Dubbo HA 高可用
一、zookeeper 宕机
现象:zookeeper 注册中心宕机,还可以消费 dubbo 暴露的服务 健壮性
监控中心宕掉不影响使用,只是丢失部分采样数据
数据库宕掉后,注册中心仍能通过缓存提供服务列表查询,但不能注册新服务
注册中心对等集群,任意一台宕掉后,将自动切换到另一台
注册中心全部宕掉后,服务提供者和服务消费者仍能通过本地缓存通讯
服务提供者无状态,任意一台宕掉后,不影响使用
服务提供者全部宕掉后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复 高可用:通过设计,减少系统不能提供服务的时间
二、dubbo 直连
// 引用服务时直接指定地址,不通过注册中心
@Reference(url = "127.0.0.1:20882")
三、集群下 dubbo 的负载均衡配置
在集群负载均衡时,Dubbo 提供了多种均衡策略,缺省为 random 随机调用。

// 暴露服务时设置权重(建议不要设置,权重可在控制台更改)
@Service(weight = 100) // 引用服务时指定负载方式(也可在提供方指定)
@Reference(loadbalance = "roundrobin")
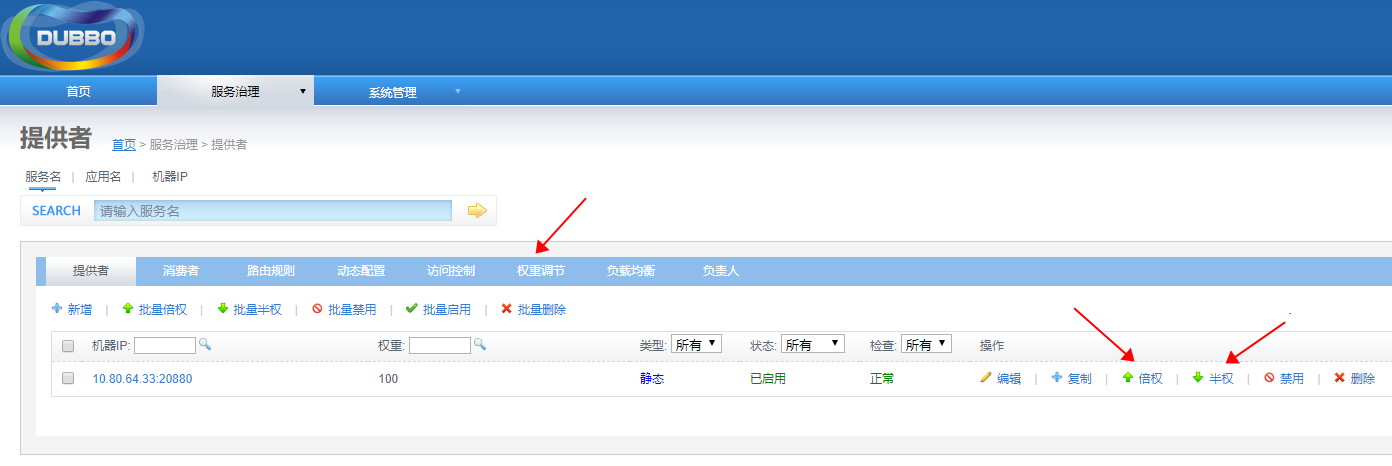
3.1、Random LoadBalance
随机,按权重设置随机概率。基于权重的随机负载均衡机制
在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重。
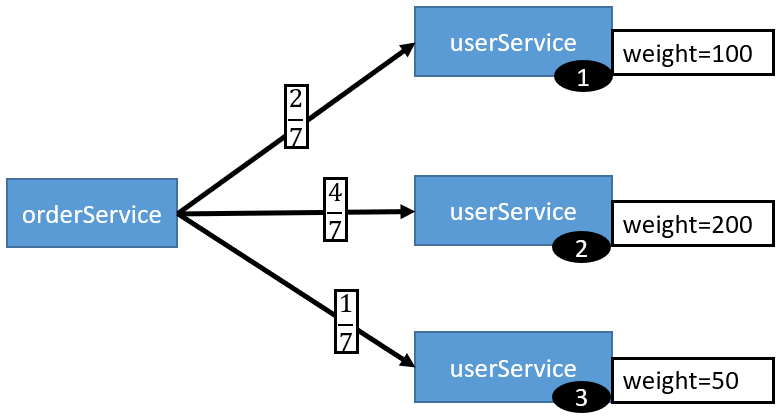
3.2、RoundRobin LoadBalance
轮循,按公约后的权重设置轮循比率。基于权重的轮询负载均衡机制
存在慢的提供者累积请求的问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上。
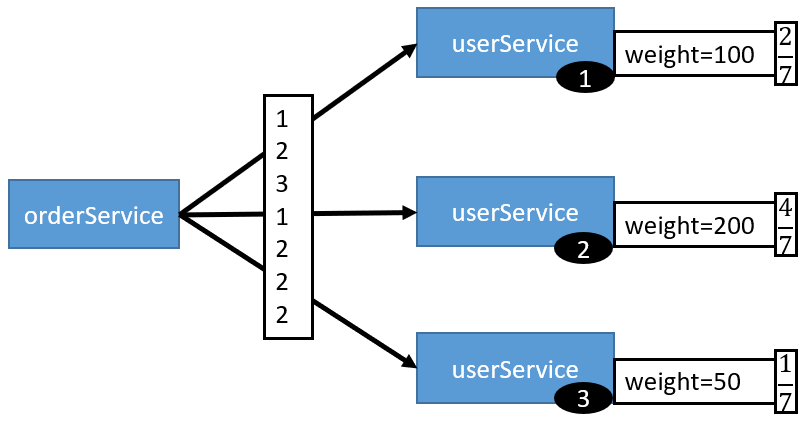
3.3、LeastActive LoadBalance
最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差。最少活跃数-负载均衡机制
使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大。
3.4、ConsistentHash LoadBalance
一致性 Hash,相同参数的请求总是发到同一提供者。一致性hash-负载均衡机制 当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。算法参见:http://en.wikipedia.org/wiki/Consistent_hashing
缺省只对第一个参数 Hash,如果要修改,请配置 <dubbo:parameter key="hash.arguments" value="0,1"/>
缺省用 160 份虚拟节点,如果要修改,请配置 <dubbo:parameter key="hash.nodes" value="320"/>

四、服务降级
