Django路由层与视图层
表与表之间建关系
图书管理系统为例
书籍表
出版社表
作者表

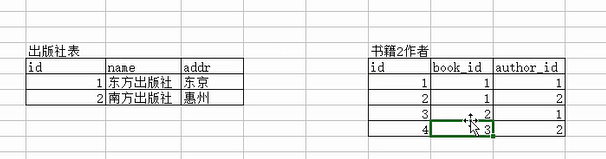
三个表之间的关系:
考虑表之间的关系:换位思考
1、书籍和出版社是一对多,外键字段建立在书籍表中
2、书籍和作者是多对多, 需要建立第三方表 记录多对多的关系
Django orm中表与表之间的关系
一对多:ForeignKey(to="publish")
一对一:OneToOneField(to="AuthorDetail")
对对多:ManyToManyField(to="Author")
注意:
前面两个关键字会自动再字段后面加_id
最后一个关键字 并不会产生实际字段 只是告诉django orm自动创建第三张表
在Django中建立表的关系:
创建Django项目的注意事项:
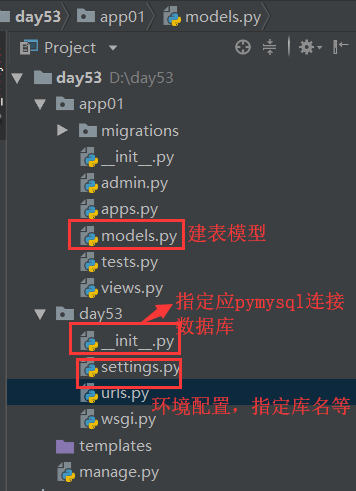
1、settings中的匹配修改
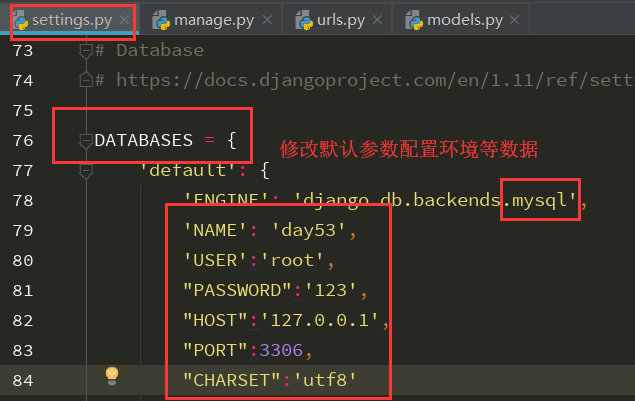
2、在__init__.py文件中指定用pymysql连接数据库

3、在Molder.py中创建表模型
from django.db import models # Create your models here.
class Book(models.Model):
# id自动创建 可以不写
title = models.CharField(max_length=64)
# 共8位 小数部分占两位
price = models.DecimalField(max_digits=8,decimal_places=2) # 书籍和出版社是一对多的外键关系
publish = models.ForeignKey(to='Publish')
# to表示的就是跟哪张表是一对多的关系 默认都是跟表的主键字段建立关系
"""
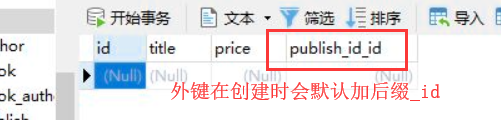
只要是ForeignKey的字段 django orm在创建表的时候 会自动在一对多的字段名之后加_id
如果你自己加了 不管 还会继续往后加
"""
# publish = models.ForeignKey(to=Publish)# to后面也可以直接写表名 但是必须保证表名在上面
# 书籍和作者是多对多的关系
authors = models.ManyToManyField(to='Author')
# 不会在表中生成authors字段 该字段是一个虚拟字段 仅仅是用来告诉django
# orm自动帮你创建书籍和作者的第三张关系表 class Publish(models.Model):
name = models.CharField(max_length=32)
addr = models.CharField(max_length=32) class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
# 作者与作者详情 是一对一的外键关系
author_detail = models.OneToOneField(to='AuthorDetail',null=True)
"""
也会自动再字段名后面加_id
"""
class AuthorDetail(models.Model):
phone = models.BigIntegerField()
addr = models.CharField(max_length=32)
4、创建外键字段时默认后缀添加_id
需要注意的点:
django orm中表与表之间建关系
一对多 ForeignKey(to='Publish') 一对一 OneToOneField(to='AuthorDetail') 多对多 ManyToManyField(to='Author') 注意:
前面两个关键字会自动再字段后面加_id
最后一个关键字 并不会产生实际字段 只是告诉django orm自动创建第三张表
创建的表如下:

Django请求生命周期
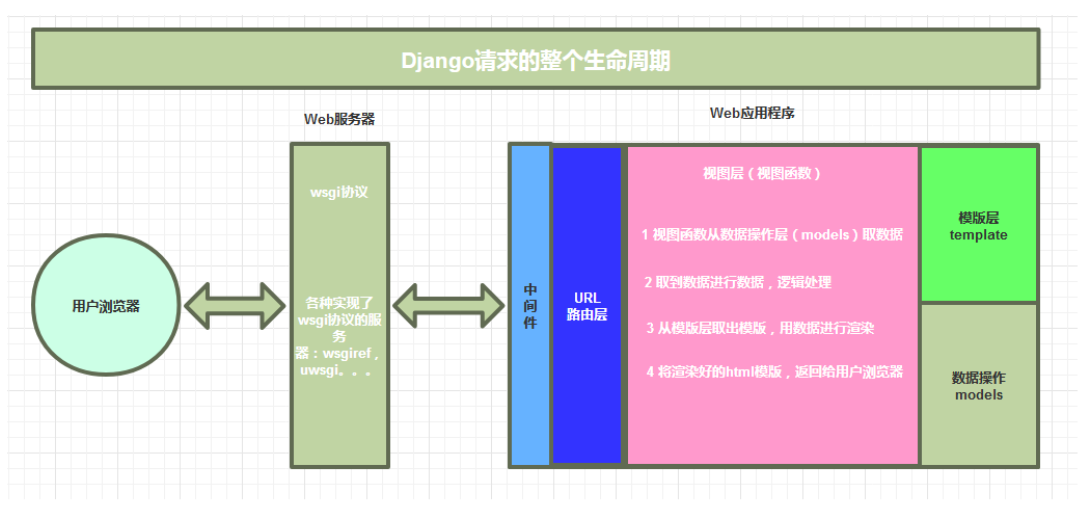

按照上述流程图开始按步骤详细学习Django框架的各个模块部分
Django路由层
URL配置(URLconf)就像Django 所支撑网站的目录。它的本质是URL与要为该URL调用的视图函数之间的映射表。
urlconf配置
基本格式:
具体写法

