Spark架构角色及基本运行流程
1. 集群角色
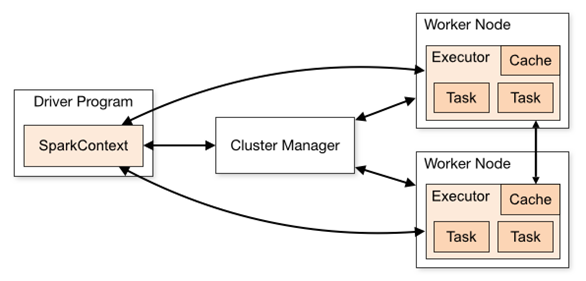
- Application:基于spark的用户程序,包含了一个Driver program 和集群中多个Executor
- Driver Program:运行application的main()函数并自动创建SparkContext。Driver program通过一个SparkContext对象来访问Spark,通常用SparkContext代表Driver。
- SparkContext: Spark的主要入口点,代表对计算集群的一个连接,是整个应用的上下文,负责与ClusterManager通信,进行资源申请、任务的分配和监控等。
- ClusterManager:在集群上获得资源的外部服务(spark standalone,mesos,yarm),Standalone模式:Spark原生的资源管理,由Master负责资源,YARN模式:Yarn中的ResourceManager
- Worker Node:集群中任何可运行Application代码的节点,负责控制计算节点,启动Executor或者Driver(Standalone模式:Worder,Yarn模式:NodeManager)
- Executor:为某个Application在worker node上执行任务的一个进程,该进程负责运行task并负责将数据存储在内存或者硬盘上,每个application都有自己独立的一组Executors。
- RDD:弹性分布式数据集,是spark 的基本运算单元,通过scala集合转化读取数据集生成或者由其他RDD进过算子操作得到
- Job:可以被拆分成Task并行计算的单元,一般为Spark Action触发的一次执行作业
- Stage:每个Job会被拆分成很多组Task,每组任务被称为Stage,也可称TaskSet,该属于经常在日志中看到
- Task:被送到executor上执行的工作单元
2. 基本运行流程
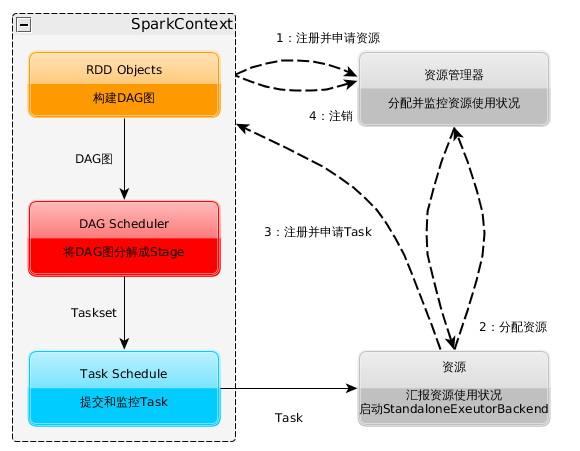
SparkContext的初始化过程中,Spark会分别创建DAGScheduler作业和TaskScheduler任务调度两级调度模块:
- DAG Scheduler:根据作业(Job)构建基于Stage的DAG,并将DAG分解成Stage以TaskSets(任务组)的形式提交给任务调度模块Task Scheduler来具体执行
- Task Scheduler:将任务(Task)分发给Executor执行
详细的流程为:
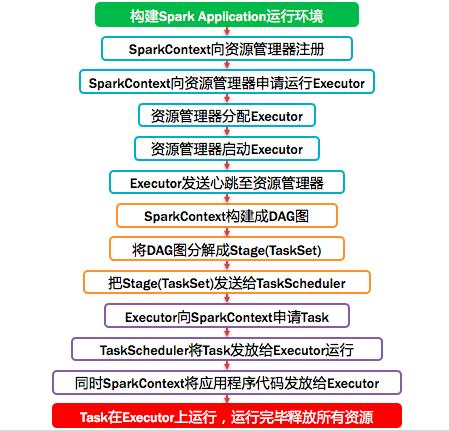
- Application启动之后, 会在本地启动一个Driver进程,用于控制整个流程(假设我们使用的Standalone模式);
- 初始化SparkContext,构建出DAGScheduler、TaskScheduler,以SparkContext为程序运行的总入口;
- 在初始化TaskSechduler的时候,它会向资源管理器(Standalone中是Master)注册Application,Master收到消息后使用资源调度算法在Spark集群的Worker上启动Executor并进行资源的分配,最后将Executor注册到TaskScheduler;
- 资源管理器分配Executor资源并启动StandaloneExecutorBackend,Executor运行情况将随着心跳发送到资源管理器上,到这里准备工作基本完成了;
- 根据我们编写的业务,如通过sc.textFile("file")加载数据源,将数据转化为RDD;
- DAGScheduer 先按照Action将程序划分为一至多个job(每一个job对应一个DAG),之后DAGScheduer根据是否进行shuffer将job划分为多个Stage,每个Stage过程都是Taskset , DAG将Taskset交给TaskScheduler(由Work中的Executor去执行)
- Executor向SparkContext申请Task;
- Task Scheduler将Task发放给Executor运行,同时SparkContext将应用程序代码发放给Executor;
- Task在Executor上运行,运行完毕释放所有资源。
Spark架构角色及基本运行流程的更多相关文章
- 【CDN+】 Spark 的入门学习与运行流程
前言 上文已经介绍了与Spark 息息相关的MapReduce计算模型,那么相对的Spark的优势在哪,有哪些适合大数据的生态呢? Spark对比MapReduce,Hive引擎,Storm流式计算引 ...