当服务器压力剧增的情况下,根据实际业务情况及流量,对一些服务和页面有策略的不处理或换种简单的方式处理,从而释放服务器资源以保证核心交易正常运作或高效运作。
可以通过服务降级功能临时屏蔽某个出错的非关键服务,并定义降级后的返回策略。向注册中心写入动态配置覆盖规则:
RegistryFactory registryFactory = ExtensionLoader.getExtensionLoader(RegistryFactory.class).getAdaptiveExtension();
Registry registry = registryFactory.getRegistry(URL.valueOf("zookeeper://10.20.153.10:2181"));
registry.register(URL.valueOf("override://0.0.0.0/com.foo.BarService?category=configurators&dynamic=false&application=foo&mock=force:return+null"));
服务降级需要更改消费方的策略,然后再可以减少相应的服务,腾出资源。其中:
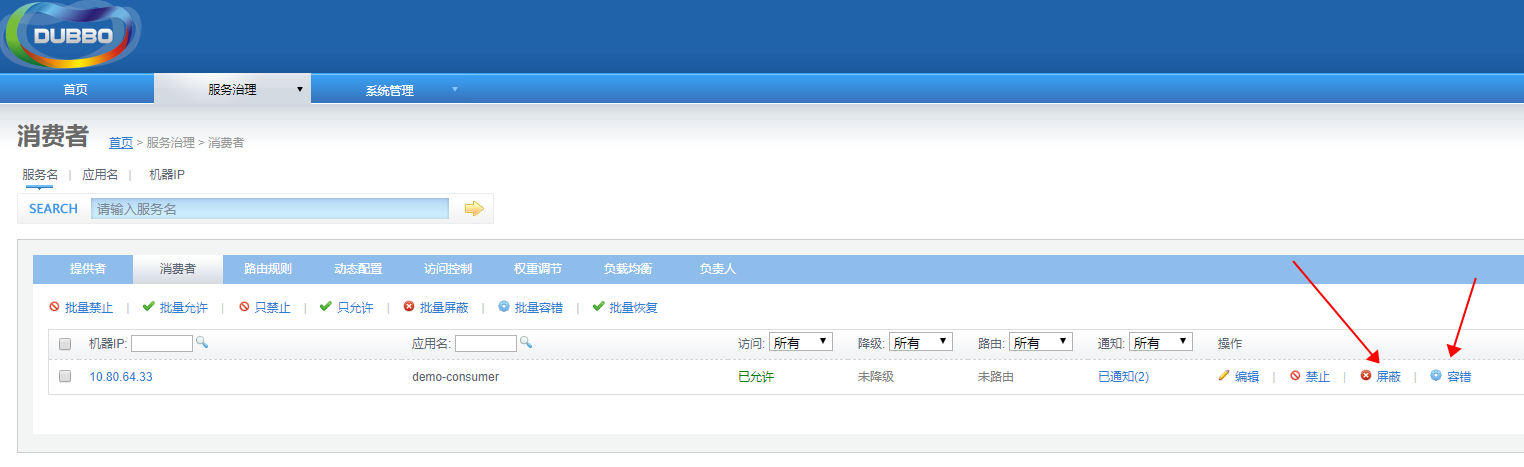
mock=force:return+null 表示消费方对该服务的方法调用都直接返回 null 值,不发起远程调用。用来屏蔽不重要服务不可用时对调用方的影响,对应控制台的屏蔽。
mock=fail:return+null 表示消费方对该服务的方法调用在失败后(如超时),再返回 null 值,不抛异常。用来容忍不重要服务不稳定时对调用方的影响,对应控制台的容错。
五、服务熔断
在集群调用失败时,Dubbo 提供了多种容错方案,缺省为 failover 重试。
Failover Cluster
失败自动切换,当出现失败,重试其它服务器。通常用于读操作,但重试会带来更长延迟。可通过 retries="2" 来设置重试次数(不含第一次)。 重试次数配置如下:
<dubbo:service retries="2" />
或
<dubbo:reference retries="2" />
或
<dubbo:reference>
<dubbo:method name="findFoo" retries="2" />
</dubbo:reference> Failfast Cluster
快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。 Failsafe Cluster
失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。 Failback Cluster
失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。 Forking Cluster
并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks="2" 来设置最大并行数。 Broadcast Cluster
广播调用所有提供者,逐个调用,任意一台报错则报错 [2]。通常用于通知所有提供者更新缓存或日志等本地资源信息。 集群模式配置
按照以下示例在服务提供方和消费方配置集群模式
