通过IDEA及hadoop平台实现k-means聚类算法
由于实验室任务方向变更,本文不再更新~
有段时间没有操作过,发现自己忘记一些步骤了,这篇文章会记录相关步骤,并随时进行补充修改。
1 基础步骤,即相关环境部署及数据准备
数据文件类型为.csv文件,excel直接另存为即可,以逗号为分隔符
2 IDEA编辑代码,打jar包
参考以下链接:
IntelliJ IDEA Windows下Spark开发环境部署
k-means聚类代码参考:
package main.scala.yang.spark
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.clustering.KMeans
object KMeansBeijing {
def main(args: Array[String]): Unit = {
// 屏蔽不必要的日志显示在终端上
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
// 设置运行环境
val conf = new SparkConf().setMaster("local").setAppName("KMeansBeijing")
val sc = new SparkContext(conf)
// 装载数据集
val data = sc.textFile("file:///home/hadoop/yang/USA/AUG_tag.csv", 1)
val parsedData = data.filter(!isColumnNameLine(_)).map(line => Vectors.dense(line.split(',').map(_.toDouble))).cache()
//
// 将数据集聚类,7个类,20次迭代,进行模型训练形成数据模型
val numClusters = 4
val numIterations = 800
val model = KMeans.train(parsedData, numClusters, numIterations)
// 打印数据模型的中心点
println("Cluster centers:")
for (c <- model.clusterCenters) {
println(" " + c.toString)
}
// 使用误差平方之和来评估数据模型
val cost = model.computeCost(parsedData)
println("Within Set Sum of Squared Errors = " + cost)
// // 使用模型测试单点数据
// println("Vectors 0.2 0.2 0.2 is belongs to clusters:" + model.predict(Vectors.dense("0.2 0.2 0.2".split(' ').map(_.toDouble))))
// println("Vectors 0.25 0.25 0.25 is belongs to clusters:" + model.predict(Vectors.dense("0.25 0.25 0.25".split(' ').map(_.toDouble))))
// println("Vectors 8 8 8 is belongs to clusters:" + model.predict(Vectors.dense("8 8 8".split(' ').map(_.toDouble))))
// 交叉评估1,只返回结果
val testdata = data.filter(!isColumnNameLine(_)).map(s => Vectors.dense(s.split(',').map(_.toDouble)))
val result1 = model.predict(testdata)
result1.saveAsTextFile("file:///home/hadoop/yang/USA/AUG/result1")
// 交叉评估2,返回数据集和结果
val result2 = data.filter(!isColumnNameLine(_)).map {
line =>
val linevectore = Vectors.dense(line.split(',').map(_.toDouble))
val prediction = model.predict(linevectore)
line + " " + prediction
}.saveAsTextFile("file:///home/hadoop/yang/USA/AUG/result2")
sc.stop()
}
private def isColumnNameLine(line: String): Boolean = {
if (line != null && line.contains("Electricity")) true
else false
}
}
3 通过WinSCP将jar包上传到hadoop平台本地服务器上
注:直接拖拽即可
4 通过SecureCRT在hadoop平台上执行相关命令
4.1 进入spark文件夹下

4.2 通过spark-submit命令提交任务(jar包)到集群
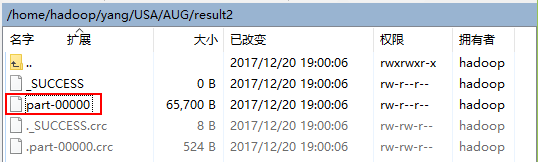
4.3 通过WinSCP查看结果
注:4.1和4.2可以综合在一条命令中:
通过IDEA及hadoop平台实现k-means聚类算法的更多相关文章
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
- K均值聚类算法
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个 ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- K均值聚类算法的MATLAB实现
1.K-均值聚类法的概述 之前在参加数学建模的过程中用到过这种聚类方法,但是当时只是简单知道了在matlab中如何调用工具箱进行聚类,并不是特别清楚它的原理.最近因为在学模式识别,又重新接触了这 ...
