通过案例对SparkStreaming透彻理解三板斧之三
本课将从二方面阐述:
一、解密SparkStreaming Job架构和运行机制
二、解密SparkStreaming容错架构和运行机制
一切不能进行实时流处理的数据都将是无效的数据。在流处理时代,SparkStreaming有着强大吸引力,加上Spark的生态系统及各个子框架,SparkStreaming可以无缝的调用其兄弟框,如SQL,MLlib、Graphx等。掌握SparkStreaming架构及Job运行机制对精通SparkStreaming至关重要。通常的Spark应用程序是对RDD的Action操作触发了应用程序的Job的运行。而对于SparkStreaming,Job是怎么样运行的呢?在编写SparkStreaming程序的时候,可设置BatchDuration,SparkStreaming框架会自动启动Job并每隔BatchDuration时间会自动触发Job的调用。
两个Job的概念
每隔BatchInterval时间片就会产生的一个个Job,这里的Job并不是Spark Core中的Job,它只是基于DStreamGraph而生成的RDD的DAG而已;从Java角度讲相当于Runnable接口的实现类,要想运行Job需要将Job提交给JobScheduler,在JobScheduler内部会通过线程池的方式创建运行Job的一个个线程,当找到一个空闲的线程后会将Job提交到集群运行(其实是在线程中基于RDD的Action触发真正的作业的运行)。为什么使用线程池呢?
a.Job根据BatchInterval不断生成,为了减少线程创建而带来的效率提升我们需要使用线程池(这和在Executor中通过启动线程池的方式来执行Task有异曲同工之妙);
b.如果Job的运行设置为FAIR公平调度的方式,这个时候也需要多线程的支持;
上面Job提交的Spark Job本身。单从这个时刻来看,此次的Job和Spark core中的Job没有任何的区别。
下面通过运行代码示例来分析整个运行机制
package com.dt.spark.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 使用Scala开发集群运行的Spark 在线黑名单过滤程序
* @author DT大数据梦工厂
* 新浪微博:http://weibo.com/ilovepains/
*
* 背景描述:在广告点击计费系统中,我们在线过滤掉黑名单的点击,进而保护广告商的利益,只进行有效的广告点击计费
* 或者在防刷评分(或者流量)系统,过滤掉无效的投票或者评分或者流量;
* 实现技术:使用transform Api直接基于RDD编程,进行join操作
*/
object OnlineForeachRDD2DB {
def main(args: Array[String]){
/**
* 第1步:创建Spark的配置对象SparkConf,设置Spark程序的运行时的配置信息,
* 例如说通过setMaster来设置程序要链接的Spark集群的Master的URL,如果设置
* 为local,则代表Spark程序在本地运行,特别适合于机器配置条件非常差(例如
* 只有1G的内存)的初学者 *
*/
val conf = new SparkConf() //创建SparkConf对象
conf.setAppName("OnlineForeachRDD") //设置应用程序的名称,在程序运行的监控界面可以看到名称
// conf.setMaster("spark://Master:7077") //此时,程序在Spark集群
conf.setMaster("local[6]")
//设置batchDuration时间间隔来控制Job生成的频率并且创建Spark Streaming执行的入口
val ssc = new StreamingContext(conf, Seconds(5))
val lines = ssc.socketTextStream("Master", 9999)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords => {
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => {
val sql = "insert into streaming_itemcount(item,count) values('" + record._1 + "'," + record._2 + ")"
val stmt = connection.createStatement();
stmt.executeUpdate(sql);
})
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}
}
}
/**
* 在StreamingContext调用start方法的内部其实是会启动JobScheduler的Start方法,进行消息循环,在JobScheduler
* 的start内部会构造JobGenerator和ReceiverTacker,并且调用JobGenerator和ReceiverTacker的start方法:
* 1,JobGenerator启动后会不断的根据batchDuration生成一个个的Job
* 2,ReceiverTracker启动后首先在Spark Cluster中启动Receiver(其实是在Executor中先启动ReceiverSupervisor),在Receiver收到
* 数据后会通过ReceiverSupervisor存储到Executor并且把数据的Metadata信息发送给Driver中的ReceiverTracker,在ReceiverTracker
* 内部会通过ReceivedBlockTracker来管理接受到的元数据信息
* 每个BatchInterval会产生一个具体的Job,其实这里的Job不是Spark Core中所指的Job,它只是基于DStreamGraph而生成的RDD
* 的DAG而已,从Java角度讲,相当于Runnable接口实例,此时要想运行Job需要提交给JobScheduler,在JobScheduler中通过线程池的方式找到一个
* 单独的线程来提交Job到集群运行(其实是在线程中基于RDD的Action触发真正的作业的运行),为什么使用线程池呢?
