Spark译文(一)
Spark Overview(Spark概述)
Security(安全性)
Downloading
Running the Examples and Shell(运行示例和Shell)
./bin/run-example SparkPi 10./bin/spark-shell --master local[2]./bin/pyspark --master local[2]./bin/spark-submit examples/src/main/python/pi.py 10
Quick Start(快速开始)
Interactive Analysis with the Spark Shell(使用Spark Shell进行交互式分析)
Basics(基本)
./bin/pyspark
或者如果在当前环境中使用pip安装了PySpark:pyspark>>> textFile = spark.read.text("README.md")>>> textFile.count() # Number of rows in this DataFrame
126
>>> textFile.first() # First row in this DataFrame
Row(value=u'# Apache Spark')
>>> linesWithSpark = textFile.filter(textFile.value.contains("Spark"))我们可以将转换和行动联系在一起:
>>> textFile.filter(textFile.value.contains("Spark")).count() # How many lines contain "Spark"?
15More on Dataset Operations(有关数据集操作的更多信息)
>>> from pyspark.sql.functions import *
>>> textFile.select(size(split(textFile.value, "\s+")).name("numWords")).agg(max(col("numWords"))).collect()
[Row(max(numWords)=15)]>>> wordCounts = textFile.select(explode(split(textFile.value, "\s+")).alias("word")).groupBy("word").count()>>> wordCounts.collect()
[Row(word=u'online', count=1), Row(word=u'graphs', count=1), ...]Caching(高速缓存)
>>> linesWithSpark.cache()
>>> linesWithSpark.count()
15
>>> linesWithSpark.count()
15Self-Contained Applications(自包含的应用程序)
install_requires=[
'pyspark=={site.SPARK_VERSION}'
]
作为示例,我们将创建一个简单的Spark应用程序SimpleApp.py:
"""SimpleApp.py"""
from pyspark.sql import SparkSession
logFile = "YOUR_SPARK_HOME/README.md" # Should be some file on your system
spark = SparkSession.builder.appName("SimpleApp").getOrCreate()
logData = spark.read.text(logFile).cache()
numAs = logData.filter(logData.value.contains('a')).count()
numBs = logData.filter(logData.value.contains('b')).count()
print("Lines with a: %i, lines with b: %i" % (numAs, numBs))
spark.stop()
# Use spark-submit to run your application
$ YOUR_SPARK_HOME/bin/spark-submit \
--master local[4] \
SimpleApp.py
...
Lines with a: 46, Lines with b: 23
如果您的环境中安装了PySpark pip(例如,pip install pyspark),您可以使用常规Python解释器运行您的应用程序,或者根据您的喜好使用提供的“spark-submit”。# Use the Python interpreter to run your application
$ python SimpleApp.py
...
Lines with a: 46, Lines with b: 23RDD Programming Guide(RDD编程指南)
Overview(概观)
Linking with Spark(与Spark链接)
install_requires=[
'pyspark=={site.SPARK_VERSION}'
]
from pyspark import SparkContext, SparkConf$ PYSPARK_PYTHON=python3.4 bin/pyspark
$ PYSPARK_PYTHON=/opt/pypy-2.5/bin/pypy bin/spark-submit examples/src/main/python/pi.pyInitializing Spark(初始化Spark)
conf = SparkConf().setAppName(appName).setMaster(master)
sc = SparkContext(conf=conf)Using the Shell(使用Shell)
$ ./bin/pyspark --master local[4]
或者,要将code.py添加到搜索路径(以便以后能够导入代码),请使用:$ ./bin/pyspark --master local[4] --py-files code.py$ PYSPARK_DRIVER_PYTHON=ipython ./bin/pyspark
要使用Jupyter notebook(以前称为IPython notebook)$ PYSPARK_DRIVER_PYTHON=jupyter PYSPARK_DRIVER_PYTHON_OPTS=notebook ./bin/pysparkResilient Distributed Datasets (弹性分布式数据集)(RDDs)
Parallelized Collections(并行化集合)
data = [1, 2, 3, 4, 5]
distData = sc.parallelize(data)External Datasets(外部数据集)
>>> distFile = sc.textFile("data.txt")| Writable Type(可写类型) | Python Type |
|---|---|
| Text | unicode str |
| IntWritable | int |
| FloatWritable | float |
| DoubleWritable | float |
| BooleanWritable | bool |
| BytesWritable | bytearray |
| NullWritable | None |
| MapWritable | dict |
$ ./bin/pyspark --jars /path/to/elasticsearch-hadoop.jar
>>> conf = {"es.resource" : "index/type"} # assume Elasticsearch is running on localhost defaults
>>> rdd = sc.newAPIHadoopRDD("org.elasticsearch.hadoop.mr.EsInputFormat",
"org.apache.hadoop.io.NullWritable",
"org.elasticsearch.hadoop.mr.LinkedMapWritable",
conf=conf)
>>> rdd.first() # the result is a MapWritable that is converted to a Python dict
(u'Elasticsearch ID',
{u'field1': True,
u'field2': u'Some Text',
u'field3': 12345})RDD Operations(RDD操作)
Basics(基本)
为了说明RDD基础知识,请考虑以下简单程序:
lines = sc.textFile("data.txt")
lineLengths = lines.map(lambda s: len(s))
totalLength = lineLengths.reduce(lambda a, b: a + b)lineLengths.persist()
在reduce之前,这将导致lineLengths在第一次计算之后保存在内存中。Passing Functions to Spark(将函数传递给Spark)
"""MyScript.py"""
if __name__ == "__main__":
def myFunc(s):
words = s.split(" ")
return len(words)
sc = SparkContext(...)
sc.textFile("file.txt").map(myFunc)class MyClass(object):
def func(self, s):
return s
def doStuff(self, rdd):
return rdd.map(self.func)class MyClass(object):
def __init__(self):
self.field = "Hello"
def doStuff(self, rdd):
return rdd.map(lambda s: self.field + s)def doStuff(self, rdd):
field = self.field
return rdd.map(lambda s: field + s)Understanding closures(理解闭包)
Example
counter = 0
rdd = sc.parallelize(data)
# Wrong: Don't do this!!
def increment_counter(x):
global counter
counter += x
rdd.foreach(increment_counter)
print("Counter value: ", counter)Local vs. cluster modes(本地与群集模式)
Printing elements of an RDD(打印RDD的元素)
Working with Key-Value Pairs(使用键值对)
lines = sc.textFile("data.txt")
pairs = lines.map(lambda s: (s, 1))
counts = pairs.reduceByKey(lambda a, b: a + b)
例如,我们也可以使用counts.sortByKey()来按字母顺序对这些对进行排序,最后使用counts.collect()将它们作为对象列表返回到驱动程序。Transformations(转换)
Actions(动作)
Shuffle operations(随机操作)
Background(背景)
Performance Impact(绩效影响)
RDD Persistence(RDD持久性)
Which Storage Level to Choose?(选择哪种存储级别?)
