(3)SQL Server表分区
1.简介
当一个表数据量很大时候,很自然我们就会想到将表拆分成很多小表,在执行查询时候就到各个小表去查,最后汇总数据集返回给调用者加快查询速度。比如电商平台订单表,库存表,由于长年累月读写较多,积累数据都是异常庞大的,这时候,我们可以想到表分区这个做法,降低运维和维护成本,提高读写性能。比如将前半年订单放一个历史分区表,不活跃库存放一个历史分区表。截止到SQL Server 2016,一张表或一个索引最多可以有15000个分区。
2.表分区
2.1分区范围
分区范围是指在要分区的表中,根据业务选择表中的关键字段做为分区边界条件,分区后,数据所在的具体位置至关重要,这样才能在需要时只访问相应的分区。注意分区是指数据的逻辑分离,不是数据在磁盘上的物理位置,数据的位置由文件组来决定,所以一般建议一个分区对应一个文件组。
2.2分区键
分区表中的字段可以作为分区键,比如库存表中供应商ID。对表和索引进行分区的第一步就是定义分区的关键数据。
2.3索引分区
除了对表的数据集进行分区之外,还可以对索引进行分区,使用相同的函数对表及其索引进行分区通常可以优化性能。
3.创建表分区
3.1创建文件组
在这里演示示例当中,我根据业务场景在TestDB数据库新增三个文件组,而三个文件组分别对应三个分区。而多个文件组好处是可以按照不同业务场景将数据放在对应文件组当中,优化性能同时好维护数据。文件组数量由硬件决定,最好是一个文件组对应一个分区,好维护。而通常文件组都处于不同磁盘上的,但是由于是演示,我只在一个磁盘中存放。
--创建四个文件组
ALTER DATABASE [TestDB] ADD FILEGROUP SupIDGroup1
ALTER DATABASE [TestDB] ADD FILEGROUP SupIDGroup2
ALTER DATABASE [TestDB] ADD FILEGROUP SupIDGroup3
3.2指定文件组存放路径
在创建文件组之后,指定文件组存放磁盘位置,文件大小。
--创建四个ndf文件,对应到各文件组中,FILENAME文件存储路径
ALTER DATABASE [TestDB] ADD FILE(
NAME='SupIDGroupFile1',
FILENAME='D:\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\SupIDGroupFile1.ndf',
