Hadoop学习笔记—6.Hadoop Eclipse插件的使用
开篇:Hadoop是一个强大的并行软件开发框架,它可以让任务在分布式集群上并行处理,从而提高执行效率。但是,它也有一些缺点,如编码、调试Hadoop程序的难度较大,这样的缺点直接导致开发人员入门门槛高,开发难度大。因此,Hadop的开发者为了降低Hadoop的难度,开发出了Hadoop Eclipse插件,它可以直接嵌入到Hadoop开发环境中,从而实现了开发环境的图形界面化,降低了编程的难度。
一、天降神器插件-Hadoop Eclipse

Hadoop Eclipse是Hadoop开发环境的插件,在安装该插件之前需要首先配置Hadoop的相关信息。用户在创建Hadoop程序时,Eclipse插件会自动导入Hadoop编程接口的jar文件,这样用户就可以在Eclipse插件的图形界面中进行编码、调试和运行Hadop程序,也能通过Eclipse插件查看程序的实时状态、错误信息以及运行结果。除此之外,用户还可以通过Eclipse插件对HDFS进行管理和查看。
总而言之,Hadoop Eclipse插件不仅安装简单,使用起来也很方便。它的功能强大,特别在Hadoop编程方面为开发者降低了很大的难度,是Hadoop入门和开发的好帮手!
二、Hadoop Eclipse的开发配置
2.1 获取Hadoop Eclipse插件
(1)为了方便,我们可以直接百度一下,我这里hadoop版本是1.1.2,因此只需要搜索一下hadoop-eclipse-plugin-1.1.2.jar即可,我们可以从下面的链接中下载该插件。
URL:http://download.csdn.net/download/azx321/7330363
(2)将下载下来的插件jar文件放置到eclipse的plugins目录下,然后重新启动eclipse。
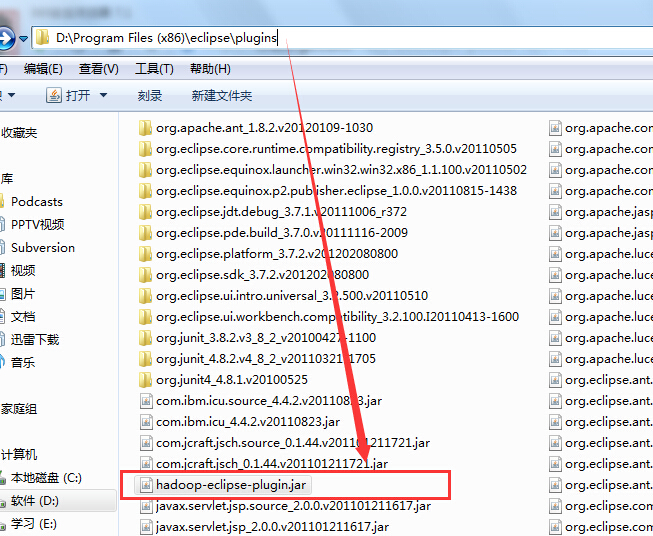
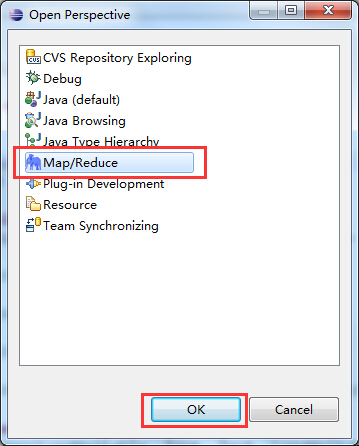
(3)重新启动eclipse之后,单击 按钮,添加hadoop eclipse插件视图按钮:首先选择Other选项,弹出如下图所示的对话框,从中选择Map/Reduce选项,然后单击OK即可。
按钮,添加hadoop eclipse插件视图按钮:首先选择Other选项,弹出如下图所示的对话框,从中选择Map/Reduce选项,然后单击OK即可。
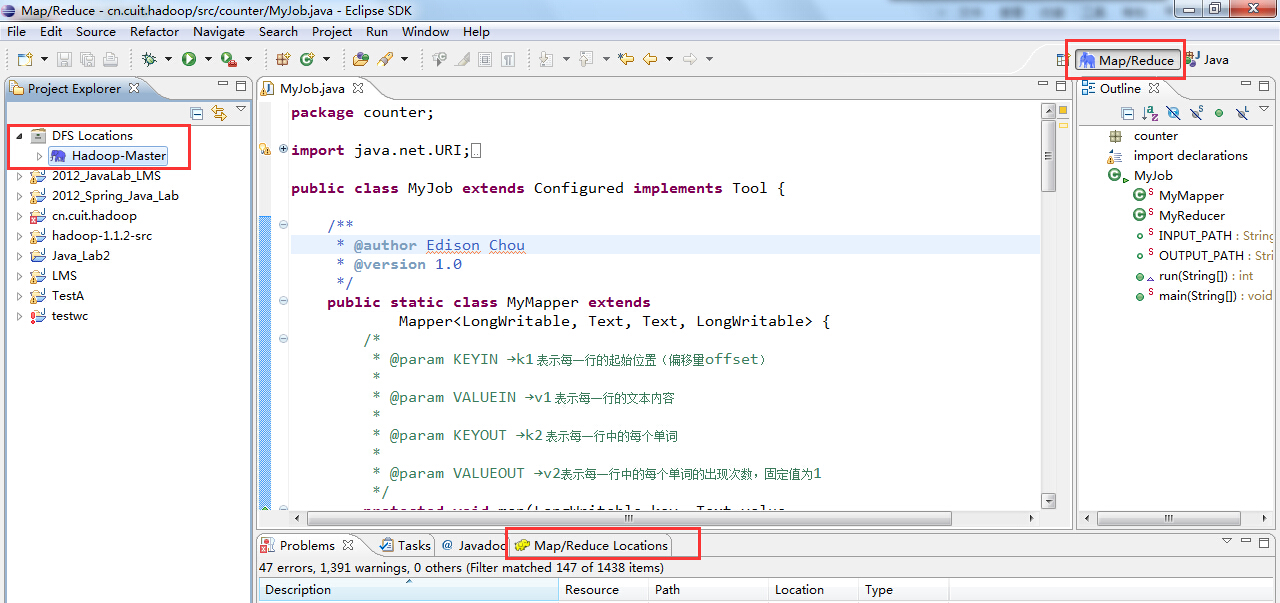
(4)添加完成后,eclipse中就会多出一个Map/Reduce视图按钮,我们可以点击进入Map/Reduce工作目录视图:
2.2 Hadoop Eclipse插件的基本配置
(1)设置Hadoop的安装目录
