一文入门Kafka,必知必会的概念通通搞定
Kakfa在大数据消息引擎领域,绝对是没有争议的国民老公。
这是kafka系列的第一篇文章。预计共出20篇系列文章,全部原创,从0到1,跟你一起死磕kafka。
本文盘点了 Kafka 的各种术语并且进行解读,术语可能比较枯燥,但真的是精髓中的精髓!
了解Kafka之前我们必须先掌握它的相关概念和术语,这对于后面深入学习 Kafka 各种功能将大有裨益。所以,枯燥你也得给我看完!
大概是有这么些东西要掌握,不多不多,预计20分钟可以吃透:
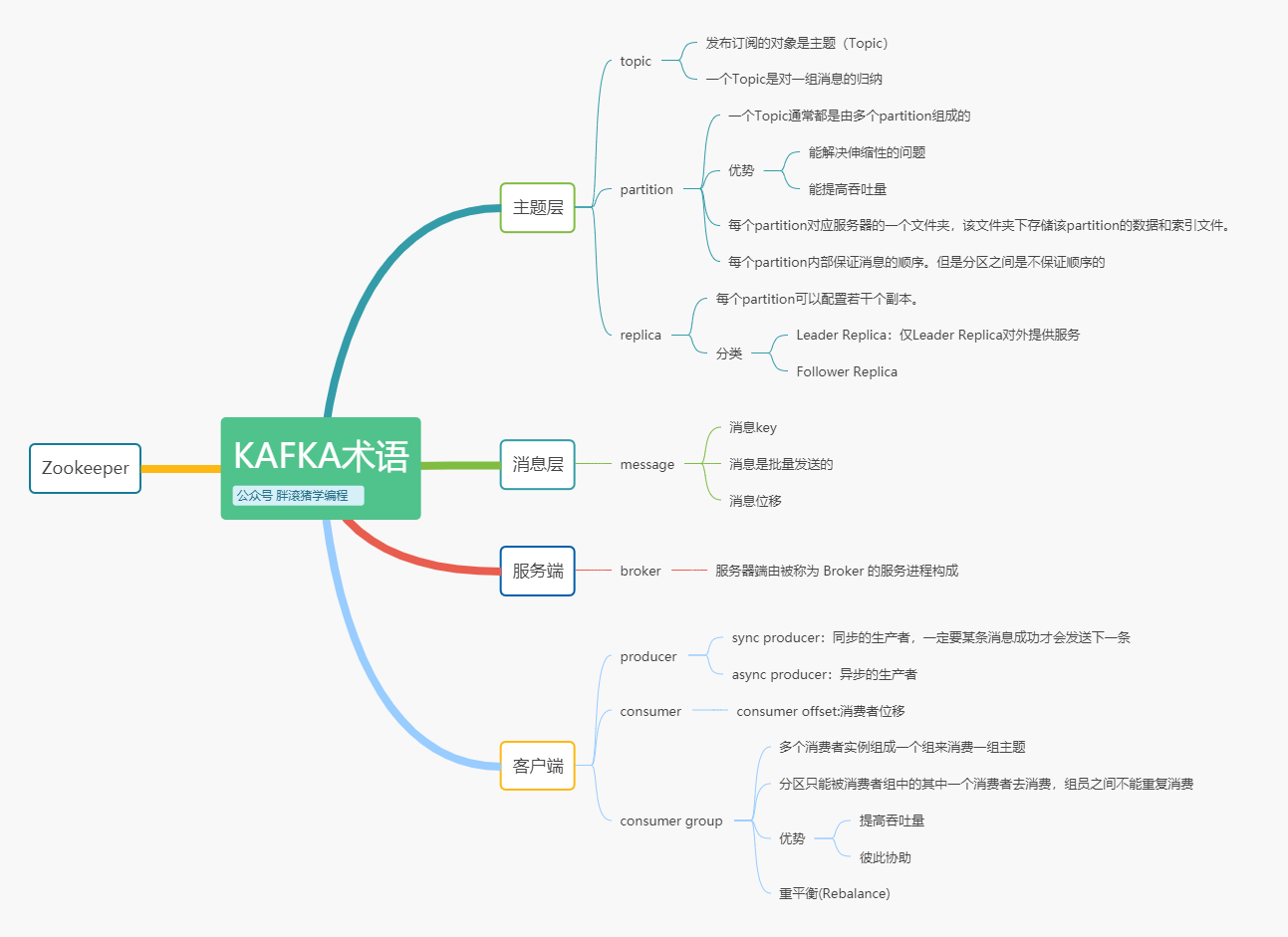
主题层
主题层有三个儿子,分别叫做:Topic、Partition、Replica。既然我说是三个儿子,那你懂了,是不可分割的整体。
Topic(主题)
Kafka 是分布式的消息引擎系统,它的主要功能是提供一套完备的消息(Message)发布与订阅解决方案。
在 Kafka 中,发布订阅的对象是主题(Topic),你可以为每个业务、每个应用甚至是每类数据都创建专属的主题。
一个Topic是对一组消息的归纳。也可以理解成传统数据库里的表,或者文件系统里的一个目录。
Partition(分区)
一个Topic通常都是由多个partition组成的,创建topic时候可以指定partition数量。
分区优势
为什么需要将Topic分区呢?如果你了解其他分布式系统,你可能听说过分片、分区域等说法,比如 MongoDB 和 Elasticsearch 中的 Sharding、HBase 中的 Region,其实它们都是相同的原理。
试想,如果一个Topic积累了太多的数据以至于单台 Broker 机器都无法容纳了,此时应该怎么办呢?
一个很自然的想法就是,能否把数据分割成多份保存在不同的机器上?这不就是分区的作用吗?其实就是解决伸缩性的问题,每个partition都可以放在独立的服务器上。
当然优势不仅于此,也可以提高吞吐量。kafka只允许单个partition的数据被一个consumer线程消费。因此,在consumer端,consumer并行度完全依赖于被消费的分区数量。综上所述,通常情况下,在一个Kafka集群中,partition的数量越多,意味着可以到达的吞吐量越大。
partition结构
每个partition对应于一个文件夹,该文件夹下存储该partition的数据和索引文件。
