hadoop报错java.io.IOException: Incorrect configuration: namenode address dfs.namenode.servicerpc-address or dfs.namenode.rpc-address is not configured
不多说,直接上干货!
问题详情
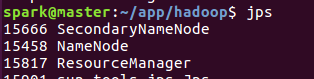


问题排查
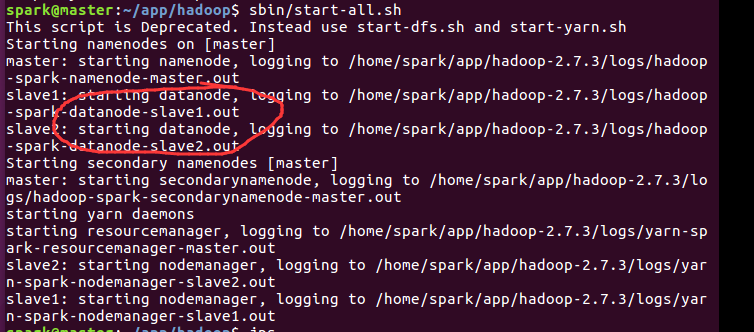
spark@master:~/app/hadoop$ sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /home/spark/app/hadoop-2.7./logs/hadoop-spark-namenode-master.out
slave1: starting datanode, logging to /home/spark/app/hadoop-2.7./logs/hadoop-spark-datanode-slave1.out
slave2: starting datanode, logging to /home/spark/app/hadoop-2.7./logs/hadoop-spark-datanode-slave2.out
Starting secondary namenodes [master]
master: starting secondarynamenode, logging to /home/spark/app/hadoop-2.7./logs/hadoop-spark-secondarynamenode-master.out
starting yarn daemons
starting resourcemanager, logging to /home/spark/app/hadoop-2.7./logs/yarn-spark-resourcemanager-master.out
slave2: starting nodemanager, logging to /home/spark/app/hadoop-2.7./logs/yarn-spark-nodemanager-slave2.out
slave1: starting nodemanager, logging to /home/spark/app/hadoop-2.7./logs/yarn-spark-nodemanager-slave1.out
spark@master:~/app/hadoop$ jps
SecondaryNameNode
NameNode
ResourceManager
sun.tools.jps.Jps
spark@master:~/app/hadoop$
解决办法
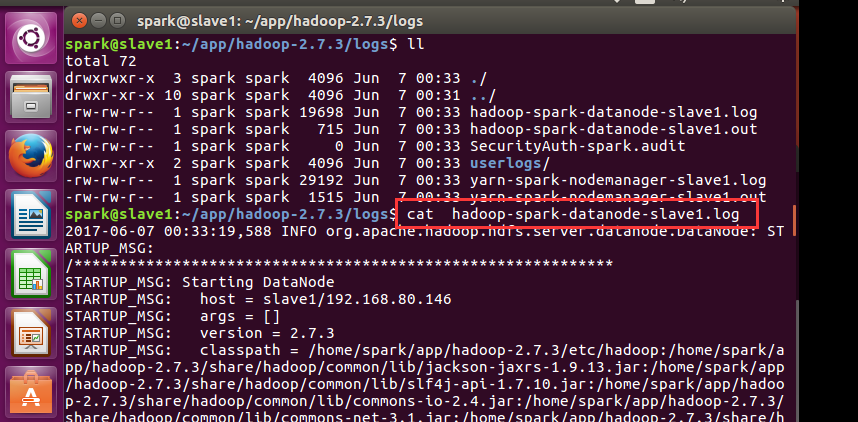
spark@slave1:~/app/hadoop-2.7./logs$ cat hadoop-spark-datanode-slave1.log
-- ::, INFO org.apache.hadoop.hdfs.server.datanode.DataNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting DataNode
STARTUP_MSG: host = slave1/192.168.80.146
STARTUP_MSG: args = []
STARTUP_MSG: version = 2.7.3
STARTUP_MSG: classpath = /home/spark/app/hadoop-2.7.3/etc/hadoop:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/slf4j-api-1.7.10.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/commons-io-2.4.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/commons-net-3.1.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/jersey-server-1.9.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/commons-configuration-1.6.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/jackson-core-asl-1.9.13.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/hamcrest-core-1.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/snappy-java-1.0.4.1.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/commons-digester-1.8.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/guava-11.0.2.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/apacheds-i18n-2.0.0-M15.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/gson-2.2.4.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/netty-3.6.2.Final.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/servlet-api-2.5.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/jackson-xc-1.9.13.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/hadoop-auth-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/jsp-api-2.1.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/httpclient-4.2.5.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/commons-collections-3.2.2.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/xmlenc-0.52.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/jersey-core-1.9.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/curator-client-2.7.1.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/jsch-0.1.42.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/httpcore-4.2.5.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/commons-cli-1.2.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/commons-lang-2.6.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/jets3t-0.9.0.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/activation-1.1.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/xz-1.0.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/commons-logging-1.1.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/paranamer-2.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/commons-compress-1.4.1.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/curator-framework-2.7.1.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/asm-3.2.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/junit-4.11.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/api-asn1-api-1.0.0-M20.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/curator-recipes-2.7.1.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/jersey-json-1.9.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/commons-math3-3.1.1.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/avro-1.7.4.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/zookeeper-3.4.6.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/commons-beanutils-1.7.0.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/commons-beanutils-core-1.8.0.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/commons-httpclient-3.1.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/stax-api-1.0-2.