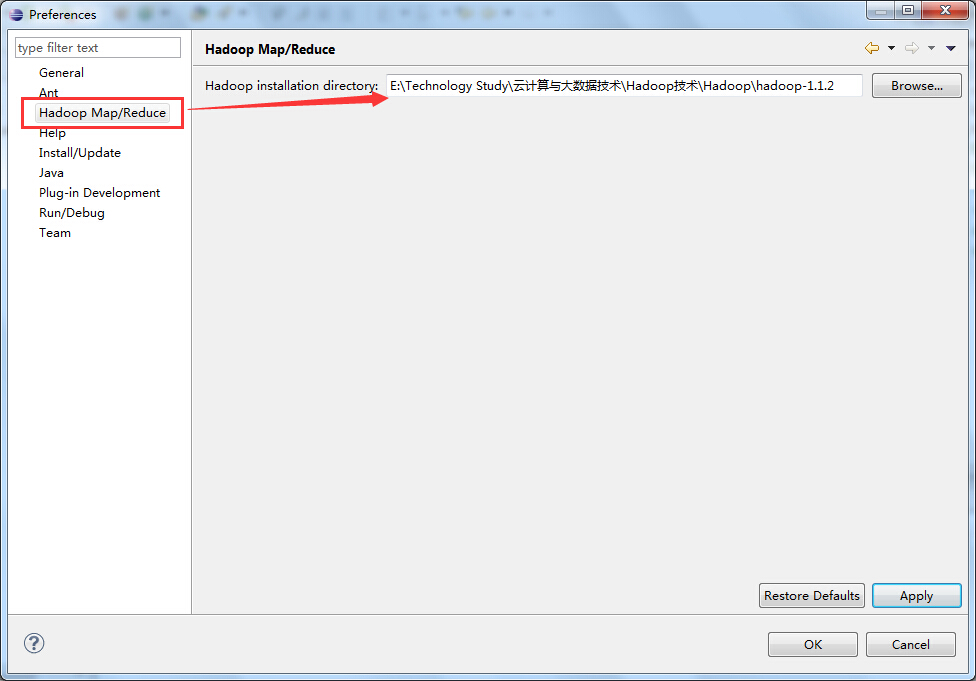
在eclipse中选择Windows→Preference按钮,弹出一个对话框,在该对话框左侧会多出一个Hadoop Map/Reduce选项,然后单击此选项,在右侧设置Hadoop的安装目录。
(2)设置Hadoop的集群信息
这里需要与Hadoop集群建立连接,在Map/Reduce Locations界面中右击,弹出选项条,选择New Hadoop Location选项;
在弹出的对话框中填写连接hadoop集群的信息,如下图所示:

在上图所示的红色区域是我们需要关注的地方,也是我们需要好好填写的地方。
PS:Location name: 这个随便填写,我填写的是我的Hadoop Master节点的主机名;
Map/Reduce Master 这个框里:
Host:就是jobtracker 所在的集群机器,我这里是192.168.80.100
Hort:就是jobtracker 的port,这里写的是9001(默认的端口号)
这两个参数就是mapred-site.xml里面mapred.job.tracker里面的ip和port;DFS Master 这个框里:
Host:就是namenode所在的集群机器,我这里由于是伪分布,都在192.168.80.100上面
Port:就是namenode的port,这里写9000(默认的端口号)
这两个参数就是core-site.xml里面fs.default.name里面的ip和port
(Use M/R master host,这个复选框如果选上,就默认和Map/Reduce Master这个框里的host一样,如果不选择,就可以自己定义输入,这里jobtracker 和namenode在一个机器上,所以是一样的,就勾选上)User name:这个是连接hadoop的用户名,我这里是root用户;
接下来,单击Advanced parameters选项卡中的hadoop.tmp.dir选项,修改为你的Hadoop集群中设置的地址,我这里Hadoop集群中设置的地址是/usr/local/hadoop/tmp,然后单击Finish按钮(这个参数在core-site.xml中进行了配置)

PS:Advanced parameters选项卡中大部分的属性都已经自动填写上了,其实就是把那几个核心xml配置文件里面的一些配置属性展示出来。
刚刚的配置完成后,返回eclipse中,我们可以看到在Map/Reduce Locations下面就会多出来一个Hadoop-Master的连接项,这就是刚刚建立的名为Hadoop-Master的Map/Reduce Location连接,如下图所示:

2.3 查看HDFS
(1)通过选择eclipse左侧的DFS Locations下面的Hadoop-Master选项,就会展示出HDFS中的文件结构;