在views.pyz中绑定请求的数据
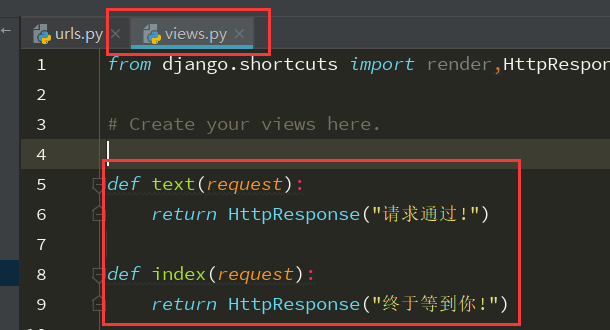
连接url
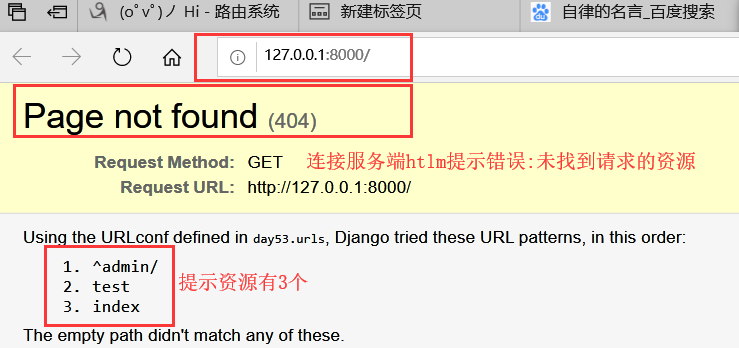
再次输入指定的url后缀名访问
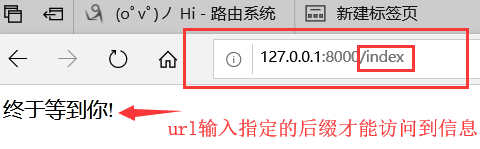
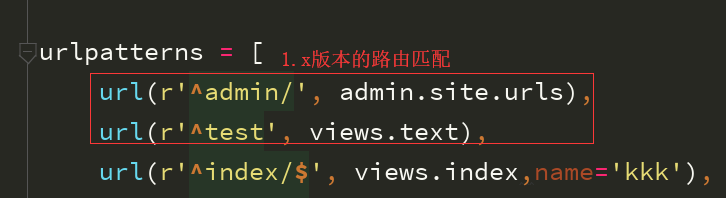
url()方法,第一个参数,其实是一个正则表达式,一旦前面的正则匹配到了内容,
就不会再往下继续匹配,而是直接执行相应的视图函数
1、当输入testindex时返回的还是text请求返回的数据?
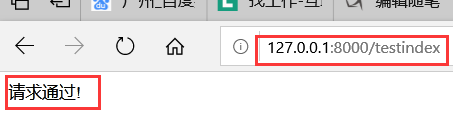
分析:当url输入后缀“testindex”访问时,正则表达式默认从上往下匹配找到“text”时就不会往下继续匹配了;
“text”和“textindex” 有相同的“text”部分

正是由于上面的特性,当你的项目特别庞大的时候 ,url的前后顺序也是你需要你考虑
极有可能会出现url错乱的情况。
django在路由的匹配的时候 当你在浏览器中没有敲最后的斜杠
路由的匹配机制
django会先拿着你没有敲斜杠的结果取匹配 如果都没有匹配上,会让浏览器在末尾加斜杠再发一次请求,再匹配一次 如果还匹配不上才会报错
如果你想取消该机制 不想做二次匹配可以在settings配置文件中 指定
APPEND_SLASH = False # 该参数默认是True
路由中:有名和无名分组
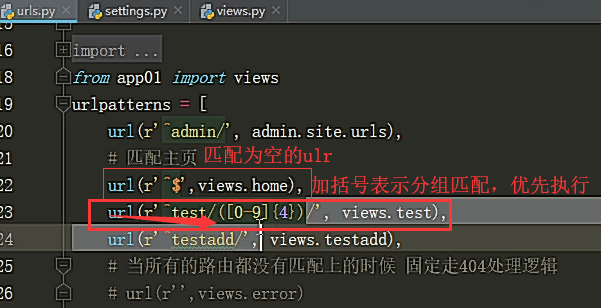
无名分组:
url(r'^test/([0-9]{4})/', views.test)
路由匹配的时候,会将括号内正则表达式匹配到的内容,当作位置参数传递给视图函数
视图函数传参:test(request,year=2019)
有名分组:
url(r'^test/(?P<year>\d+)/', views.test)
路由匹配的时候,会将括号内正则表达式匹配到的内容 当做关键字参数传递给视图函数
传参形式:test(request,year=2019)
无名有名不能混合使用
url(r'^test/(\d+)/(?P<year>\d+)/', views.test),
但是用一种分组下 可以使用多个
# 无名分组支持多个
# url(r'^test/(\d+)/(\d+)/', views.test),
# 有名分组支持多个
# url(r'^test/(?P<year>\d+)/(?P<xx>\d+)/', views.test),
反向解析
本质:其实就是给你返回一个能够返回对应url的地址
简单的理解就是通过name=‘KKK’,动态获取url地址 ,在 前端书写ref="kkk",即可,即使url中的index有变化,也能读取解析到。

