(原创)不过如此的 DFS 深度优先遍历
DFS 深度优先遍历
DFS算法用于遍历图结构,旨在遍历每一个结点,顾名思义,这种方法把遍历的重点放在深度上,什么意思呢?就是在访问过的结点做标记的前提下,一条路走到天黑,我们都知道当每一个结点都有很多分支,那么我们的小人就沿着每一个结点走,定一个标准,比如优先走右手边的路,然后在到达下一个结点前先敲敲门,当一个结点的所有门都被敲了个遍都标记过,那么就走回头路,再重复敲门,直到返回起点,这样的方式我们叫做 DFS 深度优先遍历,本文以图结构讲解,例子取自《大话数据结构》。
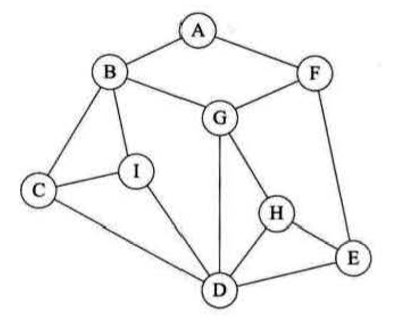
如我刚才所讲,从A点出发,将路径画出来就是以下效果。
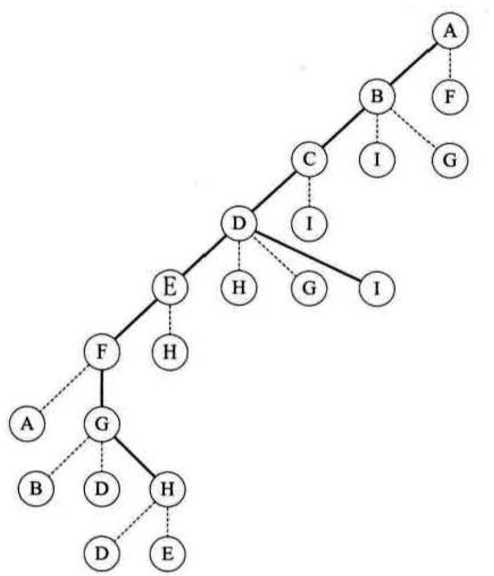
实线是走过的路程,虚线就是我们的小人敲门然后发现标记过的一个过程,大家可以寄几模拟一哈。一句话总结就是:
从图中某个顶点 v 出发,访问此顶点,然后从 v 的未被访问的邻接点出发 深度优先遍历图结构,直至图中所有和 v 有路径相通的顶点都被访问到。
结构定义代码:
- typedef char VertexType;
- typedef int EdgeType;
- #define MAXVEX 10
- #define INFINITY 65535
- typedef int boolean;
- boolean visited[MAXVEX];
- typedef struct
- {
- VertexType vexs[MAXVEX];
- EdgeType arc[MAXVEX][MAXVEX];
- int numVertexes,numEdges;
- }MGraph;
邻接矩阵创建:
- void CreateMGraph(MGraph *G)
- {
- int i,j,k;
- printf("请输入顶点数和边数(空格隔开)\n");
- scanf("%d %d",&G->numVertexes,&G->numEdges);
- printf("请依次输入每个顶点的内容:\n");
- for(i = ;i < G->numVertexes;i++)
- {
- scanf("%c",&G->vexs[i]);
- }
- for(i = ;i < G->numVertexes;i++)
- {
- for(j = ;j < G->numVertexes;j++)
- {
- G->arc[i][j] = INFINITY;
- }
- }
- for(k = ;k < G->numEdges;k++)
- {
- printf("输入边(vi,vj)上的下标i,下标j:\n");
- scanf("%d %d",&i,&j);
- G->arc[i][j] = ;
- G->arc[j][i] = G->arc[i][j];
- }
- }
DFS算法
- void DFS(MGraph G,int i) //深度优先递归算法
- {
- int j;
- visited[i] = ;
- printf("%c",G.vexs[i]);
- for(j = ;j < G.numVertexes;j++)
- {
- if(G.arc[i][j] == && !visited[j])
- DFS(G,j);
- }
- }
- void DFStraverse(MGraph G) //深度遍历
- {
- int i;
- for(i = ;i < G.numVertexes;i++)
- visited[i] = ;
- for(i = ;i < G.numVertexes;i++)
- {
- if(!visited[i])
- DFS(G,i);
- }
- }
这种方法比较好理解在于使用循环进入函数再递归,可以保证以邻接矩阵为储存单位的每一个格子都被遍历到,且做好标注,那么用邻接矩阵的DFS算法时间复杂度可以想见是 O(n²),嵌套两重循环,
我们来看下一种实现方式,这次我们使用的是邻接单链表
结构定义:
- typedef int boolean;
- boolean visited[MAXVEX];
- typedef char VertexType;
- typedef int EdgeType;
- #define MAXVEX 10
- #define INFINITY 65535
