环境篇:Superset
环境篇:Superset


Superset 是什么?
Apache Superset 是一个开源、现代、轻量的BI分析工具,能够对接多种数据源,拥有丰富的图表展示形式、支持自定义仪表盘,用户界面友好,易用。
如果没有Superset
大数据展示需要自行开发,费时费力,不能直观的展示数据报表,如数据仓库中大量的表信息图形化展示需要大量的开发周期。
1 搭建
环境要求:Python3.6运行了全套测试控件(建议选择),3.7官网说的也是兼容的,但没有经过全套测试。
1.1 更新yum组件
yum install -y python-setuptoolsyum install -y gcc gcc-c++ libffi-devel python-devel python-pip python-wheel openssl-devel cyrus-sasl-devel openldap-devel
1.2 安装 setuptools和pip
pip install --upgrade setuptools pip -i http://mirrors.aliyun.com/pypi/simple/
- 报错

- 需要配置默认镜像源创建或修改配置文件
linux的文件在~/.pip/pip.conf,
windows在%HOMEPATH%\pip\pip.ini
mkdir /root/.pipvim /root/.pip/pip.conf#>>>[global]index-url=http://mirrors.aliyun.com/pypi/simple/[install]trusted-host=mirrors.aliyun.com#<<<
1.3 安装superset
pip install apache-superset -i http://mirrors.aliyun.com/pypi/simple/
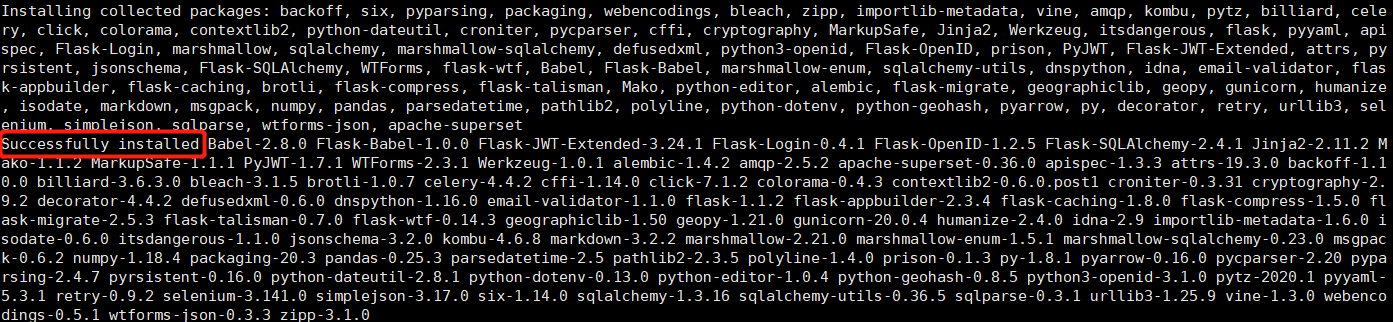
1.4 初始化superset数据库
superset db upgrade
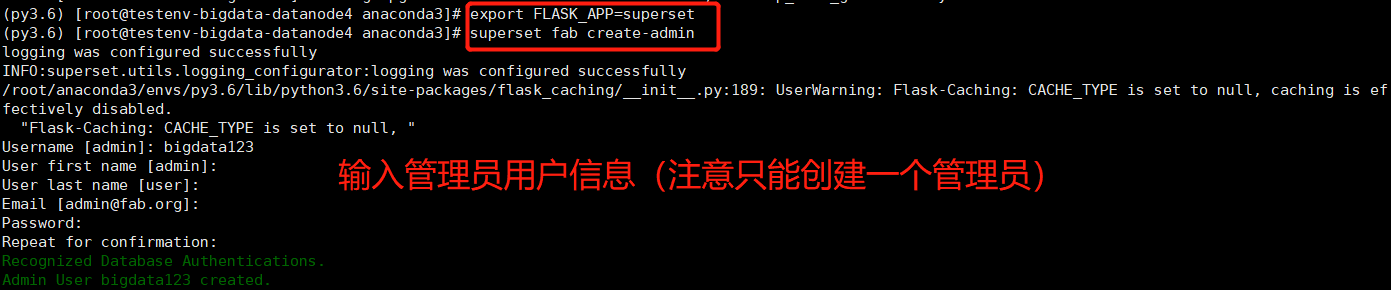
1.5 创建管理员用户
export FLASK_APP=supersetsuperset fab create-admin
1.6 初始化
superset init
1.7 安装gunicorn
gunicorn 是一个Python WEB服务,可以理解为Tomcat
pip install gunicorn -i http://mirrors.aliyun.com/pypi/simple/
1.8 启动停止
- 启动(注意python3.6)