1、先给url和视图函数对应的关系起别名
url(r'^index/$',views.index,name='kkk')
2、反向解析
后端反向解析:后端可以在任意位置通过reverse反向解析出对应的rul
HttpResponse:返回字符串
render:返回html页面,并且能够给页面传值
redirect:重定向(如绑定跳转页面 herf:"www.baidu.com")
from django.shortcuts import render,HttpResponse,redirect,reverse
reverse('kkk')

前端反向解析
{% url 'kkk' %}

无名分组反向解析
带有正则表达式的url
url(r'^index/(\d+)/$',views.index,name='kkk')
1、后端反向解析
reverse('kkk',args=(1,))
# 后面的数字通常都是数据的ID值
2、前端反向解析
{% url 'kkk' 1%} # 后面的数字通常都是数据的id值
传的参数一般是id

有名分组反向解析
同无名分组反向解析一样的用法
url(r'^index/(?p<year>\d+)/$,views.index,name='kkk')
后端反向解析:导入模块重定向
print(reverse('kkk',args=(1,))) # 推荐你使用上面这种 减少你的脑容量消耗
print(reverse('kkk',kwargs={'year':1}))
前端反向解析
<a href="{% url 'kkk' 1 %}">1</a> # 推荐你使用上面这种 减少你的脑容量消耗
<a href="{% url 'kkk' year=1 %}">1</a>
注意:在同一个应用下 别名千万不能重复!!!
Django路由分发
关键字:include
当你的Django项目特别庞大的时候,路由与视图函数对应关系特别多,那么这种情况下总路由urls.py代码过于冗余,不易维护修改
在Django中每一个应用都有自己的urls.py,static文件夹,templates文件夹(***);
基于这个条件,可以实现多人分组开发,等多人开发完成后,只需要出创建一个空的Django项目,然后把多人开发好的app全部注册进来,
在总路由实现一个路由分发,而不再做路由匹配(来了之后,只分发到相对应的app中)
当你的应用下的视图函数特别特别多的时候 你可以建一个views文件夹 里面根据功能的细分再建不同的py文件(******)
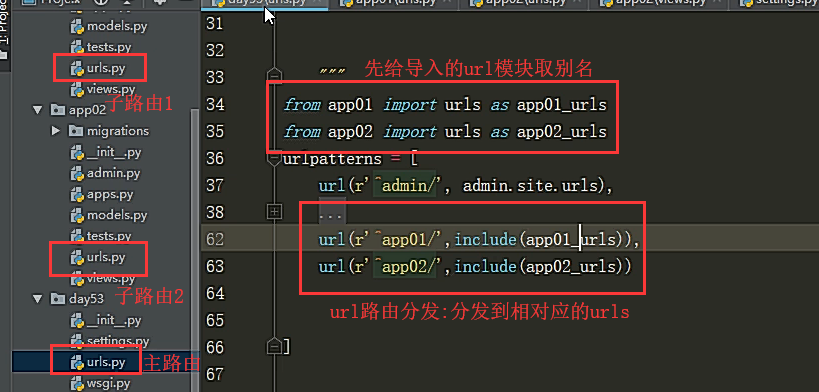
总路由中,一级路由的后面千万不加$符号,不然不能进行分发路由的操作。表示结束匹配 命名空间模式
即使不同的APP使用相同的URL名称,URL的命名空间模式也可以让你唯一反转命名的URL。
多个app起了相同的别名 这个时候用反向解析 并不会自动识别应用前缀
如果想避免这种问题的发生
方式1:
总路由
url(r'^app01/',include('app01.urls',namespace='app01'))
url(r'^app02/',include('app02.urls',namespace='app02'))
后端解析的时候
reverse('app01:index')
reverse('app02:index')
前端解析的时候
{% url 'app01:index' %}
{% url 'app02:index' %}
方式2:
起别名的时候不要冲突即可,一般情况下在起别名的时候通常建议以应用名作为前缀
name = 'app01_index'
name = 'app02_index'
伪静态
静态网页:数据是写死的,万年不变

