初识Redis的数据类型HyperLogLog
前提
未来一段时间开发的项目或者需求会大量使用到Redis,趁着这段时间业务并不太繁忙,抽点时间预习和复习Redis的相关内容。刚好看到博客下面的UV和PV统计,想到了最近看书里面提到的HyperLogLog数据类型,于是花点时间分析一下它的使用方式和使用场景(暂时不探究HyperLogLog的实现原理)。Redis中HyperLogLog数据类型是Redid 2.8.9引入的,使用的时候确保Redis版本>= 2.8.9。
HyperLogLog简介
基数计数(cardinality counting),通常用来统计一个集合中不重复的元素个数。一个很常见的例子就是统计某个文章的UV(Unique Visitor,独立访客,一般可以理解为客户端IP)。大数据量背景下,要实现基数计数,多数情况下不会选择存储全量的基数集合的元素,因为可以计算出存储的内存成本,假设一个每个被统计的元素的平均大小为32bit,那么如果统计一亿个数据,占用的内存大小为:
32 * 100000000 / 8 / 1024 / 1024 ≈ 381M。
如果有多个集合,并且允许计算多个集合的合并计数结果,那么这个操作带来的复杂度可能是毁灭性的。因此,不会使用Bitmap、Tree或者HashSet等数据结构直接存储计数元素集合的方式进行计数,而是在不追求绝对准确计数结果的前提之下,使用基数计数的概率算法进行计数,目前常见的有概率算法以下三种:
Linear Counting(LC)。LogLog Counting(LLC)。HyperLogLog Counting(HLL)。
所以,HyperLogLog其实是一种基数计数概率算法,并不是Redis特有的,Redis基于C语言实现了HyperLogLog并且提供了相关命令API入口。
Redis的作者Antirez为了纪念Philippe Flajolet对组合数学和基数计算算法分析的研究,所以在设计HyperLogLog命令的时候使用了Philippe Flajolet姓名的英文首字母PF作为前缀。也就是说,Philippe Flajolet博士是HLL算法的重大贡献者,但是他其实并不是Redis中HyperLogLog数据类型的开发者。遗憾的是Philippe Flajolet博士于2011年3月22日因病在巴黎辞世。这个是Philippe Flajolet博士的维基百科照片:

Redis提供的HyperLogLog数据类型的特征:
- 基本特征:使用
HyperLogLog Counting(HLL)实现,只做基数计算,不会保存元数据。 - 内存占用:
HyperLogLog每个KEY最多占用12K的内存空间,可以计算接近2^64个不同元素的基数,它的存储空间采用稀疏矩阵存储,空间占用很小,仅仅在计数基数个数慢慢变大,稀疏矩阵占用空间渐渐超过了阈值时才会一次性转变成稠密矩阵,转变成稠密矩阵之后才会占用12K的内存空间。 - 计数误差范围:基数计数的结果是一个标准误差(
Standard Error)为0.81%的近似值,当数据量不大的时候,得到的结果也可能是一个准确值。
内存占用小(每个KEY最高占用12K)是HyperLogLog的最大优势,而它存在两个相对明显的限制:
- 计算结果并不是准确值,存在标准误差,这是由于它本质上是用概率算法导致的。
- 不保存基数的元数据,这一点对需要使用元数据进行数据分析的场景并不友好。
HyperLogLog命令使用
Redis提供的HyperLogLog数据类型一共有三个命令API:PFADD、PFCOUNT和PFMERGE。
PFADD
PFADD命令参数如下:
PFADD key element [element …]
支持此命令的Redis版本是:>= 2.8.9
时间复杂度:每添加一个元素的复杂度为O(1)
- 功能:将所有元素参数
element添加到键为key的HyperLogLog数据结构中。
PFADD命令的执行流程如下:
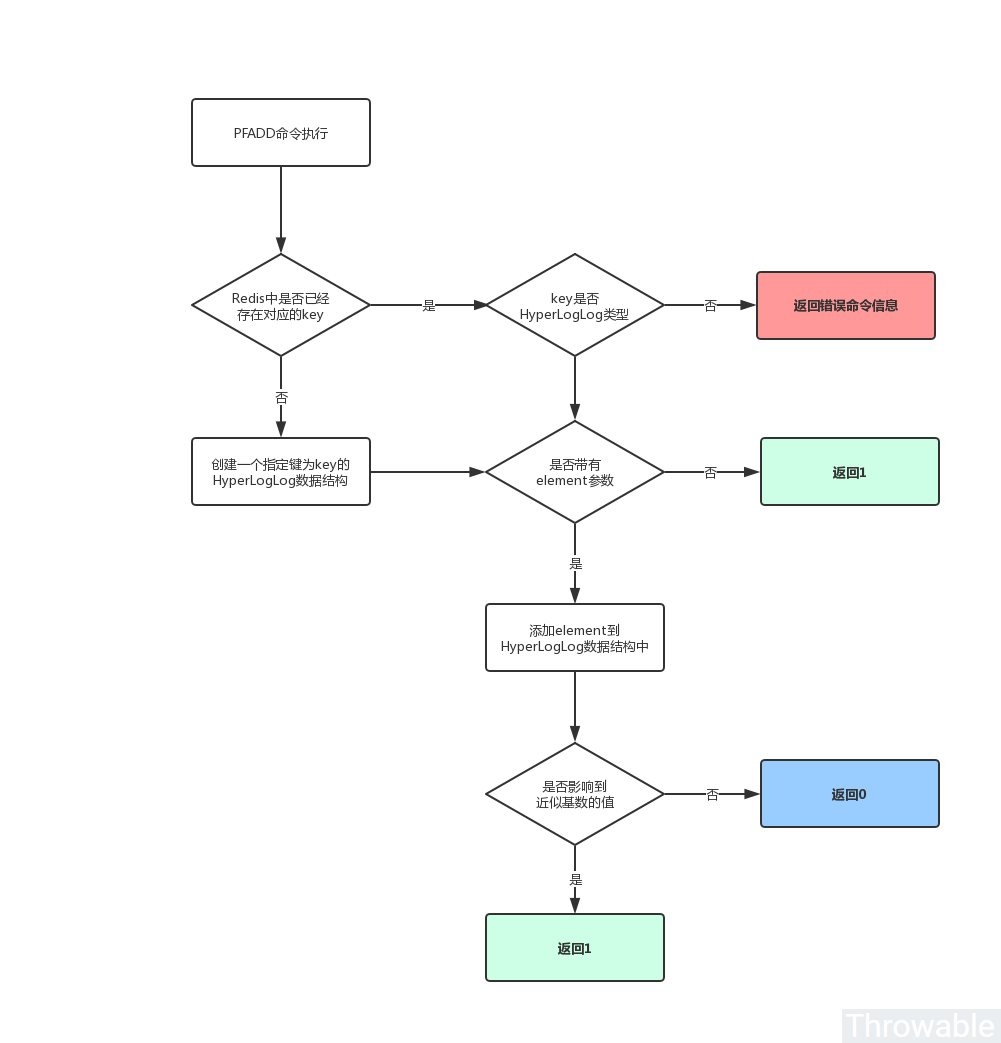
PFADD命令的使用方式如下:
127.0.0.1:6379> PFADD food apple fish
(integer) 1
127.0.0.1:6379> PFADD food apple
(integer) 0
127.0.0.1:6379> PFADD throwable
(integer) 1
127.0.0.1:6379> SET name doge
OK
127.0.0.1:6379> PFADD name throwable
(error) WRONGTYPE Key is not a valid HyperLogLog string value.