如图所示,可以看到两个文件夹,都对应着一个叫做asd的topic,在该台服务器上有两个分区,0和2,那么1呢?在其他服务器上啦!毕竟是分布式分布的!

我们进去asd-0目录中看看是什么?有后缀为.index和.log的文件,他们就是该partition的数据和索引文件:
现在先不管它们是何方神圣,因为我会在【分区机制原理】这篇文章中详细描述。
partition顺序性
现在,我需要你睁大眼睛看看关于分区非常重要的一点:
【每个partition内部保证消息的顺序。但是分区之间是不保证顺序的】
这一点很重要,例如kafka中的消息是某个业务库的数据,mysql binlog是有先后顺序的,10:01分我没有付款,所以pay_date为null,而10:02分我付款了,pay_date被更新了。
但到了kafka那,由于是分布式的,多分区的,可就不一定能保证顺序了,也许10:02分那条先来,这样可就会引发严重生产问题了。因此,一般我们需要按表+主键来分区。保证同一主键的数据发送到同一个分区中。
如果你想要 kafka 中的所有数据都按照时间的先后顺序进行存储,那么可以设置分区数为 1。
Replica (副本)
每个partition可以配置若干个副本。Kafka 定义了两类副本:领导者副本(Leader Replica)和追随者副本(Follower Replica)。只能有 1 个领导者副本和 N-1 个追随者副本。
为啥要用副本?也很好理解,反问下自己为什么重要的文件需要备份多份呢?备份机制(Replication)是实现高可用的一个手段。
需要注意的是:仅Leader Replica对外提供服务,与客户端程序进行交互,生产者总是向领导者副本写消息,而消费者总是从领导者副本读消息。而Follower Replica不能与外界进行交互,它只做一件事:向领导者副本发送请求,请求领导者把最新生产的消息发给它,保持与领导者的同步。
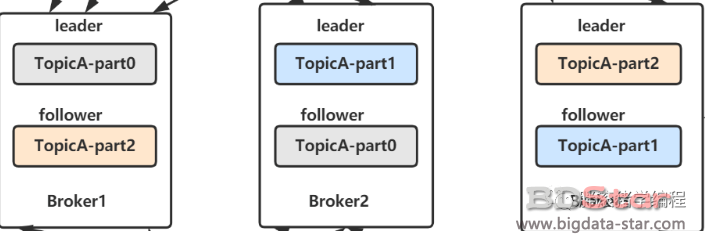
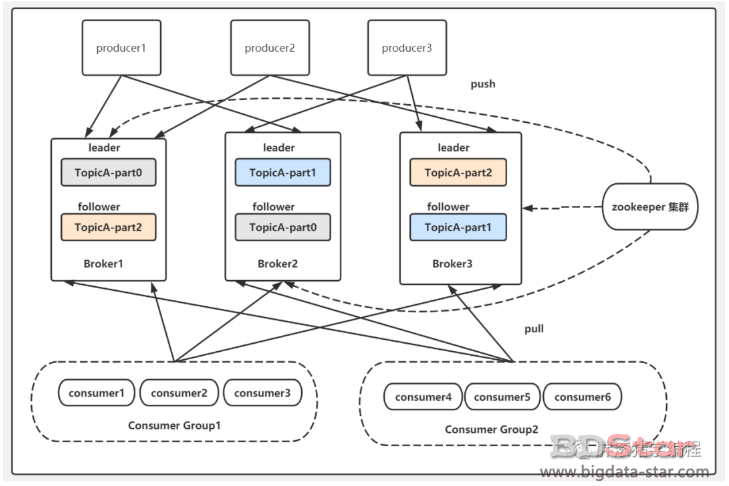
如果对于刚刚所说的主题、分区、副本还有疑惑,那么结合下面这张图再思考一下,我相信你就可以玩转它了:
下图所示,TopicA,具有三个partition,每个partion都有1 个leader副本和 1 个follower者副本。为了保证高可用性,一台机器宕机不会有影响,因此leader副本和follower副本必然分布在不同的机器上。
