Python编程-编码、文件处理、函数
一、字符编码补充知识点
1.文本编辑器存取文件的原理(nodepad++,pycharm,word)
打开编辑器就打开了启动了一个进程,是在内存中的,所以在编辑器编写的内容也都是存放与内存中的,断电后数据丢失
因而需要保存到硬盘上,点击保存按钮,就从内存中把数据刷到了硬盘上。
在这一点上,我们编写一个py文件(没有执行),跟编写其他文件没有任何区别,都只是在编写一堆字符而已。
2.python解释器执行py文件的原理 ,例如python test.py
第一阶段:python解释器启动,此时就相当于启动了一个文本编辑器
第二阶段:python解释器相当于文本编辑器,去打开test.py文件,从硬盘上将test.py的文件内容读入到内存中
第三阶段:python解释器解释执行刚刚加载到内存中test.py的代码
总结:
(1)python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样
(2)与文本编辑器不一样的地方在于,python解释器不仅可以读文件内容,还可以执行文件内容
3.python2和python3的区别
(1)在python2中有两种字符串类型str和unicode
(2)在python三种也有两种字符串类型str和bytes
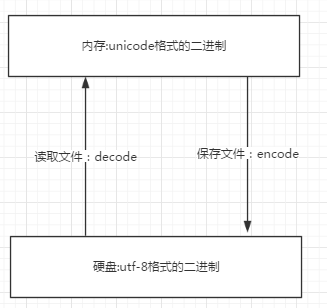
4.encode和decode
字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转换成unicode编码。
encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode('gb2312'),表示将unicode编码的字符串str2转换成gb2312编码。
二、文件处理
1.文件处理流程
(1)打开文件,得到文件句柄并赋值给一个变量
(2)通过句柄对文件进行操作
(3)关闭文件
示例:
f = open('chenli.txt') #打开文件first_line = f.readline()print('first line:',first_line) #读一行print('我是分隔线'.center(50,'-'))data = f.read()# 读取剩下的所有内容,文件大时不要用print(data) #打印读取内容f.close() #关闭文件
正确的打开方式
不指定打开编码,默认使用操作系统的编码,windows为gbk,linux为utf-8,与解释器编码无关f=open('chenli.txt',encoding='gbk') #在windows中默认使用的也是gbk编码,此时不指定编码也行f.read()
2.文件打开方式
语法:
文件句柄 = open('文件路径', mode='模式')
打开文件的模式有:
- r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】
- w,只写模式【不可读;不存在则创建;存在则清空内容】
- a, 追加模式【可读; 不存在则创建;存在则只追加内容】
"+" 表示可以同时读写某个文件
- r+, 读写【可读,可写】
- w+,写读【可读,可写】
- a+, 写读【可读,可写】
"b"表示以字节的方式操作
- rb 或 r+b
- wb 或 w+b
- ab 或 a+b
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
3.文件处理示例
(1)上下文管理
with open('a.txt','r',encoding='utf-8') as f,open('b.txt') as b_f:print(f.read())print('====>')
(2)以字节码方式打开文件时的操作
with open('a.txt','rb') as f:print(f.read().decode('utf-8'))with open('c.txt','wb') as f:f.write('哈哈哈'.encode('utf-8'))
(3)文本的方式读不了二进制文件
f=open('sb.jpg','r',encoding='utf-8')print(f.read())
(4)读取多个文件时的书写格式
with open('sb.jpg','rb') as read_f,\open('sb_alex.jpg','wb') as write_f:data=read_f.read()write_f.write(data)
(5)文件操作技巧
seek(offset,where): where=0从起始位置移动,1从当前位置移动,2从结束位置移动。当有换行时,会被换行截断。seek()无返回值,故值为None。
tell(): 文件的当前位置,即tell是获得文件指针位置,受seek、readline、read、readlines影响,不受truncate影响
truncate(n): 从文件的首行首字符开始截断,截断文件为n个字符;无n表示从当前位置起截断;截断之后n后面的所有字符被删除。其中win下的换行代表2个字符大小。
