mysql的事务四个特性以及 事务的四个隔离级别
一、事务四大属性
分别是原子性、一致性、隔离性、持久性。
1,原子性(Atomicity)
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。
参考:什么是原子性操作?
2,一致性(Consistency)
一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。举例来说,假设用户A和用户B两者的钱加起来一共是1000,那么不管A和B之间如何转账、转几次账,事务结束后两个用户的钱相加起来应该还得是1000,这就是事务的一致性。
3,隔离性(Isolation)
隔离性是当多个用户并发访问数据库时,比如同时操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。关于事务的隔离性数据库提供了多种隔离级别,稍后会介绍到。
有疑问???
4,持久性(Durability)
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。例如我们在使用JDBC操作数据库时,在提交事务方法后,提示用户事务操作完成,当我们程序执行完成直到看到提示后,就可以认定事务已经正确提交,即使这时候数据库出现了问题,也必须要将我们的事务完全执行完成。否则的话就会造成我们虽然看到提示事务处理完毕,但是数据库因为故障而没有执行事务的重大错误。这是不允许的。
有疑问???
二、事务的隔离级别
1,为什么要设置隔离级别
在数据库操作中,在并发的情况下可能出现如下问题:
更新丢失(Lost update)
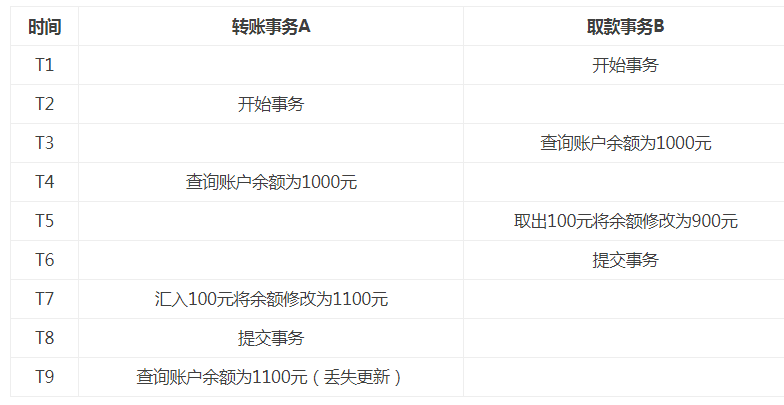
如果多个线程操作,基于同一个查询结构对表中的记录进行修改,那么后修改的记录将会覆盖前面修改的记录,前面的修改就丢失掉了,这就叫做更新丢失。这是因为系统没有执行任何的锁操作,因此并发事务并没有被隔离开来。
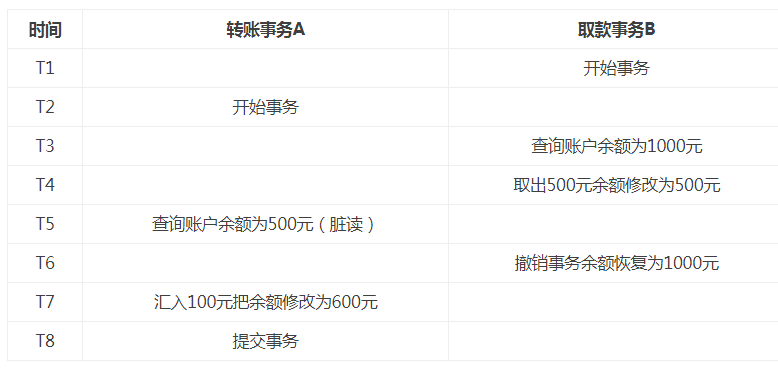
第1类丢失更新:事务A撤销时,把已经提交的事务B的更新数据覆盖了。
第2类丢失更新:事务A覆盖事务B已经提交的数据,造成事务B所做的操作丢失。
解决方法:对行加锁,只允许并发一个更新事务。脏读(Dirty Reads)
脏读(Dirty Read):A事务读取B事务尚未提交的数据并在此基础上操作,而B事务执行回滚,那么A读取到的数据就是脏数据。
解决办法:如果在第一个事务提交前,任何其他事务不可读取其修改过的值,则可以避免该问题。不可重复读(Non-repeatable Reads)
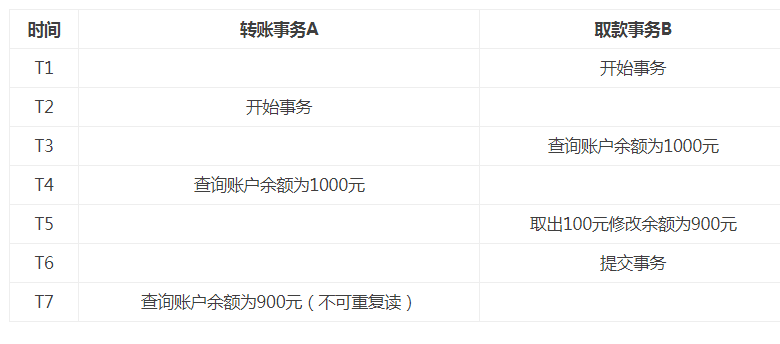
一个事务对同一行数据重复读取两次,但是却得到了不同的结果。事务T1读取某一数据后,事务T2对其做了修改,当事务T1再次读该数据时得到与前一次不同的值。
解决办法:如果只有在修改事务完全提交之后才可以读取数据,则可以避免该问题。幻象读
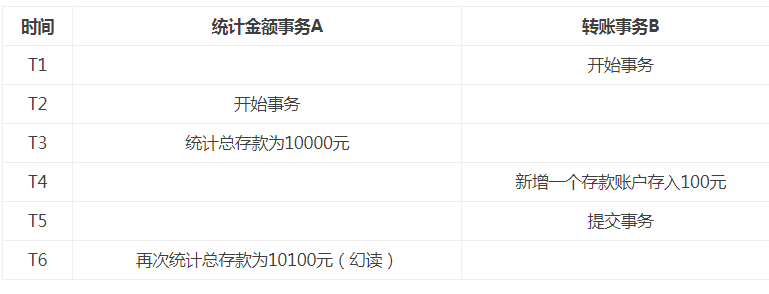
指两次执行同一条 select 语句会出现不同的结果,第二次读会增加一数据行,并没有说这两次执行是在同一个事务中。一般情况下,幻象读应该正是我们所需要的。但有时候却不是,如果打开的游标,在对游标进行操作时,并不希望新增的记录加到游标命中的数据集中来。隔离级别为 游标稳定性 的,可以阻止幻象读。例如:目前工资为1000的员工有10人。那么事务1中读取所有工资为1000的员工,得到了10条记录;这时事务2向员工表插入了一条员工记录,工资也为1000;那么事务1再次读取所有工资为1000的员工共读取到了11条记录。
解决办法:如果在操作事务完成数据处理之前,任何其他事务都不可以添加新数据,则可避免该问题。

正是为了解决以上情况,数据库提供了几种隔离级别。
2、事务的隔离级别
