CKafka如何助力腾讯课堂实现百万消息稳定互动?
疫情期间,为了保障国内学子的正常学习进度,腾讯课堂积极响应国家“停工不停学”的号召,紧急上线疫情期间专用的“老师极速版”,使广大师生足不出户,即可快速便捷的完成线上开课。面对线上课堂百万量级的互动消息,如何保证消息的实时性和准确性无疑是一个技术挑战。那么如何解决问题呢?接下来,就和小编一起来看看腾讯云中间件CKafka如何为腾讯课堂百万级消息提供技术支撑。
两年前,腾讯在线教育部就在探索如何实现架构转型。在梳理过腾讯课堂初始技术架构的痛点后,规划出架构演进的三个重点方向:微服务、中间件、DevOps。尤其在消息中间件的选取上,从自研Hippo消息队列切换到云CKafka。这主要归于以下几点原因:
- 实现技术栈的统一,降低组件适配成本。
- 使用符合开源标准的组件,便于系统切换优秀的开源组件。
- CKafka具备高性能、高可用性和高可靠性的特点:免除复杂的参数配置,提供专业的性能调优;磁盘高可靠,即使服务器坏盘50%也不影响业务;多副本备份,更有多可用区容灾方案可选,零感知服务迁移。
- CKafka提供安全的数据保障:提供鉴权与授权机制、主子账号等功能,为企业数据做好安全防护。
在刚刚过去的2019年,腾讯在线教育部已全面实现了业务上云,不仅提升了团队研发效率,还实现了快速交付。同时,CKafka在消息流处理上的高性能特点得以实践验证。
而现在,疫情当前,面对全国千万师生同时在线的线上课堂,互动消息猛增至百万级别,无疑对在线教育平台的稳定性提出更高要求。为了保证线上课堂广大师生的稳定互动,CKafka作为腾讯课堂的底层消息支撑,在消息的实时性和可靠性上提供了更优化的技术方案。
腾讯课堂在线课程页面
一、CKafka在腾讯课堂的实践