readline(n):读入若干行,n表示读入的最长字节数。其中读取的开始位置为tell()+1。当n为空时,默认只读当前行的内容
readlines读入所有行内容
read读入所有行内容
- 数字指的是读的是字符
with open('a.txt','r',encoding='utf-8') as f:print(f.read(4))with open('a.txt','rb') as f:print(f.read(1))
- seek内指定的数字代表字节
- tell指定当前光标所在的位置
with open('a.txt','r',encoding='utf-8') as f:f.seek(3)print(f.tell())print(f.read())with open('aa.txt','r+',encoding='utf-8') as f:# f.seek(3)# print(f.read())f.truncate(1) #从文件的首行首字符开始截断,截断文件为n个字符
- seek的使用方式
with open('b.txt','rb') as f:f.read()f.seek(3) #默认情况,是以文件起始位置作为开始,往后移动3个bytesf.read(1)print(f.tell())f.seek(2,1) # 1 代表以当前光标所在的位置为开始,往后移动2个bytesprint(f.tell())f.seek(-1,2) # 2 代表以结束光标所在的位置为开始,往后移动2个bytesprint(f.tell())f.seek(0,2)with open('c.txt','r',encoding='utf-8') as f:f.seek(0,2)print('====>',f.read())
补充知识:
(1)tail命令的输出方式
tail -f access.logimport timewith open('access.log','r',encoding='utf-8') as f:f.seek(0,2)while True:line=f.readline().strip()if line:print('新增一行日志',line)time.sleep(0.5)
(2)for循环结合else的用法
当for循环不被break打断,就会执行else的代码
for i in range(3):print(i)# continueif i == 1:breakelse:print('=============>')
with open('a.txt','r',encoding='utf-8') as read_f,\open('aa.txt','w',encoding='utf-8') as write_f:for line in read_f:write_f.write(line)else:print('write successfull')
i=0while i< 5:print(i)i+=1if i == 3:breakelse:print('------>')
三、函数
1.没有函数会有什么问题?
(1)无组织无结构,代码冗余
(2)可读性差
(3)无法统一管理且维护成本高
2.函数和过程
过程定义:过程就是简单特殊没有返回值的函数
当一个函数/过程没有使用return显示的定义返回值时,python解释器会隐式的返回None,所以在python中即便是过程也可以算作函数。
def test01():passdef test02():return 0def test03():return 0, 10, 'hello', ['alex', 'lb'], {'WuDaLang': 'lb'}t1 = test01()t2 = test02()t3 = test03()print('from test01 return is [%s]: ' % type(t1), t1)print('from test02 return is [%s]: ' % type(t2), t2)print('from test03 return is [%s]: ' % type(t3), t3)
运行结果:from test01 return is [<class 'NoneType'>]: Nonefrom test02 return is [<class 'int'>]: 0from test03 return is [<class 'tuple'>]: (0, 10, 'hello', ['alex', 'lb'], {'WuDaLang': 'lb'})
3.函数分类
(1)内置函数
sum
max
min
a=len('hello')print(a)b=max([1,2,3])print(b)
(2)自定义函数
def print_star():print('#'*6)def print_msg():print('hello world')print_star()print_msg()print_star()
运行结果:######hello world######
4.定义函数
(1)为什么要定义函数?