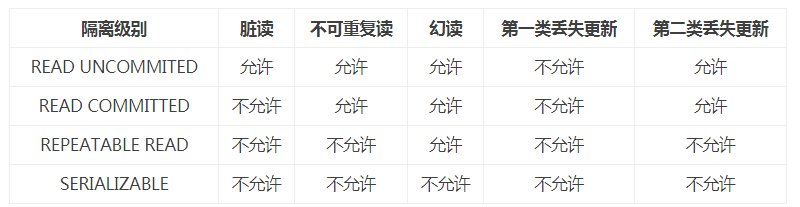
数据库事务的隔离级别有4个,由低到高依次为Read uncommitted(未授权读取、读未提交)、Read committed(授权读取、读提交)、Repeatable read(可重复读取)、Serializable(序列化),这四个级别可以逐个解决脏读、不可重复读、幻象读这几类问题。
- Read uncommitted(未授权读取、读未提交):
如果一个事务已经开始写数据,则另外一个事务则不允许同时进行写操作,但允许其他事务读此行数据。该隔离级别可以通过“排他写锁”实现。这样就避免了更新丢失,却可能出现脏读。也就是说事务B读取到了事务A未提交的数据。 - Read committed(授权读取、读提交):
读取数据的事务允许其他事务继续访问该行数据,但是未提交的写事务将会禁止其他事务访问该行。该隔离级别避免了脏读,但是却可能出现不可重复读。事务A事先读取了数据,事务B紧接了更新了数据,并提交了事务,而事务A再次读取该数据时,数据已经发生了改变。 - Repeatable read(可重复读取):
可重复读是指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两次读数据之间,即使第二个事务对数据进行修改,第一个事务两次读到的的数据是一样的。这样就发生了在一个事务内两次读到的数据是一样的,因此称为是可重复读。读取数据的事务将会禁止写事务(但允许读事务),写事务则禁止任何其他事务。这样避免了不可重复读取和脏读,但是有时可能出现幻象读。(读取数据的事务)这可以通过“共享读锁”和“排他写锁”实现。 - Serializable(序列化):
提供严格的事务隔离。它要求事务序列化执行,事务只能一个接着一个地执行,但不能并发执行。如果仅仅通过“行级锁”是无法实现事务序列化的,必须通过其他机制保证新插入的数据不会被刚执行查询操作的事务访问到。序列化是最高的事务隔离级别,同时代价也花费最高,性能很低,一般很少使用,在该级别下,事务顺序执行,不仅可以避免脏读、不可重复读,还避免了幻像读。
隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大。对于多数应用程序,可以优先考虑把数据库系统的隔离级别设为Read Committed。它能够避免脏读取,而且具有较好的并发性能。尽管它会导致不可重复读、幻读和第二类丢失更新这些并发问题,在可能出现这类问题的个别场合,可以由应用程序采用悲观锁或乐观锁来控制。大多数数据库的默认级别就是Read committed,比如Sql Server , Oracle。MySQL的默认隔离级别就是Repeatable read。
三、悲观锁和乐观锁
虽然数据库的隔离级别可以解决大多数问题,但是灵活度较差,为此又提出了悲观锁和乐观锁的概念。
1、悲观锁
悲观锁,它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度。因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制。也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统的数据访问层中实现了加锁机制,也无法保证外部系统不会修改数据。
- 使用场景举例:以MySQL InnoDB为例
商品t_items表中有一个字段status,status为1代表商品未被下单,status为2代表商品已经被下单(此时该商品无法再次下单),那么我们对某个商品下单时必须确保该商品status为1。假设商品的id为1。
如果不采用锁,那么操作方法如下:
//1.查询出商品信息select status from t_items where id=1;//2.根据商品信息生成订单,并插入订单表 t_ordersinsert into t_orders (id,goods_id) values (null,1);//3.修改商品status为2update t_items set status=2;