例如:博客园的url网页,后缀名为html,给人的感觉数据是写死的,但是在修改提交刷新后,数据是在改变的。
伪静态网页的设计是为了增加百度等搜索引擎seo查询力度
Search Engine Optimization(搜索引擎优化),seo也就是搜索引擎优化。
静态网页内容先暂时收录,缓存,以便于下次访问同样请求时直接返回
网站优化相关 通过伪静态确实可以提高你的网站被查询出来的概率
但是再怎么优化也抵不过RMB玩家
虚拟环境
一般情况下,我们会给每一个项目,配备该项目所需要的模块,不需要的一概不装
虚拟环境,就类似于为每个项目量身定做的解释器环境
如何创建虚拟环境
每创建一个虚拟环境,就类似于你又下载了一个全新的python解释器;
比较耗费资源,且不能保存数据在本地,删除后就全部丢失
创建项目后:

虚拟环境创建的项目跟下载了纯净的pycharm解释器一样,都是最初的环境配置

Djnago版本的区别
主要讨论:Django1.x跟Django2.x版本的区别
路由层:
1.x用的是url,正则表达式
2.x用的是path
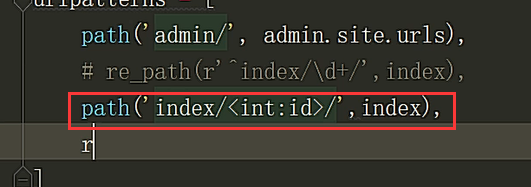
2.x中的path第一个参数不再是正则表达式,而是写什么就匹配什么,属于精准匹配

当使用2.x不习惯的时候,2.x还有一个叫re_path;
2.x中的re_path相当于1.x中的url

虽然2.X中path不支持正则表达式, 但是它提供了五种默认的转换器
1.0版本的url和2.0版本的re_path分组出来的数据都是字符串类型
默认有五个转换器.
str,匹配除了路径分隔符(/)之外的非空字符串,这是默认的形式
int,匹配正整数,包含0。
slug,匹配字母、数字以及横杠、下划线组成的字符串。
uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。
path,匹配任何非空字符串,包含了路径分隔符(/)(不能用?)
如下:path('index/<int:id>/',index) # 会将id匹配到的内容自动转换成整型
还支持自定义转换器:
class FourDigitYearConverter: #先定义一个类,人书写正则匹配,起别名转换
regex = '[0-9]{4}'
def to_python(self, value):
return int(value)
def to_url(self, value):
return '%04d' % value 占四位,不够用0填满,超了则就按超了的位数来!
register_converter(FourDigitYearConverter, 'yyyy') urlpatterns = [
path('articles/2003/', views.special_case_2003),
path('articles/<yyyy:year>/', views.year_archive),
...
]
Django视图层
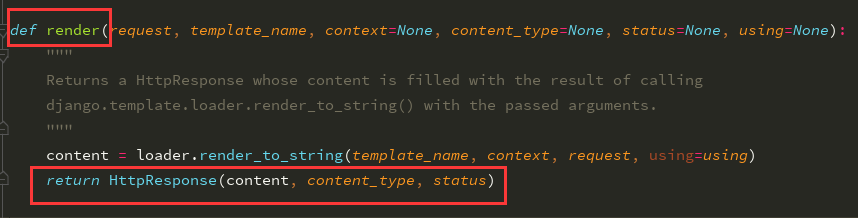
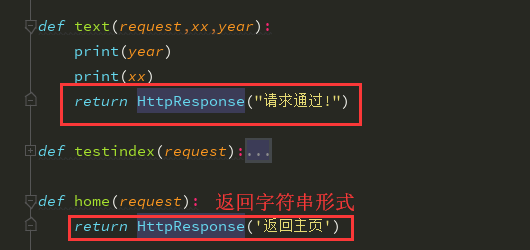
小白必会的三板斧:HttpResponse(返回字符串),render(返回html页面),redirect(重定向)
概念:django视图函数必须要给前端返回一个HttpResponse对象(一个类产生的对象)

