Paper Reading_Database
最近(以及预感接下来的一年)会读很多很多的paper......不如开个帖子记录一下读paper心得
AI+DB
A. Pavlo et al., Self-Driving Database Engineering, in Unpublished Manuscript, 2019
写到这里啦:Self-Driving Database
CDBTune: An End-to-End Automatic Cloud Database Tuning System Using Deep Reinforcement Learning
2333
OtterTune: Automatic Database Management System Tuning Through Large-scale Machine Learning
笔记在这里:Link
后来我们借鉴OtterTune的思想,开发了AutoTiKV
Links:
https://www.cnblogs.com/pdev/p/10948322.html
https://www.cnblogs.com/pdev/p/11318880.html
Query-based Workload Forecasting forSelf-Driving Database Management Systems
在Self-driving Database这篇综述中,曾经提到过self-driving的DBMS需要能预测未来的workload情况。这篇文章就是来解决这个问题的,更具体一点说是predict the expected arrival rate of queries(也就是QPS) in the future based on historical data,并且特指是SQL Query。
其实有很多类似的工作也在试图做这个玩意儿,比如这篇是用LSTM预测应用程序的resource utilization(比如cpu usage, memory usage, balabala),但这些metric有个缺点就是比如硬件配置改变时(以及像本文的scenario下,当DBMS的底层设计改变了时),之前测的就不准啦。所以不如从上层的东西入手,预测业务的workload情况。比如能预测到双11,或者每天晚上是个访问高峰,那么就可以配合automatic knob tuning的一些工具来自动调优啦。其中本文重点关注了三种有代表性的workload pattern(见Fig1),个人感觉选的倒都挺经典的:
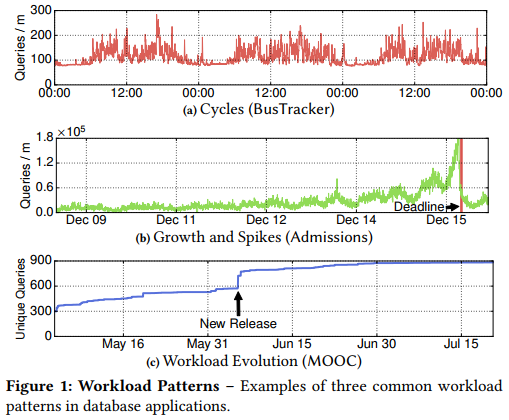
本文要解决这么几个难点:
- 如何设计一个好的ML model
- 如何降低原始数据的complexity(因为SQL语句的花样很多,对每种query分别预测是不可能的)
- 要做的这个framework必须能全自动化
根据上面的思路,本文开发了QueryBot5000(QB5000),它的pipeline如下图所示:
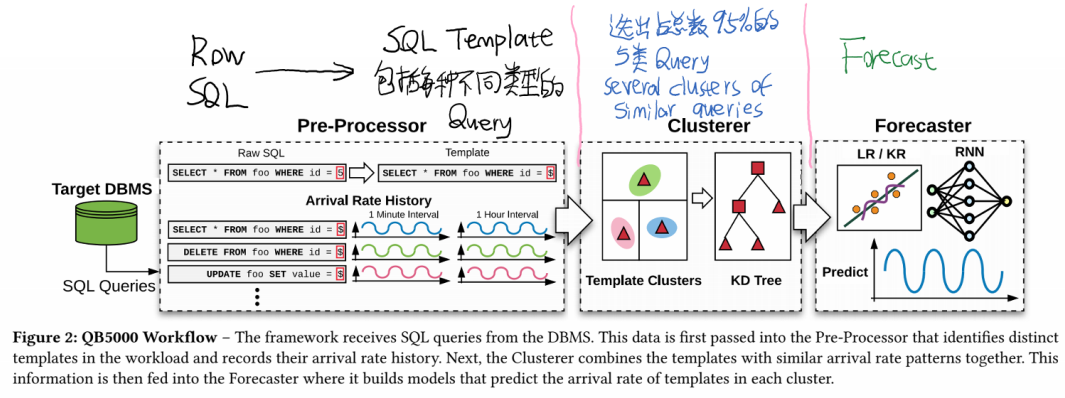
这三个部分的具体细节如下:
- Pre-processor:首先DBMS会把所有接收到的Query转发给QB5000。虽然SQL语句花样很多,但从语义来看种类还是很有限的嘛(Such similar queries execute withthe same frequency and often have the same resource utilizationin the system.)。因此就可以用pre-processor总结出语义基本一致,只是参数不同的Query,把相似的query归类总结成一个generic query template。
- Cluster:上面总结了之后,发现啊template(语义不同的Query的种类数量)还是有很多,需要进一步减少template的数量。具体细节先不看了.......大致意思就是把arrival rate相近的Query template合并起来(比如说两种template都在同一张表上操作,那么它们的arrival rate就可能很接近,可以合并,也具有可以用ml来学习的潜力)。最后选出占了总数的95%的Query。
- Forecast:好的经过之前两顿猛如虎的操作,现在the framework has converted raw SQL queries into templates and grouped them into clusters,并且有了它们的QPS的历史数据(the number of queries executed per minute for each cluster)。现在是时候用ML model来predict(estimate the number of queries that the application will execute in the future)啦。这也是我们要关注的重点。因为NoSQL语义比较少,不需要前两步啊哈哈哈哈。
Forecast这一节我们专门拉出来看。本文考察了以下几个model:
- Linear Regression (LR):比较简单嘛......它的优势是简单,可以避免过拟合,需要的训练数据也比较少。
- Kernel Regression (KR):相对于Linear Regression,Kernel方法可以实现对一些非线性函数的回归。看似很猛如虎,但它也比较复杂,需要的训练数据多,容易过拟合。在作者的实验中,LR对短时间(比如1小时)内的prediction比较好,而KR对长时间(比如一天)的prediction比较好。Kernel方法也分很多种......本文中使用的是Nadaraya–Watson kernel regression,这也是一个无参数的方法。????