* 1.作业不断生成,所以为了提升效率,我们需要线程池;这和在Executor中通过线程池执行Task有异曲同工之妙;
* 2.有可能设置了Job的FAIR公平调度的方式,这个时候也需要多线程的支持;
*/
ssc.start()
ssc.awaitTermination()
}
}
package com.dt.spark.sparkstreaming;
import java.sql.Connection;
import java.sql.DriverManager;
import java.util.LinkedList;
public class ConnectionPool {
private static LinkedList<Connection> connectionQueue;
static {
try {
Class.forName("com.mysql.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
public synchronized static Connection getConnection() {
try {
if(connectionQueue == null) {
connectionQueue = new LinkedList<Connection>();
for(int i = 0; i < 5; i++) {
Connection conn = DriverManager.getConnection(
"jdbc:mysql://Master:3306/sparkstreaming",
"root",
"778899..");
connectionQueue.push(conn);
}
}
} catch (Exception e) {
e.printStackTrace();
}
return connectionQueue.poll();
}
public static void returnConnection(Connection conn) {
connectionQueue.push(conn);
}
}
将上述代码打成JAR包:





启动SparkStreaming应用程序:
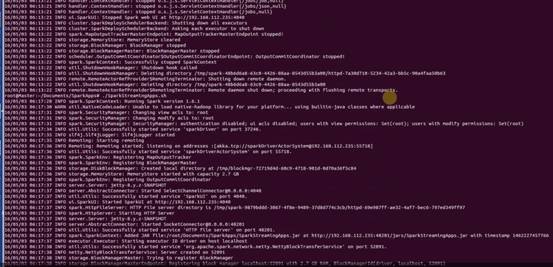
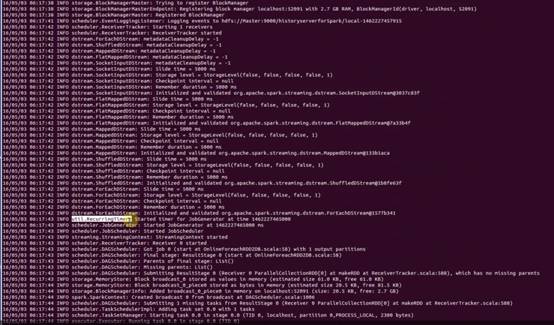
具体执行细节是走的是SparkCore路线:
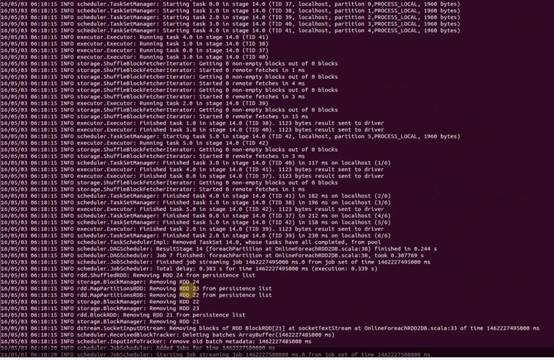
使用foreachRDD的话将结果内容直接插入数据库中,不会进行打印结果输出:
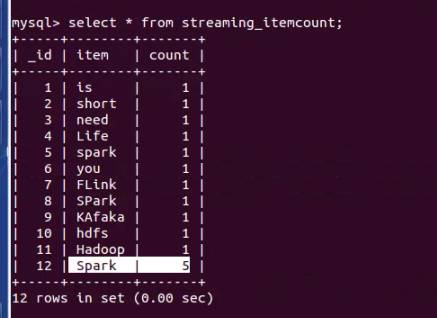
再看下整个运行过程:

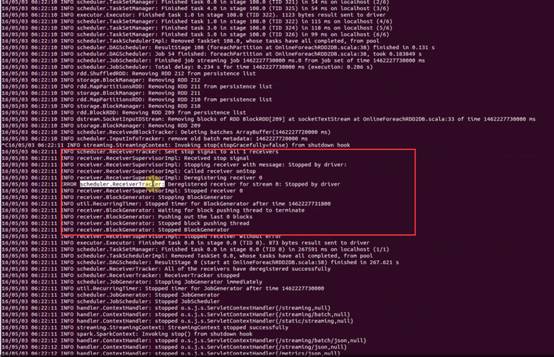
总调度器启动:Jobscheduler,主要是根据batchInterval或windows窗口移动进行作业划分,SparkStreaming不断接收流进来数据,不断生成Job,看下web控制台:
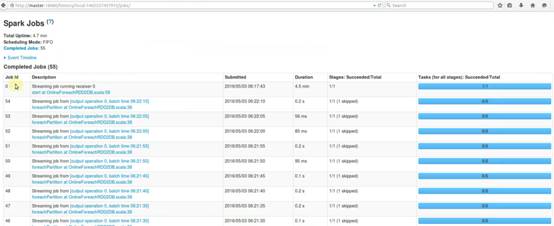