Removing Data(删除数据)
Shared Variables(共享变量)
Broadcast Variables(广播变量)
>>> broadcastVar = sc.broadcast([1, 2, 3])
<pyspark.broadcast.Broadcast object at 0x102789f10>
>>> broadcastVar.value
[1, 2, 3]Accumulators(累加器)
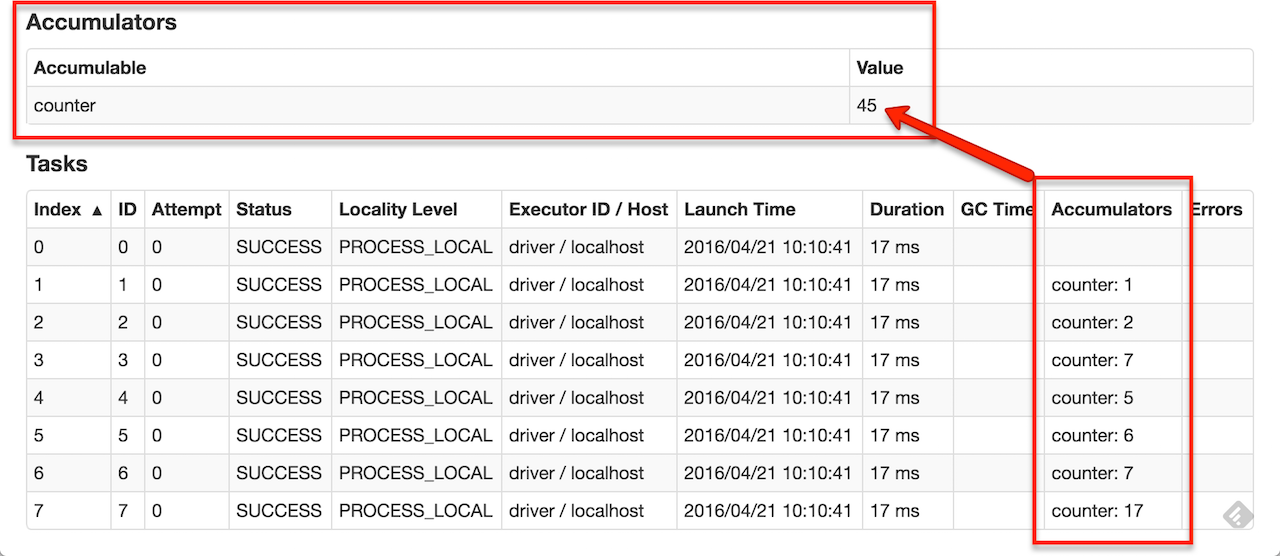
>>> accum = sc.accumulator(0)
>>> accum
Accumulator<id=0, value=0>
>>> sc.parallelize([1, 2, 3, 4]).foreach(lambda x: accum.add(x))
...
10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 s
>>> accum.value
10class VectorAccumulatorParam(AccumulatorParam):
def zero(self, initialValue):
return Vector.zeros(initialValue.size)
def addInPlace(self, v1, v2):
v1 += v2
return v1
# Then, create an Accumulator of this type:
vecAccum = sc.accumulator(Vector(...), VectorAccumulatorParam())accum = sc.accumulator(0)
def g(x):
accum.add(x)
return f(x)
data.map(g)
# Here, accum is still 0 because no actions have caused the `map` to be computed.Deploying to a Cluster(部署到群集)
Launching Spark jobs from Java / Scala(从Java / Scala启动Spark作业)
org.apache.spark.launcher包提供了使用简单Java API将Spark作业作为子进程启动的类。
Unit Testing(单元测试)
Where to Go from Here(从这往哪儿走)
You can see some example Spark programs on the Spark website. In addition, Spark includes several samples in the examples directory (Scala,Java, Python, R). You can run Java and Scala examples by passing the class name to Spark’s bin/run-example script; for instance:
./bin/run-example SparkPi
对于Python示例,请使用spark-submit代替:
./bin/spark-submit examples/src/main/python/pi.py
Spark SQL, DataFrames and Datasets Guide
SQL
Datasets and DataFrames
Getting Started(入门)
Starting Point: SparkSession(起点:SparkSession)
from pyspark.sql import SparkSession spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
Creating DataFrames(创建DataFrame)
# spark is an existing SparkSession
df = spark.read.json("examples/src/main/resources/people.json")
# Displays the content of the DataFrame to stdout
df.show()
# +----+-------+
# | age| name|
# +----+-------+
# |null|Michael|
# | 30| Andy|
# | 19| Justin|
# +----+-------+
Untyped Dataset Operations (aka DataFrame Operations)无类型数据集操作(又名DataFrame操作)
# spark, df are from the previous example
# Print the schema in a tree format
df.printSchema()
# root
# |-- age: long (nullable = true)
# |-- name: string (nullable = true) # Select only the "name" column
df.select("name").show()
# +-------+
# | name|
# +-------+
# |Michael|
# | Andy|
# | Justin|
# +-------+ # Select everybody, but increment the age by 1
df.select(df['name'], df['age'] + 1).show()
# +-------+---------+
# | name|(age + 1)|
# +-------+---------+
# |Michael| null|
# | Andy| 31|
# | Justin| 20|
# +-------+---------+ # Select people older than 21
df.filter(df['age'] > 21).show()
# +---+----+
# |age|name|
# +---+----+
# | 30|Andy|
# +---+----+ # Count people by age
df.groupBy("age").count().show()
# +----+-----+
# | age|count|
# +----+-----+
# | 19| 1|
# |null| 1|
# | 30| 1|
# +----+-----+
Running SQL Queries Programmatically(以编程方式运行SQL查询)
SparkSession上的sql函数使应用程序能够以编程方式运行SQL查询并将结果作为DataFrame返回。
# Register the DataFrame as a SQL temporary view
df.createOrReplaceTempView("people") sqlDF = spark.sql("SELECT * FROM people")
sqlDF.show()
# +----+-------+
# | age| name|
# +----+-------+
# |null|Michael|
# | 30| Andy|
# | 19| Justin|
# +----+-------+
Global Temporary View(全球临时观点)
# Register the DataFrame as a global temporary view
df.createGlobalTempView("people") # Global temporary view is tied to a system preserved database `global_temp`
spark.sql("SELECT * FROM global_temp.people").show()
# +----+-------+
# | age| name|
# +----+-------+
# |null|Michael|
# | 30| Andy|
# | 19| Justin|
# +----+-------+ # Global temporary view is cross-session
spark.newSession().sql("SELECT * FROM global_temp.people").show()
# +----+-------+
# | age| name|
# +----+-------+
# |null|Michael|
# | 30| Andy|
# | 19| Justin|
# +----+-------+
Creating Datasets(创建数据集)
case class Person(name: String, age: Long) // Encoders are created for case classes
val caseClassDS = Seq(Person("Andy", 32)).toDS()
caseClassDS.show()
// +----+---+
// |name|age|
// +----+---+
// |Andy| 32|
// +----+---+ // Encoders for most common types are automatically provided by importing spark.implicits._
val primitiveDS = Seq(1, 2, 3).toDS()
primitiveDS.map(_ + 1).collect() // Returns: Array(2, 3, 4) // DataFrames can be converted to a Dataset by providing a class. Mapping will be done by name
val path = "examples/src/main/resources/people.json"
val peopleDS = spark.read.json(path).as[Person]
peopleDS.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
Interoperating with RDDs(与RDD互操作)
Inferring the Schema Using Reflection(使用反射推断模式)
from pyspark.sql import Row sc = spark.sparkContext # Load a text file and convert each line to a Row.