gunicorn -w 5 --timeout 120 -b 10.28.13.85:8888 "superset.app:create_app()" --daemon
gunicorn 是一个Python WEB服务,可以理解为Tomcat
-w WORKERS:指定线程数
--timeout:worker进程超时时间,超过会自动重启
-b BIND:绑定Superset访问地址
--daemon:后台运行
- 停止
ps -ef | awk '/gunicorn/ && !/awk/{print $2}' | xargs kill -9
2 对接数据源
http://superset.apache.org/installation.html#database-dependencies
从如上文档查看对接相关数据源
2.1 对接mysql
停止superset
conda install mysqlclientpip install mysqlclient -i http://mirrors.aliyun.com/pypi/simple/
启动superset
3 使用demo
3.1 添加数据源
- 添加数据库
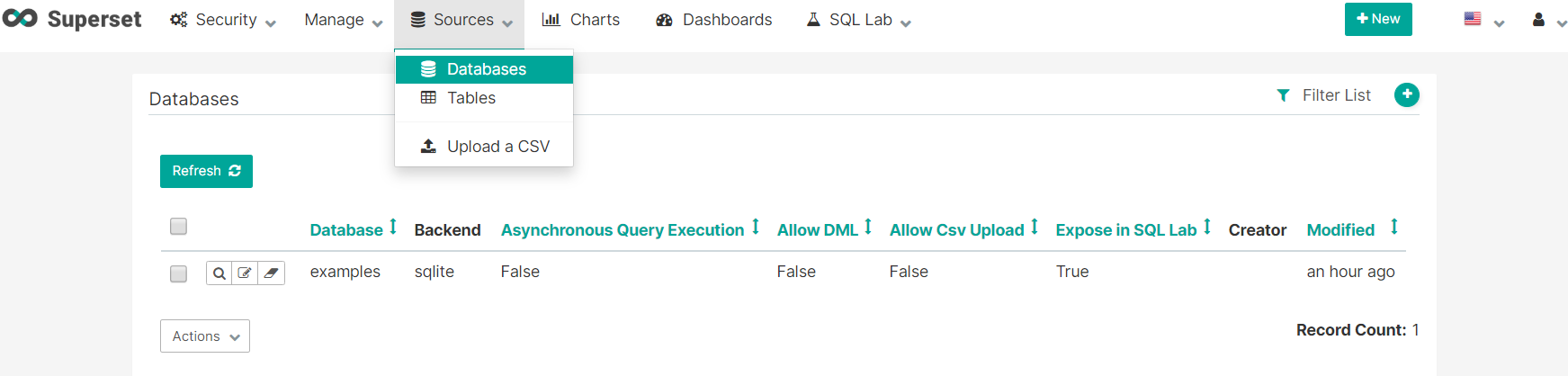

上图为mysql例子,Database为Superbase取的别名。URI写法--> mysql://账号:密码@IP/数据库名称。