- 1
- 2
- 3
- 4
- 5
- 6
但是上面这种场景在高并发访问的情况下很可能会出现问题。例如当第一步操作中,查询出来的商品status为1。但是当我们执行第三步Update操作的时候,有可能出现其他人先一步对商品下单把t_items中的status修改为2了,但是我们并不知道数据已经被修改了,这样就可能造成同一个商品被下单2次,使得数据不一致。所以说这种方式是不安全的。
- 使用悲观锁来解决问题
在上面的场景中,商品信息从查询出来到修改,中间有一个处理订单的过程,使用悲观锁的原理就是,当我们在查询出t_items信息后就把当前的数据锁定,直到我们修改完毕后再解锁。那么在这个过程中,因为t_items被锁定了,就不会出现有第三者来对其进行修改了。需要注意的是,要使用悲观锁,我们必须关闭mysql数据库的自动提交属性,因为MySQL默认使用autocommit模式,也就是说,当你执行一个更新操作后,MySQL会立刻将结果进行提交。我们可以使用命令设置MySQL为非autocommit模式:set autocommit=0;
设置完autocommit后,我们就可以执行我们的正常业务了。具体如下:
//0.开始事务begin;/begin work;/start transaction; (三者选一就可以)//1.查询出商品信息select status from t_items where id=1 for update;//2.根据商品信息生成订单insert into t_orders (id,goods_id) values (null,1);//3.修改商品status为2update t_items set status=2;//4.提交事务commit;/commit work;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
上面的begin/commit为事务的开始和结束,因为在前一步我们关闭了mysql的autocommit,所以需要手动控制事务的提交。
上面的第一步我们执行了一次查询操作:select status from t_items where id=1 for update;与普通查询不一样的是,我们使用了select…for update的方式,这样就通过数据库实现了悲观锁。此时在t_items表中,id为1的那条数据就被我们锁定了,其它的事务必须等本次事务提交之后才能执行。这样我们可以保证当前的数据不会被其它事务修改。需要注意的是,在事务中,只有SELECT ... FOR UPDATE 或LOCK IN SHARE MODE 操作同一个数据时才会等待其它事务结束后才执行,一般SELECT ... 则不受此影响。拿上面的实例来说,当我执行select status from t_items where id=1 for update;后。我在另外的事务中如果再次执行select status from t_items where id=1 for update;则第二个事务会一直等待第一个事务的提交,此时第二个查询处于阻塞的状态,但是如果我是在第二个事务中执行select status from t_items where id=1;则能正常查询出数据,不会受第一个事务的影响。
- Row Lock与Table Lock
使用select…for update会把数据给锁住,不过我们需要注意一些锁的级别,MySQL InnoDB默认Row-Level Lock,所以只有「明确」地指定主键或者索引,MySQL 才会执行Row lock (只锁住被选取的数据) ,否则MySQL 将会执行Table Lock (将整个数据表单给锁住)。举例如下:
1、select * from t_items where id=1 for update;