lines = sc.textFile("examples/src/main/resources/people.txt")
parts = lines.map(lambda l: l.split(","))
people = parts.map(lambda p: Row(name=p[0], age=int(p[1]))) # Infer the schema, and register the DataFrame as a table.
schemaPeople = spark.createDataFrame(people)
schemaPeople.createOrReplaceTempView("people") # SQL can be run over DataFrames that have been registered as a table.
teenagers = spark.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19") # The results of SQL queries are Dataframe objects.
# rdd returns the content as an :class:`pyspark.RDD` of :class:`Row`.
teenNames = teenagers.rdd.map(lambda p: "Name: " + p.name).collect()
for name in teenNames:
print(name)
# Name: Justin
Programmatically Specifying the Schema(以编程方式指定架构)
例如:
# Import data types
from pyspark.sql.types import * sc = spark.sparkContext # Load a text file and convert each line to a Row.
lines = sc.textFile("examples/src/main/resources/people.txt")
parts = lines.map(lambda l: l.split(","))
# Each line is converted to a tuple.
people = parts.map(lambda p: (p[0], p[1].strip())) # The schema is encoded in a string.
schemaString = "name age" fields = [StructField(field_name, StringType(), True) for field_name in schemaString.split()]
schema = StructType(fields) # Apply the schema to the RDD.
schemaPeople = spark.createDataFrame(people, schema) # Creates a temporary view using the DataFrame
schemaPeople.createOrReplaceTempView("people") # SQL can be run over DataFrames that have been registered as a table.
results = spark.sql("SELECT name FROM people") results.show()
# +-------+
# | name|
# +-------+
# |Michael|
# | Andy|
# | Justin|
# +-------+
Aggregations(聚合)
Untyped User-Defined Aggregate Functions(无用户定义的聚合函数)
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.expressions.MutableAggregationBuffer
import org.apache.spark.sql.expressions.UserDefinedAggregateFunction
import org.apache.spark.sql.types._
object MyAverage extends UserDefinedAggregateFunction {
// Data types of input arguments of this aggregate function
def inputSchema: StructType = StructType(StructField("inputColumn", LongType) :: Nil)
// Data types of values in the aggregation buffer
def bufferSchema: StructType = {
StructType(StructField("sum", LongType) :: StructField("count", LongType) :: Nil)
}
// The data type of the returned value
def dataType: DataType = DoubleType
// Whether this function always returns the same output on the identical input
def deterministic: Boolean = true
// Initializes the given aggregation buffer. The buffer itself is a `Row` that in addition to
// standard methods like retrieving a value at an index (e.g., get(), getBoolean()), provides
// the opportunity to update its values. Note that arrays and maps inside the buffer are still
// immutable.
def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L
buffer(1) = 0L
}
// Updates the given aggregation buffer `buffer` with new input data from `input`
def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if (!input.isNullAt(0)) {
buffer(0) = buffer.getLong(0) + input.getLong(0)
buffer(1) = buffer.getLong(1) + 1
}
}
// Merges two aggregation buffers and stores the updated buffer values back to `buffer1`
def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
// Calculates the final result
def evaluate(buffer: Row): Double = buffer.getLong(0).toDouble / buffer.getLong(1)
}
// Register the function to access it
spark.udf.register("myAverage", MyAverage)
val df = spark.read.json("examples/src/main/resources/employees.json")
df.createOrReplaceTempView("employees")
df.show()
// +-------+------+
// | name|salary|
// +-------+------+
// |Michael| 3000|
// | Andy| 4500|
// | Justin| 3500|
// | Berta| 4000|
// +-------+------+
val result = spark.sql("SELECT myAverage(salary) as average_salary FROM employees")
result.show()
// +--------------+
// |average_salary|
// +--------------+
// | 3750.0|
// +--------------+
Type-Safe User-Defined Aggregate Functions(类型安全的用户定义聚合函数)
import org.apache.spark.sql.{Encoder, Encoders, SparkSession}
import org.apache.spark.sql.expressions.Aggregator
case class Employee(name: String, salary: Long)
case class Average(var sum: Long, var count: Long)
object MyAverage extends Aggregator[Employee, Average, Double] {
// A zero value for this aggregation. Should satisfy the property that any b + zero = b
def zero: Average = Average(0L, 0L)
// Combine two values to produce a new value. For performance, the function may modify `buffer`
// and return it instead of constructing a new object
def reduce(buffer: Average, employee: Employee): Average = {
buffer.sum += employee.salary
buffer.count += 1
buffer
}
// Merge two intermediate values
def merge(b1: Average, b2: Average): Average = {
b1.sum += b2.sum
b1.count += b2.count
b1
}
// Transform the output of the reduction
def finish(reduction: Average): Double = reduction.sum.toDouble / reduction.count
// Specifies the Encoder for the intermediate value type
def bufferEncoder: Encoder[Average] = Encoders.product
// Specifies the Encoder for the final output value type
def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
val ds = spark.read.json("examples/src/main/resources/employees.json").as[Employee]
ds.show()
// +-------+------+
// | name|salary|
// +-------+------+
// |Michael| 3000|
// | Andy| 4500|
// | Justin| 3500|
// | Berta| 4000|
// +-------+------+
// Convert the function to a `TypedColumn` and give it a name
val averageSalary = MyAverage.toColumn.name("average_salary")
val result = ds.select(averageSalary)
result.show()
// +--------------+
// |average_salary|
// +--------------+
// | 3750.0|
// +--------------+
Data Sources(数据源)
Generic Load/Save Functions(通用加载/保存功能)
在最简单的形式中,默认数据源(parquet除非另外由spark.sql.sources.default配置)将用于所有操作。
df = spark.read.load("examples/src/main/resources/users.parquet")