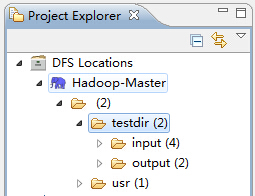
(2)这里在testdir文件夹处右击选择一个指定的文件,如下图所示:
三、在Eclipse下运行WordCount程序
3.1 创建Map/Reduce项目
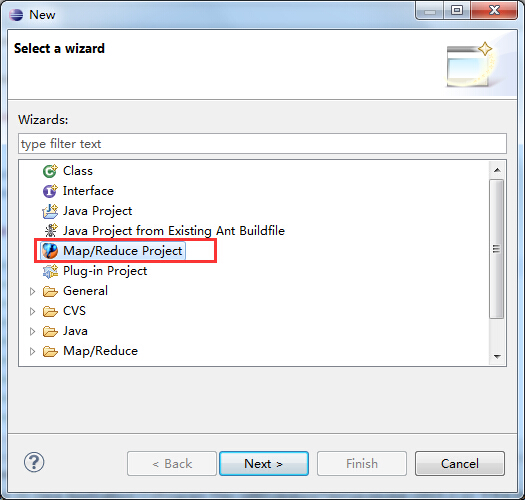
选择File→Other命令,找到Map/Reduce Project,然后选择它,如下所示:
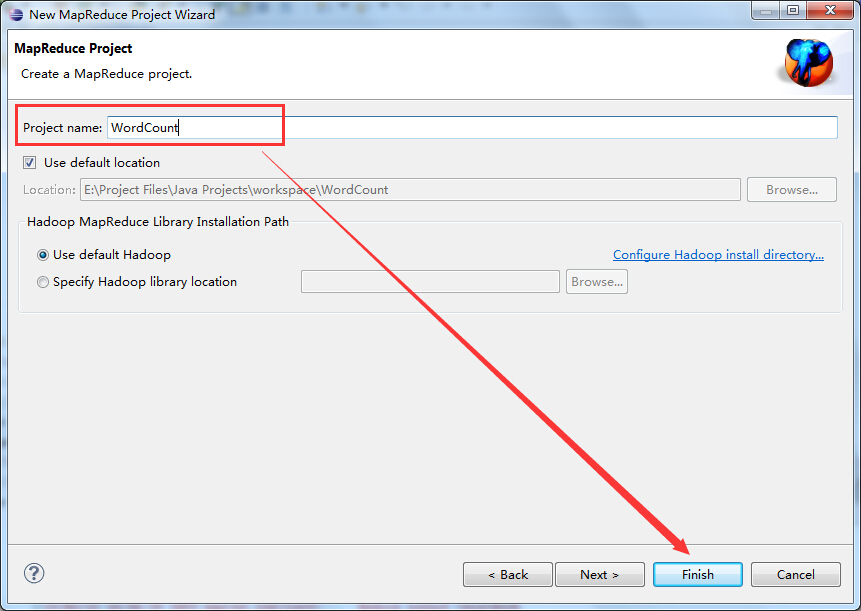
输入Map/Reduce工程的名称,这里取为:WordCount,单击Finish按钮完成,如下图所示:
3.2 创建WordCount类
这里新建一个WordCount类,输入以下代码:
public class WordCount extends Configured implements Tool {
/**
* @author Edison Chou
* @version 1.0
*/
public static class MyMapper extends
Mapper<LongWritable, Text, Text, LongWritable> {
/*
* @param KEYIN →k1 表示每一行的起始位置(偏移量offset)
*
* @param VALUEIN →v1 表示每一行的文本内容
*
* @param KEYOUT →k2 表示每一行中的每个单词
*
* @param VALUEOUT →v2表示每一行中的每个单词的出现次数,固定值为1
*/
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws java.io.IOException, InterruptedException {
Counter sensitiveCounter = context.getCounter("Sensitive Words:", "Hello");
String line = value.toString();
// 这里假定Hello是一个敏感词
if(line.contains("Hello")){
sensitiveCounter.increment(1L);
}
String[] spilted = line.split(" ");
for (String word : spilted) {
context.write(new Text(word), new LongWritable(1L));
}
};
}
/**
* @author Edison Chou
* @version 1.0
*/
public static class MyReducer extends