这条语句明确指定主键(id=1),并且有此数据(id=1的数据存在),则采用row lock。只锁定当前这条数据。
2、select * from t_items where id=3 for update;
这条语句明确指定主键,但是却查无此数据,此时不会产生lock(没有元数据,又去lock谁呢?)。
3、select * from t_items where name='手机' for update;
这条语句没有指定数据的主键,那么此时产生table lock,即在当前事务提交前整张数据表的所有字段将无法被查询。
4、select * from t_items where id>0 for update; 或者select * from t_items where id<>1 for update;(注:<>在SQL中表示不等于)
上述两条语句的主键都不明确,也会产生table lock。
5、select * from t_items where status=1 for update;(假设为status字段添加了索引)
这条语句明确指定了索引,并且有此数据,则产生row lock。
6、select * from t_items where status=3 for update;(假设为status字段添加了索引)
这条语句明确指定索引,但是根据索引查无此数据,也就不会产生lock。
- 悲观锁小结
悲观锁并不是适用于任何场景,它也有它存在的一些不足,因为悲观锁大多数情况下依靠数据库的锁机制实现,以保证操作最大程度的独占性。如果加锁的时间过长,其他用户长时间无法访问,影响了程序的并发访问性,同时这样对数据库性能开销影响也很大,特别是对长事务而言,这样的开销往往无法承受。所以与悲观锁相对的,我们有了乐观锁。
2、乐观锁
乐观锁( Optimistic Locking ) 相对悲观锁而言,乐观锁假设认为数据一般情况下不会造成冲突,所以只会在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则返回用户错误的信息,让用户决定如何去做。实现乐观锁一般来说有以下2种方式:
- 使用版本号
使用数据版本(Version)记录机制实现,这是乐观锁最常用的一种实现方式。何谓数据版本?即为数据增加一个版本标识,一般是通过为数据库表增加一个数字类型的 “version” 字段来实现。当读取数据时,将version字段的值一同读出,数据每更新一次,对此version值加一。当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的version值进行比对,如果数据库表当前版本号与第一次取出来的version值相等,则予以更新,否则认为是过期数据。 - 使用时间戳
乐观锁定的第二种实现方式和第一种差不多,同样是在需要乐观锁控制的table中增加一个字段,名称无所谓,字段类型使用时间戳(timestamp), 和上面的version类似,也是在更新提交的时候检查当前数据库中数据的时间戳和自己更新前取到的时间戳进行对比,如果一致则OK,否则就是版本冲突。
参考文档:https://www.cnblogs.com/limuzi1994/p/9684083.html
mysql的事务四个特性以及 事务的四个隔离级别的更多相关文章
- 数据库事务的四大特性以及事务的隔离级别-与-Spring事务传播机制&隔离级别
数据库事务的四大特性以及事务的隔离级别 本篇讲诉数据库中事务的四大特性(ACID),并且将会详细地说明事务的隔离级别. 如果一个数据库声称支持事务的操作,那么该数据库必须要具备以下四个特性: ⑴ ...
- mysql的事务四个特性以及事务的四个隔离级别
一.事务四大属性 分别是原子性.一致性.隔离性.持久性. 1.原子性(Atomicity) 原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,因此事务的操作如果成功就必须要完全应用到数据库, ...