虽然HyperLogLog数据结构本质是一个字符串,但是不能在String类型的KEY使用HyperLogLog的相关命令。
PFCOUNT
PFCOUNT命令参数如下:
PFCOUNT key [key …]
支持此命令的Redis版本是:>= 2.8.9
时间复杂度:返回单个HyperLogLog的基数计数值的复杂度为O(1),平均常数时间比较低。当参数为多个key的时候,复杂度为O(N),N为key的个数。
- 当
PFCOUNT命令使用单个key的时候,返回储存在给定键的HyperLogLog数据结构的近似基数,如果键不存在, 则返回0。 - 当
PFCOUNT命令使用多个key的时候,返回储存在给定的所有HyperLogLog数据结构的并集的近似基数,也就是会把所有的HyperLogLog数据结构合并到一个临时的HyperLogLog数据结构,然后计算出近似基数。
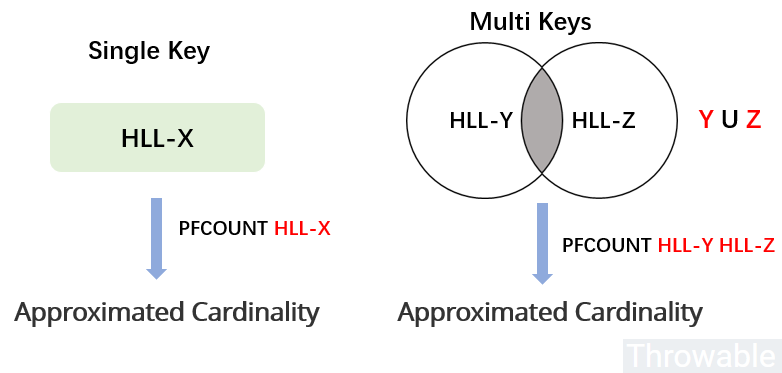
PFCOUNT命令的使用方式如下:
127.0.0.1:6379> PFADD POST:1 ip-1 ip-2
(integer) 1
127.0.0.1:6379> PFADD POST:2 ip-2 ip-3 ip-4
(integer) 1
127.0.0.1:6379> PFCOUNT POST:1
(integer) 2
127.0.0.1:6379> PFCOUNT POST:1 POST:2
(integer) 4
127.0.0.1:6379> PFCOUNT NOT_EXIST_KEY
(integer) 0
PFMERGE
PFMERGE命令参数如下:
PFMERGE destkey sourcekey [sourcekey ...]
支持此命令的Redis版本是:>= 2.8.9
时间复杂度:O(N),其中N为被合并的HyperLogLog数据结构的数量,此命令的常数时间比较高
- 功能:把多个
HyperLogLog数据结构合并为一个新的键为destkey的HyperLogLog数据结构,合并后的HyperLogLog的基数接近于所有输入HyperLogLog的可见集合(Observed Set)的并集的基数。 - 命令返回值:只会返回字符串
OK。
PFMERGE命令的使用方式如下
127.0.0.1:6379> PFADD POST:1 ip-1 ip-2
(integer) 1
127.0.0.1:6379> PFADD POST:2 ip-2 ip-3 ip-4
(integer) 1
127.0.0.1:6379> PFMERGE POST:1-2 POST:1 POST:2
OK
127.0.0.1:6379> PFCOUNT POST:1-2
(integer) 4
使用HyperLogLog统计UV的案例
假设现在有个简单的场景,就是统计博客文章的UV,要求UV的计数不需要准确,也不需要保存客户端的IP数据。下面就这个场景,使用HyperLogLog做一个简单的方案和编码实施。
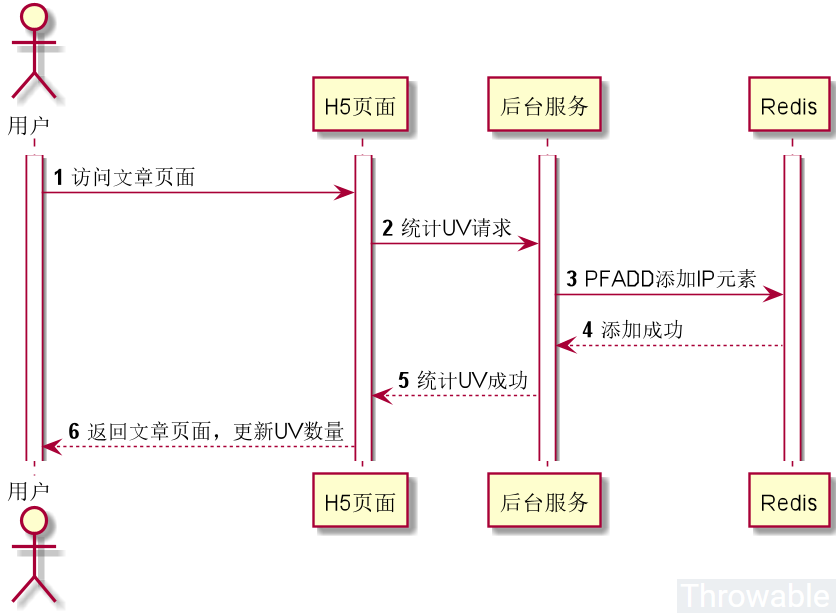
这个流程可能步骤的先后顺序可能会有所调整,但是要做的操作是基本不变的。先简单假设,文章的内容和统计数据都是后台服务返回的,两个接口是分开设计。引入Redis的高级客户端Lettuce依赖:
<dependency>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
<version>5.2.1.RELEASE</version>
</dependency>
编码如下:
public class UvTest {
private static RedisCommands<String, String> COMMANDS;
@BeforeClass
public static void beforeClass() throws Exception {
// 初始化Redis客户端
RedisURI uri = RedisURI.builder().withHost("localhost").withPort(6379).build();
RedisClient redisClient = RedisClient.create(uri);
StatefulRedisConnection<String, String> connect = redisClient.connect();