随着时间的流失,不断生成job本身,job怎么生成?

运行过程总结如下:
1、在StreamingContext调用start方法的内部其实是会启动JobScheduler的Start方法,进行消息循环,在JobScheduler
的start内部会构造JobGenerator和ReceiverTacker,并且调用JobGenerator和ReceiverTacker的start方法:
JobGenerator启动后会不断的根据batchDuration生成一个个的Job
ReceiverTracker启动后首先在Spark Cluster中启动Receiver(其实是在Executor中先启动ReceiverSupervisor),在Receiver收到
数据后会通过ReceiverSupervisor存储到Executor并且把数据的Metadata信息发送给Driver中的ReceiverTracker,在ReceiverTracker
内部会通过ReceivedBlockTracker来管理接受到的元数据信息
每个BatchInterval会产生一个具体的Job,其实这里的Job不是Spark Core中所指的Job,它只是基于DStreamGraph而生成的RDD
的DAG而已,从Java角度讲,相当于Runnable接口实例,此时要想运行Job需要提交给JobScheduler,在JobScheduler中通过线程池的方式找到一个
单独的线程来提交Job到集群运行(其实是在线程中基于RDD的Action触发真正的作业的运行)。
2、为什么使用线程池呢?
作业不断生成,所以为了提升效率,我们需要线程池;这和在Executor中通过线程池执行Task有异曲同工之妙;
有可能设置了Job的FAIR公平调度的方式,这个时候也需要多线程的支持;
新浪微博:http://weibo.com/ilovepains
微信公众号:DT_Spark
博客:http://blog.sina.com.cn/ilovepains
手机:18610086859
QQ:1740415547
邮箱:18610086859@vip.126.com
Spark发行版笔记3
通过案例对SparkStreaming透彻理解三板斧之三的更多相关文章
- 通过案例对SparkStreaming透彻理解三板斧之一
本节课通过二个部分阐述SparkStreaming的理解: 一.解密SparkStreaming另类在线实验 二.瞬间理解SparkStreaming本质 Spark源码定制班主要是自己做发行版.自己 ...
- 通过案例对SparkStreaming透彻理解三板斧之二
本节课主要从以下二个方面来解密SparkStreaming: 一.解密SparkStreaming运行机制 二.解密SparkStreaming架构 SparkStreaming运行时更像SparkC ...
- 通过案例对 spark streaming 透彻理解三板斧之三:spark streaming运行机制与架构
本期内容: 1. Spark Streaming Job架构与运行机制 2. Spark Streaming 容错架构与运行机制 事实上时间是不存在的,是由人的感官系统感觉时间的存在而已,是一种虚幻的 ...