点击render查看源码:
点击HttpResponse源码:

所以证明在书写views视图函数时,必须要返回一个HttpResponse对象
如果不书写会报错:

前后端分离:
数据的传输问题
前端一个人干(前端转成自定义对象)
前端语法对应关系:
JSON.stringify() >>> json.dumps()
JSON.parse() >>> json.loads()
后端另一个人干(python后端用字典)
只要涉及到数据交互,一般情况下都是用的json格式
后端只负责产生接口,前端调用该接口能拿到一个大字典
后端只需要写一个接口文档 里面描述字典的详细信息以及参数的传递
2、JsonReponse书写字典形式转换,传给前端html页面显示
from django.http import JsonResponse
def index(request):
data = {'name':'jason好帅哦 我好喜欢','password':123}
l = [1,2,3,4,5,6,7,8]
# res = json.dumps(data,ensure_ascii=False)
# return HttpResponse(res)
# return JsonResponse(data,json_dumps_params={'ensure_ascii':False})
return JsonResponse(l,safe=False)
# 如果返回的不是字典 只需要修改safe参数为false即可
前端网页结果展示:

上传文件
from表单上传文件需要注意的事项
1.enctype 需要有默认的urlencoded 变成formdata
2.method需要由默认的get变成post请求ht
(目前还需要考虑的是 提交post请求需要将配置文件中的csrf中间件注释)
如果form表单上传文件 后端需要在request.FILES获取文件数据 而不再是POST里面
HTML文件:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script src="https://cdn.bootcss.com/jquery/3.4.1/jquery.min.js"></script>
</head>
<body>
<form action="" method="post" enctype="multipart/form-data">
<input type="file" name="myfile">
<input type="submit">
</form>
</body>
</html>
页面下效果显示:
对应的views.py文件:
def upload_file(request):
if request.method == 'POST':
# print(request.POST)
file_obj=request.FILES.get('myfile')
print(file_obj.name)
with open(file_obj.name,'wb') as f:
for line in file_obj.chunks(): # file_obj也是一个可迭代对象
f.write(line)
return HttpResponse("收到下载信息!")
return render(request,'file.html') 获取的信息返回给html
Django中request(请求)常用的有
request.method
request.GET #获取url?后面的数据
request.POST #获取用户请求的一大推键值对
request.FILES
request.path # 只回去url后缀 不获取?后面的参数
request.get_full_path() # 后缀和参数全部获取
request.body # 原生的二进制数据
request.path # 只拿url
request.get_full_path # rul+?后面的参数
概念:
"""
RBAC (role based access control)
基于角色的权限管理 当你在做权限管理的时候 需要用到
在web领域权限就是一个个的url
简单判断用户是否有权限访问某个url思路
获取用户想要访问的url
与数据库中该用户可以访问的url进行对比 """
Django路由层与视图层的更多相关文章
- Django路由层与视图层、pycharm虚拟环境
一. Django路由层 路由层即对应项目文件下的urls.py文件.实际上每个APP中也可以有自己的urls.py路由层.templates文件夹及static文件夹.Django支持这么做,也为实 ...
- Django 路由层与视图层
1.路由层 1.1无名分组 1.2 有名分组 1.3 反向解析 1.4 路由分发 1.5 名称空间 2.伪静态网页 3.虚拟环境 4.视图层 1.1 JsonResponse 1.2 FBV与CBV ...