Reducer<Text, LongWritable, Text, LongWritable> {
/*
* @param KEYIN →k2 表示每一行中的每个单词
*
* @param VALUEIN →v2 表示每一行中的每个单词的出现次数,固定值为1
*
* @param KEYOUT →k3表示每一行中的每个单词
*
* @param VALUEOUT →v3 表示每一行中的每个单词的出现次数之和
*/
protected void reduce(Text key,
java.lang.Iterable<LongWritable> values,
Reducer<Text, LongWritable, Text, LongWritable>.Context context)
throws java.io.IOException, InterruptedException {
long count = 0L;
for (LongWritable value : values) {
count += value.get();
}
context.write(key, new LongWritable(count));
};
}
// 输入文件路径
public static String INPUT_PATH = "hdfs://hadoop-master:9000/testdir/input/words.txt";
// 输出文件路径
public static String OUTPUT_PATH = "hdfs://hadoop-master:9000/testdir/output/wordcount";
@Override
public int run(String[] args) throws Exception {
// 首先删除输出路径的已有生成文件
FileSystem fs = FileSystem.get(new URI(INPUT_PATH), getConf());
Path outPath = new Path(OUTPUT_PATH);
if (fs.exists(outPath)) {
fs.delete(outPath, true);
}
Job job = new Job(getConf(), "WordCount");
// 设置输入目录
FileInputFormat.setInputPaths(job, new Path(INPUT_PATH));
// 设置自定义Mapper
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 设置自定义Reducer
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 设置输出目录
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH));