SIZE=10MB,
FILEGROWTH=10MB)
TO FILEGROUP SupIDGroup1 ALTER DATABASE [TestDB] ADD FILE(
NAME='SupIDGroupFile2',
FILENAME='D:\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\SupIDGroupFile2.ndf',
SIZE=10MB,
FILEGROWTH=10MB)
TO FILEGROUP SupIDGroup2 ALTER DATABASE [TestDB] ADD FILE(
NAME='SupIDGroupFile3',
FILENAME='D:\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\SupIDGroupFile3.ndf',
SIZE=10MB,
FILEGROWTH=10MB)
TO FILEGROUP SupIDGroup3
注(附上删除文件组T-SQL):
ALTER DATABASE [TestDB] REMOVE FILE SupIDGroupFile3
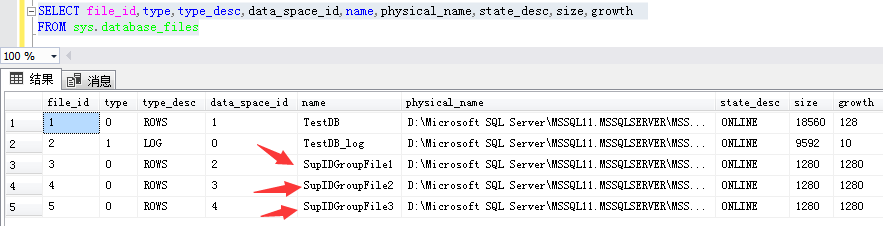
可以通过以下T-SQL语句查看文件组存放相关信息:
SELECT file_id,type,type_desc,data_space_id,name,physical_name,state_desc,size,growth
FROM sys.database_files
3.3创建分区函数
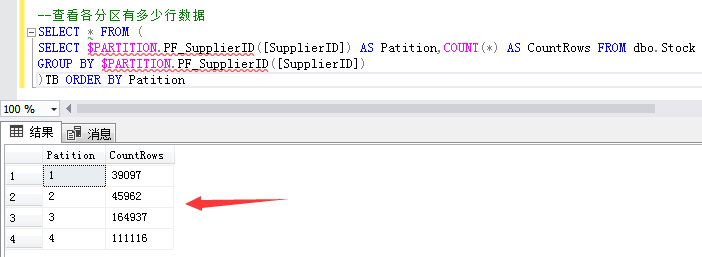
如何创建表分区边界值,我们肯定要根据业务场景来决定。比如我测试库库存表有36万左右数据,而有些供应商的库存数据远远比其他供应商大,那么我可以考虑使用供应商ID字段作为边界值分区。例如:根据T-SQL统计,18080供应商库存数据最大,那么我可以根据18080供应商上下分为三个区。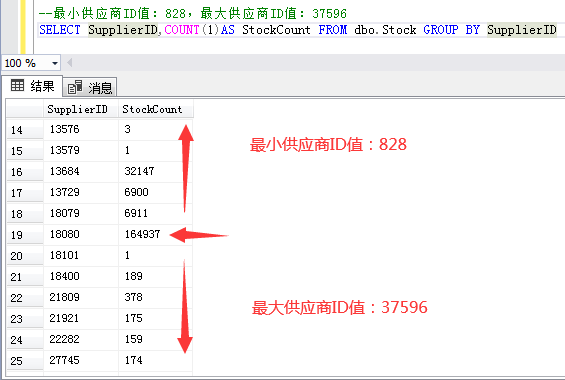
第一个分区范围记录:供应商ID小于等于13570的39097条库存数据。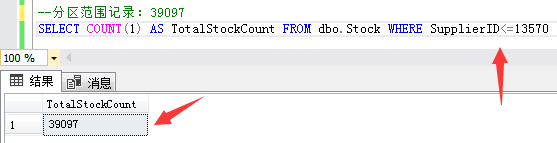
第二个分区范围记录:供应商ID大于13570和小于等于18079的45962条库存数据。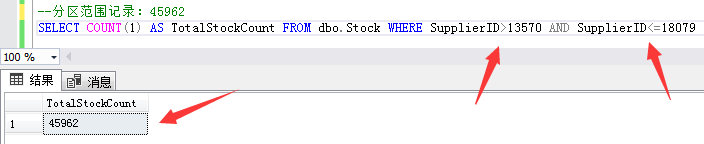