df.select("name", "favorite_color").write.save("namesAndFavColors.parquet")
Manually Specifying Options(手动指定选项)
要加载JSON文件,您可以使用:
df = spark.read.load("examples/src/main/resources/people.json", format="json")
df.select("name", "age").write.save("namesAndAges.parquet", format="parquet")
要加载CSV文件,您可以使用:
df = spark.read.load("examples/src/main/resources/people.csv",
format="csv", sep=":", inferSchema="true", header="true")
df = spark.read.orc("examples/src/main/resources/users.orc")
(df.write.format("orc")
.option("orc.bloom.filter.columns", "favorite_color")
.option("orc.dictionary.key.threshold", "1.0")
.save("users_with_options.orc"))
Run SQL on files directly(直接在文件上运行SQL)
可以直接使用SQL查询该文件,而不是使用读取API将文件加载到DataFrame并进行查询
df = spark.sql("SELECT * FROM parquet.`examples/src/main/resources/users.parquet`")
Save Modes(保存模式)
| Scala/Java | Any Language | Meaning |
|---|---|---|
SaveMode.ErrorIfExists(default) |
"error" or "errorifexists"(default) |
将DataFrame保存到数据源时,如果数据已存在,则会引发异常。 |
SaveMode.Append |
"append" |
将DataFrame保存到数据源时,如果数据/表已存在,则DataFrame的内容应附加到现有数据。 |
SaveMode.Overwrite |
"overwrite" |
覆盖模式意味着在将DataFrame保存到数据源时,如果数据/表已经存在,则预期现有数据将被DataFrame的内容覆盖。 |
SaveMode.Ignore |
"ignore" |
Ignore mode means that when saving a DataFrame to a data source, if data already exists, the save operation is expected not to save the contents of the DataFrame and not to change the existing data. This is similar to a CREATE TABLE IF NOT EXISTS in SQL. |
Saving to Persistent Tables(保存到持久表)
Bucketing, Sorting and Partitioning
df.write.bucketBy(42, "name").sortBy("age").saveAsTable("people_bucketed")
虽然分区可以在使用数据集API时与save和saveAsTable一起使用。
df.write.partitionBy("favorite_color").format("parquet").save("namesPartByColor.parquet")
df = spark.read.parquet("examples/src/main/resources/users.parquet")
(df
.write
.partitionBy("favorite_color")
.bucketBy(42, "name")
.saveAsTable("people_partitioned_bucketed"))
Parquet Files(Parquet文件)
- Loading Data Programmatically
- Partition Discovery
- Schema Merging
- Hive metastore Parquet table conversion
- Configuration
Loading Data Programmatically(以编程方式加载数据)
使用上面示例中的数据:
peopleDF = spark.read.json("examples/src/main/resources/people.json")
# DataFrames can be saved as Parquet files, maintaining the schema information.
peopleDF.write.parquet("people.parquet")
# Read in the Parquet file created above.
# Parquet files are self-describing so the schema is preserved.
# The result of loading a parquet file is also a DataFrame.
parquetFile = spark.read.parquet("people.parquet")
# Parquet files can also be used to create a temporary view and then used in SQL statements.
parquetFile.createOrReplaceTempView("parquetFile")
teenagers = spark.sql("SELECT name FROM parquetFile WHERE age >= 13 AND age <= 19")
teenagers.show()
# +------+
# | name|
# +------+
# |Justin|
# +------+
Partition Discovery(分区发现)
path
└── to
└── table
├── gender=male
│ ├── ...
│ │
│ ├── country=US
│ │ └── data.parquet
│ ├── country=CN
│ │ └── data.parquet
│ └── ...
└── gender=female
├── ...
│
├── country=US
│ └── data.parquet
├── country=CN
│ └── data.parquet
└── ...root
|-- name: string (nullable = true)
|-- age: long (nullable = true)
|-- gender: string (nullable = true)
|-- country: string (nullable = true)Schema Merging(架构合并)
from pyspark.sql import Row # spark is from the previous example.
# Create a simple DataFrame, stored into a partition directory
sc = spark.sparkContext squaresDF = spark.createDataFrame(sc.parallelize(range(1, 6))
.map(lambda i: Row(single=i, double=i ** 2)))
squaresDF.write.parquet("data/test_table/key=1") # Create another DataFrame in a new partition directory,
# adding a new column and dropping an existing column
cubesDF = spark.createDataFrame(sc.parallelize(range(6, 11))
.map(lambda i: Row(single=i, triple=i ** 3)))
cubesDF.write.parquet("data/test_table/key=2") # Read the partitioned table
mergedDF = spark.read.option("mergeSchema", "true").parquet("data/test_table")
mergedDF.printSchema() # The final schema consists of all 3 columns in the Parquet files together
# with the partitioning column appeared in the partition directory paths.
# root
# |-- double: long (nullable = true)
# |-- single: long (nullable = true)
# |-- triple: long (nullable = true)
# |-- key: integer (nullable = true)
Hive metastore Parquet table conversion(Hive Metastore Parquet表转换)
Hive/Parquet Schema Reconciliation
Metadata Refreshing(元数据刷新)
# spark is an existing SparkSession
spark.catalog.refreshTable("my_table")Configuration(构造)
可以使用SparkSession上的setConf方法或使用SQL运行SET key = value命令来完成Parquet的配置。
| Property Name | Default | Meaning |
|---|---|---|
spark.sql.parquet.binaryAsString |
false |
·其他一些Parquet生成系统,特别是Impala,Hive和旧版本的Spark SQL,在写出Parquet模式时不区分二进制数据和字符串。
·此标志告诉Spark SQL将二进制数据解释为字符串,以提供与这些系统的兼容性。
|
spark.sql.parquet.int96AsTimestamp |
true |
·一些Parquet生产系统,特别是Impala和Hive,将时间戳存储到INT96中。
·此标志告诉Spark SQL将INT96数据解释为时间戳,以提供与这些系统的兼容性。
|
spark.sql.parquet.compression.codec |
snappy |
·设置编写Parquet文件时使用的压缩编解码器。
·如果在特定于表的选项/属性中指定了“compression”或“parquet.compression”,则优先级为“compression”,“parquet.compression”,“spark.sql.parquet.compression.codec”。
·可接受的值包括:none,uncompressed,snappy,gzip,lzo,brotli,lz4,zstd。
·请注意,`zstd`需要在Hadoop 2.9.0之前安装`ZStandardCodec`,`brotli`需要安装`BrotliCodec`。
|
spark.sql.parquet.filterPushdown |
true | 设置为true时启用Parquet过滤器下推优化。 |
spark.sql.hive.convertMetastoreParquet |
true | 设置为false时,Spark SQL将使用Hive SerDe作为镶木桌而不是内置支持。 |
spark.sql.parquet.mergeSchema |
false |
如果为true,则Parquet数据源合并从所有数据文件收集的模式,否则,如果没有可用的摘要文件,则从摘要文件或随机数据文件中选取模式。 |
spark.sql.parquet.writeLegacyFormat |
false |
·如果为true,则数据将以Spark 1.4及更早版本的方式写入。
·例如,十进制值将以Apache Parquet的固定长度字节数组格式写入,其他系统(如Apache Hive和Apache Impala)也使用该格式。
·如果为false,将使用Parquet中的较新格式。
·例如,小数将以基于int的格式写入。
·如果Parquet输出旨在用于不支持此较新格式的系统,请设置为true。
|
JSON Files(JSON文件)