<dubbo:service cluster="failsafe" />
或
<dubbo:reference cluster="failsafe" />
整合 hystrix
Hystrix 旨在通过控制那些访问远程系统、服务和第三方库的节点,从而对延迟和故障提供更强大的容错能力。Hystrix具备拥有回退机制和断路器功能的线程和信号隔离,请求缓存和请求打包,以及监控和配置等功能。
1.在消费方和提供方加入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
<version>2.1.1.RELEASE</version>
</dependency>
2.在消费方和提供方开启 Hystrix
@EnableHystrix
3.在提供方要容错的方法上标注,并指定出错时调用的方法
// 出错时调用 xxx 方法
@HystrixCommand(fallbackMethod = "xxx")
@Override
public String sayHello(String name) {
// 抛出异常
int x = 10 / 0;
System.out.println("Hello " + name + ", request from consumer: ");
return "Hello " + name + ", response from provider: ";
} public String xxx(String name) {
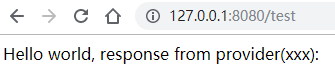
return "Hello " + name + ", response from provider(xxx): ";
}
4.在消费方要容错的方法上标注
@HystrixCommand
@ResponseBody
@RequestMapping("test")
public String test() {
return demoService.sayHello("world");
}
5.测试
http://dubbo.apache.org/zh-cn/docs/user/demos/loadbalance.html
http://dubbo.apache.org/zh-cn/docs/user/demos/fault-tolerent-strategy.html
Dubbo HA 高可用的更多相关文章
- HA高可用的搭建
HA 即 (high available)高可用,又被叫做双机热备,用于关键性业务. 简单理解就是,有两台机器A和B,正常是A提供服务,B待命闲置,当A宕机或服务宕掉,会切换至B机器继续提供服务.常用 ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- CentOS7+Hadoop2.7.2(HA高可用+Federation联邦)+Hive1.2.1+Spark2.1.0 完全分布式集群安装
1 2 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 2.9.1 2.9.2 2.9.2.1 2.9.2.2 2.9.3 2.9.3.1 2.9.3.2 2.9.3.3 2. ...