- RNN:其实这里就用的LSTM。LSTM可以“记忆”数据在过去时间段的一些特征,并应用到预测未来上。它的缺点也是模型复杂,需要的sample多。(所以ML中并不是模型越复杂就越好......是需要根据实际情况做很多的tradeoff的)
- ENSEMBLE:另外有一种方法叫做ensemble learning,可以结合两种不同模型的优点。在本文中作者就把LR和RNN给ensemble到了一起,拼成了一个新model(equally averaging the prediction results of the LR and RNN models),这里我们记为ENSEMBLE
作者在实验中发现:
- 1). ENSEMBLE方法的average prediction accuracy比较好,但它无法预测出带有周期性尖峰的workload。比如对于大学申请的网站,每年的申请deadline之前都是一个高峰,但平时没什么人访问(见Fig1b)。
- 2). KR的average prediction accuracy并不如ENSEMBLE,但是只有它能预测出带有尖峰的workload。
综合上述结果,作者提出了一个HYBRID模型,自动根据不同情况决定采用上面哪种model。针对尖峰这个feature我们可以这样设计:如果KR预测出的结果(its predicted workload volume)比ENSEMBLE的结果大K%(K是一个threshold,这里定为150%),就使用KR的结果,否则使用ENSEMBLE的结果。
接下来还有些细节需要考虑。比如Prediction Horizons(要预测多长时间内的workload,相当于Regression图上x坐标的范围)和Prediction Intervals(模型的直接输出结果是预测多长时间内的Query数量,相当于x坐标上每个点的单位)。这里作者把interval设为一分钟。也就是对于horizon时间段内的每一分钟,预测这一分钟内的arrival rate of queries。(还有些细节可参考6.2节)
最后是实验环节啦。对于cluster,结论是选择top5的类就可以了,后面训练的时候把这top5的cluster混合到一起作为training data,只训练一个model。我们重点关注Forecast的效果。在下面的实验中,使用过去3周的数据Train,然后实验了不同的Prediction Horizon。
对于模型的选择,理论上说应该是不能选择对超参数过于敏感的模型,这是因为fne-tuning a model’s hyperparameters is by itself a hard optimization task。而在实验中也证实了这一点(Fig7,但这里好像没有说实验的Prediction interval.....好在后面还会专门讨论这个):
- 在Horizon比较短的时候(一天以内),LR比RNN的表现还要好。因为短时间内的the relationship between the arrival rate observed in the recent past and the arrival rate in the near future is more linear than for longer horizons。 而复杂的模型反倒有可能过拟合。
- 在Horizon比较长的时候(一天及以上),the relationship between the past and the future also grows in complexity。RNN的表现会比较好
- 综合了上述两个model的ENSEMBLE的overall性能最好。
- 只有HYBRID可以预测到带有尖峰的workload pattern
另外作者还选择了如下几个模型做对比:
- Autoregressive Moving Average (ARMA):这是一种时间序列模型(其实时间序列也是一个可以考虑的方向)。但是它的效果并不是很稳定,在38%的case下都不好。这是因为the model is sensitive to its hyperparameters. The optimal hyperparameter settings for ARMA are highly dependent on the statistical properties of the data, such as stationarity and the autocorrelation structure.
- Feed-forward Neural Network (FNN):就是普通的多层神经网络...被RNN完爆
- Predictive State Recurrent Neural Network (PSRNN):LSTM的一个变种。然而在这里还是被LSTM完爆...