# spark is from the previous example.
sc = spark.sparkContext # A JSON dataset is pointed to by path.
# The path can be either a single text file or a directory storing text files
path = "examples/src/main/resources/people.json"
peopleDF = spark.read.json(path) # The inferred schema can be visualized using the printSchema() method
peopleDF.printSchema()
# root
# |-- age: long (nullable = true)
# |-- name: string (nullable = true) # Creates a temporary view using the DataFrame
peopleDF.createOrReplaceTempView("people") # SQL statements can be run by using the sql methods provided by spark
teenagerNamesDF = spark.sql("SELECT name FROM people WHERE age BETWEEN 13 AND 19")
teenagerNamesDF.show()
# +------+
# | name|
# +------+
# |Justin|
# +------+ # Alternatively, a DataFrame can be created for a JSON dataset represented by
# an RDD[String] storing one JSON object per string
jsonStrings = ['{"name":"Yin","address":{"city":"Columbus","state":"Ohio"}}']
otherPeopleRDD = sc.parallelize(jsonStrings)
otherPeople = spark.read.json(otherPeopleRDD)
otherPeople.show()
# +---------------+----+
# | address|name|
# +---------------+----+
# |[Columbus,Ohio]| Yin|
# +---------------+----+
Hive Tables(Hive表)
from os.path import expanduser, join, abspath from pyspark.sql import SparkSession
from pyspark.sql import Row # warehouse_location points to the default location for managed databases and tables
warehouse_location = abspath('spark-warehouse') spark = SparkSession \
.builder \
.appName("Python Spark SQL Hive integration example") \
.config("spark.sql.warehouse.dir", warehouse_location) \
.enableHiveSupport() \
.getOrCreate() # spark is an existing SparkSession
spark.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING) USING hive")
spark.sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src") # Queries are expressed in HiveQL
spark.sql("SELECT * FROM src").show()
# +---+-------+
# |key| value|
# +---+-------+
# |238|val_238|
# | 86| val_86|
# |311|val_311|
# ... # Aggregation queries are also supported.
spark.sql("SELECT COUNT(*) FROM src").show()
# +--------+
# |count(1)|
# +--------+
# | 500 |
# +--------+ # The results of SQL queries are themselves DataFrames and support all normal functions.
sqlDF = spark.sql("SELECT key, value FROM src WHERE key < 10 ORDER BY key") # The items in DataFrames are of type Row, which allows you to access each column by ordinal.
stringsDS = sqlDF.rdd.map(lambda row: "Key: %d, Value: %s" % (row.key, row.value))
for record in stringsDS.collect():
print(record)
# Key: 0, Value: val_0
# Key: 0, Value: val_0
# Key: 0, Value: val_0
# ... # You can also use DataFrames to create temporary views within a SparkSession.
Record = Row("key", "value")
recordsDF = spark.createDataFrame([Record(i, "val_" + str(i)) for i in range(1, 101)])
recordsDF.createOrReplaceTempView("records") # Queries can then join DataFrame data with data stored in Hive.
spark.sql("SELECT * FROM records r JOIN src s ON r.key = s.key").show()
# +---+------+---+------+
# |key| value|key| value|
# +---+------+---+------+
# | 2| val_2| 2| val_2|
# | 4| val_4| 4| val_4|
# | 5| val_5| 5| val_5|
# ...
Specifying storage format for Hive tables(指定Hive表的存储格式)
| Property Name | Meaning |
|---|---|
fileFormat |
·fileFormat是一种存储格式规范包,包括“serde”,“input format”和“output format”。
·目前我们支持6种fileFormats:'sequencefile','rcfile','orc','parquet','textfile'和'avro'。
|
inputFormat, outputFormat |
·这两个选项将相应的`InputFormat`和`OutputFormat`类的名称指定为字符串文字,例如
·`org.apache.hadoop.hive.ql.io.orc.OrcInputFormat`。
·这两个选项必须出现在pair中,如果已经指定了`fileFormat`选项,则无法指定它们。
|
serde |
·此选项指定serde类的名称。
·当指定`fileFormat`选项时,如果给定的`fileFormat`已经包含serde的信息,则不要指定此选项。
·目前“sequencefile”,“textfile”和“rcfile”不包含serde信息,您可以将此选项与这3个fileFormats一起使用。
|
fieldDelim, escapeDelim, collectionDelim, mapkeyDelim, lineDelim |
·这些选项只能与“textfile”fileFormat一起使用。
·它们定义了如何将分隔文件读入行。
|
使用OPTIONS定义的所有其他属性将被视为Hive serde属性。
Interacting with Different Versions of Hive Metastore(与不同版本的Hive Metastore交互)
| Property Name | Default | Meaning |
|---|---|---|
spark.sql.hive.metastore.version |
1.2.1 |
Version of the Hive metastore. Available options are 0.12.0 through 2.3.3. |
spark.sql.hive.metastore.jars |
builtin |
Location of the jars that should be used to instantiate the HiveMetastoreClient. This property can be one of three options:
Use Hive 1.2.1, which is bundled with the Spark assembly when
Use Hive jars of specified version downloaded from Maven repositories. This configuration is not generally recommended for production deployments. |
spark.sql.hive.metastore.sharedPrefixes |
com.mysql.jdbc, |
A comma-separated list of class prefixes that should be loaded using the classloader that is shared between Spark SQL and a specific version of Hive. An example of classes that should be shared is JDBC drivers that are needed to talk to the metastore. Other classes that need to be shared are those that interact with classes that are already shared. For example, custom appenders that are used by log4j. |
spark.sql.hive.metastore.barrierPrefixes |
(empty) |
A comma separated list of class prefixes that should explicitly be reloaded for each version of Hive that Spark SQL is communicating with. For example, Hive UDFs that are declared in a prefix that typically would be shared (i.e. |
JDBC To Other Databases(JDBC到其他数据库)
bin/spark-shell --driver-class-path postgresql-9.4.1207.jar --jars postgresql-9.4.1207.jar| Property Name | Meaning |
|---|---|
url |
·要连接的JDBC URL。
·可以在URL中指定特定于源的连接属性。
·例如,jdbc:postgresql:// localhost / test?user = fred&password = secret
|
dbtable |
·应该读取或写入的JDBC表。
·请注意,在读取路径中使用它时,可以使用在SQL查询的FROM子句中有效的任何内容。
·例如,您也可以在括号中使用子查询,而不是完整的表。
·不允许同时指定`dbtable`和`query`选项。
|
query |
·将用于将数据读入Spark的查询。指定的查询将括起来并用作FROM子句中的子查询。Spark还会为子查询子句分配别名。
·例如,spark将向JDBC Source发出以下形式的查询
·使用此选项时,以下是一些限制。
·不允许同时指定`dbtable`和`query`选项。
·不允许同时指定`query`和`partitionColumn`选项。
·当需要指定`partitionColumn`选项时,可以使用`dbtable`选项指定子查询,并且可以使用作为`dbtable`的一部分提供的子查询别名来限定分区列。
