吴裕雄--天生自然 人工智能机器学习实战代码:LASSO回归
import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets, linear_model
from sklearn.model_selection import train_test_split def load_data():
diabetes = datasets.load_diabetes()
return train_test_split(diabetes.data,diabetes.target,test_size=0.25,random_state=0) #Lasso回归
def test_Lasso(*data):
X_train,X_test,y_train,y_test=data
regr = linear_model.Lasso()
regr.fit(X_train, y_train)
print('Coefficients:%s, intercept %.2f'%(regr.coef_,regr.intercept_))
print("Residual sum of squares: %.2f"% np.mean((regr.predict(X_test) - y_test) ** 2))
print('Score: %.2f' % regr.score(X_test, y_test)) # 产生用于回归问题的数据集
X_train,X_test,y_train,y_test=load_data()
# 调用 test_Lasso
test_Lasso(X_train,X_test,y_train,y_test) def test_Lasso_alpha(*data):
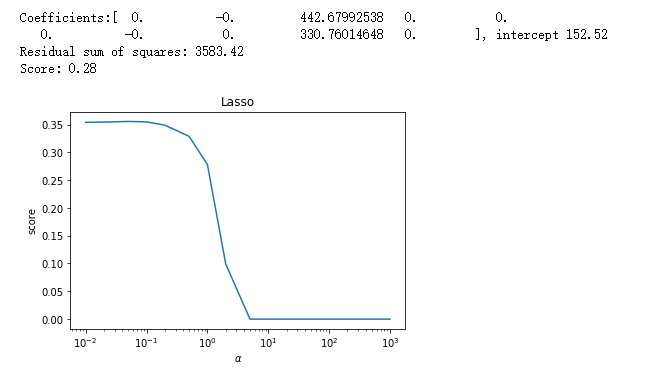
X_train,X_test,y_train,y_test=data
alphas=[0.01,0.02,0.05,0.1,0.2,0.5,1,2,5,10,20,50,100,200,500,1000]
scores=[]
for i,alpha in enumerate(alphas):
regr = linear_model.Lasso(alpha=alpha)
regr.fit(X_train, y_train)
scores.append(regr.score(X_test, y_test))
## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(alphas,scores)
ax.set_xlabel(r"$\alpha$")
ax.set_ylabel(r"score")
ax.set_xscale('log')
ax.set_title("Lasso")
plt.show() # 调用 test_Lasso_alpha
test_Lasso_alpha(X_train,X_test,y_train,y_test)
吴裕雄--天生自然 人工智能机器学习实战代码:LASSO回归的更多相关文章
- 吴裕雄--天生自然 人工智能机器学习实战代码:线性判断分析LINEARDISCRIMINANTANALYSIS
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄--天生自然 人工智能机器学习实战代码:ELASTICNET回归
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄--天生自然python机器学习实战:K-NN算法约会网站好友喜好预测以及手写数字预测分类实验
实验设备与软件环境 硬件环境:内存ddr3 4G及以上的x86架构主机一部 系统环境:windows 软件环境:Anaconda2(64位),python3.5,jupyter 内核版本:window ...
- 吴裕雄--天生自然python机器学习:使用Logistic回归从疝气病症预测病马的死亡率
,除了部分指标主观和难以测量外,该数据还存在一个问题,数据集中有 30%的值是缺失的.下面将首先介绍如何处理数据集中的数据缺失问题,然 后 再 利 用 Logistic回 归 和随机梯度上升算法来预测 ...
- 吴裕雄--天生自然python机器学习:决策树算法
我们经常使用决策树处理分类问题’近来的调查表明决策树也是最经常使用的数据挖掘算法. 它之所以如此流行,一个很重要的原因就是使用者基本上不用了解机器学习算法,也不用深究它 是如何工作的. K-近邻算法可 ...
- 吴裕雄--天生自然python机器学习:使用K-近邻算法改进约会网站的配对效果
在约会网站使用K-近邻算法 准备数据:从文本文件中解析数据 海伦收集约会数据巳经有了一段时间,她把这些数据存放在文本文件(1如1^及抓 比加 中,每 个样本数据占据一行,总共有1000行.海伦的样本主 ...
- 吴裕雄--天生自然python机器学习:支持向量机SVM
基于最大间隔分隔数据 import matplotlib import matplotlib.pyplot as plt from numpy import * xcord0 = [] ycord0 ...
- 吴裕雄--天生自然python机器学习:朴素贝叶斯算法
分类器有时会产生错误结果,这时可以要求分类器给出一个最优的类别猜测结果,同 时给出这个猜测的概率估计值. 概率论是许多机器学习算法的基础 在计算 特征值取某个值的概率时涉及了一些概率知识,在那里我们先 ...
- 吴裕雄--天生自然python机器学习:机器学习简介
除却一些无关紧要的情况,人们很难直接从原始数据本身获得所需信息.例如 ,对于垃圾邮 件的检测,侦测一个单词是否存在并没有太大的作用,然而当某几个特定单词同时出现时,再辅 以考察邮件长度及其他因素,人们 ...
随机推荐
- 【MySQL优化】数据库结构优化
原则: 设计表结构,字段类型,最小化磁盘存储的空间,减少IO.数据库操作中最为耗时的操作就是 IO 处理,大部分数据库操作 90% 以上的时间都花在了 IO 读写上面.所以尽可能减少 IO 读写量,可 ...
- Maven--仓库的分类
对于 Maven 仓库来说,仓库只分为两类:本地仓库和远程仓库. 当 Maven 根据坐标寻找构件的时候,它首先会查看本地仓库,如果本地仓库存在此构件,则直接使用:如果本地仓库不存在此构件,或者需要查 ...
- 好看的UI组合,为以后自己写组件库做准备
1. 黑色格子背景 { color: rgb(255, 255, 255); text-shadow: 1px 1px 0 rgba(0,0,0,.3); rgb(62, 64, 74); backg ...
- iOS 中UITableView的深理解
例如下图:首先分析一下需求:1.根据模型的不同状态显示不同高度的cell,和cell的UI界面. 2.点击cell的取消按钮时,对应的cell首先要把取消按钮隐藏掉,然后改变cell的高度. 根据需求 ...
- LeetCode No.151,152,153
No.151 ReverseWords 翻转字符串里的单词 题目 给定一个字符串,逐个翻转字符串中的每个单词. 示例 输入: "the sky is blue" 输出: " ...
- [原]PInvoke导致栈破坏
原, 总结, 调试, 调试案例 项目中遇到一个诡异的问题,程序在升级到.net4.6.1后会崩溃,提示访问只读内存区.大概现象如下: debug版不崩溃,release版稳定崩溃. 只有x64位的程 ...
- 肯德基联手亚马逊Kindle试水咖啡主题店中店能成功吗?
互联网上始终有一个传说:kindle与泡面是绝配.因为用kindle压着泡面,泡出来的味道格外的好.当然,这只是一个调侃.毕竟很多人购买kindle的动力是为了摆脱其他电子设备的诱惑,想去好好去读书. ...
- CentOS7 安装配置笔记
CentOS7 安装配置笔记 1.通过镜像安装 CentOS7 ==============================* 使用 UltraISO 9.7 或者 rufus-3.5p 制作ISO的 ...
- 2018-10-09-Pser
title date tags layout Pser 2018-10-09 杂谈 post ### 踏雪无痕![踏雪无痕](http://da1sy.github.io/assets/images/ ...
- windows 环境下Maven私服搭建
使用Nexus.3.11在Windows环境上搭建1.下载nexus.3.11.zip包https://www.sonatype.com/download-oss-sonatype 下载下来之后,进行 ...