先定义后使用,如果没有定义而直接使用,就相当于引用了一个不存在的变量名。
foo()def foo():print('from foo')print(foo)
函数定义阶段到底干了什么事情:只检测函数体的语法,并不会执行
(2)函数的使用
函数的使用包含两个阶段:定义阶段和使用阶段
def 函数名(参数1,参数2,...):"""文档注释"""函数体return 值x=len('hello')print(x)
(3)定义函数的三种形式
- 无参数函数
如果函数的功能仅仅只是执行一些操作而已,就定义成无参函数,无参函数通常都有返回值
def print_star():print('#'*6)
- 有参函数
函数的功能的执行依赖于外部传入的参数,有参函数通常都有返回值
def my_max(x,y):res=x if x >y else yreturn res
- 空函数
def auth():"""认证功能"""passauth()
5.函数参数
(1)函数的参数分类
形参(变量名),实参(值)
- 形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
- 实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值
(2)详细的区分函数的参数(五类)
1)位置参数
def foo(x,y,z): #位置形参:必须被传值的参数print(x,y,z)foo(1,2,3) #位置实参数:与形参一一对应
2)关键字参数:key=value
def foo(x,y,z):print(x,y,z)foo(z=3,x=1,y=2)
关键字参数需要注意的问题:
1:关键字实参必须在位置实参后面
foo(1,x=1,y=2,z=3)
2: 不能重复对一个形参数传值
foo(1,z=3,y=2) #正确
foo(x=1,2,z=3) #错误
3)默认参数
def register(name,age,sex='male'): #形参:默认参数print(name,age,sex)register('asb',age=40)register('a1sb',39)register('a2sb',30)register('a3sb',29)register('钢蛋',20,'female')register('钢蛋',sex='female',age=19)
默认参数需要注意的问题:
- 默认参数必须跟在非默认参数后
def register(sex='male',name,age): #在定义阶段就会报错print(name,age,sex)
- 默认参数在定义阶段就已经赋值了,而且只在定义阶段赋值一次
a=100000000def foo(x,y=a):print(x,y)a=0foo(1)
- 默认参数的值通常定义成不可变类型
4)可变长参数
第一种:*args
*会把溢出的按位置定义的实参都接收,以元组的形式赋值给args
def foo(x,y,*args):print(x,y)print(args)foo(1,2,3,4,5)
运行结果:1 2(3, 4, 5)
def add(*args):res=0for i in args:res+=ireturn resprint(add(1,2,3,4))print(add(1,2))
运行结果:103
第二种:**kwargs
**会把溢出的按关键字定义的实参都接收,以字典的形式赋值给kwargs
def foo(x, y, **kwargs):print(x, y)print(kwargs)foo(1,2,a=1,name='egon',age=18)
运行结果:1 2{'a': 1, 'name': 'egon', 'age': 18}
def foo(name,age,**kwargs):print(name,age)if 'sex' in kwargs:print(kwargs['sex'])if 'height' in kwargs:print(kwargs['height'])foo('egon',18,sex='male',height='185')foo('egon',18,sex='male')
运行结果:egon 18male185egon 18male
5)命名关键字参数
*后定义的参数为命名关键字参数,这类参数,必须被传值,而且必须以关键字实参的形式去传值
def foo(name,age,*,sex='male',height):print(name,age)print(sex)print(height)foo('egon',17,height='185')
运行结果:egon 17male185
6.综合使用
def foo(name,age=10,*args,sex='male',height,**kwargs):print(name)print(age)print(args)print(sex)print(height)print(kwargs)foo('alex',1,2,3,4,5,sex='female',height='150',a=1,b=2,c=3)
运行结果:alex1(2, 3, 4, 5)female150{'a': 1, 'c': 3, 'b': 2}
def foo(*args):print(args)foo(1,2,3,4)*['A','B','C','D'],=====>'A','B','C','D'foo(*['A','B','C','D']) #foo('A','B','C','D')foo(['A','B','C','D'])