范例: |
driver |
用于连接到此URL的JDBC驱动程序的类名 |
partitionColumn, lowerBound, upperBound |
·如果指定了任何选项,则必须全部指定这些选项。此外,必须指定numPartitions。它们描述了在从多个工作者并行读取时如何对表进行分区。partitionColumn必须是相关表中的数字,日期或时间戳列。
·请注意,lowerBound和upperBound仅用于决定分区步幅,而不是用于过滤表中的行。因此,表中的所有行都将被分区并返回。此选项仅适用于阅读。
|
numPartitions |
The maximum number of partitions that can be used for parallelism in table reading and writing. This also determines the maximum number of concurrent JDBC connections. If the number of partitions to write exceeds this limit, we decrease it to this limit by calling coalesce(numPartitions) before writing. |
queryTimeout |
The number of seconds the driver will wait for a Statement object to execute to the given number of seconds. Zero means there is no limit. In the write path, this option depends on how JDBC drivers implement the API setQueryTimeout, e.g., the h2 JDBC driver checks the timeout of each query instead of an entire JDBC batch. It defaults to 0. |
fetchsize |
The JDBC fetch size, which determines how many rows to fetch per round trip. This can help performance on JDBC drivers which default to low fetch size (eg. Oracle with 10 rows). This option applies only to reading. |
batchsize |
The JDBC batch size, which determines how many rows to insert per round trip. This can help performance on JDBC drivers. This option applies only to writing. It defaults to 1000. |
isolationLevel |
The transaction isolation level, which applies to current connection. It can be one of NONE, READ_COMMITTED, READ_UNCOMMITTED, REPEATABLE_READ, or SERIALIZABLE, corresponding to standard transaction isolation levels defined by JDBC's Connection object, with default of READ_UNCOMMITTED. This option applies only to writing. Please refer the documentation in java.sql.Connection. |
sessionInitStatement |
After each database session is opened to the remote DB and before starting to read data, this option executes a custom SQL statement (or a PL/SQL block). Use this to implement session initialization code. Example: option("sessionInitStatement", """BEGIN execute immediate 'alter session set "_serial_direct_read"=true'; END;""") |
truncate |
This is a JDBC writer related option. When SaveMode.Overwrite is enabled, this option causes Spark to truncate an existing table instead of dropping and recreating it. This can be more efficient, and prevents the table metadata (e.g., indices) from being removed. However, it will not work in some cases, such as when the new data has a different schema. It defaults to false. This option applies only to writing. |
cascadeTruncate |
This is a JDBC writer related option. If enabled and supported by the JDBC database (PostgreSQL and Oracle at the moment), this options allows execution of a TRUNCATE TABLE t CASCADE (in the case of PostgreSQL a TRUNCATE TABLE ONLY t CASCADE is executed to prevent inadvertently truncating descendant tables). This will affect other tables, and thus should be used with care. This option applies only to writing. It defaults to the default cascading truncate behaviour of the JDBC database in question, specified in the isCascadeTruncate in each JDBCDialect. |
createTableOptions |
This is a JDBC writer related option. If specified, this option allows setting of database-specific table and partition options when creating a table (e.g., CREATE TABLE t (name string) ENGINE=InnoDB.). This option applies only to writing. |
createTableColumnTypes |
The database column data types to use instead of the defaults, when creating the table. Data type information should be specified in the same format as CREATE TABLE columns syntax (e.g: "name CHAR(64), comments VARCHAR(1024)"). The specified types should be valid spark sql data types. This option applies only to writing. |
customSchema |
·用于从JDBC连接器读取数据的自定义架构。例如,“id DECIMAL(38,0),名称为STRING”。您还可以指定部分字段,其他字段使用默认类型映射。例如,“id DECIMAL(38,0)”。列名应与JDBC表的相应列名相同。用户可以指定Spark SQL的相应数据类型,而不是使用默认值。
·此选项仅适用于阅读。
|
pushDownPredicate |
·用于启用或禁用谓词下推到JDBC数据源的选项。默认值为true,在这种情况下,Spark会尽可能地将过滤器下推到JDBC数据源。否则,如果设置为false,则不会将过滤器下推到JDBC数据源,因此所有过滤器都将由Spark处理。当Spark通过比JDBC数据源更快地执行谓词过滤时,谓词下推通常会被关闭。
|
# Note: JDBC loading and saving can be achieved via either the load/save or jdbc methods
# Loading data from a JDBC source
jdbcDF = spark.read \
.format("jdbc") \
.option("url", "jdbc:postgresql:dbserver") \
.option("dbtable", "schema.tablename") \
.option("user", "username") \
.option("password", "password") \
.load() jdbcDF2 = spark.read \
.jdbc("jdbc:postgresql:dbserver", "schema.tablename",
properties={"user": "username", "password": "password"}) # Specifying dataframe column data types on read
jdbcDF3 = spark.read \
.format("jdbc") \
.option("url", "jdbc:postgresql:dbserver") \
.option("dbtable", "schema.tablename") \
.option("user", "username") \
.option("password", "password") \
.option("customSchema", "id DECIMAL(38, 0), name STRING") \
.load() # Saving data to a JDBC source
jdbcDF.write \
.format("jdbc") \
.option("url", "jdbc:postgresql:dbserver") \
.option("dbtable", "schema.tablename") \
.option("user", "username") \
.option("password", "password") \
.save() jdbcDF2.write \
.jdbc("jdbc:postgresql:dbserver", "schema.tablename",
properties={"user": "username", "password": "password"}) # Specifying create table column data types on write
jdbcDF.write \
.option("createTableColumnTypes", "name CHAR(64), comments VARCHAR(1024)") \
.jdbc("jdbc:postgresql:dbserver", "schema.tablename",
properties={"user": "username", "password": "password"})
Apache Avro Data Source Guide(Apache Avro数据源指南)
- Deploying
- Load and Save Functions
- to_avro() and from_avro()
- Data Source Option
- Configuration
- Compatibility with Databricks spark-avro
- Supported types for Avro -> Spark SQL conversion
- Supported types for Spark SQL -> Avro conversion
自Spark 2.4发布以来,Spark SQL为读取和编写Apache Avro数据提供了内置支持。
Deploying(配置)
./bin/spark-submit --packages org.apache.spark:spark-avro_2.12:2.4.2 ...