Ckafka在腾讯课堂系统架构中的应用是非常典型的场景,即消息总线和业务解耦。使用了GB带宽、TB存储规格的实例。我们先来看一下CKafka作为消息总线在腾讯课堂的架构中所处的位置,如下图:
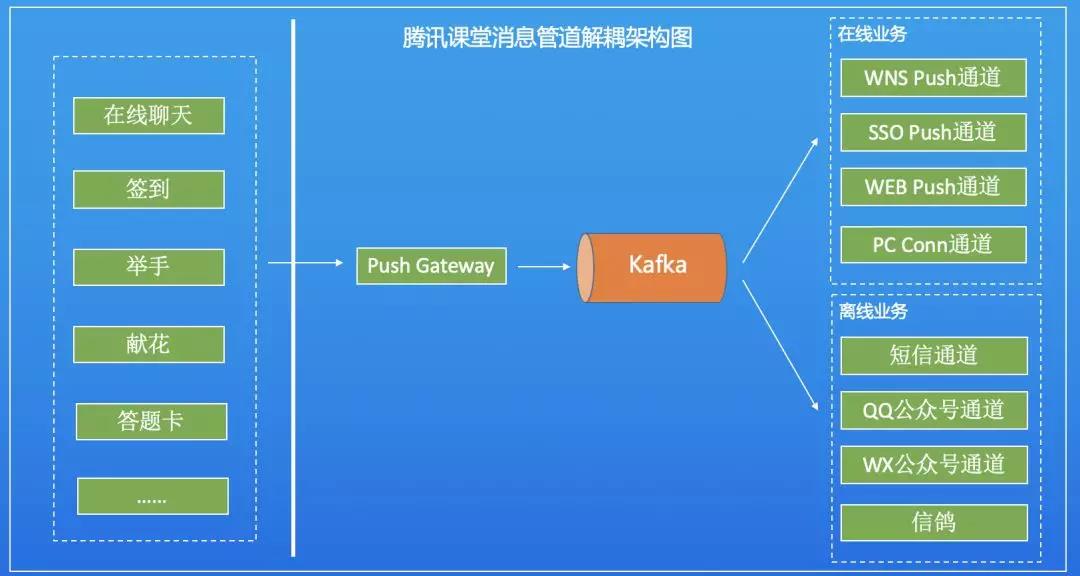
从架构图可知,CKafka处于消息管道的中心位置。同时接收多个消息源数据,等待下游组件的订阅消费。并利用其自身高分布式、高吞吐、高可靠的特性,实现流量削峰和业务解耦。
腾讯课堂中的聊天消息、签到、举手、献花、答题卡等功能都使用了该能力。在线课堂的业务场景不允许出现如消息延迟、数据丢失等情况,否则就会立刻被在线课堂的师生们感知业务的不稳定,造成不良的用户体验。
我们来假设一个场景:老师在课堂发布一个问题,学生们举手回答问题,如果老师发出的消息出现延时或丢失的情况,学生们就不能收到消息,无法及时给老师反馈问题答案,线上课堂的互动效果就会很差,严重影响课堂教学质量。如何避免上述问题呢?我们从CKafka保障消息的实时性和可靠性两方面进行阐述。
1. 消息的实时性
Apache Kafka架构上设计的底层数据读写和存储是以分区为最小单位进行的。首先来看一下Kafka Topic的生产消费模型。
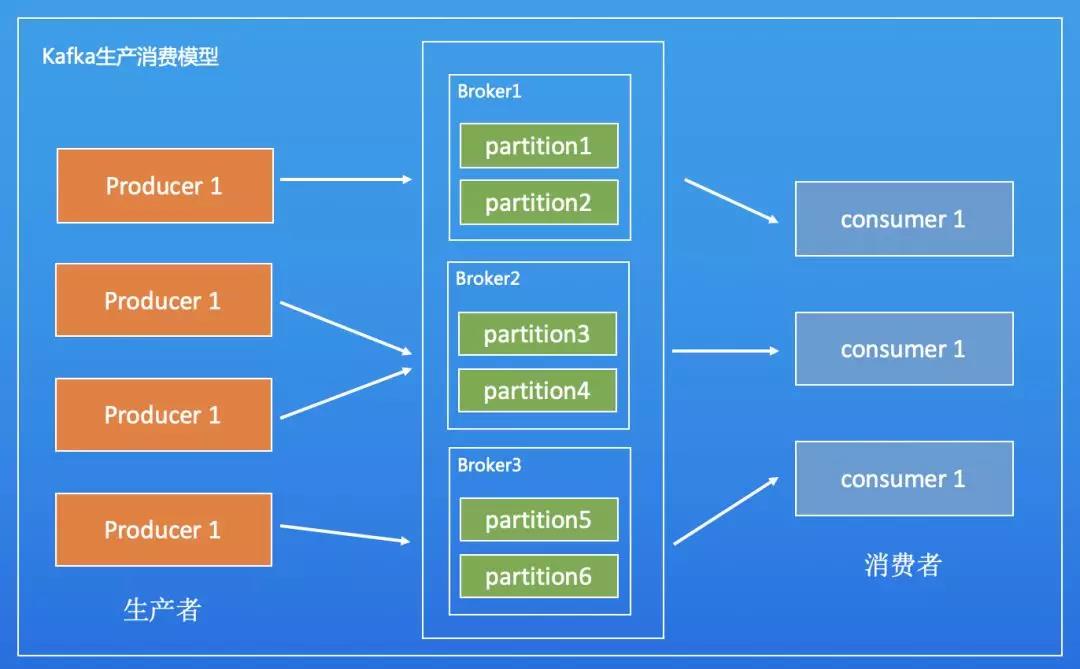
如上图所示,生产者将数据写入到分布在集群内不同节点的不同分区上,一个或多个消费者从多台Borker的分区上消费订阅数据。从这个模型可知,如果数据的读写都集中在单个分区上,则Topic的的所有压力都会集中在该分区上,从而落到单台Broker上面。
假设单台机器能承受的流量是300MB,则此时以腾讯教育的GB/s的流量规模,则会出现消息处理过慢,会导致消息延时。那怎么办呢?此时就应该提升分区的数量,提高数据处理的并行度,从而将整个topic的压力均分到多台机器上。这时就会有一个疑问,Topic需要多少分区合适呢?是不是越多的分区越好呢?