消息层
Kafka的官方定义是message system,由此我们可以知道Kafka 中最基本的数据单元无疑是消息message,它可理解成数据库里的一条行或者一条记录。消息是由字符数组组成。关于消息你必须知道这几件事:
消息key
发送消息的时候指定 key,这个 key 也是个字符数组。key 用来确定消息写入分区时,进入哪一个分区。你可以用有明确业务含义的字段作为key,比如用户号,这样就可以保证同一个用户号进入同一个分区。
批量写入
为了提高效率, Kafka 以批量batch的方式写入。
一个 batch 就是一组消息的集合, 这一组的数据都会进入同一个 topic 和 partition(这个是根据 producer 的配置来定的) 。
每一个消息都进行一次网络传输会很消耗性能,因此把消息收集到一起再同时处理就高效的多。
当然,这样会引入更高的延迟以及吞吐量:batch 越大,同一时间处理的消息就越多。batch 通常都会进行压缩,这样在传输以及存储的时候效率都更高一些。
位移
生产者向分区写入消息,每条消息在分区中的位置信息由一个叫位移(Offset)的数据来表征。分区位移总是从 0 开始,假设一个生产者向一个空分区写入了 10 条消息,那么这 10 条消息的位移依次是 0、1、2、…、9。
服务端
Kafka 的服务器端由被称为 Broker 的服务进程构成,即一个 Kafka 集群由多个 Broker 组成,Kafka支持水平扩展,broker数量越多,集群吞吐量越高。在集群中每个broker都有一个唯一brokerid,不得重复。Broker 负责接收和处理客户端发送过来的请求,以及对消息进行持久化。
一般会将不同的 Broker 分散运行在不同的机器上,这样如果集群中某一台机器宕机,kafka可以自动选举出其他机器上的 Broker 继续对外提供服务。这其实就是 Kafka 提供高可用的手段之一。
controller
Kafka集群中会有一个或者多个broker,其中有且仅有一个broker会被选举为控制器(Kafka Controller),它负责管理整个集群中所有分区和副本的状态。
当某个分区的leader副本出现故障时,由控制器负责为该分区选举新的leader副本。当检测到某个分区的ISR集合发生变化时,由控制器负责通知所有broker更新其元数据信息。当为某个topic增加分区数量时,同样还是由控制器负责分区的重新分配。
