关于hadoop setCombinerClass 与 setReducerClass同时使用存在的问题。
最近在学习hadoop mapreduce编程的过程中遇到一个莫名奇妙的问题。最后通过调试时发现同时使用setCombinerClass(Reducer.class) 与 setReducerClass(Reducer.class)造成的。我个人觉得这两个不能同时使用,官方给出的WordCount例子中同时使用了这两个方法,我觉得是不严谨的,下面通过实验证明。
首先,我们来了解一下 setCombinerClass 的用法

如果同时使用这两个类会造成什么问题呢?会造成你reduce 输出的key value会当成map阶段的输出key value再次输入到reduce中进行处理。下面通过实验证明。首先官方WordCount中部分代码如下:
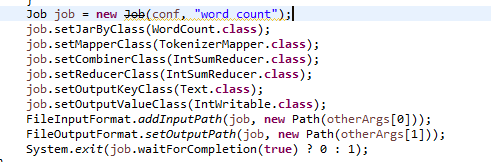
可以看到同时使用了
我们使用测试数据如下
Tom Lucy
Tom Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Ben
Jack Alice
Jack Jesse
Terry Alice
Terry Jesse
Philip Terry
Philip Alma
Mark Terry
Mark Alma
我们在reduce方法里添加一个调试信息,每次执行reduce都会输出相应的信息。

最后运行mapreduce程序。调试信息输出如下:
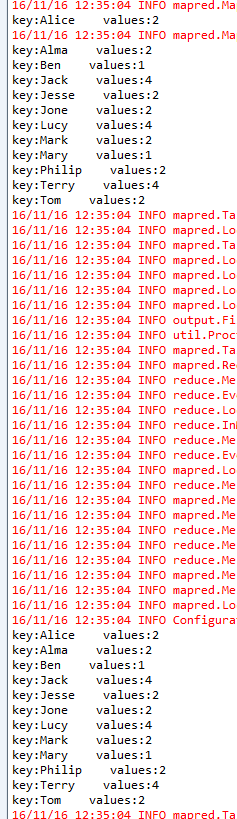
可以看见reduce执行了24次,而我们map阶段最后的key只有12个。
所以执行的流程为map(输出key--value)---->setCombinerClass(reduce)(输出key-value)---->reduce(key---value)
所以我们reduce执行了两次,第一次执行Combiner reduce的输入为map的输出,第二次执行reduece的输入为第一次执行Combiner reduce的输出。
由于这个例子刚好map的输出与Combiner reduce的输出一模一样,所以对结果没有影响,但如果这两个输出不一样,就会产生错误的结果。
所以setCombinerClass 与 setReducerClass同时只能使用一个。
关于hadoop setCombinerClass 与 setReducerClass同时使用存在的问题。的更多相关文章
- 吴裕雄--天生自然HADOOP操作实验学习笔记:pig简介
实验目的 了解pig的该概念和原理 了解pig的思想和用途 了解pig与hadoop的关系 实验原理 1.Pig 相比Java的MapReduce API,Pig为大型数据集的处理提供了更高层次的抽象 ...
- [Hadoop in Action] 第6章 编程实践
Hadoop程序开发的独门绝技 在本地,伪分布和全分布模式下调试程序 程序输出的完整性检查和回归测试 日志和监控 性能调优 1.开发MapReduce程序 [本地模式] 本地模式 ...
- 初识Hadoop
第一部分: 初识Hadoop 一. 谁说大象不能跳舞 业务数据越来越多,用关系型数据库来存储和处理数据越来越感觉吃力,一个查询或者一个导出,要执行很长 ...
- [hadoop in Action] 第3章 Hadoop组件
管理HDFS中的文件 分析MapReduce框架中的组件 读写输入输出数据 1.HDFS文件操作 [命令行方式] Hadoop的文件命令采取的形式为: hadoop fs -cmd < ...
- [Hadoop in Action] 第1章 Hadoop简介
编写可扩展.分布式的数据密集型程序和基础知识 理解Hadoop和MapReduce 编写和运行一个基本的MapReduce程序 1.什么是Hadoop Hadoop是一个开源的框架,可编写和运 ...
- [Hadoop]-从数据去重认识MapReduce
这学期刚好开了一门大数据的课,就是完完全全简简单单的介绍的那种,然后就接触到这里面最被人熟知的Hadoop了.看了官网的教程[吐槽一下,果然英语还是很重要!],嗯啊,一知半解地搭建了本地和伪分布式的, ...
- Hadoop 全分布模式 平台搭建
现将博客搬家至CSDN,博主改去CSDN玩玩~ 传送门:http://blog.csdn.net/sinat_28177969/article/details/54138163 Ps:主要答疑区在本帖 ...
- Hadoop学习笔记—9.Partitioner与自定义Partitioner
一.初步探索Partitioner 1.1 再次回顾Map阶段五大步骤 在第四篇博文<初识MapReduce>中,我们认识了MapReduce的八大步凑,其中在Map阶段总共五个步骤,如下 ...
- 第一个hadoop 程序
首先检查hadoop是否安装并配置正确然后建立WordCount.java文件里面保存package org.myorg; import java.io.IOException;import java ...
随机推荐
- bin/mysqld: error while loading shared libraries: libnuma.so.1: 安装mysql
如果安装mysql出现了以上的报错信息.这是却少numactl这个时候如果是Centos就yum -y install numactl就可以解决这个问题了. ubuntu的就sudo apt-get ...
- poj 3270(置换 循环)
经典的题目,主要还是考思维,之前在想的时候只想到了在一个循环中,每次都用最小的来交换,结果忽略了一种情况,还可以选所有数中最小的来交换一个循环. Cow Sorting Time Limit: 200 ...
- 【BZOJ4771】七彩树 主席树+树链的并
[BZOJ4771]七彩树 Description 给定一棵n个点的有根树,编号依次为1到n,其中1号点是根节点.每个节点都被染上了某一种颜色,其中第i个节点的颜色为c[i].如果c[i]=c[j], ...
- 安装IntelliJ IDEA 破解安装
IDEA 功能介绍 1-深度智力 IntelliJ IDEA为您的源代码编制索引后,通过在每个环境中提供相关建议,提供快速,智能的体验:即时和智能的代码完成,即时代码分析和可靠的重构工具. 2-开箱即 ...
- java.sql.SQLException: The user specified as a definer ('root'@'%') does not exist
权限问题,授权给 root 所有sql 权限 在Navicat for MySQL中按F6进入命令列界面 mysql> grant all privileges on *.* to root@& ...
- Mapinfo修改道路方向
在mapinfp工具管理添加插件Reverse Line Direction,就可以修改道路方向 插件
- Loadrunder之脚本篇——关联
关联的原理 关联也属于一钟特殊的参数化.一般参数化的参数来源于一个文件.一个定义的table.通过sql写的一个结果集等,但关联所获得的参数是服务器响应请求所返回的一个符合条件的.动态的值. 例子:常 ...
- Understanding When to use RabbitMQ or Apache Kafka
https://content.pivotal.io/rabbitmq/understanding-when-to-use-rabbitmq-or-apache-kafka How do humans ...
- SM3算法
/* * sm3.h * * 为使此算法兼容32位.64位下Linux或Windows系统, * 选择 int 来表示 32 位整数. * 消息长度最大限定为 2**32 - 1(单位:比特), * ...
- Vuex mapGetters,mapActions
一.基本用法 1. 初始化并创建一个项目 ? 1 2 3 vue init webpack-simple vuex-demo cd vuex-demo npm install 2. 安装 vuex ? ...