第三个分区范围记录:供应商ID大于18079小于等于18080的164937条库存数据。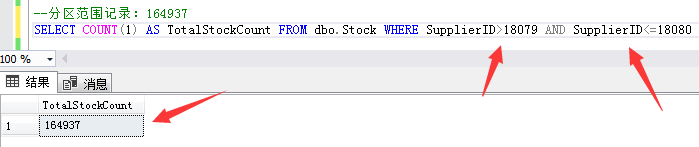
第四个分区范围记录:供应商ID大于18080的111116条库存数据。
根据上述分区范围记录,我们可以将供应商ID作为边界值设置,执行以下T-SQL语句设置边界值:
--设置边界值
CREATE PARTITION FUNCTION PF_SupplierID(int)
AS RANGE LEFT FOR VALUES (,,)
执行完毕后如图所示:
3.4创建分区方案
执行以下T-SQL语句创建分区方案:
--创建分区方案
CREATE PARTITION SCHEME PS_SupplierID
AS PARTITION PF_SupplierID TO ([PRIMARY], [SupIDGroup1],[SupIDGroup2],[SupIDGroup3])
执行完毕后如图所示:

3.5创建分区表
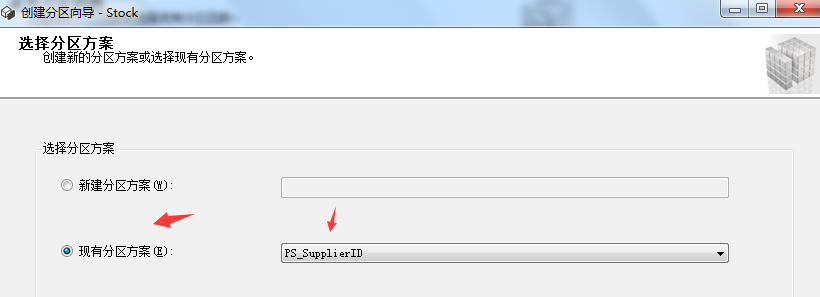
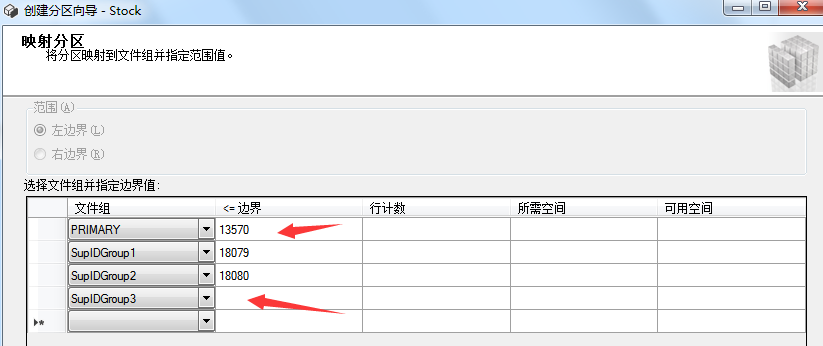
上面那些分区步骤都是为了接下来创建分区表这一步骤而准备的。废话不多说,现在我们来看看如何创建分区表。右键需要分区的表->储存->创建分区,具体步骤如下图所示:


3.6创建分区索引
--创建分区索引
CREATE NONCLUSTERED INDEX [NCI_SupplierID] ON dbo.Stock
(
SupplierID ASC
)
INCLUDE ( [Model],[Brand],[Encapsulation]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
GO
或者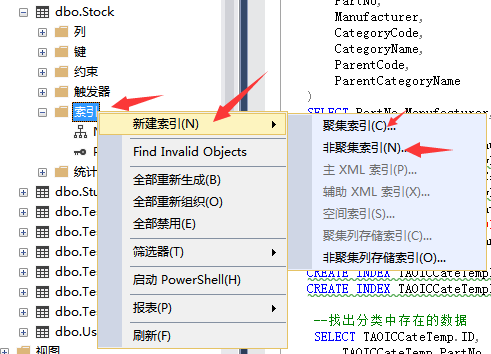
执行完毕后如图所示:
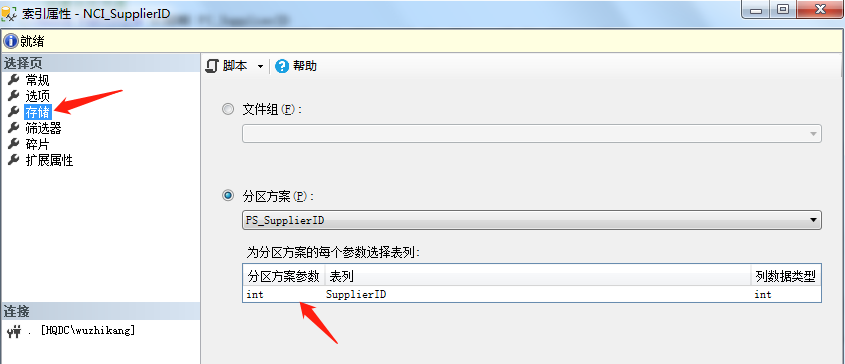
创建好索引之后,我们来看看分区情况:
--查看各分区有多少行数据
SELECT * FROM (
SELECT $PARTITION.PF_SupplierID([SupplierID]) AS Patition,COUNT(*) AS CountRows FROM dbo.Stock