- Django路由层、视图层
一.路由匹配: 第一个参数是正则表达式,匹配规则按照从上往下一次匹配,匹配到一个后立即停止 urlpatterns = [ url(r'^admin/', admin.site.urls), url( ...
- Django的路由层和视图层
一丶Django 的路由层(URLconf) URL配置(URLconf)就像Django 所支撑网站的目录.它的本质是URL与要为该URL调用的视图函数之间的映射表:你就是以这种方式告诉Django ...
- 052.Python前端Django框架路由层和视图层
一.路由层(URLconf) 1.1 路由层简单配置 URL配置(URLconf)就像Django 所支撑网站的目录.它的本质是URL与要为该URL调用的视图函数之间的映射表:你就是以这种方式告诉Dj ...
- 关于Django路由层简单笔记
Django—路由层 URL配置(URLconf)就像Django 所支撑网站的目录.它的本质是URL与要为该URL调用的视图函数之间的映射表:你就是以这种方式告诉Django,对于客户端发来的某个U ...
- django 路由层 伪静态网页 虚拟环境 视图层
路由层 无名分组 有名分组 反向解析 路由分发 名称空间 伪静态网页 虚拟环境 视图层 JsonResponse FBV与CBV 文件上传 项目urls.py下面 from app01 import ...
- $Django 路由层(有,无名分组、反向解析、总路由分发、名称空间、伪静态)
1 简单配置 -第一个参数是正则表达式(如果要精准匹配:'^publish/$') -第二个参数是视图函数(不要加括号) -url(r'^admin/', admin.site.urls), 注: ...
- django 实战篇之视图层
视图层(views.py) django必会三板斧 HttpResponse >>> 返回字符串 render >>> 支持模板语法,渲染页面,并返回给前端 red ...
随机推荐
- Django中使用ORM
一.ORM概念 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术. 简单的说,ORM是通过使用描述对象和数 ...
- Codeforces 1296E1 - String Coloring (easy version)
题目大意: 给定一段长度为n的字符串s 你需要给每个字符进行涂色,然后相邻的不同色的字符可以进行交换 需要保证涂色后能通过相邻交换把这个字符串按照字典序排序(a~z) 你只有两种颜色可以用来涂 问是否 ...
- POJ 1547:Clay Bully
Clay Bully Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 8349 Accepted: 4711 Descri ...
- Java编程知识点梳理
1. elementAt() temp.elementAt(0) 返回temp这个vector里面存放的第一个元素--->也是一个vector类型. 2. 字符串空格分割 String [] ...
- Java 使用控制台操作实现数据库的增删改查
使用控制台进行数据库增删改查操作,首先创建一个Java Bean类,实现基础数据的构造,Get,Set方法的实现,减少代码重复性. 基本属性为 学生学号 Id, 学生姓名 Name,学生性别 Sex, ...
- input只允许输入数字,并且小数点后保留4位
<input type="text" value="" name="should_send_num" id="should_ ...
- php对象:get_object_vars(), get_parent_class(),is_subclass_of(),interface_exists()
get_object_vars():获得对象的属性,以关联数组形式返回 get_parent_class():获得对象的父类 is_subclass_of():判断对象是否某类(参数2)的子类实例出的 ...
- MySQL--基础SQL--DML
1.插入记录 INSERT INTO tablename (fields1, fields2, ..., fieldsn) VALUES (value1, value2, ..., valuen) 例 ...
- Java集合(一)——Collection
集合概述 集合(Collections)是存储对象的容器.方便对多个对象的操作.存储对象,集合的作用就在这时显现了. 集合的出现就是为了持有对象.集合中可以存储任意类型的对象, 而且长度可变.在程序中 ...
- linux 解压命令总结
常用Linux 命令: [转自]https://www.jianshu.com/p/ca41f32420d6 解压缩 .tar 解包:tar xvf FileName.tar 打包:tar cvf F ...