def foo(x,y,z):print(x,y,z)# foo(*[1,2,3]) #foo(1,2,3)foo(*[1,2]) #foo(1,2)
def foo(**kwargs):print(kwargs)#x=1,y=2 <====>**{'y': 2, 'x': 1}# foo(x=1,y=2)foo(**{'y': 2, 'x': 1,'a':1}) #foo(a=1,y=2,x=1)
def foo(x,y,z):print(x,y,z)# foo(**{'z':3,'x':1,'y':2}) #foo(x=1,z=3,y=2)foo(**{'z':3,'x':1}) #foo(x=1,z=3)
def foo(x,y,z):print('from foo',x,y,z)
def wrapper(*args,**kwargs):print(args)print(kwargs)wrapper(1,2,3,a=1,b=2)
def foo(x,y,z):print('from foo',x,y,z)def wrapper(*args,**kwargs):print(args) #args=(1,2,3)print(kwargs) #kwargs={'a':1,'b':2}foo(*args,**kwargs) #foo(*(1,2,3),**{'a':1,'b':2}) #foo(1,2,3,b=2,a=1)# wrapper(1,2,3,a=1,b=2)wrapper(1,z=2,y=3)
def foo(x,y,z):print('from foo',x,y,z)def wrapper(*args,**kwargs):# print(args) #args=(1,)# print(kwargs) #kwargs={'y':3,'z':2}foo(*args,**kwargs) #foo(*(1,),**{'y':3,'z':2}) #foo(1,z=2,y=3)# wrapper(1,2,3,a=1,b=2)wrapper(1,z=2,y=3)
7.函数的返回值
def foo():print('from foo')return Noneres=foo()print(res)
运行结果:from fooNone
以下三种情况返回值都为None:
(1)没有return
(2)return 什么都不写
(3)return None
return为一个值时,函数调用返回的结果就是这个值
def foo():print('from foo')x=1return xres=foo()print(res)
运行结果:from foo1
return 值1,值2,值3,... 返回结果:(值1,值2,值3,...)
def foo():print('from foo')x=1return 1,[2,3],(4,5),{}res=foo()print(res)a,b,c,d=foo()print(d)
运行结果:from foo(1, [2, 3], (4, 5), {})from foo{}
参数取值
t=(1,2,3)a,_,_=tprint(a)t=(1,2,3,4,5,6,7,8,9)a,*_,c=tprint(a)print(c)
运行结果:119
8.函数调用
- 按照有参和无参可以将函数调用分两种
foo() #定义时无参,调用时也无需传入参数
bar('egon') #定义时有参,调用时也必须有参数
def foo():print('from foo')def bar(name):print('bar===>',name)
- 按照函数的调用形式和出现的位置,分三种
#调用函数的语句形式foo()#调用函数的表达式形式def my_max(x,y):res=x if x >y else yreturn resres=my_max(1,2)*10000000print(res)#把函数调用当中另外一个函数的参数res=my_max(my_max(10,20),30)print(res)
Python编程-编码、文件处理、函数的更多相关文章
- 跟着ALEX 学python day3集合 文件操作 函数和函数式编程 内置函数
声明 : 文档内容学习于 http://www.cnblogs.com/xiaozhiqi/ 一. 集合 集合是一个无序的,不重复的数据组合,主要作用如下 1.去重 把一个列表变成集合 ,就自动去重 ...
- Python—字符编码转换、函数基本操作
字符编码转换 函数 #声明文件编码,格式如下: #-*- coding:utf-8 -*- 注意此处只是声明了文件编码格式,python的默认编码还是unicode 字符编码转换: import sy ...
- python读写Excel文件的函数--使用xlrd/xlwt
python中读取Excel的模块或者说工具有很多,如以下几种: Packages 文档下载 说明 openpyxl Download | Documentation | Bitbucket The ...
- 【Python】 编码,en/decode函数以及print语句的一些探索
昨天晚上在整理hashlib和hmac模块的时候,又看到了编码这块的内容.越看越觉得之前的理解不对,然后想研究一下自己想出来,但是越陷越深..总之把昨晚+今天一个上午的这些自己想到的东西写下来 ● 几 ...
- python字符编码-文件操作
字符编码 字符编码历史及发展 为什么有字符编码 ''' 原因:人们想要将数据存入计算机 计算机的能存储的信息都是二进制的数据 内存是基于电工作的,而电信号只有高低频两种,就用01来表示高低电频,所以计 ...