- Kernel Regression (KR):单纯KR的效果其实一般般...因为it is prone to error when it has not seen inputs in training that are close to the input to make the prediction with。但是后面预测尖峰的时候还真是会用到它
对于有尖峰的workload pattern,这里使用1 hour的interval,用full workload history来训练,然后试图预测出一周后的workload是否会出现尖峰。在这种情况下,只有KR顺利预测出了尖峰(Fig9)。这是因为its prediction is based on the distance between the test points and training data, where the influence of each training data point decreases exponentially with its distance from the test point。
对于Prediction Horizon的选择,在BusTracker的数据上测试发现还是Prediction Horizon比较短的时候效果好...比如1 hour的时候就比1 week好(Fig8)
对于Prediction Interval的选择,interval越短的效果会越好(shorter intervals provide more training samples and better information for learning),但interval太小了也会导致noise多,模型更复杂,训练也更久,因此这也是个tradeoff。最终实验发现总的来说1 hour的interval比较好。(一个future work就是自动设置interval)
Link:
https://zhuanlan.zhihu.com/p/37182849
https://github.com/pentium3/QueryBot5000
Distributed DB
PolarFS: An Ultra-low Latency and Failure ResilientDistributed File System for Shared Storage Cloud Database
https://zhuanlan.zhihu.com/p/87030280
....
Paper Reading_Database的更多相关文章
- Paper Reading
Paper Reading_SysML Paper Reading_Computer Architecture Paper Reading_Database Paper Reading_Distrib ...
- 激光打印机的Color/paper, Xerography介绍
Color Basic 看见色彩三要素: 光源,物体,视觉 加色色彩模型:R,G,B 多用于显示器 减色色彩模型:C,M,Y,K 多用于打印复印 Paper 东亚地区常用A系列标准用纸,在多功能一体机 ...
- Facebook Paper使用的第三方库
Facebook Paper使用的第三方库 第三方库名 简介 链接 ACE code editor https://github.com/ajaxorg/ace Appirater 用户评分组件 ht ...
- paper 118:计算机视觉、模式识别、机器学习常用牛人主页链接
牛人主页(主页有很多论文代码) Serge Belongie at UC San Diego Antonio Torralba at MIT Alexei Ffros at CMU Ce Liu at ...
- #Deep Learning回顾#之2006年的Science Paper
大家都清楚神经网络在上个世纪七八十年代是着实火过一回的,尤其是后向传播BP算法出来之后,但90年代后被SVM之类抢了风头,再后来大家更熟悉的是SVM.AdaBoost.随机森林.GBDT.LR.FTR ...
- Tips for writing a paper
Tips for writing a paper 1. Tips for Paper Writing 2.• Before you write a paper • When you are writi ...
- How to (seriously) read a scientific paper
How to (seriously) read a scientific paper Adam Ruben’s tongue-in-cheek column about the common diff ...
- How to read a scientific paper
How to read a scientific paper Nothing makes you feel stupid quite like reading a scientific journal ...
- 如何写好一篇高质量的paper
http://blog.csdn.net/tiandijun/article/details/41775223 这篇文章来源于中科院Zhouchen Lin 教授的report,有幸读到,和大家分享一 ...
随机推荐
- js能否上传文件夹
文件夹上传:从前端到后端 文件上传是 Web 开发肯定会碰到的问题,而文件夹上传则更加难缠.网上关于文件夹上传的资料多集中在前端,缺少对于后端的关注,然后讲某个后端框架文件上传的文章又不会涉及文件夹. ...
- smooth L1损失函数
当预测值与目标值相差很大时,L2 Loss的梯度为(x-t),容易产生梯度爆炸,L1 Loss的梯度为常数,通过使用Smooth L1 Loss,在预测值与目标值相差较大时,由L2 Loss转为L1 ...
- [51nod1383&1048]整数分解为2的幂:DP
算法一 分析 \(f[x]=f[x-1]+f[x/2] \times [x \equiv 0 \mod 2],O(n)\) 代码 n=int(input()) f=[0]*(n+5) f[0]=1 m ...
- android字符串工具类
package com.ctbri.weather.utils.calendar; /** * Created by IntelliJ IDEA. * User: zhouxin@easier.cn ...
- Kylin CDH安装
Kylin安装 从官网下载 apache-kylin-2.0.0-bin-cdh57.tar.gz 放到每台需要安装kylin 服务的机器 [hadoop@hadoop3 cdh5.12.0]$ su ...
- 快速排序和二分查找(Javascript)
var data = [8, 3, 4, 1, 18, 22, 11, 3, 5, 6, 2, 1, 77] quickSort(data, 0, data.length - 1) console.l ...
- Oracle诊断:drop table失败[转]
转: From <http://blog.csdn.net/cyxlxp8411/article/details/7775113> 今天在drop一张表的时候报ORA-00054错误 SQ ...
- Getting CFNetwork SSLHandshake failed (-9806) error
平常个人打测试包一切OK,今天突然不能联网了 How to handle "CFNetwork SSLHandshake failed" in iOS 参考1 Getting CF ...
- Ubuntu18.04修改为阿里云
对源安装时,要先知道系统的版本,以免安装错的版本 使用命令:lsb_release -c 备份原先的配置文件 cd /etc/apt sudo cp sources.list sources.list ...
- kurento搭建以及运行kurento-hello-world
搭建环境的系统是ubuntu 1.kurento服务器搭建 运行如下脚本即可完成安装 #!/bin/bash echo "deb http://ubuntu.kurento.org trus ...