【Kafka】自定义分区策略
自定义分区策略
思路
Command+Option+shift+N 调出查询页面,找到producer包的Partitioner接口
Partitioner下有一个DefaultPartitioner实现类
这里就有之前提到kafka数据分区策略
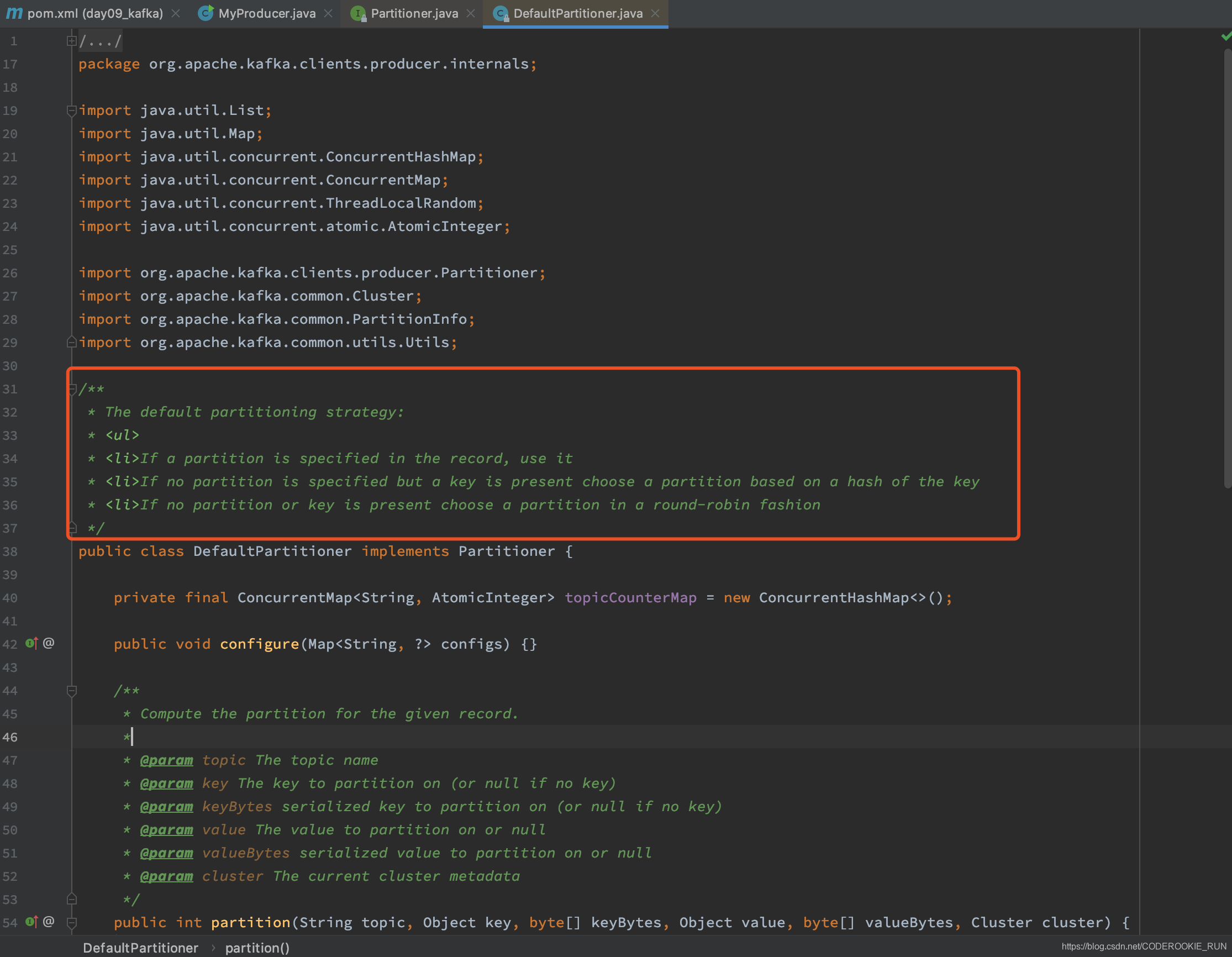
自定义分区策略
创建一个MyPartitioner类,继承并重新定义上面的Partitioner类
package cn.itcast.kafka.demo1;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
public class MyPartitioner implements Partitioner {
/**
* 此方法是确定分区规则
* @param topic
* @param key
* @param keyBytes
* @param value
* @param valueBytes
* @param cluster
* @return 返回的int值为分区
*/
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
//return 3 则指定发送数据到3分区
return 3;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
还需要在MyProducer中添加一行代码
props.put("partitioner.class","cn.itcast.kafka.demo1.MyPartitioner");
而且在MyProducer类中不需要指定分区号
producer.send(new ProducerRecord<String, String>("test" , "mykey" + i,"这是第" + i + "条message"));
【Kafka】自定义分区策略的更多相关文章
- kafka 自定义分区器
package cn.xiaojf.kafka.producer; import org.apache.kafka.clients.producer.Partitioner; import org.a ...