对于在spark-shell上进行试验,您还可以使用--packages直接添加org.apache.spark:spark-avro_2.12及其依赖项
./bin/spark-shell --packages org.apache.spark:spark-avro_2.12:2.4.2 ...
有关提交具有外部依赖性的应用程序的详细信息,请参阅“应用程序提交指南。
Load and Save Functions(加载和保存功能)
df = spark.read.format("avro").load("examples/src/main/resources/users.avro")
df.select("name", "favorite_color").write.format("avro").save("namesAndFavColors.avro")to_avro() and from_avro()
import org.apache.spark.sql.avro._
// `from_avro` requires Avro schema in JSON string format.
val jsonFormatSchema = new String(Files.readAllBytes(Paths.get("./examples/src/main/resources/user.avsc")))
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
// 1. Decode the Avro data into a struct;
// 2. Filter by column `favorite_color`;
// 3. Encode the column `name` in Avro format.
val output = df
.select(from_avro('value, jsonFormatSchema) as 'user)
.where("user.favorite_color == \"red\"")
.select(to_avro($"user.name") as 'value)
val query = output
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic2")
.start()Data Source Option(数据源选项)
可以使用DataFrameReader或DataFrameWriter上的.option方法设置Avro的数据源选项。
| Property Name | Default | Meaning | Scope |
|---|---|---|---|
avroSchema |
None | Optional Avro schema provided by an user in JSON format. The date type and naming of record fields should match the input Avro data or Catalyst data, otherwise the read/write action will fail. | read and write |
recordName |
topLevelRecord | Top level record name in write result, which is required in Avro spec. | write |
recordNamespace |
"" | Record namespace in write result. | write |
ignoreExtension |
true | The option controls ignoring of files without .avro extensions in read.If the option is enabled, all files (with and without .avro extension) are loaded. |
read |
compression |
snappy | The compression option allows to specify a compression codec used in write.Currently supported codecs are uncompressed, snappy, deflate, bzip2 and xz.If the option is not set, the configuration spark.sql.avro.compression.codec config is taken into account. |
write |
Configuration(构造)
可以使用SparkSession上的setConf方法或使用SQL运行SET key = value命令来完成Avro的配置。
| Property Name | Default | Meaning |
|---|---|---|
| spark.sql.legacy.replaceDatabricksSparkAvro.enabled | true | If it is set to true, the data source provider com.databricks.spark.avro is mapped to the built-in but external Avro data source module for backward compatibility. |
| spark.sql.avro.compression.codec | snappy | Compression codec used in writing of AVRO files. Supported codecs: uncompressed, deflate, snappy, bzip2 and xz. Default codec is snappy. |
| spark.sql.avro.deflate.level | -1 | Compression level for the deflate codec used in writing of AVRO files. Valid value must be in the range of from 1 to 9 inclusive or -1. The default value is -1 which corresponds to 6 level in the current implementation. |
Compatibility with Databricks spark-avro(与Databricks spark-avro的兼容性)
Supported types for Avro -> Spark SQL conversion
目前,Spark支持在Avro记录下读取所有原始类型和复杂类型。
| Avro type | Spark SQL type |
|---|---|
| boolean | BooleanType |
| int | IntegerType |
| long | LongType |
| float | FloatType |
| double | DoubleType |
| string | StringType |
| enum | StringType |
| fixed | BinaryType |
| bytes | BinaryType |
| record | StructType |
| array | ArrayType |
| map | MapType |
| union | See below |
| Avro logical type | Avro type | Spark SQL type |
|---|---|---|
| date | int | DateType |
| timestamp-millis | long | TimestampType |
| timestamp-micros | long | TimestampType |
| decimal | fixed | DecimalType |
| decimal | bytes | DecimalType |
目前,忽略了Avro文件中存在的文档,别名和其他属性。
Supported types for Spark SQL -> Avro conversion(支持的Spark SQL类型 - > Avro转换)
| Spark SQL type | Avro type | Avro logical type |
|---|---|---|
| ByteType | int | |
| ShortType | int | |
| BinaryType | bytes | |
| DateType | int | date |
| TimestampType | long | timestamp-micros |
| DecimalType | fixed | decimal |
| Spark SQL type | Avro type | Avro logical type |
|---|---|---|
| BinaryType | fixed | |
| StringType | enum | |
| TimestampType | long | timestamp-millis |
| DecimalType | bytes | decimal |
Performance Tuning(性能调优)
对于某些工作负载,可以通过在内存中缓存数据或打开一些实验选项来提高性能。
Caching Data In Memory(在内存中缓存数据)
| Property Name | Default | Meaning |
|---|---|---|
spark.sql.inMemoryColumnarStorage.compressed |
true | 设置为true时,Spark SQL将根据数据统计信息自动为每列选择压缩编解码器 |