- typedef struct EdgeNode //边表结构点
- {
- int adjvex;
- struct EdgeNode *next;
- }EdgeNode;
- typedef struct VertexNode //顶点表结构点
- {
- VertexType data;
- EdgeNode *firstedge;
- }VertexNode,AdjList[MAXVEX];
- typedef struct //总表结构
- {
- AdjList adjList;
- int numVertexes,numEdges;
- }GraphAdjList;
比邻接矩阵复杂一点,但是其结构只有三种,总表、定点表和边表
创建:
- void CreateALGraph(GraphAdjList *G)
- {
- int i,j,k;
- EdgeNode *e;
- printf("请输入顶点数和边数(空格隔开)\n");
- scanf("%d %d",&G->numVertexes,&G->numEdges);
- for(i = ;i < G->numVertexes;i++)
- {
- scanf("%c",&G->adjList[i].data);
- G->adjList[i].firstedge = NULL;
- }
- for(k = ;k < G->numVertexes;k++)
- {
- printf("输入边(vi,vj)上的下标i,下标j:\n");
- scanf("%d %d",&i,&j);
- e = (EdgeNode*)malloc(sizeof(EdgeNode));
- e->adjvex=i;
- e->next = adjList[j].firstedge;
- adjList[j].firstedge = e;
- e = (EdgeNode*)malloc(sizeof(EdgeNode));
- e->adjvex=j;
- e->next = adjList[i].firstedge;
- adjList[i].firstedge = e;
- }
- }
DFS算法实现:
- void DFS(GraphAdjList GL,int i)
- {
- EdgeNode *p;
- visited[i] = ;
- printf("%c",GL->adjList[i].data);
- while(p)
- {
- if(!visited[p->adjvex])
- DFS(GL,p->adjvex);
- p = p->next;
- }
- }
- void DFStraverse(GraphAdjList GL)
- {
- int i;
- for(i = ;i < GL->numVertexes;i++)
- visited[i] = ;
- for(i = ;i < GL->numVertexes;i++)
- {
- if(!visited[i])
- DFS(GL,i);
- }
- }
利用邻接表的方式能够实现相同效果的遍历,同时这种方法的算法时间复杂度为 O(n+e)
显然对于点多边少的稀疏图来说,邻接表结构使得算法在时间效率上大大提高。
(原创)不过如此的 DFS 深度优先遍历的更多相关文章
- 图的深度优先遍历DFS
图的深度优先遍历是树的前序遍历的应用,其实就是一个递归的过程,我们人为的规定一种条件,或者说一种继续遍历下去的判断条件,只要满足我们定义的这种条件,我们就遍历下去,当然,走过的节点必须记录下来,当条件 ...
- 图的深度优先遍历(DFS)—递归算法
实验环境:win10, DEV C++5.11 实验要求: 实现图的深度优先遍历 实验代码: #include <iostream> #define maxSize 255 #includ ...
- 图的深度优先遍历(DFS)和广度优先遍历(BFS)
body, table{font-family: 微软雅黑; font-size: 13.5pt} table{border-collapse: collapse; border: solid gra ...
- 广度优先遍历-BFS、深度优先遍历-DFS
广度优先遍历-BFS 广度优先遍历类似与二叉树的层序遍历算法,它的基本思想是:首先访问起始顶点v,接着由v出发,依次访问v的各个未访问的顶点w1 w2 w3....wn,然后再依次访问w1 w2 w3 ...