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/jetty-6.1.26.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/commons-codec-1.4.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/jettison-1.1.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/hadoop-annotations-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/jetty-util-6.1.26.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/jaxb-api-2.2.2.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/mockito-all-1.8.5.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/log4j-1.2.17.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/api-util-1.0.0-M20.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/lib/jsr305-3.0.0.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/hadoop-common-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/hadoop-common-2.7.3-tests.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/common/hadoop-nfs-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-io-2.4.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/htrace-core-3.1.0-incubating.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/jackson-mapper-asl-1.9.13.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/jersey-server-1.9.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/jackson-core-asl-1.9.13.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/leveldbjni-all-1.8.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/guava-11.0.2.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/netty-3.6.2.Final.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/servlet-api-2.5.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/xmlenc-0.52.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/jersey-core-1.9.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/netty-all-4.0.23.Final.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/asm-3.2.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/xercesImpl-2.9.1.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/xml-apis-1.3.04.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/jetty-6.1.26.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-codec-1.4.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/jetty-util-6.1.26.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/lib/jsr305-3.0.0.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/hadoop-hdfs-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/hadoop-hdfs-nfs-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/hdfs/hadoop-hdfs-2.7.3-tests.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/jackson-jaxrs-1.9.13.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/commons-io-2.4.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/jackson-mapper-asl-1.9.13.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/jersey-server-1.9.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/jackson-core-asl-1.9.13.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/leveldbjni-all-1.8.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/guava-11.0.2.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/netty-3.6.2.Final.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/servlet-api-2.5.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/zookeeper-3.4.6-tests.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/jackson-xc-1.9.13.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/commons-collections-3.2.2.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/jersey-core-1.9.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/jersey-guice-1.9.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/commons-cli-1.2.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/commons-lang-2.6.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/activation-1.1.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/xz-1.0.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/aopalliance-1.0.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/commons-logging-1.1.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/commons-compress-1.4.1.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/asm-3.2.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/guice-servlet-3.0.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/jaxb-impl-2.2.3-1.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/protobuf-java-2.5.0.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/jersey-json-1.9.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/javax.inject-1.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/jersey-client-1.9.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/zookeeper-3.4.6.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/stax-api-1.0-2.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/jetty-6.1.26.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/commons-codec-1.4.