这几句话可能会让你觉得困惑不要方 只是突出下控制器的职能很多,而这些功能的具体细节会在后面的文章中做具体的介绍。
Kafka中的控制器选举的工作依赖于Zookeeper,成功竞选为控制器的broker会在Zookeeper中创建/controller这个临时(EPHEMERAL)节点,此临时节点的内容参考如下:
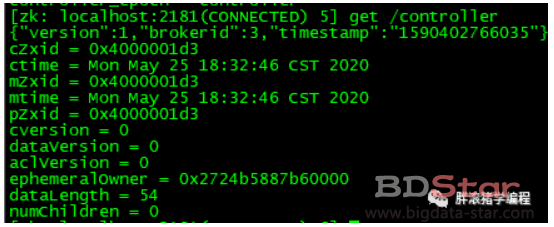
其中version在目前版本中固定为1,brokerid表示称为控制器的broker的id编号,timestamp表示竞选称为控制器时的时间戳。
两种客户端
Kafka有两种客户端。生产者和消费者。我们把生产者和消费者统称为客户端(Clients)。
向主题Topic发布消息Message的客户端应用程序称为生产者(Producer),生产者程序通常持续不断地向一个或多个主题发送消息。
而订阅这些主题消息的客户端应用程序就被称为消费者(Consumer)。和生产者类似,消费者也能够同时订阅多个主题的消息。
Producer
Producer 用来创建Message。在发布订阅系统中,他们也被叫做 Publisher 发布者或 writer 写作者。
通常情况下,会发布到特定的Topic,并负责决定发布到哪个分区(通常简单的由负载均衡机制随机选择,或者通过key,或者通过特定的分区函数选择分区。)
Producer分为Sync Producer 和 Aync Producer。
Sync Producer同步的生产者,即一定要某条消息成功才会发送下一条。所以它是低吞吐率、一般不会出现数据丢失。
Aync Producer异步的生产者,有个队列的概念,是直接发送到队列里面,批量发送。高吞吐率、可能有数据丢失的。
Consumer 和 Consumer Group
消费者
Consumer 读取消息。在发布订阅系统中,也叫做 subscriber 订阅者或者 reader 阅读者。消费者订阅一个或者多个主题,然后按照顺序读取主题中的数据。
消费位移
消费者需要记录消费进度,即消费到了哪个分区的哪个位置上,这是消费者位移(Consumer Offset)。注意,这和上面所说的消息在分区上的位移完全不是一个概念。上面的“位移”表征的是分区内的消息位置,它是不变的,即一旦消息被成功写入到一个分区上,它的位移值就是固定的了。