- 浅析MyBatis(一):由一个快速案例剖析MyBatis的整体架构与运行流程
MyBatis 是轻量级的 Java 持久层中间件,完全基于 JDBC 实现持久化的数据访问,支持以 xml 和注解的形式进行配置,能灵活.简单地进行 SQL 映射,也提供了比 JDBC 更丰富的结果 ...
- Spark学习之路 (七)Spark 运行流程
一.Spark中的基本概念 (1)Application:表示你的应用程序 (2)Driver:表示main()函数,创建SparkContext.由SparkContext负责与ClusterMan ...
- Spark Streaming运行流程及源码解析(一)
本系列主要描述Spark Streaming的运行流程,然后对每个流程的源码分别进行解析 之前总听同事说Spark源码有多么棒,咱也不知道,就是疯狂点头.今天也来撸一下Spark源码. 对Spark的 ...
- Spark学习之路 (七)Spark 运行流程[转]
Spark中的基本概念 (1)Application:表示你的应用程序 (2)Driver:表示main()函数,创建SparkContext.由SparkContext负责与ClusterManag ...
- 宜信开源|分布式任务调度平台SIA-TASK的架构设计与运行流程
一.分布式任务调度的背景 无论是互联网应用或者企业级应用,都充斥着大量的批处理任务.我们常常需要一些任务调度系统来帮助解决问题.随着微服务化架构的逐步演进,单体架构逐渐演变为分布式.微服务架构.在此背 ...
- Spark基本运行流程
不多说,直接上干货! Spark基本运行流程 Application program的组成 Job : 包含多个Task 组成的并行计算,跟Spark action对应. Stage : Job 的调 ...
- 2 Spark角色介绍及运行模式
第2章 Spark角色介绍及运行模式 2.1 集群角色 从物理部署层面上来看,Spark主要分为两种类型的节点,Master节点和Worker节点:Master节点主要运行集群管理器的中心化部分,所承 ...
- 大数据学习day18----第三阶段spark01--------0.前言(分布式运算框架的核心思想,MR与Spark的比较,spark可以怎么运行,spark提交到spark集群的方式)1. spark(standalone模式)的安装 2. Spark各个角色的功能 3.SparkShell的使用,spark编程入门(wordcount案例)
0.前言 0.1 分布式运算框架的核心思想(此处以MR运行在yarn上为例) 提交job时,resourcemanager(图中写成了master)会根据数据的量以及工作的复杂度,解析工作量,从而 ...
随机推荐
- OpenCascade建模:构建圆环API--BRepPrimAPI_MakeTortus()
构建圆环API--BRepPrimAPI_MakeTortus() 函数语法: BRepPrimAPI_MakeTortus( const Standard_Real R1, const Standa ...
- JSONArray排序和倒转
JSONArray排序 // JSONArray转list List<JSONObject> list = JSONArray.parseArray(ordersDataArray.toJ ...
- Ajax异步传值总结
Ajax异步传值 将数据从前台传向后台: 1:通过get方式,将参数在链接中,配合“?”进行传值. 实例: //前台传值方法 //触发该方法调用ajax function testAjax(yourD ...
- the nearest point/vertex point of linestring
引用https://github.com/Toblerity/Shapely/issues/190 snorfalorpagus commented on 18 Oct 2014 The point ...
- Angular 如何修改启动的端口
在默认的情况下 Angular 启动使用的是端口 4200. 如果修改这个启动的端口,比如说我们希望再 4100 端口上启动? 可以在启动的时候添加端口参数 --port. 例如使用下面的启动命令: ...
- python学习之路(14)
通过列表生成式,我们可以直接创建一个列表.但是,受到内存限制,列表容量肯定是有限的.而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素 ...
- [CSP-S模拟测试]:花(DP)
题目传送门(内部题111) 输入格式 一个整数$T$,表示测试数据组数. 每组测试数据占一行,两个整数,分别表示$L$和$S$. 输出格式 对每组数据,输出一个整数表示答案. 样例 样例输入1: 13 ...
- 套接字之msghdr结构
用户端在使用sendmsg/recvmsg发送或者接收数据时,会使用msghdr来构造消息,其对应的内核结构为user_msghdr:其中msg_iov向量指向了多个数据区,msg_iovlen标识了 ...
- Excel中使用Power Query获取网页json数据
Power Query下载地址 https://www.microsoft.com/zh-CN/download/details.aspx?id=39379 使用步骤 1.数据->其它源-> ...
- 191121HTML
一.HTML 1.web server import socket def handle_request(client): buf = client.recv(1024) client.send(by ...