GROUP BY $PARTITION.PF_SupplierID([SupplierID])
)TB ORDER BY Patition
最后我们来看看加了索引之后表数据查询情况: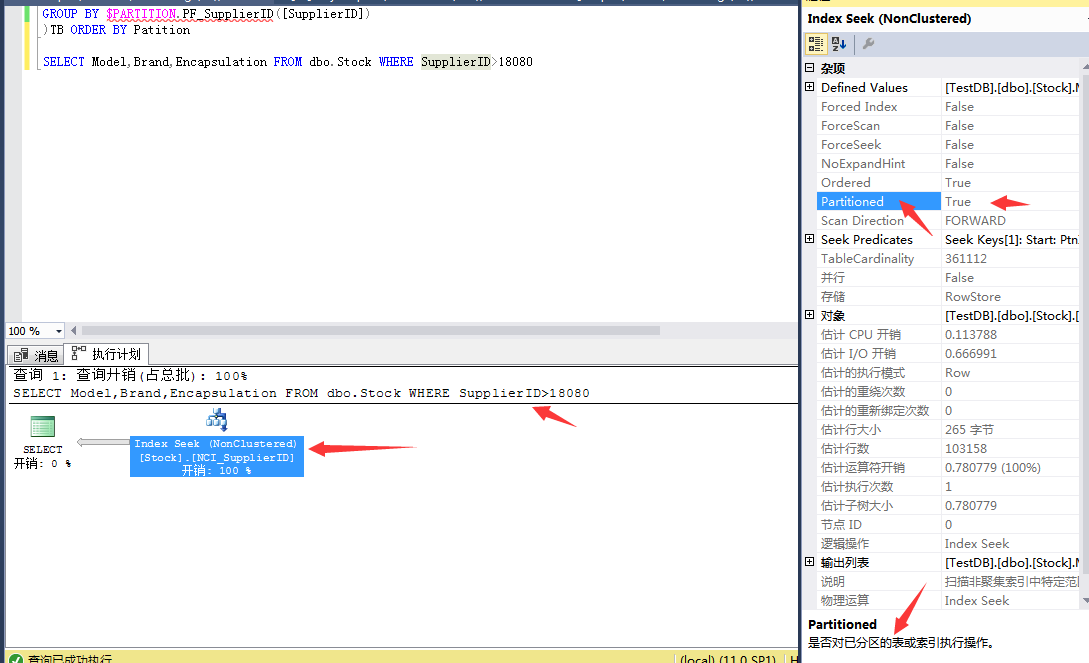
4.表分区的优缺点
优点:
●改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
●增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用。
●维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可。
●均衡I/O:可以把不同的分区映射到不同磁盘以平衡I/O,改善整个系统性能。
缺点:
分区表相关:已经存在的表没有方法可以直接转化为分区表。
(3)SQL Server表分区的更多相关文章
- SQL Server表分区的NULL值问题
SQL Server表分区的NULL值问题 SQL Server表分区只支持range分区这一种类型,但是本人觉得已经够用了 虽然MySQL支持四种分区类型:RANGE分区.LIST分区.HASH分区 ...
- SQL Server表分区【转】
转自:http://www.cnblogs.com/knowledgesea/p/3696912.html SQL Server表分区 什么是表分区 一般情况下,我们建立数据库表时,表数据都存放在 ...
- SQL Server表分区详解
原文:SQL Server表分区详解 什么是表分区 一般情况下,我们建立数据库表时,表数据都存放在一个文件里. 但是如果是分区表的话,表数据就会按照你指定的规则分放到不同的文件里,把一个大的数据文件拆 ...
- SQL Server表分区-水平分区
SQL Server表分区,sql server水平分区 转自:http://www.cnblogs.com/knowledgesea/p/3696912.html 根据时间的,直接上T-SQL代码 ...
- SQL Server 表分区备忘
1.创建的代码如下: )) AS RANGE LEFT FOR VALUES ( N', N', N',... ) CREATE PARTITION SCHEME [01_SubjectiveScor ...