- 深度优先遍历DFS
深度优先遍历,这个跟树中的遍历类似,做深度遍历就是访问一个节点之后,在访问这个节点的子节点,依次下去是一个递归的过程. 具体代码: void DFS(MGraph g ,int i) { in ...
- 采用邻接矩阵表示图的深度优先搜索遍历(与深度优先搜索遍历连通图的递归算法仅仅是DFS的遍历方式变了)
//采用邻接矩阵表示图的深度优先搜索遍历(与深度优先搜索遍历连通图的递归算法仅仅是DFS的遍历方式变了) #include <iostream> using namespace std; ...
- 图文详解两种算法:深度优先遍历(DFS)和广度优先遍历(BFS)
参考网址:图文详解两种算法:深度优先遍历(DFS)和广度优先遍历(BFS) - 51CTO.COM 深度优先遍历(Depth First Search, 简称 DFS) 与广度优先遍历(Breath ...
- 图的深度优先遍历(DFS) c++ 非递归实现
深搜算法对于程序员来讲是必会的基础,不仅要会,更要熟练.ACM竞赛中,深搜也牢牢占据着很重要的一部分.本文用显式栈(非递归)实现了图的深度优先遍历,希望大家可以相互学习. 栈实现的基本思路是将一个节点 ...
- 【图的遍历】广度优先遍历(DFS)、深度优先遍历(BFS)及其应用
无向图满足约束条件的路径 •[目的]:掌握深度优先遍历算法在求解图路径搜索问题的应用 [内容]:编写一个程序,设计相关算法,从无向图G中找出满足如下条件的所有路径: (1)给定起点u和终点v. ( ...
随机推荐
- 【luogu P2397 yyy loves Maths VI (mode) 】 题解
题目链接:https://www.luogu.org/problemnew/show/P2397 卡空间. 对于众数出现次数 > n/2 我们考虑rand. 每次正确的概率为1/2,五个测试点, ...
- JQuery 禁用后退按钮
jQuery(document).ready(function () { if (window.history && window.history.pushState) { $(win ...
- js点赞效果图
点赞时点赞图标会发生变化. html部分: <img src="img/icon_thumb_up.png" id="imgs1" style=" ...
- CSS&JS定位器
一.CssSelector定位器 1.概述 CssSelector是效率很高的元素定位方法,Selenium官网的Document里极力推荐使用CSS locator,而不是XPath来定位元素,原因 ...
- 第一次接触mysql
一:数据库的好处 1. 可以持久化保存数据在本地 2.结构化查询 二:数据库常见的概念 1.DB: 是datebase数据库的缩写,储存数据得到容器 2.DBMS:数据库管理系统,用于管理数据库,和创 ...
- SpringCloud微服务实战:一、Eureka注册中心服务端
1.项目启动类application.java类名上增加@EnableEurekaServer注解,声明是注册中心 1 import org.springframework.boot.SpringAp ...
- iOS开发 | 自定义不规则label
其中有一个不太规则的label: image.png 这个label顶部的两个角是圆角,底部的两个角是直角,底部还有一个小三角. 思路 CAShapeLayer联合UIBezierPath画一个不 ...
- SmallMQ实现发布
最近一直学习,主要处理java的分布式,MQ,RPC,通信,数据库,缓存等方向. 一般现在的MQ都是企业级的,庞大,功能齐全.最主要是代码量大,对于我们这些小程序员而言,太大,修改困难,修复更加困难, ...
- mysqldump备份与基于bin-log实现完全恢复
MySQL数据库备份是一项非常重要的工作,mysql的备份主要分为逻辑备份和物理备份,同时,不同的生产环境要备份的策略也不会不同.下面先说一说备份时要考虑到的一些因素,然后再实际操作进行不同方式的数据 ...
- Linux入门-第三周
1.总结vim命令行模式常见快捷方式,以及vim查找,替换的方法 vim [options] [file ..] +# 打开文件后,让光标处于第#行的行首,(默认行尾) 举例vim +10 /etc/ ...