- 数据库事务的四大特性以及事务的隔离级别(mysql)
本篇讲诉数据库中事务的四大特性(ACID),并且将会详细地说明事务的隔离级别. 如果一个数据库声称支持事务的操作,那么该数据库必须要具备以下四个特性: ⑴ 原子性(Atomicity) 原子性是指 ...
- MySQL数据库事务的四大特性以及事务的隔离级别
一.事务的四大特性(ACID) 如果一个数据库声称支持事务的操作,那么该数据库必须要具备以下四个特性: 1.原子性(Atomicity) 原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,因 ...
- Mysql 四种事务隔离级别
一.前提 时过一年重新拾起博文记录,希望后面都能坚持下来. 接着之前MySql的学习,先记录下这篇. 以下都是基于mysql8 innodb存储引擎进行分析的. 二.事务的ACID特性 A(Atomi ...
- Mysql(三)------事务的特性、事务并发、事务读一致性问题
1 什么是数据库的事务? 1.1 事务的典型场景 在项目里面,什么地方会开启事务,或者配置了事务?无论是在方法上加注解,还 是配置切面 <tx:advice id="txAdvice& ...
- MySQL事务及ACID特性
一.事物 1.定义:事务是访问和更新数据库的程序执行单元,事务中包含一条或者多条SQL语句,这些语句要么全部执行成功,要么都不执行. 在MySQL中,事务支持是在引擎层实现的,MySQL是一个支持多引 ...
- 事务的隔离级别及mysql对应操作
/* 本次高并发解决之道 1,更改事务隔离级别为 read uncommitted读未提交 2,查询前设定延迟,延迟时间为随机 50-500 微秒 3,修改数据前将 超范围作为 限定修改条件 事务是作 ...
- MySQL详解--锁,事务
http://www.cnblogs.com/jukan/p/5670950.html http://blog.csdn.net/xifeijian/article/details/20313977 ...
随机推荐
- MongoDB服务的安装与删除
服务的安装: 在MongoDB的目录下创建两个文件夹 data和logs, 在通过cmd进入bin目录下,执行命令: mongod --dbpath "C:\Program Files\Mo ...
- 职责链模式ChainOfResponsibility
原创转载请注明出处:https://www.cnblogs.com/agilestyle/p/11407114.html 1.定义 使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合 ...
- paper 134:结构张量structure tensor(二)
根据结构张量能区分图像的平坦区域.边缘区域与角点区域. 此算法也算是计算机科学最重要的32个算法之一了.链接的文章中此算法名称为Strukturtensor算法,不过我搜索了一下,Strukturte ...
- 关于最近练习PYTHON代码的一点心得
做测试以来,一直想学习代码,以前也断断续续的学习过,不过都是练习一些基础语法,学习的是菜鸟教程,但是效果不大. 最近在练习CODEWAR里做练习题,慢慢强化自己对一些基本语法的理解,熟悉基本的内置函数 ...
- 7、c++版,在大学学的编程基础知识
1.各种排序 #include<iostream> using namespace std; //-------直接插入排序 void InsertSort(ElemType A[],in ...
- Python错误 importModuleNotFoundError: No module named 'Crypto'
0x00经过 今天在python中导入模块的用 from Crypto.Cipher import AES 的时候出现了找不到模块的错误. 百度了很长时间有很多解决方法,但是因不同的环境不同的 ...
- javascript实现继承的六种方式
/*实现继承的六种方式*/ /*1.扩展原型对象的方法实现继承*/ function Foo1(){} //在Foo1函数上扩展一个fn1方法,由构造函数创建的对象都具有fn1这个方法 Foo1. ...
- 2018 ICPC Asia Singapore Regional A. Largest Triangle (计算几何)
题目链接:Kattis - largesttriangle Description Given \(N\) points on a \(2\)-dimensional space, determine ...
- Python Numpy 矩阵级基本操作(1)
NumPy的操作介绍 import numpy as np #导入numpy包,简写为np print "Generate 1*10 matrix" a=np.arange(1,1 ...
- Django框架(十七)—— 中间件、CSRF跨站请求伪造
目录 中间件 一.什么是中间件 二.中间件的作用 三.中间件执行顺序 四.自定义中间件 1.导包 2.定义类,继承MiddlewareMixin 3.在视图函数中定义一个函数 4.在settings的 ...