(1)影响分区数量的因素
从生产者的角度来看,数据向不同的分区写入是完全并行的;从消费者的角度来看,并发数完全取决于分区的数量(如果 consumer 数量大于 分区 数量,则必有 consumer 闲置)。因此选取合适的分区对于发挥 CKafka 实例的性能十分重要。
Topic的分区数量是由多种因素决定的,一般可以根据以下几个因素综合考虑:
- 生产者的峰值带宽
假设单机单partiton的生产消费吞吐各自最高为300,峰值生产带宽是900MB,则单纯生产至少需要3个Partiton。
- 消费者的峰值带宽
有人可能会觉得消费的峰值带宽应该等于生产的峰值带宽。这样是不对的。生产者只会生产一份数据,但是可以有N个消费者消费同一份数据,则此时消费带宽=N*生产带宽。另外如果是离线计算,可能会在某一时刻,消费历史所有数据,此时消费带宽可能会远远高于生产带宽。此时如果Topic只设计3个分区就有问题了。假设消费峰值带宽是生产带宽的2倍。则此时至少需要6个分区。
- 消费者的处理能力
假设创建了6个分区。此时6个分区最多只会有6个消费者,每个消费者最多每秒可以从Kafka Server拉到300MB的数据。但是每个消费者因为还需处理业务逻辑的关系,只能消费100MB的数据,这样就会容易导致出现消费堆积的情况。为了增大消费能力,则需要多加入消费者。
因为Kafka的consumer group机制里同一个消费组里同一个分区只能被一个消费者消费。所以,就应该增大分区的数量。为满足如上需求,此时至少需要18个分区,18个消费者,才能满足消费需求。在上面的Case中,分区数的设计也需要存在一定的冗余,因为很多情况下,性能是无法达到最优的。所以,分区数量需要综合考虑多个因素,可以适当的多一点分区数量,以提高实例的性能。但也不能太大,太大也会导致一系列的其他问题。
(2)选取合适的分区数量
考虑到上面提到的实际因素,是否有一个相对简单的判断方法来设计分区数量呢?
在理想情况下,可以通过如下公式来判断分区的数目:
Num = max( T/PT , T/CT ) = T / min( PT , CT )其中,Num 代表分区数量,T 代表目标吞吐量,PT 代表生产者写入单个 分区 的最大吞吐,CT 代表消费者从单个分区消费的最大吞吐。则分区数量应该等于 T/PT 和 T/CT 中的较大值。
在实际情况中,生产者写入分区的最大吞吐 PT 的影响因素和批处理的规模、压缩算法、确认机制、副本数等有关。消费者从单个分区消费的最大吞吐 CT 的影响因素和业务逻辑有关,需要在不同场景下实测得出。通常建议分区的数量一定要大于等于消费者的数量来实现最大并发。如果消费者数量为5,则分区的数目也应该 ≥ 5 的。
但需要注意的是:过多的分区会导致生产吞吐的降低和选举耗时的增加,因此也不建议过多分区。提供如下信息供参考:
- 单个分区是可以实现消息的顺序写入的。
- 单个分区只能被同消费者组的单个消费者进程消费。
- 单个消费者进程可同时消费多个分区,即分区限制了消费端的并发能力。
- 分区越多,当Leader节点失效后,其他分区重新进行Leader选举的耗时就会越长。
- 分区的数量是可以动态增加的,只能增加不能减少。但增加会出现消息 rebalance 的情况。
在上述方法的基础上,我们还综合考虑了腾讯课堂的生产消费峰值带宽、消费的行为特征和单个消费者的消费能力等因素,为其设计了合理的分区数量,以满足其对消息实时性的要求。
2. 消息的可靠性
消息的可靠性从不同的角度看是不一样的。从Apache Kafka自身角度看来,消息的可靠性是消息的可靠存储。从业务的角度来看,消息的可靠性是指消息传输、存储、消费的可靠性。从服务提供商来看,我们希望消息的可靠性是站在客户这一边的,即可靠的传输,存储,消费。CKafka在做好可靠性存储的基础上,还从配置调优、异常告警等方面尽量做到消息的可靠传输和消费。
(1)关于副本
在介绍下面的方案前,我们先聊聊一下副本。为什么要有副本的存在呢?