- Kafka 生产者分区策略
分区策略 1)分区的原因 (1)方便在集群中扩展,每个 Partition 可以通过调整以适应它所在的机器,而一个 topic 又可以有多个 Partition 组成,因此整个集群就可以适应任意大小的 ...
- 【Kafka】数据分区策略
数据分区策略 四种策略 一.指定分区号,数据会直接发送到所指定的分区 二.没有指定分区号,指定了数据的key,可以通过key获取hashCode决定数据发送到哪个分区 三.都没有指定的话,会采取rou ...
- Kafka分区策略
Kafka分区策略 所谓分区策略是决定生产者将消息发送到哪个分区的算法.Kafka 为我们提供了默认的分区策略,同时它也支持你自定义分区策略. 常见的分区策略包含以下几种:轮询策略.随机策略 .按消息 ...
- Spark自定义分区(Partitioner)
我们都知道Spark内部提供了HashPartitioner和RangePartitioner两种分区策略,这两种分区策略在很多情况下都适合我们的场景.但是有些情况下,Spark内部不能符合咱们的需求 ...
- kafka的分区分配策略
用过 Kafka 的同学应该都知道,每个 Topic 一般会有很多个 partitions.为了使得我们能够及时消费消息,我们也可能会启动多个 Consumer 去消费,而每个 Consumer 又会 ...
- kafka数据分区的四种策略
kafka的数据的分区 探究的是kafka的数据生产出来之后究竟落到了哪一个分区里面去了 第一种分区策略:给定了分区号,直接将数据发送到指定的分区里面去 第二种分区策略:没有给定分区号,给定数据的ke ...
- Kafka的接口回调 +自定义分区、拦截器
一.接口回调+自定义分区 1.接口回调:在使用消费者的send方法时添加Callback回调 producer.send(new ProducerRecord<String, String> ...
- kafka Poll轮询机制与消费者组的重平衡分区策略剖析
注意本文采用最新版本进行Kafka的内核原理剖析,新版本每一个Consumer通过独立的线程,来管理多个Socket连接,即同时与多个broker通信实现消息的并行读取.这就是新版的技术革新.类似于L ...
随机推荐
- 利用numpy实现多维数组操作图片
1.上次介绍了一点点numpy的操作,今天我们来介绍它如何用多维数组操作图片,这之前我们要了解一下色彩是由blue ,green ,red 三种颜色混合而成,0:表示黑色 ,127:灰色 ,255:白 ...
- 用Taro做个微信小程序Todo, 小白工作记录
微信小程序框架: Taro 做微信小程序的框架, 几个比较主流的: 官方的WePY: https://tencent.github.io/wepy/document.html#/ 美团的mpvue: ...
- @ModelAttribute 的使用
@ModelAttribute注解可被应用在 方法 或 方法参数 上. 对方法使用 @ModelAttribute 注解: 注解在方法上的@ModelAttribute说明了方法的作用是用于添加一个或 ...
- L12 Transformer
Transformer 在之前的章节中,我们已经介绍了主流的神经网络架构如卷积神经网络(CNNs)和循环神经网络(RNNs).让我们进行一些回顾: CNNs 易于并行化,却不适合捕捉变长序列内的依赖关 ...
- Java优秀教程
1.java中局部变量是在栈上分配的: 2.数组是储存在堆上的对象,可以保存多个同类型变量: 3.在Java语言中,所有的变量在使用前必须声明. 4.局部变量没有默认值,所以局部变量被声明后,必须经过 ...
- [php代码审计]bluecms v1.6 sp1
一.环境搭建 bluecms v1.6 sp1源码 windows 7 phpstudy2016(php 5.4.45) seay源代码审计系统 源码在网上很容易下载,很多教程说访问地址 http:/ ...
- tensorflow1.0 placeholder占位符
import tensorflow as tf #(tf.float32,[2,2]) input1 = tf.placeholder(tf.float32) input2 = tf.placehol ...
- pytorch seq2seq模型中加入teacher_forcing机制
在循环内加的teacher forcing机制,这种为目标确定的时候,可以这样加. 目标不确定,需要在循环外加. decoder.py 中的修改 """ 实现解码器 &q ...
- 进阶 Linux基本命令-1
vmware三种网络模式1,桥接虚拟机直接连接外网,局域网.宿主机电脑不提供路由. 2,NAT网络地址转换,家庭网 3,host only 只能和宿主电脑打交道 Linux命令形式 命令 +[参数]+ ...
- Inno Script - How to make “I Accept the Agreement” radio button on EULA page selected by Default
出处: https://stackoverflow.com/questions/11187022/inno-script-how-to-make-i-accept-the-agreement-radi ...