而消费者位移则不同,它可能是随时变化的,毕竟它是消费者消费进度的指示器嘛。通过存储最后消费的 Offset,消费者应用在重启或者停止之后,还可以继续从之前的位置读取。保存的机制可以是 zookeeper,或者 kafka 自己。
消费者组
ConsumerGroup:消费者组,指的是多个消费者实例组成一个组来消费一组主题,分区只能被消费者组中的其中一个消费者去消费,组员之间不能重复消费。
为什么要引入消费者组呢?主要是为了提升消费者端的吞吐量。多个消费者实例同时消费,加速整个消费端的吞吐量(TPS)。
当然它的作用不仅仅是瓜分订阅主题的数据,加速消费。它们还能彼此协助。假设组内某个实例挂掉了,Kafka 能够自动检测到,然后把这个 Failed 实例之前负责的分区转移给其他活着的消费者,这个过程称之为重平衡(Rebalance)。
你务必先把这个词记住,它是kafka大名鼎鼎的重平衡机制,生产出现的异常问题很多都是由于它导致的。后续我会在【kafka大名鼎鼎又臭名昭著的重平衡】文章中详细分析。
Zookeeper
zookeeper目前在kafka中扮演着举重轻重的角色和作用~是kafka不可缺少的一个组件。
目前,Apache Kafka 使用 Apache ZooKeeper 来存储它的元数据,比如brokers信息、分区的位置和主题的配置等数据就是存储在 ZooKeeper 集群中。
注意我的用词,我只说是目前。why?在 2019 年社区提出了一个计划,以打破这种依赖关系,并将元数据管理引入 Kafka 本身。因为拥有两个系统会导致大量的重复。
在之前的设计中,我们至少需要运行三个额外的 Java 进程,有时甚至更多。事实上,我们经常看到具有与 Kafka 节点一样多的 ZooKeeper 节点的 Kafka 集群!此外,ZooKeeper 中的数据还需要缓存在 Kafka 控制器上,这导致了双重缓存。
更糟糕的是,在外部存储元数据限制了 Kafka 的可伸缩性。当 Kafka 集群启动时,或者一个新的控制器被选中时,控制器必须从 ZooKeeper 加载集群的完整状态。随着元数据数量的增加,加载过程需要的时间也会增加,这限制了 Kafka 可以存储的分区数量。
最后,将元数据存储在外部会增加控制器的内存状态与外部状态不同步的可能性。
因此,未来,Kafka 的元数据将存储在 Kafka 本身中,而不是存储在 ZooKeeper 之类的外部系统中。可以持续关注kafka社区动态哦!
总结