在分布式的场景下,数据损坏和机械故障是被认为常见事件。数据副本是指在不同节点上持久化同一份数据,当某一个节点上存储的数据丢失时,可以从副本上读取该数据,这是解决分布式系统数据丢失问题最为有效的方法。
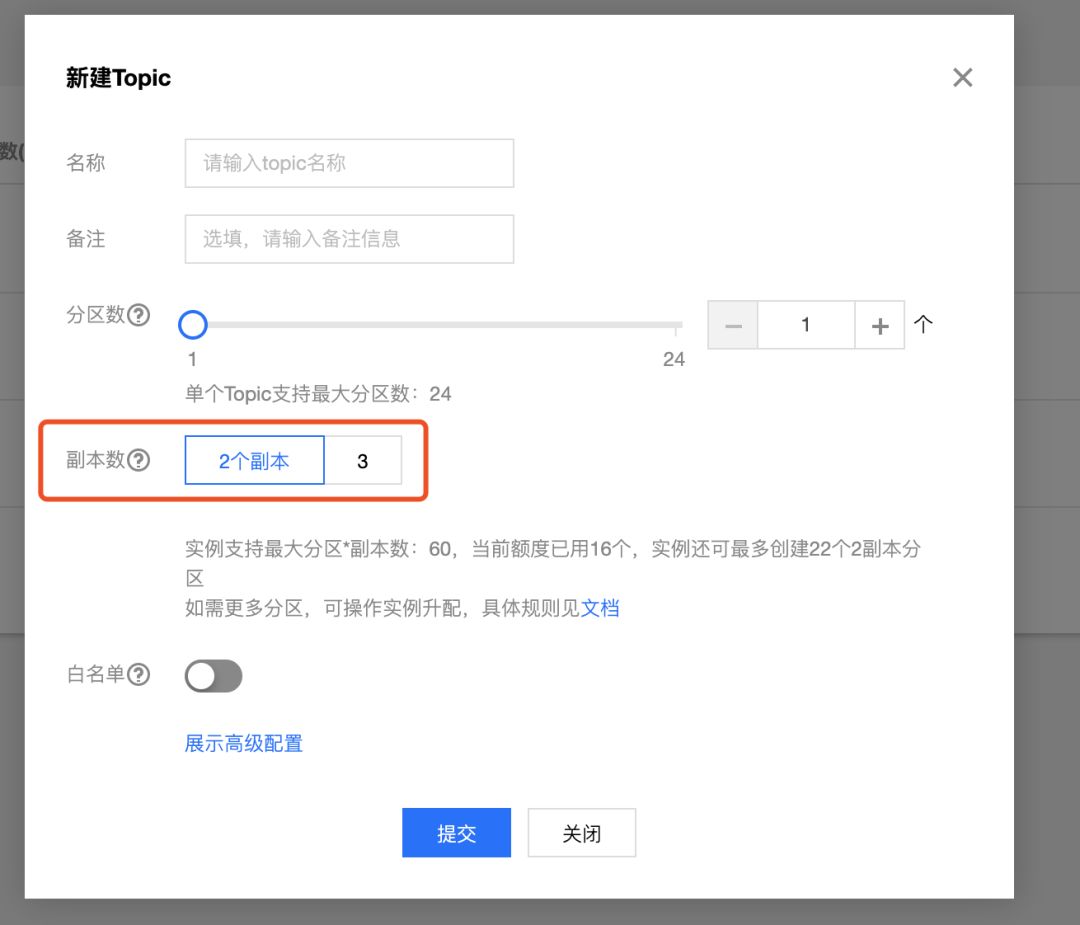
那么我们来思考下:有多少个副本的数据才是安全的?理论上2个副本就可以大概率范围的保证数据安全,但是当两个副本都损坏时,数据也会丢失,此时就需要更多的副本,或者需要副本跨可用区、跨地域分布。
当然更多的副本就意味着要存储更多的数据,需要更高的成本投入。所以用户需要在冗余和安全之间权衡出一种平衡。这也是腾讯云上创建topic需要用户指定副本数量的原因,如下图:
(2)服务端的可靠性
假设TopicA有3个分区,每个分区有三个副本。来看一下如下的Topic分区分布示意图。
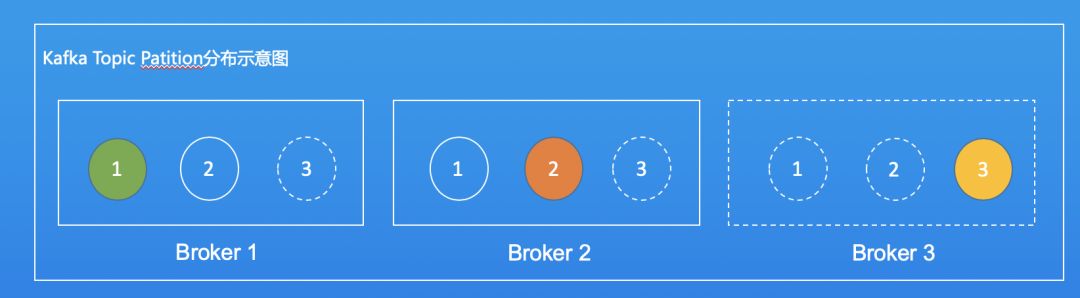
如图所示,三个分区和三个副本均匀的分布在三个Broker中,每台Broker分布了一个分区的Leader分区。
从上一节关于副本的描述可知,除非所有的Broker在同一时间挂掉,否则即使同时挂掉2台Borker,服务也可以正常运行。
而在我们当前的运营架构中,三台broker同时挂掉的概率微乎其微,当然如果真的出现这种情况,那就是整个机房挂掉了。
为了避免整个机房挂掉的情况,腾讯云Ckafka也可以配置跨机房容灾和跨可用区容灾,来保证数据的可靠性。我们可以通过参数配置来尽可能的保证可靠性传输和消费,用告警来做兜底策略,让研发感知介入处理。下面来看一下生产和消费端的参数调优。
(3)客户端参数调优
生产的可靠传输,主要来看一下如下三个配置: ack、retries。
- ack
Kafka producer 的 ack 有 3 种机制,分别说明如下:
-1:Broker 在 leader 收到数据并同步给所有 ISR 中的 follower 后,才应答给 Producer 继续发送下一条(批)消息。这种配置提供了最高的数据可靠性,只要有一个已同步的副本存活就不会有消息丢失。
0:生产者不等待来自 broker 同步完成的确认,继续发送下一条(批)消息。这种配置生产性能最高,但数据可靠性最低(当服务器故障时可能会有数据丢失) 。
1:生产者在 leader 已成功收到的数据并得到确认后再发送下一条(批)消息。这种配置是在生产吞吐和数据可靠性之间的权衡(如果leader已死但是尚未复制,则消息可能丢失)用户不显式配置时,默认值为1。如果是需要可靠性要求高的,建议设置为-1。设置为-1会影响吞吐的性能。
- retries
请求发生错误时重试次数,建议将该值设置为大于0,失败重试最大程度保证消息不丢失。消费的稳定,看一下以下配置,主要避免重复消费和频繁的消费组Rebalance:
- auto.offset.reset
表示当Broker端没有offset(如第一次消费或 offset超过7天过期)时如何初始化 offset。earliest:表示自动重置到 分区 的最小 offsetlatest:默认为 latest,表示自动重置到分区的最大 offsetnone:不自动进行 offset 重置,抛出 OffsetOutOfRangeException 异常默认值为latest。
当设置为earliest的时候,需要注意的是:当offset失效后,就会从现存的最早的数据开始消费的情况,可能会出现数据重复消费的情况。
- session.timeout.ms
使用 Kafka 消费分组机制时,消费者超时的时间。当 Broker 在该时间内没有收到消费者的心跳时,就会认为该消费者发生故障,Broker 发起重新 Rebalance 过程。目前该值的在 Broker 的配置必须在group.min.session.timeout.ms=6000和group.max.session.timeout.ms=300000 之间。
