadoop 2.x简介
Hadoop 2.0产生背景
- Hadoop1.0中HDFS和MapReduce在高可用、扩展性等方面存在问题
- HDFS存在的问题
- NameNode单点故障,难以应用于在线场景
- NameNode压力过大,且内存受限,影响系统扩展性
- MapReduce存在的问题
- JobTracker访问压力大,影响系统扩展性
- 难以支持除MapReduce之外的计算框架,比如Spark 、Storm等
MapReduce是离线计算框架,计算时间会比较长
Spark是内存计算框架,更快
Storm是流计算框架,可实时获取计算结果
Hadoop 1.x 与Hadoop 2.x
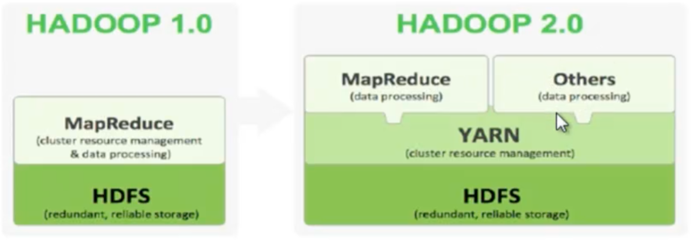
- Hadoop 2.x由HDFS、MapReduce和YARN三个分支构成
- HDFS : NN Federation、HA;
- MapReduce : 运行在YARN上的MR
- YARN : 资源管理系统(内存、CPU资源)
Federation把元数据分成两个独立的NameNode去工作。
YARN知道任何一台机器的使用情况,在执行任务的时候,首先去YARN上申请,YARN 分配到某台机器上去执行,可做到资源不浪费
HDFS存储的数据可由MapReduce进行计算,也可以由其它的计算框架计算
HDFS 2.x优点
- 解决HDFS 1.0中单点故障和内存受限问题
- 解决单点故障
- HDFS HA : 通过主备NameNode解决(只有一个NameNode正常工作,其它都是备用)
- 如果主NameNode发生故障,则切换到备NameNode上
- 解决内存受限问题
- HDFS Federation(联邦)
- 水平扩展,支持多个NameNode
- 每个NameNode分管一部分目录(相互独立)
- 所有NameNode共享所有DataNode存储资源
- 2.x仅是架构上发生了变化,使用方式不变
- 对HDFS使用者透明
- HDFS 1.X中的命令和API仍可以使用
Hadoop 2.x简介的更多相关文章
- Hadoop开发环境简介(转)
1.Hadoop开发环境简介 1.1 Hadoop集群简介 Java版本:jdk-6u31-linux-i586.bin Linux系统:CentOS6.0 Hadoop版本:hadoop-1.0.0 ...
- Hadoop发展历史简介
简介 本篇文章主要介绍了Hadoop系统的发展历史以及商业化现状, 科普文. 如果你喜欢本博客,请点此查看本博客所有文章:http://www.cnblogs.com/xuanku/p/index.h ...
- Hadoop体系架构简介
今天跟一个朋友在讨论hadoop体系架构,从当下流行的Hadoop+HDFS+MapReduce+Hbase+Pig+Hive+Spark+Storm开始一直讲到HDFS的底层实现,MapReduce ...
- 二十六、Hadoop学习笔记————Hadoop Yarn的简介复习
1. 介绍 YARN(Yet Another Resource Negotiator)是一个通用的资源管理平台,可为各类计算框架提供资源的管理和调度. 之前有提到过,Yarn主要是为了减轻Hadoop ...
- Hadoop mapreduce框架简介
传统hadoop MapReduce架构(老架构) 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 1.首先用户程序 (JobClient) 提交了一个 job,job ...
- Hadoop主要生态系统简介
Hadoop的起源 Doug Cutting是Hadoop之父 ,起初他开创了一个开源软件Lucene(用Java语言编写,提供了全文检索引擎的架构,与Google类似),Lucene后来面临与Goo ...
- hadoop(十一)HDFS简介和常用命令介绍
HDFS背景 随着数据量的增大,在一个操作系统中内存不了了,就需要分配到操作系统的的管理磁盘中,但是不方便管理者维护,迫切需要一种系统来管理多态机器上的文件,这就是分布式文件管理系统. HDFS的概念 ...
- hadoop学习笔记(一):hadoop生态系统及简介
一.hadoop1.x的生态系统 HBase:实时分布式数据库 相当于关系型数据库,数据放在文件中,文件就放在HDFS中.因此HBase是基于HDFS的关系型数据库.实时性:延迟非常低,实时性高. 举 ...
- 【hadoop】——window下elicpse连接hadoop集群基础超详细版
1.Hadoop开发环境简介 1.1 Hadoop集群简介 Java版本:jdk-6u31-linux-i586.bin Linux系统:CentOS6.0 Hadoop版本:hadoop-1.0.0 ...
随机推荐
- java之静态代理
© 版权声明:本文为博主原创文章,转载请注明出处 定义: - 为其他对象提供一种代理以控制对这个对象的访问 组成: 抽象角色:通过接口或抽象类声明真正角色实现的业务方法 真实角色:实现抽象角色,定义真 ...
- 【cogs182】【USACO Jan07】均衡队形【st表】
题目描写叙述 农夫约翰的 N (1 ≤ N ≤ 50,000) 头奶牛,每天挤奶时总会按相同的顺序站好. 一日.农夫约翰决定为奶牛们举行一个"终极飞盘"比赛.为简化问题.他将从奶牛 ...
- git学习之安装(二)
安装Git 最早Git是在Linux上开发的,很长一段时间内,Git也只能在Linux和Unix系统上跑.不过,慢慢地有人把它移植到了Windows上.现在,Git可以在Linux.Unix.Mac和 ...
- CentOS VSCode调试go语言出现:exec: "gcc": executable file not found in PATH
CentOS VSCode调试go语言出现:exec: "gcc": executable file not found in PATH 解决方案: 执行如下命令安装GCC,然后重 ...
- java栈的最大深度?
1. 概述 某公司面试,总监大叔过来,问了图论及栈的最大深度,然后^_^ 一直记着,今天搞一下 2. 代码 package com.goodfan.test; public class JavaSta ...
- Teradata架构
Teradata在整体上是按Shared Nothing 架构体系进行组织的,他的定位就是大型数据仓库系统,定位比较高,他的软硬件都是NCR自己的,其他的都不识别:所以一般的企业用不起,价格很贵.由于 ...
- 嵌入式数据库H2的安装与配置
一.配置JAVA环境 1.首先检查系统是否自带JDK 使用命令:#java -version 没有信息即为没有安装,如有且版本较低,可采用如下方式卸载: 查看命令: rpm -qa | grep ja ...
- Linux进程间通信(五) - 信号灯(史上最全)及其经典应用案例
信号灯概述 什么是信号灯 信号灯用来实现同步,用于多线程,多进程之间同步共享资源(临界资源). PV原语:信号灯使用PV原语 P原语操作的动作是: u sem减1. u sem减1后仍大于或等于零 ...
- apache常用模块介绍
mod_actions 基于媒体类型或请求方法,为执行CGI脚本而提供 mod_alias 提供从文件系统的不同部分到文档树的映射和URL重定向 mod_asis 发送自己包含HTTP头内容的文件 ...
- uitableview滚动到最后一行
本文转载至 http://mrjeye.iteye.com/blog/1278521 - (void)scrollTableToFoot:(BOOL)animated { NSInteger s = ...