一个典型的kafka集群包含若干个producer(向主题发布新消息),若干consumer(从主题订阅新消息,用Consumer Offset表征消费者消费进度),cousumergroup(多个消费者实例共同组成的一个组,共同消费多个分区),若干broker(服务器端进程)。还有zookeeper。
kafka发布订阅的对象叫主题,每个Topic下可以有多个Partition,Partition中每条消息的位置信息又叫做消息位移(Offset),Partition有副本机制,使得同一条消息能够被拷贝到多个地方以提供数据冗余,副本分为领导者副本和追随者副本。
可以用下面这张图来形象表达kafka的组成:
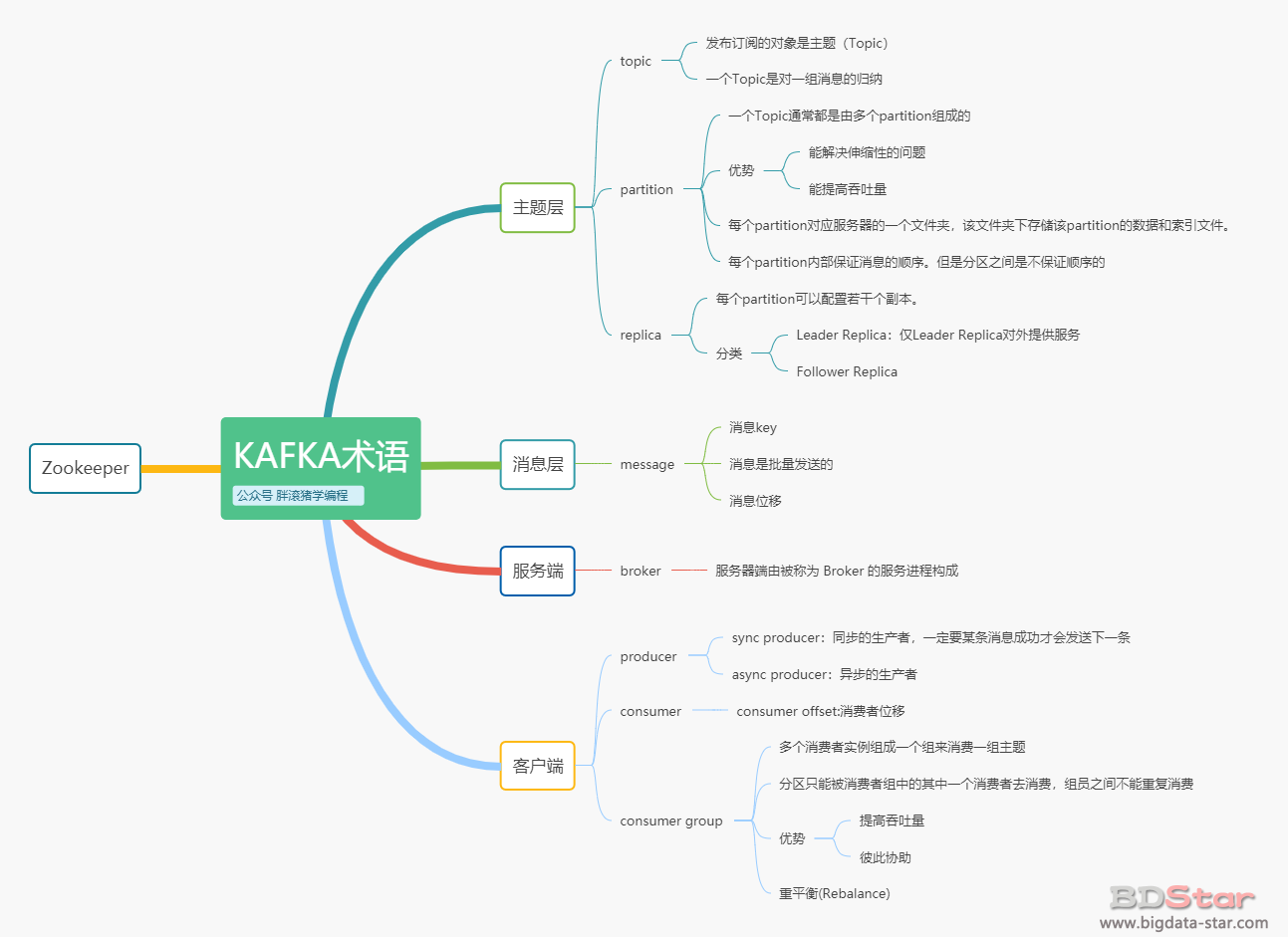
另外,再po一张思维导图助你回顾本文所述的术语。
重要!!关注【胖滚猪学编程】公众号发送"kafka"。获取本文所有架构图以及Kafka全系列思维导图!

本文来源于公众号:【胖滚猪学编程】。一枚集颜值与才华于一身,不算聪明却足够努力的女程序媛。用漫画形式让编程so easy and interesting!求关注!
一文入门Kafka,必知必会的概念通通搞定的更多相关文章
- 脑残式网络编程入门(三):HTTP协议必知必会的一些知识
本文原作者:“竹千代”,原文由“玉刚说”写作平台提供写作赞助,原文版权归“玉刚说”微信公众号所有,即时通讯网收录时有改动. 1.前言 无论是即时通讯应用还是传统的信息系统,Http协议都是我们最常打交 ...
- .NET零基础入门09:SQL必知必会
一:前言 仿佛到了更进一步的时候了,每一个程序员迟早都会遇到数据存储的问题.我们拿什么来存储程序产生的数据?举例来说,用什么来存储我们的打老鼠游戏每次的成绩呢?选择如下: 1:内存中.缺点,退出游戏, ...
- Elasticsearch必知必会的干货知识一:ES索引文档的CRUD
若在传统DBMS 关系型数据库中查询海量数据,特别是模糊查询,一般我们都是使用like %查询的值%,但这样会导致无法应用索引,从而形成全表扫描效率低下,即使是在有索引的字段精确值查找,面对海量数 ...
- SpringBoot快速入门(必知必会)
是什么?能做什么 SpringBoot必知必会 是什么?能做什么 SpringBoot是一个快速开发脚手架 快速创建独立的.生产级的基于Spring的应用程序 SpringBoot必知必会 快速创建应 ...