- 机器学习实战5:k-means聚类:二分k均值聚类+地理位置聚簇实例
k-均值聚类是非监督学习的一种,输入必须指定聚簇中心个数k.k均值是基于相似度的聚类,为没有标签的一簇实例分为一类. 一 经典的k-均值聚类 思路: 1 随机创建k个质心(k必须指定,二维的很容易确定 ...
- 机器学习理论与实战(十)K均值聚类和二分K均值聚类
接下来就要说下无监督机器学习方法,所谓无监督机器学习前面也说过,就是没有标签的情况,对样本数据进行聚类分析.关联性分析等.主要包括K均值聚类(K-means clustering)和关联分析,这两大类 ...
- 机器学习之K均值聚类
聚类的核心概念是相似度或距离,有很多相似度或距离的方法,比如欧式距离.马氏距离.相关系数.余弦定理.层次聚类和K均值聚类等 1. K均值聚类思想 K均值聚类的基本思想是,通过迭代的方法寻找K个 ...
- 100天搞定机器学习|day44 k均值聚类数学推导与python实现
[如何正确使用「K均值聚类」? 1.k均值聚类模型 给定样本,每个样本都是m为特征向量,模型目标是将n个样本分到k个不停的类或簇中,每个样本到其所属类的中心的距离最小,每个样本只能属于一个类.用C表示 ...
- 聚类之K均值聚类和EM算法
这篇博客整理K均值聚类的内容,包括: 1.K均值聚类的原理: 2.初始类中心的选择和类别数K的确定: 3.K均值聚类和EM算法.高斯混合模型的关系. 一.K均值聚类的原理 K均值聚类(K-means) ...
随机推荐
- win10/server2019 系统安装 详解
https://www.microsoft.com/zh-cn/software-download/windows10 https://go.microsoft.com/fwlink/?LinkId= ...
- nignx 重启
sudo /opt/nginx/sbin/nginx -s stop sudo /opt/nginx/sbin/nginx
- C Primer Plus学习笔记(八)- 函数
函数简介 函数(function)是完成特定任务的独立程序代码单元 使用函数可以省去编写重复代码的苦差,函数能让程序更加模块化,提高程序代码的可读性,更方便后期修改.完善 #include <s ...
- SUSE eth0 No such device
删除 etc/udev/rules.d/70-persistent-net.rules 文件 之后重启让系统重新生成eth0配置文件 rm -f etc/udev/rules.d/70-persis ...
- QTP11使用DOM XPath以及CSS识别元素对象
我们知道,像DOM,Html,CSS,XPath等对对象的识别策略广泛运用于一些开源的工具,例如:Selenium,Watir,Watir-Webdriver,以前qtp版本是不支持这些东西的,现在q ...
- 第一章 深入Web请求过程(待续)
B/S网络架构概述 如何发起一个请求 HTTP解析 DNS域名解析 CDN工作机制
- delphi 蓝牙 TBluetoothLE
delphi 蓝牙 TBluetoothLE.TBluetoothLEManager BLE http://docwiki.embarcadero.com/RADStudio/Seattle/en/U ...
- Shell编程进阶 1.4 shell自定义变量
变量 系统自带变量 echo $PATH $HOME $PWD 自定义变量 # a= # echo $a1 # b= # echo $b2 写与用户交互的脚本 vim .sh #!/bin/bash ...
- (修改)oracle11g监听多台主机配置,用pl/sql连接操作多个数据库详解
很多朋友在开发项目中并不是每个人用一个数据库,而是有单独的一台主机作为开发的数据库服务器,这样,就需要我们的开发人员去连接它. 首先是进入oracle的 Net Mananger:
- 【转】TinyMCE(富文本编辑器)
效果预览:http://www.tinymce.com/tryit/full.php [转]TinyMCE(富文本编辑器)在Asp.Net中的使用方法 转自:http://www.cnblogs.co ...