spark.sql.inMemoryColumnarStorage.batchSize |
10000 |
·控制柱状缓存的批次大小。
·较大的批处理大小可以提高内存利用率和压缩率,但在缓存数据时存在OOM风险。
|
Other Configuration Options(其他配置选项)
| Property Name | Default | Meaning |
|---|---|---|
spark.sql.files.maxPartitionBytes |
134217728 (128 MB) | 读取文件时打包到单个分区的最大字节数。 |
spark.sql.files.openCostInBytes |
4194304 (4 MB) |
·可以在同一时间扫描通过字节数测量的打开文件的估计成本。
·将多个文件放入分区时使用。
·最好过度估计,然后使用较小文件的分区将比具有较大文件的分区(首先安排的分区)更快
|
spark.sql.broadcastTimeout |
300 |
广播连接中广播等待时间的超时(以秒为单位) |
spark.sql.autoBroadcastJoinThreshold |
10485760 (10 MB) |
·配置在执行连接时将广播到所有工作节点的表的最大大小(以字节为单位)。
·通过将此值设置为-1,可以禁用广播。
·请注意,目前仅支持运行命令ANALYZE TABLE COMPUTE STATISTICS noscan的Hive Metastore表的统计信息。
|
spark.sql.shuffle.partitions |
200 | 配置在为连接或聚合洗牌数据时要使用的分区数。 |
Broadcast Hint for SQL Queries(SQL查询的广播提示)
from pyspark.sql.functions import broadcast
broadcast(spark.table("src")).join(spark.table("records"), "key").show()
Distributed SQL Engine(分布式SQL引擎)
Running the Thrift JDBC/ODBC server(运行Thrift JDBC / ODBC服务器)
./sbin/start-thriftserver.sh
export HIVE_SERVER2_THRIFT_PORT=<listening-port>
export HIVE_SERVER2_THRIFT_BIND_HOST=<listening-host>
./sbin/start-thriftserver.sh \
--master <master-uri> \
...或系统属性:
./sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=<listening-port> \
--hiveconf hive.server2.thrift.bind.host=<listening-host> \
--master <master-uri>
...现在您可以使用beeline来测试Thrift JDBC / ODBC服务器:
./bin/beeline
使用以下方式直接连接到JDBC / ODBC服务器:
beeline> !connect jdbc:hive2://localhost:10000
hive.server2.transport.mode - Set this to value: http
hive.server2.thrift.http.port - HTTP port number to listen on; default is 10001
hive.server2.http.endpoint - HTTP endpoint; default is cliservice
要进行测试,请使用beeline以http模式连接到JDBC / ODBC服务器:
beeline> !connect jdbc:hive2://<host>:<port>/<database>?hive.server2.transport.mode=http;hive.server2.thrift.http.path=<http_endpoint>
Running the Spark SQL CLI(运行Spark SQL CLI)
./bin/spark-sql
Spark译文(一)的更多相关文章
- Spark译文(三)
Structured Streaming Programming Guide(结构化流编程指南) Overview(概貌) ·Structured Streaming是一种基于Spark SQL引擎的 ...
- Spark译文(二)
PySpark Usage Guide for Pandas with Apache Arrow(使用Apache Arrow的Pandas PySpark使用指南) Apache Arrow in ...
- spark 学习
三种编译方式 1. 编译文档:more—>buiding spark 2. 三种编译方式:SBT,Maven,打包编译 make-distribution.sh 运行方式 local,stand ...
- 【Spark学习】Apache Spark调优
Spark版本:1.1.0 本文系以开源中国社区的译文为基础,结合官方文档翻译修订而来,转载请注明以下链接: http://www.cnblogs.com/zhangningbo/p/4117981. ...
- Spark 2.x不支持ALTER TABLE ADD COLUMNS,没关系,我们改进下
SparkSQL从2.0开始已经不再支持ALTER TABLE table_name ADD COLUMNS (col_name data_type [COMMENT col_comment], .. ...
- spark中groupByKey与reducByKey
[译]避免使用GroupByKey Scala Spark 技术 by:leotse 原文:Avoid GroupByKey 译文 让我们来看两个wordcount的例子,一个使用了reduceB ...
- sparklyr包:实现Spark与R的接口
日前,Rstudio公司发布了sparklyr包.该包具有以下几个功能: 实现R与Spark的连接—sparklyr包提供了一个完整的dplyr后端 筛选并聚合Spark数据集,接着在R中实现分析与可 ...
- sparklyr包:实现Spark与R的接口+sparklyr 0.5
本文转载于雪晴数据网 相关内容: sparklyr包:实现Spark与R的接口,会用dplyr就能玩Spark Sparklyr与Docker的推荐系统实战 R语言︱H2o深度学习的一些R语言实践-- ...
- Spark技术内幕:究竟什么是RDD
RDD是Spark最基本,也是最根本的数据抽象.http://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdf 是关于RDD的论文.如果觉得英 ...
随机推荐
- # 江西ccpc省赛-waves-(DP做法)
江西ccpc省赛-waves-(DP做法) 题链:http://acm.hdu.edu.cn/showproblem.php?pid=6570 题意:给你长度为N,1≤N≤100000的一个数组,其中 ...
- Windows系统下同时安装Python2和Python3
Windows系统下同时安装Python2和Python3 说明 有时由于工作需求我们需要在Python2版本下面进行一些开发,有时又需要Python3以上的版本,那么我们怎么在一台电脑上同时安装多个 ...
- rabbitmq中关于exchange模式type报错
channel.exchange_declare(exchange='logs', type='fanout') 报错: Traceback (most recent call last): Fil ...
- solr学习笔记-增加mmesg4J中文分词
solr版本6.1.centos6.7.mmesg4j版本2.30 solr安装目录:/usr/local/solr-6.1.0 1.下载mmesg4j包: 地址:https://github.com ...
- Intellij IDEA 配置 Code Style
前言 昨天自说自话,闲扯了界面设计和代码规范.设计确实需要一些经验,也不一定能取悦所有人.而代码规范却是程序员所起码应当做到的,多人协作中,杂乱的代码就好像批阅潦草的作文,可读性极差. 然而这是个懒人 ...
- 使用JavaScript实现字符串格式化
使用JavaScript实现字符串格式化 String.prototype.format = function (kwargs) { /* hello-{n}-{m} {'n':'word','m': ...
- SQL数据库字段数据类型详细说明
这里先总结数据类型.MySQL中的数据类型大的方面来分,可以分为:日期和时间.数值,以及字符串.下面就分开来进行总结. 日期和时间数据类型 MySQL数据类型 含义 date 3字节,日期,格式:20 ...
- This application has no explicit mapping for /error, so you are seeing this as a fallback.
检查url是否输入正确,要加上之前的mapping映射
- 两个实体类 复制 copy 工具类
import java.lang.reflect.Field; import java.lang.reflect.Method; import java.util.Date; public class ...
- slf4j日志的使用-学习笔记
maven项目: 一.首先在pom.xml文件中添加maven依赖 这是其中一种: <dependency> <groupId>org.slf4j</groupI ...