- 添加表
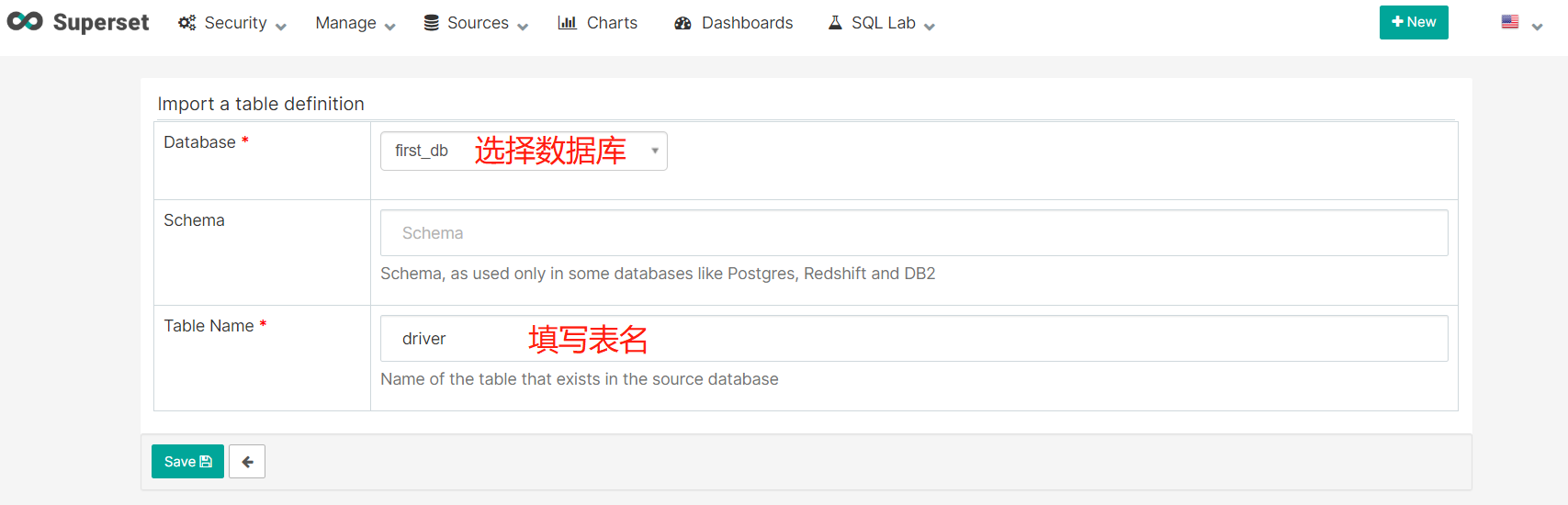
3.2 制作仪表盘
- 创建仪表盘


- 创建图
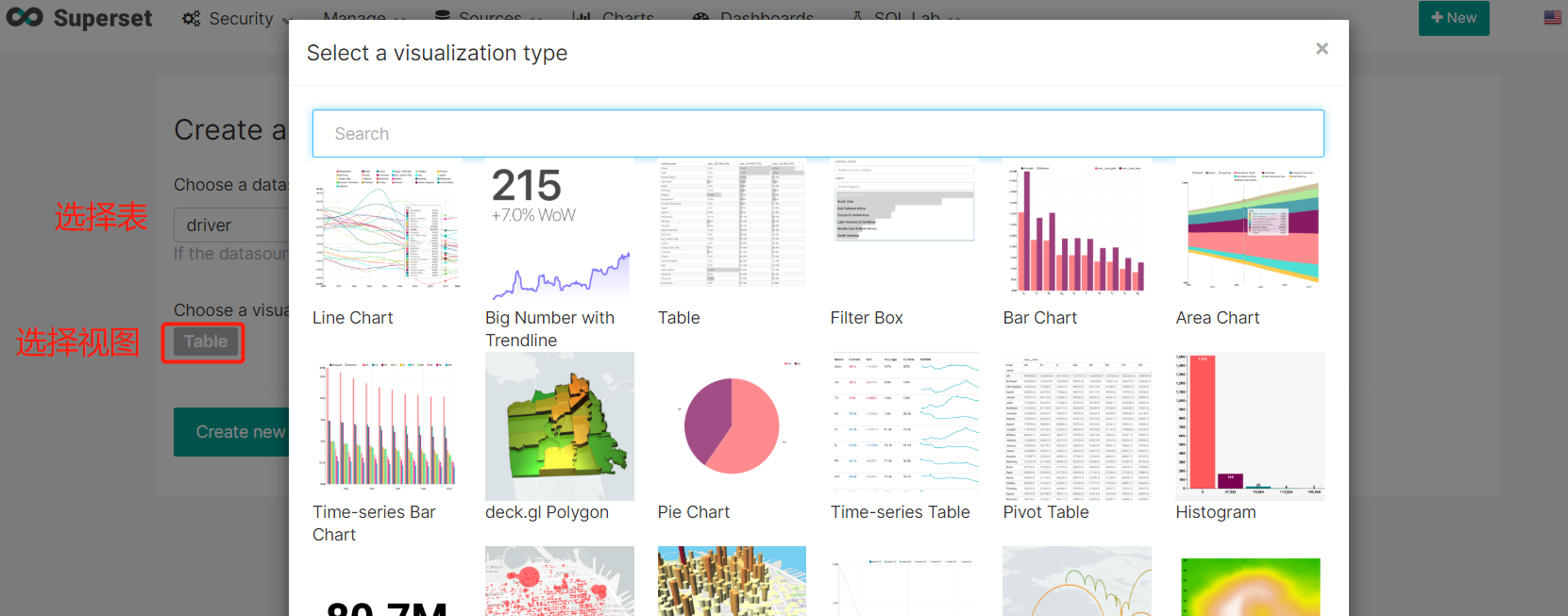
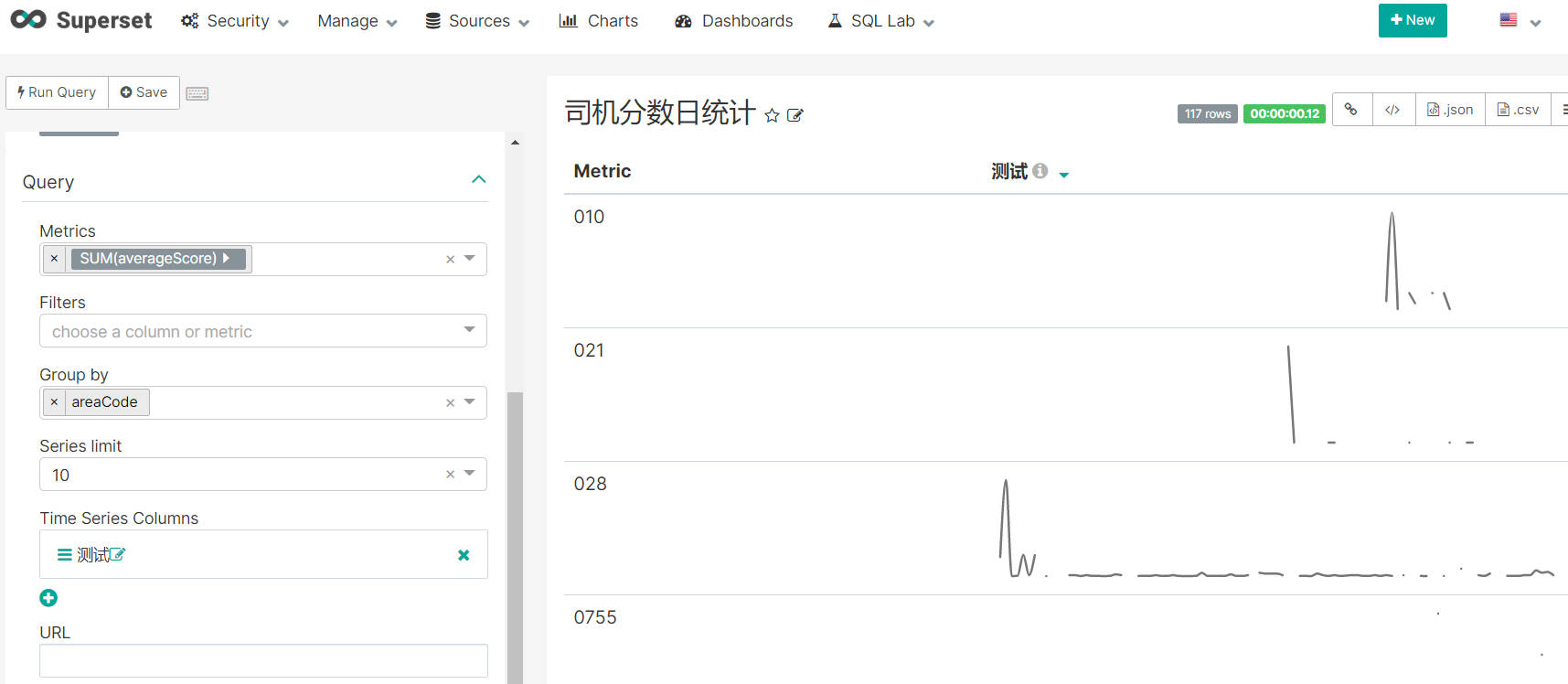
测试数据有点喽,大家将就看了哈

仪表盘的设计,总体来说很简单了,是在不会用,可以点国旗切换文字来玩。
环境篇:Superset的更多相关文章
- 篇5 python自动化测试应用-Selenium环境篇
篇5 python自动化测试应用-Selenium环境篇 --lamecho 1.1概要 大家好!我是lamecho(辣么丑),从本篇开始我将开始 ...
- SpringBoot系列之profles配置多环境(篇二)
SpringBoot系列之profles配置多环境(篇二) 继续上篇博客SpringBoot系列之profles配置多环境(篇一)之后,继续写一篇博客进行补充 写Spring项目时,在测试环境是一套数 ...
- 环境篇:Docker
环境篇:Docker www.docker.com Docker 是什么? Docker 是一个开源的应用容器引擎,基于Go语言并遵从Apache协议的开源,让开发者可以打包他们的应用以及依赖包到一个 ...