- 8、SQL Server 表分区
什么是表分区?表分区其实就是将一个大表分成若干个小表.表分区可以从物理上将一个大表分成几个小表,但是逻辑上还是一个表.所以当执行插入.更新等操作的时候,不需要我们去判断应该插入或更新到哪个表中.只需要 ...
- SQL Server表分区案例
--学习创建表分区脚本/*SQL SERVER 2005中以上版本,终于引入了表分区,就是说,当一个表里的数据很多时,可以将其分拆到多个的表里,大大提高了性能.下面举例子说明之*/ --------- ...
- sql server 表分区
背景: 一般情况下,我们建立数据库表时,表数据都存放在一个文件里. 但是如果是分区表的话,表数据就会按照你指定的规则分放到不同的文件里,把一个大的数据文件拆分为多个小文件,还可以把这些小文件放在不同的 ...
- SQL Server表分区(水平分区及垂直分区)
什么是表分区? 表分区分为水平表分区和垂直表分区,水平表分区就是将一个具有大量数据的表,进行拆分为具有相同表结构的若干个表:而垂直表分区就是把一个拥有多个字段的表,根据需要进行拆分列,然后根据某一个字 ...
- SQL Server 表分区之水平表分区
什么是表分区? 表分区分为水平表分区和垂直表分区,水平表分区就是将一个具有大量数据的表,进行拆分为具有相同表结构的若干个表:而垂直表分区就是把一个拥有多个字段的表,根据需要进行拆分列,然后根据某一个字 ...
随机推荐
- Springboot与Maven多环境配置文件夹解决方案
Profile用法 我们在application.yml中为jdbc.name赋予一个值,这个值为一个变量 jdbc: username: ${jdbc.username} Maven中的profil ...
- 误删除所有redo日志的一组成员的处理过程
系统中共有3个日志文件组,每个组中各有一个日志文件成员.往系统中添加一个日志文件组,组中日志文件成员数量是2.SQL> alter database add logfile group 4 (' ...
- Cisco asa组建IPSEC for ikev1
IPSec的实现主要由两个阶段来完成:--第一阶段,双方协商安全连接,建立一个已通过身份鉴别和安全保护的通道.--第二阶段,安全协议用于保护数据的和信息的交换. IPSec有两个安全协议:AH和ESP ...
- 手写Promise原理
我的promise能实现什么? 1:解决回调地狱,实现异步 2:可以链式调用,可以嵌套调用 3:有等待态到成功态的方法,有等待态到失败态的方法 4:可以衍生出周边的方法,如Promise.resolv ...
- [C++入门篇]了解C++
前言 我是杨某人,点击右下方"+"一键关注我.如果你喜欢我的文章,那么拒绝白嫖行为.然后..请多来做客鸭. 如果你是已经入门的大佬,请滑到下方点个推荐再走. 我个人认为,博客有两种 ...
- nes 红白机模拟器 第5篇 全屏显示
先看一下效果图 放大的原理是使用最初级的算法,直接取对应像素法. /*================================================================= ...
- Redis05——Redis Cluster 如何实现分布式集群
前面一片文章,我们已经说了Redis的主从集群及其哨兵模式.本文将继续介绍Redis的分布式集群. 在高并发场景下,单个Redis实例往往不能满足业务需求.单个Redis数据量过大会导致RDB文件过大 ...
- GitHub 热点速览 Vol.11:回暖的 GitHub 迎来上千星的图片流项目
作者:HelloGitHub-小鱼干 摘要:连着两周成绩平平的 GitHub Trending 榜,终于和三月的天气一样进入全面变暖的模式,无论是本周刚开源搭乘 ocr 热点并获得 1,500+ st ...
- Linux 文件系统及 ext2 文件系统
linux 支持的文件系统类型 Ext2: 有点像 UNIX 文件系统.有 blocks,inodes,directories 的概念. Ext3: Ext2 的加强版,添加了日志 ...
- centos-Linux静态IP地址配置
首先在VMware菜单中点击编辑-->虚拟网卡编辑器,查看NAT网段(子网掩码.网关.起止IP地址) 1.用nmcli命令配置IP地址 [root@Core ~]# nmcli connecti ...