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/jettison-1.1.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/jetty-util-6.1.26.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/guice-3.0.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/jaxb-api-2.2.2.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/log4j-1.2.17.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/lib/jsr305-3.0.0.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-client-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-tests-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-common-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-sharedcachemanager-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-api-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-common-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-registry-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/lib/commons-io-2.4.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/lib/jackson-mapper-asl-1.9.13.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/lib/jackson-core-asl-1.9.13.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/lib/leveldbjni-all-1.8.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/lib/hamcrest-core-1.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/lib/snappy-java-1.0.4.1.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/lib/netty-3.6.2.Final.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/lib/xz-1.0.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/lib/paranamer-2.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/lib/commons-compress-1.4.1.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/lib/asm-3.2.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/lib/junit-4.11.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/lib/protobuf-java-2.5.0.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/lib/javax.inject-1.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/lib/avro-1.7.4.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/lib/hadoop-annotations-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/lib/guice-3.0.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/lib/log4j-1.2.17.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.3-tests.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.7.3.jar:/home/spark/app/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar:/contrib/capacity-scheduler/*.jar:/contrib/capacity-scheduler/*.jar:/contrib/capacity-scheduler/*.jar
STARTUP_MSG: build = https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff; compiled by 'root' on 2016-08-18T01:41Z
STARTUP_MSG: java = 1.8.0_60
************************************************************/
-- ::, INFO org.apache.hadoop.hdfs.server.datanode.DataNode: registered UNIX signal handlers for [TERM, HUP, INT]
-- ::, INFO org.apache.hadoop.metrics2.impl.MetricsConfig: loaded properties from hadoop-metrics2.properties
-- ::, INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Scheduled snapshot period at second(s).
-- ::, INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: DataNode metrics system started
-- ::, INFO org.apache.hadoop.hdfs.server.datanode.BlockScanner: Initialized block scanner with targetBytesPerSec
-- ::, INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Configured hostname is slave1
-- ::, INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Starting DataNode with maxLockedMemory =
-- ::, INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Opened streaming server at /0.0.0.0:
-- ::, INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Balancing bandwith is bytes/s
-- ::, INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Number threads for balancing is
-- ::, INFO org.mortbay.log: Logging to org.slf4j.impl.Log4jLoggerAdapter(org.mortbay.log) via org.mortbay.log.Slf4jLog
-- ::, INFO org.apache.hadoop.security.authentication.server.AuthenticationFilter: Unable to initialize FileSignerSecretProvider, falling back to use random secrets.
-- ::, INFO org.apache.hadoop.http.HttpRequestLog: Http request log for http.requests.datanode is not defined
-- ::, INFO org.apache.hadoop.http.HttpServer2: Added global filter 'safety' (class=org.apache.hadoop.http.HttpServer2$QuotingInputFilter)
-- ::, INFO org.apache.hadoop.http.HttpServer2: Added filter static_user_filter (class=org.apache.hadoop.http.lib.StaticUserWebFilter$StaticUserFilter) to context datanode
-- ::, INFO org.apache.hadoop.http.HttpServer2: Added filter static_user_filter (class=org.apache.hadoop.http.lib.StaticUserWebFilter$StaticUserFilter) to context static
-- ::, INFO org.apache.hadoop.http.HttpServer2: Added filter static_user_filter (class=org.apache.hadoop.http.lib.StaticUserWebFilter$StaticUserFilter) to context logs
-- ::, INFO org.apache.hadoop.http.HttpServer2: Jetty bound to port
-- ::, INFO org.mortbay.log: jetty-6.1.