- (安全之路)从头开始学python编程之文件操作
0x00 python学习路径 b站(哔哩哔哩)视频,w3cschool(详情百度),官方文档,各大群内获取资料等等方式 0x01 python的学习要点 open()函数:有两个参数,文件名跟模式, ...
- Python | 多种编码文件(中文)乱码问题解决
问题线索 1 可以知道的是,文本文件的默认编码并不是utf8. 我们打开一个文本文件,并点击另存为 2 我们在新窗口的编码一栏看到默认编码是ANSI.先不管这个编码是什么编码,但是通过下拉列表我们 ...
- python中不同文件中函数和类的调用
最近在学习Python的时候,遇到了一个不同文件中类无法调用的问题,搜了很多,发现很多人针对 这个问题都说的相当含糊,让我费了好大劲才把这个东东搞明白.记录一下,权且温习. 调用分两种,一种是同种文件 ...
- Python编程-编码、变量、数据类型
一.Python和其他语言对比 C语言最接近机器语言,因此运行效率是最高的,但需要编译. JAVA更适合企业应用. PHP适合WEB页面应用. PYTHON语言更加简洁,丰富的类库,使初学者更易实现应 ...
随机推荐
- X264码率控制总结
ABR,CQP,CRF X264显式支持的一趟码率控制方法有:ABR, CQP, CRF. 缺省方法是CRF.这三种方式的优先级是ABR > CQP > CRF. if ( bitrate ...
- mac与phy怎样实现网络自适应
这两天改动网卡驱动以实现10/100/1000M自适应,因此研究了下phy芯片和emac驱动怎样兼容10/100/1000M网络环境,记录在此. 网络中设备端数据链路层由mac芯片和phy芯片组成.p ...
- 【直播预告】7月18日3D游戏引擎免费公开课答疑,參与送C币!
喜讯喜讯! 为了酬谢广大学员.CSDN学院特推出iOS和3D游戏引擎开发免费技术答疑公开课,让您度过一个充实的暑假~ 參与本次公开课,即有机会获得50C币! 答疑公开课时间:7月18日 晚7:30-9 ...
- ChemDraw 15支持哪些输入格式
当我们想让我们的化学图形应用在试卷编辑.论文撰写.刊物出版等各个方面,这个时候往往都得使用ChemDraw 15.它可以与很多第三方应用灵活.本ChemDraw教程介绍新版ChemDraw Profe ...
- python提供了一个进行hash加密的模块:hashlib
python提供了一个进行hash加密的模块:hashlib下面主要记录下其中的md5加密方式 import hashlib data1 = 'sada' #####字母和数字 m = hashlib ...
- 《从零开始学Swift》学习笔记(Day 18)——有几个分支语句?
原创文章,欢迎转载.转载请注明:关东升的博客 分支语句又称条件语句,Swift编程语言提供了if.switch和guard三种分支语句. if语句 由if语句引导的选择结构有if结构.if ...
- <2013 08 12> Andrew:C语言的一点心得
C语言的特点在于,这是少见的中级语言(介于机器汇编和高级语言之间),因此它极其紧密地与特定机器架构.编译器.操作系统.库等基本概念相连.在底层,人们可以少量的甚至不使用汇编,但是不能不使用C.它以一种 ...
- 类 String、StringBuffer、StringBuilder
类 String String 类代表字符串.Java 程序中的所有字符串字面值(如 "abc" )都作为此类的实例实现.字符串是常量:它们的值在创建之后不能更改.字符串缓冲区支持 ...
- CRM客户关系管理系统-需求概设和详设
大概设计 大概设计就是对需求进行一个整体性分析,把需要实现的功能都列出来,对于客户关系管理系统,我们需要从角色出发,从而确定有哪些需求,最好是画个思维导图 首先我们是为培训学校这么一个场景来开发的,所 ...
- ThinkPHP在入口文件中判断是手机还是PC端访问网站
<?php// +----------------------------------------------------------------------// | ThinkPHP [ WE ...