- heartbeat.interval.ms
使用 Kafka 消费分组机制时,消费者发送心跳的间隔。这个值必须小于 session.timeout.ms,一般小于它的三分之一。
- max.poll.interval.ms
使用 Kafka 消费分组机制时,再次调用 poll 允许的最大间隔。如果在该时间内没有再次调用 poll,则认为该消费者已经失败,Broker 会重新发起 Rebalance 把分配给它的分区 分配给其他消费者。
参数调优只能最大程度保证服务的可用,并不能保证服务的百分百可用。客户端需要具有捕获生产,消费等行为异常的行为。当出现异常时,能够告警,以便人工处理。这样才能最大的保证业务的高可用。
二、CKafka的其他优势
CKafka除了作为消息管道帮助业务实现数据解耦、流量削峰外,还可以在其他场景有所作为。
1. 日志分析系统
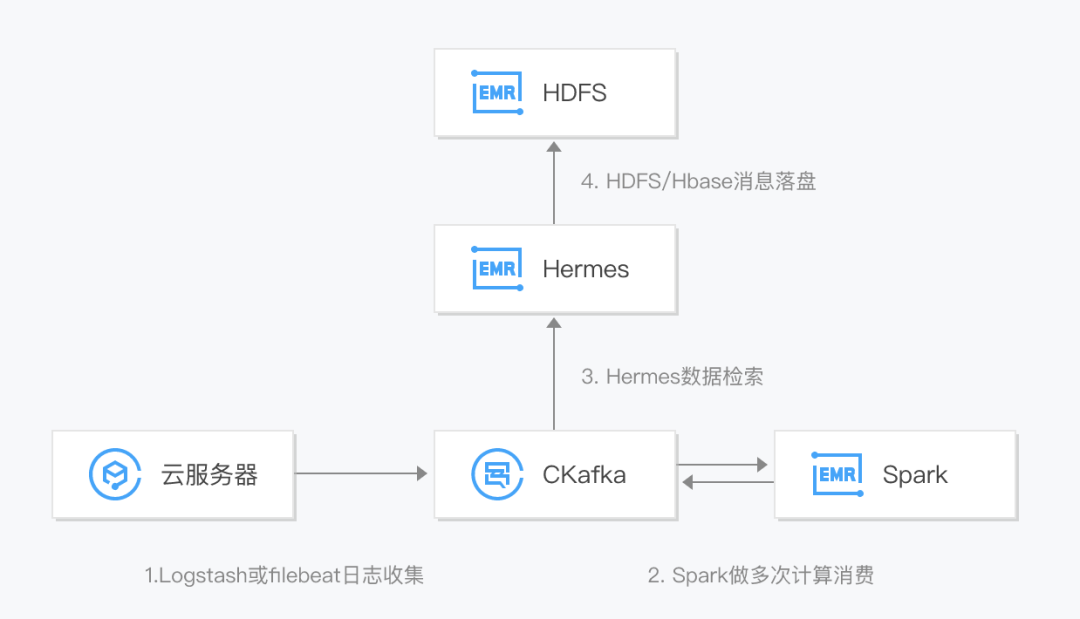
CKafka 结合大数据套件 EMR,可构建完整的日志分析系统。首先通过部署在客户端的 agent 进行日志采集,并将数据聚合到消息队列 CKafka,之后通过后端的大数据套件如 Spark 等进行数据的多次计算消费,并且对原始日志进行清理,落盘存储或进行图形化展示。
2. 流数据处理平台
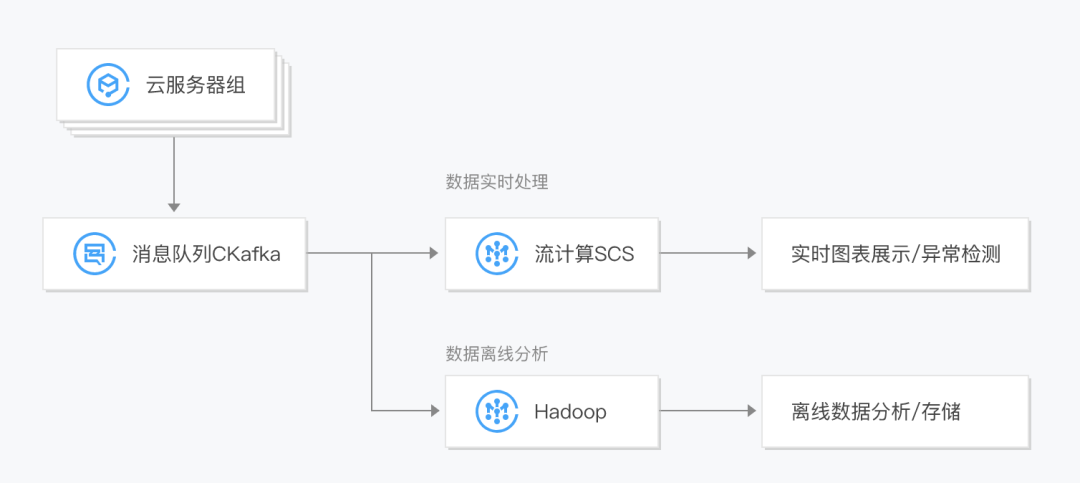
CKafka 结合流计算 SCS , 可用于实时/离线数据处理及异常检测,满足不同场景需要:
- 对实时数据进行分析和展示,并做异常检测,快速定位系统问题。
- 消费历史数据进行落盘存储和离线分析,对数据进行二次加工,生成趋势报表等。
结语