-- ::, INFO org.mortbay.log: Started HttpServer2$SelectChannelConnectorWithSafeStartup@localhost:
-- ::, INFO org.apache.hadoop.hdfs.server.datanode.web.DatanodeHttpServer: Listening HTTP traffic on /0.0.0.0:
-- ::, INFO org.apache.hadoop.hdfs.server.datanode.DataNode: dnUserName = spark
-- ::, INFO org.apache.hadoop.hdfs.server.datanode.DataNode: supergroup = supergroup
-- ::, INFO org.apache.hadoop.ipc.CallQueueManager: Using callQueue class java.util.concurrent.LinkedBlockingQueue
-- ::, INFO org.apache.hadoop.ipc.Server: Starting Socket Reader # for port
-- ::, INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Opened IPC server at /0.0.0.0:
-- ::, INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Refresh request received for nameservices: null
-- ::, INFO org.mortbay.log: Stopped HttpServer2$SelectChannelConnectorWithSafeStartup@localhost:
-- ::, INFO org.apache.hadoop.ipc.Server: Stopping server on
-- ::, INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Stopping DataNode metrics system...
-- ::, INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: DataNode metrics system stopped.
-- ::, INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: DataNode metrics system shutdown complete.
-- ::, INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Shutdown complete.
-- ::, FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Exception in secureMain
java.io.IOException: Incorrect configuration: namenode address dfs.namenode.servicerpc-address or dfs.namenode.rpc-address is not configured.
at org.apache.hadoop.hdfs.DFSUtil.getNNServiceRpcAddressesForCluster(DFSUtil.java:)
at org.apache.hadoop.hdfs.server.datanode.BlockPoolManager.refreshNamenodes(BlockPoolManager.java:)
at org.apache.hadoop.hdfs.server.datanode.DataNode.startDataNode(DataNode.java:)
at org.apache.hadoop.hdfs.server.datanode.DataNode.<init>(DataNode.java:)
at org.apache.hadoop.hdfs.server.datanode.DataNode.makeInstance(DataNode.java:)
at org.apache.hadoop.hdfs.server.datanode.DataNode.instantiateDataNode(DataNode.java:)
at org.apache.hadoop.hdfs.server.datanode.DataNode.createDataNode(DataNode.java:)
at org.apache.hadoop.hdfs.server.datanode.DataNode.secureMain(DataNode.java:)
at org.apache.hadoop.hdfs.server.datanode.DataNode.main(DataNode.java:)
-- ::, INFO org.apache.hadoop.util.ExitUtil: Exiting with status
-- ::, INFO org.apache.hadoop.hdfs.server.datanode.DataNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down DataNode at slave1/192.168.80.146
************************************************************/
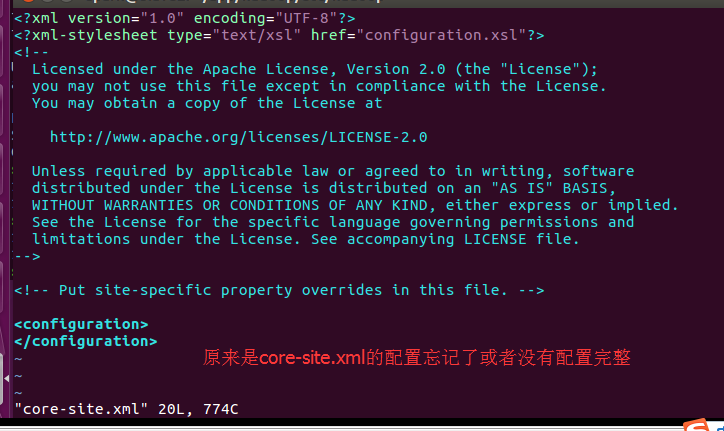
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value></value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hadoop-2.6./tmp</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
成功!
hadoop报错java.io.IOException: Incorrect configuration: namenode address dfs.namenode.servicerpc-address or dfs.namenode.rpc-address is not configured的更多相关文章
- hadoop报错java.io.IOException: Bad connect ack with firstBadLink as 192.168.1.218:50010
[root@linuxmain hadoop]# bin/hadoop jar hdfs3.jar com.dragon.test.CopyToHDFS Java HotSpot(TM) Client ...
- Spark报错java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
Spark 读取 JSON 文件时运行报错 java.io.IOException: Could not locate executable null\bin\winutils.exe in the ...
- Kafka 启动报错java.io.IOException: Can't resolve address.