- linux -- 基于zookeeper搭建yarn的HA高可用集群
linux -- 基于zookeeper搭建yarn的HA高可用集群 实现方式:配置yarn-site.xml配置文件 <configuration> <property> & ...
- hadoop 集群HA高可用搭建以及问题解决方案
hadoop 集群HA高可用搭建 目录大纲 1. hadoop HA原理 2. hadoop HA特点 3. Zookeeper 配置 4. 安装Hadoop集群 5. Hadoop HA配置 搭建环 ...
- centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课
centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课 heartbeat是Linu ...
- 大数据Hadoop的HA高可用架构集群部署
1 概述 在Hadoop 2.0.0之前,一个Hadoop集群只有一个NameNode,那么NameNode就会存在单点故障的问题,幸运的是Hadoop 2.0.0之后解决了这个问题,即支持N ...
- Kubeadm 1.9 HA 高可用集群本地离线镜像部署【已验证】
k8s介绍 k8s 发展速度很快,目前很多大的公司容器集群都基于该项目,如京东,腾讯,滴滴,瓜子二手车,易宝支付,北森等等. kubernetes1.9版本发布2017年12月15日,每三个月一个迭代 ...
随机推荐
- springboot(二十二)-sharding-jdbc-读写分离
前面我们使用sharding-jdbc配置了分库分表.sharding-jdbc还有个用法,就是实现读写分离. 什么时候需要或者可以使用读写分离? 当我们的项目所使用的数据库查询的访问量,访问频率,及 ...
- mybatis字符#与字符$的区别
问题:使用in查询查询出一批数据,in查询的参数是字符串拼接的.调试过程中,把mybatis输出的sql复制到navicat中,在控制台将sql的参数也复制出来,替换到sql的字符 '?' 的位置,执 ...
- ubuntu终端安装最新ss
有时候因为加密方式比较新,比如aes-256-gcm,导致旧版本的不能用 一句命令安装ss最新版本 aes-256-gcm加密方式可以用,没毛病
- Notepad++ 文件丢失了,找回历史文件方法
一开始我还以为文件丢失找不到了,心凉了半截,后来找到了它的备份路径 C:\Users\Administrator\AppData\Roaming\Notepad++\backup
- openxlsx模块
import openpyxl #创建工作簿 wb = openpyxl.Workbook()#获取当前活跃的工作表 ws = wb.active#删除工作表 remove_sheet(wb.get_ ...
- 浅析Java泛型
什么是泛型? 泛型是JDK 1.5的一项新特性,它的本质是参数化类型(Parameterized Type)的应用,也就是说所操作的数据类型被指定为一个参数,在用到的时候在指定具体的类型.这种参数类型 ...
- CUDA, CUDNN 版本查询
CUDA 查询: cat /usr/local/cuda/version.txt 或者 nvcc -V (也可以看到版本信息) CUDNN 查询 cat /usr/local/cuda/include ...
- qt5---资源文件
创建资源文件: 视频教程:https://www.bilibili.com/video/av66748323/ 右击工程目录--->-->--> 添加资源: 右击资源文件--> ...
- C风格函数
很多C风格的函数用起来非常舒适,例如: if(access(sPath, 0) == 0){ ://检测文件是否存在 } 用来测试文件存在与否,以及读写权限. 而他有宽字节版与ascii码版 宽版 _ ...
- PHP大文件上传断点续传源码
文件夹数据库处理逻辑 publicclass DbFolder { JSONObject root; public DbFolder() { this.root = new JSONObject(); ...