腾讯云CKafka作为高性能、高吞吐量的消息中间件,为千万师生有序稳定的线上课堂提供了性能支撑,有效的解决了数据的实时性和可靠性问题。特别是在业务故障时,可实现快速扩缩容,并以其全面的容错机制和故障处理机制为用户提供解决方案。
在2020年突如其来的疫情期间,CKafka将与腾讯课堂一起努力,为莘莘学子们百万级的课堂互动消息做好技术支撑,为构建良好的线上课堂体验贡献一份力量。
作者简介
许文强, 腾讯云中间件消息队列资深研发工程师。腾讯云Ckafka核心研发,拥有多年分布式系统研发经验。主要负责腾讯云CKafka定制化开发及优化工作。专注于Kafka在公有云多租户和大规模集群场景下的性能分析和优化。
CKafka如何助力腾讯课堂实现百万消息稳定互动?的更多相关文章
- 12月22日《奥威Power-BI财务报表数据填报》腾讯课堂开课啦
一扇可以通向任何地方的“任意门”,是我们多少人幼时最梦寐以求的道具之一.即使到了现在,工作中的我们还会时不时有“世界那么大,我想去看看”的念头,或者在突然不想工作的时刻,幻想着自己的家门变成了“任意门 ...
- 12月14日《奥威Power-BI销售计划填报》腾讯课堂开课啦
2016年的最后一个月也过半了,新的一年就要到来,你是否做好了启程的准备?新的一年,有计划,有目标,有方向,才不至于迷茫.规划你的2017,新的一年,遇见更好的自己! 所以 ...
- 12月07日《奥威Power-BI智能分析报告制作方法 》腾讯课堂开课啦
前几天跟我一个做报表的哥们聊天,听着他一茬一茬地诉苦:“每天做报表做到想吐,老板看报表时还是不给一个好脸色.”我也只能搬出那一套“过程大于结果”的内心疗程赠与他,没想到他反而怒了:“做 ...
- 11月30日《奥威Power-BI智能分析报表制作方法》腾讯课堂开课啦
这么快一周就过去了,奥威公开课又要与大家见面咯,上节课老师教的三种报表集成方法你们都掌握了吗?大家都知道,学习的结果在于实际应用,想要熟练掌握新内容的要点就在于去应用它.正是基于这一要点,每一期的课程 ...
