Hadoop- MR的shuffle过程
step1 input
InputFormat读取数据,将数据转换成<key ,value>对,设置FileInputFormat,默认是文本格式(TextInputFormat)
step2 map
map<KEYIN, VALUEIN, KEYOUT, VALUEOUT> 默认情况下KEYIN:LongWritable,偏移量。VALUEIN:Text,KEYOUT与VALUEOUT要根据我们的具体的业务来定。
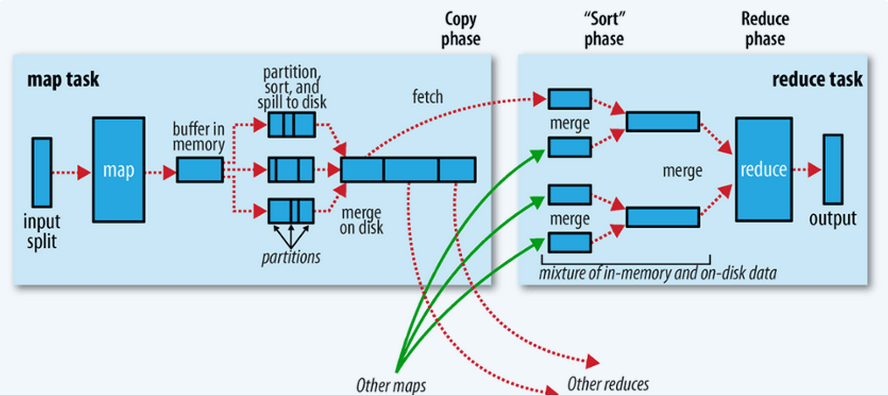
step3 shuffle
map输出到reduce之前这个阶段是mr的shuffle阶段。
map输出的<key , value>对首先放在内存中,当达到一定的内存大小,就会溢写(spill)到本地磁盘中,可能有很多文件。spill过程有两个操作,分区(partition)和排序(sort)。当map task结束后可能有很多的小文件,spill。那么我们需要对这些文件合并(merge),排序成一个大文件。此时map阶段才结束。
Reduce task 会到Map Task运行的机器上,拷贝要处理的数据。然后合并(merge),排序,分组(group)将相同key 的value 放在一起,完成了reduce 数据输入的过程。
step4 reduce
reduce<KEYIN, VALUEIN, KEYOUT, VALUEOUT>,map输出的<key , value>数据类型与reduce输入<key , value>的数据类型一致。
接下来就是执行Reducer 定义的方法了
step5 output
TextOutputFormat
最后将结果输出到文件系统上,每个< key , value >对, key与value中间分隔符为\t,默认调用 key 和 value 的 toString() 方法。
我们可以在map端输出文件压缩,可设置,combiner(map端的reduce)。
Hadoop- MR的shuffle过程的更多相关文章
- Hadoop学习之shuffle过程
转自:http://langyu.iteye.com/blog/992916,多谢分享,学习Hadopp性能调优的可以多关注一下 Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方, ...
- Hadoop MapReduce的Shuffle过程
一.概述 理解Hadoop的Shuffle过程是一个大数据工程师必须的,笔者自己将学习笔记记录下来,以便以后方便复习查看. 二. MapReduce确保每个reducer的输入都是按键排序的.系统执行 ...
- Hadoop Mapreduce的shuffle过程详解
1.map task读取数据时默认调用TextInputFormat的成员RecoreReader,RecoreReader调用自己的read()方法,进行逐行读取,返回一个key.value; 2. ...
- Hadoop学习笔记—10.Shuffle过程那点事儿
一.回顾Reduce阶段三大步骤 在第四篇博文<初识MapReduce>中,我们认识了MapReduce的八大步骤,其中在Reduce阶段总共三个步骤,如下图所示: 其中,Step2.1就 ...
- Shuffle过程
Shuffle过程 在MapReduce框架中,shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过shuffle这个环节,shuffle的性能高低直接影响了整 ...
- 【Big Data - Hadoop - MapReduce】通过腾讯shuffle部署对shuffle过程进行详解
摘要: 通过腾讯shuffle部署对shuffle过程进行详解 摘要:腾讯分布式数据仓库基于开源软件Hadoop和Hive进行构建,TDW计算引擎包括两部分:MapReduce和Spark,两者内部都 ...
- 剖析Hadoop和Spark的Shuffle过程差异
一.前言 对于基于MapReduce编程范式的分布式计算来说,本质上而言,就是在计算数据的交.并.差.聚合.排序等过程.而分布式计算分而治之的思想,让每个节点只计算部分数据,也就是只处理一个分片,那么 ...
- 剖析Hadoop和Spark的Shuffle过程差异(一)
一.前言 对于基于MapReduce编程范式的分布式计算来说,本质上而言,就是在计算数据的交.并.差.聚合.排序等过程.而分布式计算分而治之的思想,让每个节点只计算部分数据,也就是只处理一个分片,那么 ...
- Hadoop计算中的Shuffle过程(转)
Hadoop计算中的Shuffle过程 作者:左坚 来源:清华万博 时间:2013-07-02 15:04:44.0 Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方.要想理解Ma ...
- hadoop的shuffle过程
1. shuffle: 洗牌.发牌——(核心机制:数据分区,排序,缓存): shuffle具体来说:就是将maptask输出的处理结果数据,分发给reducetask,并在分发的过程中,对数据按key ...
随机推荐
- Java基础IO流
流 流的本质是数据传输,根据数据传输特性将流抽象为各种类,方便更直观的进行数据操作.IO流最终要以对象来体现,对象都存在IO包中. IO流的分类 根据处理数据类型的不同分为:字符流和字节流 根据数据流 ...
- setpgid()
#include<unistd.h> int setpgid(pid_t pid,pid_t pgid); 函数作用:将pid进程的进程组ID设置成pgid,创建一个新进程组或加入一个已存 ...
- lua table库
整理自:http://www.cnblogs.com/whiteyun/archive/2009/08/10/1543139.html 1.table.concat(table, sep, st ...
- linux svn 更新地址
进行你所工作的svn映射到本地的目录中.在终端下运行$svn switch --relocate http://oldPath http://newpath.系统提示输入用户名,密码.重新输入后,即可 ...
- 【Mysql】之基础sql语句模板
==============新建数据库============ create database if not exists XXX; ==============删除数据库============ d ...
- android 自定义 listView
目录: 1.主布局 ListView <?xml version="1.0" encoding="utf-8"?><RelativeLayou ...
- 读《《图解TCP-IP》》有感
读<<图解TCP/IP>>有感 TCP/IP 近期几天读完<<图解TCP/IP>>,收获蛮多,记得上学时读stevens的<<TCP/IP具 ...
- POJ1942
Paths on a Grid Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 24236 Accepted: 6006 ...
- Hibernate 表连接hql语句
现有两个表 user 表 和 VIPcard 表 UserVo user VIPcardVo 中含有 UserVo user select v from VIPCardVo v left join ...
- 测试站如何最快获取正式站的最新数据: ln -s
针对静态数据, 比如图片/js等文件, 测试站如何获取最新的呢? ln -s /alidata/www/mysite/uploads /alidata/www/mysite_test/uploads ...