COMMANDS = connect.sync();
}
@Data
public static class PostDetail {
private Long id;
private String content;
}
private PostDetail selectPostDetail(Long id) {
PostDetail detail = new PostDetail();
detail.setContent("content");
detail.setId(id);
return detail;
}
private PostDetail getPostDetail(String clientIp, Long postId) {
PostDetail detail = selectPostDetail(postId);
String key = "puv:" + postId;
COMMANDS.pfadd(key, clientIp);
return detail;
}
private Long getPostUv(Long postId) {
String key = "puv:" + postId;
return COMMANDS.pfcount(key);
}
@Test
public void testViewPost() throws Exception {
Long postId = 1L;
getPostDetail("111.111.111.111", postId);
getPostDetail("111.111.111.222", postId);
getPostDetail("111.111.111.333", postId);
getPostDetail("111.111.111.444", postId);
System.out.println(String.format("The uv count of post [%d] is %d", postId, getPostUv(postId)));
}
}
输出结果:
The uv count of post [1] is 4
可以适当使用更多数量的不同客户端IP调用getPostDetail(),然后统计一下误差。
题外话-如何准确地统计UV
如果想要准确统计UV,则需要注意几个点:
- 内存或者磁盘容量需要准备充足,因为就目前的基数计数算法来看,没有任何算法可以在不保存元数据的前提下进行准确计数。
- 如果需要做用户行为分析,那么元数据最终需要持久化,这一点应该依托于大数据体系,在这一方面笔者没有经验,所以暂时不多说。
假设在不考虑内存成本的前提下,我们依然可以使用Redis做准确和实时的UV统计,简单就可以使用Set数据类型,增加UV只需要使用SADD命令,统计UV只需要使用SCARD命令(时间复杂度为O(1),可以放心使用)。举例:
127.0.0.1:6379> SADD puv:1 ip-1 ip-2
(integer) 2
127.0.0.1:6379> SADD puv:1 ip-3 ip-4
(integer) 2
127.0.0.1:6379> SCARD puv:1
(integer) 4
如果这些统计数据仅仅是用户端展示,那么可以采用异步设计:

在体量小的时候,上面的所有应用的功能可以在同一个服务中完成,消息队列可以用线程池的异步方案替代。
小结
这篇文章只是简单介绍了HyperLogLog的使用和统计UV的使用场景。总的来说就是:在(1)原始数据量巨大,(2)内存占用要求尽可能小,(3)允许计数存在一定误差并且(4)不要求存放元数据的场景下,可以优先考虑使用HyperLogLog进行计数。
参考资料:
(本文完 c-3-d e-a-20191117)
初识Redis的数据类型HyperLogLog的更多相关文章
- redis常用数据类型 HyperLoglog
1.HyperLoglog简介 HyperLoglog是redis新支持的两种类型中的另外一种(上一种是位图类型Bitmaps).主要适用场景是海量数据的计算.特点是速度快.占用空间小. 同样是用于计 ...
- 初识redis数据类型
初识redis数据类型 1.String(字符串) string是redis最基本的类型,一个key对应一个value. string类型是二进制安全的.意思是redis的string可以包含任何数据 ...