System.exit(job.waitForCompletion(true) ? 0 : 1);
return 0;
}
public static void main(String[] args) {
Configuration conf = new Configuration();
try {
int res = ToolRunner.run(conf, new WordCount(), args);
System.exit(res);
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.3 运行WordCount程序
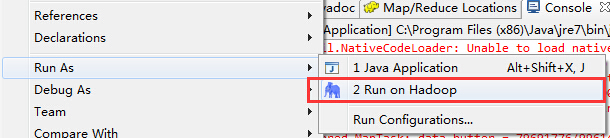
选择WordCount并右击,选择Run on Hadoop方式运行,如下图所示:
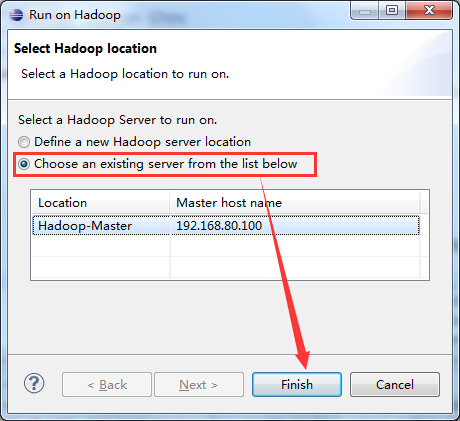
运行结果如下图所示:

3.4 查看HDFS中的运行结果
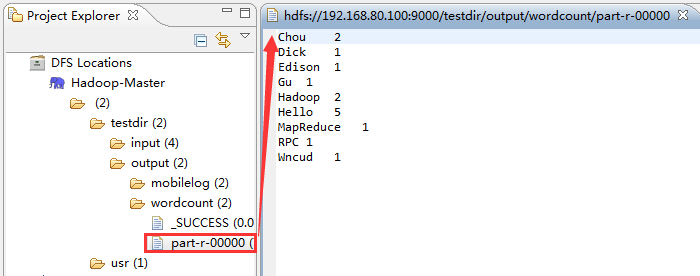
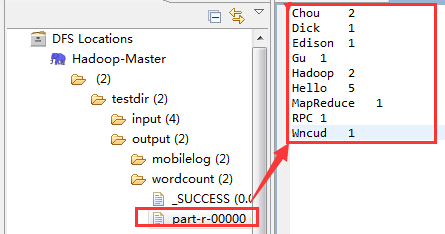
打开设定的输出文件夹output下的part-r-00000文件,就是WordCount程序的执行结果,如下图所示:
参考资料
(1)万川梅、谢正兰,《Hadoop应用开发实战详解(修订版)》:http://item.jd.com/11508248.html
(2)cybercode,《eclipse hadoop开发环境配置》:http://blog.csdn.net/cybercode/article/details/7084603
Hadoop学习笔记—6.Hadoop Eclipse插件的使用的更多相关文章
- [转帖]hadoop学习笔记:hadoop文件系统浅析
hadoop学习笔记:hadoop文件系统浅析 https://www.cnblogs.com/sharpxiajun/archive/2013/06/15/3137765.html 1.什么是分布式 ...
- Hadoop学习笔记【Hadoop家族成员概述】
Hadoop家族成员概述 一.Hadoop简介 1.1 什么是Hadoop? Hadoop是一个分布式系统基础架构,由Apache基金会所开发,目前Yahoo!是其最重要的贡献者. Hadoop实现了 ...
- 吴裕雄--天生自然HADOOP学习笔记:hadoop集群实现PageRank算法实验报告
实验课程名称:大数据处理技术 实验项目名称:hadoop集群实现PageRank算法 实验类型:综合性 实验日期:2018年 6 月4日-6月14日 学生姓名 吴裕雄 学号 15210120331 班 ...