阿里云上 部署Kafka 启动报错java.io.IOException: Can't resolve address. 本地调试的,报错 需要在本地添加阿里云主机的 host 映射 linux ...
- React Natived打包报错java.io.IOException: Could not delete path '...\android\support\v7'解决
问题详情 React Native打包apk时在第二次编译时候报错: java.io.IOException: Could not delete path 'D:\mycode\reactnative ...
- github提交失败并报错java.io.IOException: Authentication failed:
一.概述 我最近在写一个android的项目. 软件:android studio.Android studio VCS integration(插件) Android studio VCS inte ...
- vue app混合开发蓝牙串口连接(报错java.io.IOException: read failed, socket might closed or timeout, read ret: -1;at android.bluetooth.BluetoothSocket.connect at js/BluetoothTool.js:329)
我使用的uni-app <template> <view class="bluetooth"> <!-- 发送数据 --> <view c ...
- java get请求带参数报错 java.io.IOException: Server returned HTTP response code: 400 for URL
解决方案 在使用JAVA发起http请求的时候,经常会遇到这个错误,我们copy请求地址在浏览器中运行的时候又是正常运行的,造成这个错误的原因主要是因为请求的URL中包含空格,这个时候我们要使用URL ...
- jsp报错java.io.IOException: Stream closed
在使用jsp的时候莫名其妙的抛出了这个异常,经过反复检查 去掉了网友们说的jsp使用流未关闭,以及tomcat版本冲突等原因,最后发现是书写格式的原因. 当时使用的代码如下 <jsp:inclu ...
- Spark- ERROR Shell: Failed to locate the winutils binary in the hadoop binary path java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
运行 mport org.apache.log4j.{Level, Logger} import org.apache.spark.rdd.RDD import org.apache.spark.{S ...
随机推荐
- 自己动手实现一个简化版的requireJs
一直想实现一个简单版本的requireJs,最直接的办法去看requireJs源码搞明白原理,但是能力有限requireJs的源码比想象的要复杂许多,看了几遍也不是很明白,最后通过搜索找到了一些有价值 ...
- js+css实现简单下拉菜单
<head> <meta http-equiv="Content-Type" content="text/html; charset=gb2312&qu ...
- Asp.net 检测到有潜在危险的 Request.From值
因为Asp.net对客户端提交的数据进行了基本的安全验证,检测是否有最基础的 sql注入 或者 xss跨站脚本攻击代码. 如果你提交了:</div><script type=&quo ...
- Adobe Reader 的直接下载地址
页面:https://get.adobe.com/reader/direct/ 选择操作系统.选择语言.选择版本,然后点击立即下载. https://ardownload2.adobe.com/pub ...
- MySQL 分区知识点(一 )
前言: 查了下资料,关于 MySQL 分区的博文讲的详细的比较少,也不全,只好在官网去翻译英文文章看了.大体整理了一下记录起来: MySQL 分区类型: 1.RANGE 分区: // 这种类型的分区基 ...
- Javasript 内置函数
var str = 'AAAA';var aTest= new Array(); //['ff'[,'er']] \ new Array(10); \ new Array('ff','fee');va ...
- mysql 库,表,数据操作
一 系统数据库 information_schema: 虚拟库,不占用磁盘空间,存储的是数据库启动后的一些参数,如用户表信息.列信息.权限信息.字符信息等performance_schema: MyS ...
- Spring_总结_02_依赖注入
一.前言 本文承接上一节:Spring_总结_01_Spring概述 在上一节中,我们了解了Spring的最根本使命.四大原则.六大模块以及Spring的生态. 这一节我们开始了解Spring的第二大 ...
- 20165210 Java第一次实验报告
20165210 第一次实验报告 实验内容 建立目录运行简单的Java程序 建立自己学号的目录 在上个目录下建立src,bin等目录 Javac,Java的执行在学号目录下 IDEA的调试与设置断点 ...
- L117
Hoover has become a household word for a vacuum cleaner through the world.Economics are slowly killi ...