- 环境篇:Virtualbox+Vagrant安装Centos7
环境篇:Virtualbox+Vagrant安装Centos7 1 安装Vagrant Vagrant下载地址:https://www.vagrantup.com/ Vagrant百度网盘:https ...
- 环境篇:VMware Workstation安装Centos7
环境篇:VMware Workstation安装Centos7 1 VMware Workstation安装 CentOS下载地址:http://isoredirect.centos.org/cent ...
- 环境篇:Atlas2.0.0兼容CDH6.2.0部署
环境篇:Atlas2.0.0兼容CDH6.2.0部署 Atlas 是什么? Atlas是一组可扩展和可扩展的核心基础治理服务,使企业能够有效地满足Hadoop中的合规性要求,并允许与整个企业数据生态系 ...
- 环境篇:Kylin3.0.1集成CDH6.2.0
环境篇:Kylin3.0.1集成CDH6.2.0 Kylin是什么? Apache Kylin™是一个开源的.分布式的分析型数据仓库,提供Hadoop/Spark 之上的 SQL 查询接口及多维分析( ...
- 环境篇:Zeppelin
环境篇:Zeppelin Zeppelin 是什么 Apache Zeppelin 是一个让交互式数据分析变得可行的基于网页的开源框架.Zeppelin提供了数据分析.数据可视化等功能. Zeppel ...
- 环境篇:CM+CDH6.3.2环境搭建(全网最全)
环境篇:CM+CDH6.3.2环境搭建(全网最全) 一 环境准备 1.1 三台虚拟机准备 Master( 32g内存 + 100g硬盘 + 4cpu + 每个cpu2核) 2台Slave( 12g内存 ...
随机推荐
- 基于my-DAQ的温室迷你温室设计
这是一个小项目,采用NI的my-DAQ做数据采集,需要采集的数据有温度(LM35),气体(MQ2),需要控制的设备有风扇.加热棒,另外还有光照亮度调节. 一.数据采集 1.LM35 LM35是模拟输出 ...
- Delphi 文件操作(4)Reset
procedure Reset(var F [: File; RecSize: Word ] ); { 作用: 对于文本文件,Reset过程将以只读方式打开文件,对于类型文件和无类型文件, ...
- RxHttp ,比Retrofit 更优雅的协程体验
1.前言 Hello,各位小伙伴,又见面了,回首过去,RxHttp 就要迎来一周年生日了(19年4月推出),这一年,走过来真心....真心不容易,代码维护.写文章.写文档等等,经常都是干到零点之后,也 ...
- stand up meeting 12-11
今天因组员时间问题,并没有集中在一起开会,但士杰当面和天赋同学进行了沟通,在lync与国庆进行了沟通. 天赋与重阳再次进行了了沟通,确定了“单词挑战”与“背单词”这两个模块集成的难度,决定先不进行集成 ...
- 实验一 熟悉IDLE和在线编程平台
实验目的 1.掌握python IDLE集成开发环境的安装与使用 2.熟悉在线编程平台 3.掌握基本的python程序编写.编译与运行程序的方法 实验内容 1.按照实验指导安装IDLE,尝试交互式运行 ...
- mongodb权限篇
1. 权限详解 内建角色: 数据库用户角色: read.readWrite: 数据库管理角色: dbAdmin.dbOwner.userAdmin: 集群管理角色: clusterAdmin.clus ...
- MVC-路由解析
MVC程序入口 Global.asax.cs 执行Application_Start 方法 *默认路由 *静态路由,访问链接只需要域名加路由url固定值就行了 *替换控制器,或方法名, *正则路由 方 ...
- Spring Boot 自定义kafka 消费者配置 ContainerFactory最佳实践
Spring Boot 自定义kafka 消费者配置 ContainerFactory最佳实践 本篇博文主要提供一个在 SpringBoot 中自定义 kafka配置的实践,想象这样一个场景:你的系统 ...
- [机器学习实战-Logistic回归]使用Logistic回归预测各种实例
目录 本实验代码已经传到gitee上,请点击查收! 一.实验目的 二.实验内容与设计思想 实验内容 设计思想 三.实验使用环境 四.实验步骤和调试过程 4.1 基于Logistic回归和Sigmoid ...
- Qt 用户通过对话框选择文件
void class::on_pushButton_clicked() { fileFullPath = QFileDialog::getOpenFileName(this, tr("Sel ...