- Hadoop学习笔记—3.Hadoop RPC机制的使用
一.RPC基础概念 1.1 RPC的基础概念 RPC,即Remote Procdure Call,中文名:远程过程调用: (1)它允许一台计算机程序远程调用另外一台计算机的子程序,而不用去关心底层的网 ...
- [Hadoop] Hadoop学习笔记之Hadoop基础
1 Hadoop是什么? Google公司发表了两篇论文:一篇论文是“The Google File System”,介绍如何实现分布式地存储海量数据:另一篇论文是“Mapreduce:Simplif ...
- Hadoop学习笔记(3) Hadoop I/O
1. HDFS的数据完整性 HDFS会对写入的所有数据计算校验和,并在读取数据时验证校验和.datanode负责在验证收到的数据后存储数据及其校验和.正在写数据的客户端将数据及其校验和发送到由一系列d ...
- Hadoop学习笔记(3) Hadoop文件系统二
1 查询文件系统 (1) 文件元数据:FileStatus,该类封装了文件系统中文件和目录的元数据,包括文件长度.块大小.备份.修改时间.所有者以及版权信息.FileSystem的getFileSta ...
- Hadoop学习笔记(3) Hadoop文件系统一
1. 分布式文件系统,即为管理网络中跨多台计算机存储的文件系统.HDFS以流式数据访问模式来存储超大文件,运行于商用硬件集群上.HDFS的构建思路为:一次写入.多次读取是最高效的访问模式.数据集通常由 ...
- 吴裕雄--天生自然Hadoop学习笔记:Hadoop简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速运算和存储.Hadoop实现了一个分布式文件系统(H ...
随机推荐
- [转]序列化悍将Protobuf-Net,入门动手实录
最近在研究web api 2,看了一篇文章,讲解如何提升性能的, 在序列化速度的跑分中,Protobuf一骑绝尘,序列化速度快,性能强,体积小,所以打算了解下这个利器 1:安装篇 谷歌官方没有提供.n ...
- SVN使用教程之-分支/标记 合并 subeclipse (转)
首先说下为什么我们需要用到分支-合 并.比如项目demo下有两个小组,svn下有一个trunk版.由于客户需求突然变化,导致项目需要做较大改动,此时项目组决定由小组1继续完成原来正 进行到一半的工作[ ...
- Matlab 读取文件夹中所有的bmp文件
将srcimg文件下的bmp文件转为jpg图像,存放在dstimg文件夹下 str = 'srcimg'; dst = 'dstimg'; file=dir([str,'\*.bmp']); :len ...
- 高性能的JavaScript--加载和执行
写在前面 JavaScript在浏览器中的性能,可认为是开发者所要面对的最重要的可用性的问题,此问题因JavaScript的阻塞特征而复杂,也就是说JavaScript运行时其他的事情不能被浏览器处理 ...
- Java 之 常用类(二)
1.StringBuffer a.StringBuffer 与 String:①StringBuffer是一个全新的类型,与String没有继承关系 ②StringBuffer的出现是为了解决Stri ...
- [leetcode] 390 Elimination Game
很开心,自己想出来的一道题 There is a list of sorted integers from 1 to n. Starting from left to right, remove th ...
- python遍历一个网段的ip地址
def ip2num(ip):#ip to int num lp = [int(x) for x in ip.split('.')] return lp[0] << 24 | lp[1] ...
- iOS Swift 数组 交换元素的两种方法
swap(&arr[fromIndexPath.row], &arr[to.row]) (arr[fromIndexPath.row],arr[to.row]) = (arr[to.r ...
- C# DataGridView绑定数据源
第一种: DataSet ds=new DataSet (); ]; 第二种: DataTable dt=new DataTable(); this.dataGridView1.DataSource= ...
- elasticsearch-1.3.0 之索引代码粗略梳理
elasticsearch-1.3.0 发送请求 创建 [root@centos ~]# curl -XPUT 172.16.136.159:9200/customer?pretty { " ...