- 11月23日《奥威Power-BI报表集成到其他系统》腾讯课堂开课啦
听说明天全国各地区都要冷到爆了,要是天气冷到可以放假就好了.想象一下大冷天的一定要在被窝里度过才对嘛,索性明天晚上来个相约吧,相约在被窝里看奥威Power-BI公开课如何? 上周奥威公开 ...
- 11月16日《奥威Power-BI基于SQL的存储过程及自定义SQL脚本制作报表》腾讯课堂开课啦
上周的课程<奥威Power-BI vs微软Power BI>带同学们全面认识了两个Power-BI的使用情况,同学们已经迫不及待想知道这周的学习内容了吧!这周的课程关键词—— ...
- 11月09日《奥威Power-BI vs微软Power BI》腾讯课堂开课啦
上过奥威公开课的同学可能有一个疑问:奥威Power-BI和微软Power BI是同一个吗,为什么叫同样的名字?正如这个世界上有很多个John.Jack.Marry…一样,奥威Power-BI和微软Po ...
- 10月26日 奥威Power-BI基于微软示例库(MSOLAP)快速制作管理驾驶舱 腾讯课堂开课啦
本次课是基于olap数据源的案例实操课,以微软olap示例库Adventure Works为数据基础. AdventureWorks示例数据库为一家虚拟公司的数据,公司背景为大型跨国生产 ...
- 10月12号 晚八点 Speed-BI 云平台-基于Excel数据源的管理驾驶舱构建全过程,腾讯课堂开课啦
认真地做了一大摞一大摞的报表,老板没时间看?努力把能反馈的内容都融汇进图表里,老板嫌复杂?做了几个简单的报表,老板一眼就觉得信息不全面?每个报表都用了各种各样的图表,老板却毫无兴趣?明明很努力了,为什 ...
随机推荐
- spring参数拼装
-- 知道轮子是怎么造的 -- 自己试着造一造轮子 ,这样才可以更好地利用轮子,轮子的缺陷和优点才能明确. spring参数拼装,需要用到set函数,参考文档: http://coderec.cn/2 ...
- js 网页运行原理
当我们打开一个网页的时候,浏览器会首先创建一个窗口,这个窗口就是我所知道的window对象,也就是整个Javascript运行所依附的全局变量. 为了加载网页文档,当前窗口又需要创建一个Documen ...
- Python字符串编码——Unicode
ASCII码 我们知道,在计算机内部,所有的信息最终都表示为一个二进制的字符串.每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte).也就是 ...
- 视频播放插件JWPlayer的使用
JwPlayer 简介 JW Media Player是一个开源的在网页上使用的Flash视频.音频以及图片播放器,支持 Sliverlight 播放,支持H.264 ( .mp4, .mo ...
- 杂记:VMware中为mac虚拟机扩容
之前在VMware中安装Mac虚拟机时,硬盘选的是默认的40G,后来用的过程中随着软件的安装,特别是安装完Xcode和QT5.9之后,可用空间只剩不到3G,每次开机之后都会提醒空间不足,需要清理空间, ...
- 为什么要用location的hash来传递参数?
分页功能代码实现 <div> <a class="btn" href="#" style="..." @Click.pre ...
- 从2019-nCoV趋势预测问题,联想到关于网络安全态势预测问题的讨论
0. 引言 在这篇文章中,笔者希望和大家讨论一个话题,即未来趋势是否可以被精确或概率性地预测. 对笔者所在的网络安全领域来说,由于网络攻击和网络入侵常常变现出随机性.非线性性的特征,因此纯粹的未来预测 ...
- Python使用input方法输入字母显示NameError
如图,每次用input方法,输入数字正常,但是输入字母就会报错. 到网上查找资料之后,明白了原来在python2.7中应该用raw_input. 修改之后,代码就正常了.
- flask 参数校验
校验参数是否存在,不存在返回400 @app.route('/check',methods=['POST']) def check(): values = request.get_json() req ...
- spring jpa ManyToMany 理解和使用
1.java和jpa 中所有的关系都是单向的.这个关系数据库不同,关系数据库,通过外键定义并查询,使得反向查询总是存在的. 2.JPA还定义了一个OneToMany关系,它与ManyToMany关系类 ...