- 01:初识Redis
付磊和张益军两位大咖写的葵花宝典(Redis开发和运维)学习笔记. 一.初识Redis 1.redis简介 Redis是一种基于键值对(key-value)的NoSQL数据库,与很多键值对数据库不同的 ...
- 分布式数据存储 之 Redis(一) —— 初识Redis
分布式数据存储 之 Redis(一) -- 初识Redis 为什么要学习并运用Redis?Redis有什么好处?我们步入Redis的海洋,初识Redis. 一.Redis是什么 Redis 是一个 ...
- Redis扩展数据类型详解
在Redis中有5种基本数据类型,分别是String, List, Hash, Set, Zset.除此之外,Redis中还有一些实用性很高的扩展数据类型,下面来介绍一下这些扩展数据类型以及它们的使用 ...
- Redis 基础数据类型重温
有一天你突然收到一条线上告警:Redis 内存使用率 85%.你吓坏了赶紧先进行扩容然后再去分析 big key.等你进行完这一系列操作之后老板叫你去复盘,期间你们聊到了业务的数据存储在 Redis ...
- Redis——学习之路三(初识redis config配置)
我们先看看config 默认情况下系统是怎么配置的.在命令行中输入 config get *(如图) 默认情况下有61配置信息,每一个命令占两行,第一行为配置名称信息,第二行为配置的具体信息. ...
- Redis——学习之路二(初识redis服务器命令)
上一章我们已经知道了如果启动redis服务器,现在我们来学习一下,以及如何用客户端连接服务器.接下来我们来学习一下查看操作服务器的命令. 服务器命令: 1.info——当前redis服务器信息 s ...
- 初识Redis(1)
Redis 是一款依据BSD开源协议发行的高性能Key-Value存储系统(cache and store). 它通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希( ...
随机推荐
- CF915D Almost Acyclic Graph
题目链接:http://codeforces.com/contest/915/problem/D 题目大意: 给出一个\(n\)个结点\(m\)条边的有向图(无自环.无重边,2 ≤ n ≤ 500, ...
- 27-1 分组-having
group by select * from TblStudent --1.请从学生表中查询出每个班的班级id和班级人数 select tsclassId as 班级id, 班级人数=count(*) ...
- 一,初次接触html+css需要注意的小问题
不足之处请不吝赐教,在评论区帮忙补充 html最基础的,入门学习的是标签,常用的标签有<a> 定义锚.<b> 定义粗体字.<br> 单 ...
- zookeeper配置集群报错Mode: standalone
按照https://www.cnblogs.com/wrong5566/p/6056788.html 一步步配置好以后,老是启动显示Mode: standalone ,即单机模式启动. 经过排查,排除 ...
- linux 多线程 信号
一个老系统的问题,用的system v消息队列同步等响应,通过alarm信号来进行超时控制.现在系统进行升级改造(所谓云化),原来进程处理的逻辑全部改成了线程框架,问题就出现了.alarm信号发出的时 ...
- Java中的集合(二)单列集合顶层接口------Collection接口
Java中的集合(二)单列集合顶层接口------Collection接口 Collection是一个高度封装的集合接口,继承自Iterable接口,它提供了所有集合要实现的默认方法.由于Iterab ...
- Java实现 LeetCode 831 隐藏个人信息(暴力)
831. 隐藏个人信息 给你一条个人信息字符串 S,它可能是一个 邮箱地址 ,也可能是一串 电话号码 . 我们将隐藏它的隐私信息,通过如下规则: 电子邮箱 定义名称 name 是长度大于等于 2 (l ...
- C# winform 学习(一)
目标 1.类和对象 2.定义类 3.对象的操作 4.命名空间 一.类和对象 1.理解 1)类:具有共同特征和行为的一类事物的统称 2)对象:类的一个具体唯一的实例 eg: 1路公交车;(类) 车牌为F ...
- Java实现 LeetCode 553 最优除法(思路问题)
553. 最优除法 给定一组正整数,相邻的整数之间将会进行浮点除法操作.例如, [2,3,4] -> 2 / 3 / 4 . 但是,你可以在任意位置添加任意数目的括号,来改变算数的优先级.你需要 ...
- Java实现 洛谷 P1280 尼克的任务
import java.util.Scanner; public class Main { public static class edg{ private int to; private int n ...