- 通过案例对 spark streaming 透彻理解三板斧之一: spark streaming 另类实验
本期内容 : spark streaming另类在线实验 瞬间理解spark streaming本质 一. 我们最开始将从Spark Streaming入手 为何从Spark Streaming切入 ...
- 通过案例对 spark streaming 透彻理解三板斧之二:spark streaming运行机制
本期内容: 1. Spark Streaming架构 2. Spark Streaming运行机制 Spark大数据分析框架的核心部件: spark Core.spark Streaming流计算. ...
- 回调函数透彻理解Java
http://blog.csdn.net/allen_zhao_2012/article/details/8056665 回调函数透彻理解Java 标签: classjavastringinterfa ...
- 透彻理解Spring事务设计思想之手写实现
前言 事务,是描述一组操作的抽象,比如对数据库的一组操作,要么全部成功,要么全部失败.事务具有4个特性:Atomicity(原子性),Consistency(一致性),Isolation(隔离性),D ...
- 透彻理解Spring事务设计思想之手写实现(山东数漫江湖)
前言 事务,是描述一组操作的抽象,比如对数据库的一组操作,要么全部成功,要么全部失败.事务具有4个特性:Atomicity(原子性),Consistency(一致性),Isolation(隔离性),D ...
- Android Activity 生命周期的透彻理解
说来惭愧,虽然已经做了一年多的android开发,但是最近被人问起activity的生命周期的时候,却感觉自己并不能很自信很确定的回答对方的问题,对activity的生命周期的理解还不透彻啊. ...
随机推荐
- Windows+Git+TortoiseGit+COPSSH安装图文教程【转】
转自:http://blog.csdn.net/aaron_luchen/article/details/10498181/ Windows+Git+TortoiseGit+COPSSH 安装图文教程 ...
- Linux环境下通过ODBC访问MSSql Server
为了解决Linux系统连接MSSql Server的问题,微软为Linux系统提供了连接MSSql Server的ODBC官方驱动.通过官方驱动,Linux程序可以方便地对MSSql Server进行 ...
- linux coredump测试
1 )如何生成 coredump 文件 ? 登陆 LINUX 服务器,任意位置键入 echo "ulimit -c 1024" >> /etc/profile 退出 L ...
- 最新Python异步编程详解
我们都知道对于I/O相关的程序来说,异步编程可以大幅度的提高系统的吞吐量,因为在某个I/O操作的读写过程中,系统可以先去处理其它的操作(通常是其它的I/O操作),那么Python中是如何实现异步编程的 ...
- RedHat修改系统时区
http://blog.itpub.net/27099995/viewspace-1370723/ 今天又被开发的说服务器时间异常,时差很大.我就纳闷了,上个星期都调整过的.去查看了一下. [root ...
- 【反演复习计划】【bzoj2820】YY的GCD
这题跟2818一样的,只不过数据水一点,可以用多一个log的办法水过去…… 原题意思是求以下式子:$Ans=\sum\limits_{isprime(p)}\sum\limits_{i=1}^{a}\ ...
- 《Java编程思想》笔记 第八章 多态
1.向上转型 把子类引用当作父类引用.(子类对象赋值给父类引用) 2.绑定 确定方法属于哪个类. 3.前期绑定 程序执行前绑定. 4.后期绑定也叫动态绑定 程序运行时绑定. 5.多态 多个不同的对象对 ...
- Win 32平台SDK中的文件操作
读取文件: HANDLE hFile ; // 声明文件操作内核对象句柄 hFile = CreateFile(, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL ...
- MATLAB的cftool工具箱简介
下面,通过一个例子说明cftool可视化界面工具箱的用法. 例如,已知 x = [0 0.2 0.50.8 0.9 1.3 1.4 1.9 2.1 2.2 2.5 2.6 2.9 3.0]; y = ...
- 如何设置Google Chrome的界面显示语言
昨天不小心,把Chrome浏览器的界面语言换成了中文, 结果换不回去英文了!!! 这是为啥呀? 我本来使用的是英文界面,换成中文却不让换回原来的语言,这怎么也说不过去吧. Google了一会子也没找到 ...