- SQL 必知必会
本文介绍基本的 SQL 语句,包括查询.过滤.排序.分组.联结.视图.插入数据.创建操纵表等.入门系列,不足颇多,望诸君指点. 注意本文某些例子只能在特定的DBMS中实现(有的已标明,有的未标明),不 ...
- 2015 前端[JS]工程师必知必会
2015 前端[JS]工程师必知必会 本文摘自:http://zhuanlan.zhihu.com/FrontendMagazine/20002850 ,因为好东东西暂时没看懂,所以暂时保留下来,供以 ...
- [ 学习路线 ] 2015 前端(JS)工程师必知必会 (2)
http://segmentfault.com/a/1190000002678515?utm_source=Weibo&utm_medium=shareLink&utm_campaig ...
- Android程序员必知必会的网络通信传输层协议——UDP和TCP
1.点评 互联网发展至今已经高度发达,而对于互联网应用(尤其即时通讯技术这一块)的开发者来说,网络编程是基础中的基础,只有更好地理解相关基础知识,对于应用层的开发才能做到游刃有余. 对于Android ...
- 迈向高阶:优秀Android程序员必知必会的网络基础
1.前言 网络通信一直是Android项目里比较重要的一个模块,Android开源项目上出现过很多优秀的网络框架,从一开始只是一些对HttpClient和HttpUrlConnection简易封装使用 ...
随机推荐
- web自动化的一些基础知识
selenium 原理 就是通过webdriver 给浏览器的驱动发送命令,打开浏览器,建立http通信请求 然后通过发送各种命令让浏览器进而执行各种操作 xpath 语法 #xpath定位总结:'' ...
- 【JAVA习题六】输入两个正整数m和n,求其最大公约数
import java.util.Scanner; public class Oujilide欧几里得 { public static void main(String[] args) { // TO ...
- Parrot os KDE还是MATE版本
在经历了KDE桌面痛苦折磨后,准备转投MATE的怀抱,不得不说Parrot KDE的ram的占有和windows 10差不多,大量的图形化处理,让我本来不多的内存更加血上加霜. 所以,关于版本的推荐, ...
- data类型的url
所谓"data"类型的Url格式,是在RFC2397中 提出的,目的对于一些"小"的数据,可以在网页中直接嵌入,而不是从外部文件载入.例如对于img这个Ta ...
- 小谢第8问:ui框架的css样式如何更改
目前有三种方法, 1.使用scss,增加样式覆盖,但是此种方法要求css的className需要与框架内的元素相一致,因此修改时候需要特别注意,一个父级的不同就可能修改失败 2.deep穿透,这种方法 ...
- JAVASE(九)面向对象特性之 : 继承性、方法重写、关键字super、
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 1.继承性 1.1 为什么要类的继承性?(继承性的好处) ①减少了代码的冗余,提高了代码的复用性:②更好 ...
- Java实现 蓝桥杯 算法提高 分解质因数(暴力)
试题 算法提高 分解质因数 问题描述 给定一个正整数n,尝试对其分解质因数 输入格式 仅一行,一个正整数,表示待分解的质因数 输出格式 仅一行,从小到大依次输出其质因数,相邻的数用空格隔开 样例输入 ...
- Java实现 蓝桥杯VIP 算法训练 接水问题
题目描述 有n个人在一个水龙头前排队接水,假如每个人接水的时间为Ti,请编程找出这n个人排队的一种顺序,使得n个人的平均等待时间最小. 输入输出格式 输入格式: 输入文件共两行,第一行为n:第二行分别 ...
- Java实现 LeetCode 215. 数组中的第K个最大元素
215. 数组中的第K个最大元素 在未排序的数组中找到第 k 个最大的元素.请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素. 示例 1: 输入: [3,2,1,5,6 ...
- Java实现 蓝桥杯VIP 算法提高 超级玛丽
算法提高 超级玛丽 时间限制:1.0s 内存限制:256.0MB 问题描述 大家都知道"超级玛丽"是一个很善于跳跃的探险家,他的拿手好戏是跳跃,但它一次只能向前跳一步或两步.有一次 ...