聚类 高维聚类 聚类评估标准 EM模型聚类
高维数据的聚类分析
高维聚类研究方向
高维数据聚类的难点在于:
1、适用于普通集合的聚类算法,在高维数据集合中效率极低
2、由于高维空间的稀疏性以及最近邻特性,高维的空间中基本不存在数据簇。
在高维聚类的研究中有如下几个研究重点:
1)维度约简,主要分为特征变换和特征选择两大类。前者是对特征空间的变换映射,常见的有PCA、SVD等。后者则是选择特征的子集,常见的搜索方式有自顶向下、随机搜索等;(降维)
2)高维聚类算法,主要分为高维全空间聚类和子空间聚类算法。前者的研究主要聚焦在对传统聚类算法的优化改进上,后者则可以看做维度约简的推广;
子空间聚类:
特征选择算法综述:http://www.cnblogs.com/heaad/archive/2011/01/02/1924088.html
不同的簇对应不同的子空间,并且每个子空间维数不同,因此也不可能一个子空间就可以发现所有的簇。选取与给定簇密切相关的维,然后在对应的子空间进行聚类。子空间聚类需要自定义一种搜索策略和评测标准来筛选出需要聚类的簇
传统的特征选择算法可以用来确定相关维。
CLIQUE算法(综合了基于密度和基于网格的算法)
CLIQUE把每个维划分成不重叠的区间,从而把数据对象的整个嵌入空间划分成单元。它使用一个密度阈值识别稠密单元和稀疏单元。如果映射到它的对象数超过该密度阈值,则这个单元是稠密的。
CLIQUE通过两个阶段进行聚类。在第一阶段,CLIQUE把d-维数据空间划分若干互不重叠的矩形单元,并且从中识别出稠密单元。CLIQUE在所有的子空间中发现稠密单元。
为了做到这一点,CLIQUE把每个维都划分成区间,并识别至少包含l个点的区间,其中l是密度阈值。
然后,CLIQUE迭代地连接子空间.CLIQUE检查中的点数是否满足密度阈值。
当没有候选产生或候选都不稠密时,迭代终止。
在第二阶段中,CLIQUE使用每个子空间中的稠密单元来装配可能具有任意形状的簇。其思想是利用最小描述长度(MDL)原理,使用最大区域来覆盖连接的稠密单元,其中最大区域是一个超矩形,落人该区域中的每个单元都是稠密的,并且该区域在该子空间的任何维上都不能再扩展。一般地找出簇的最佳描述是NP一困难的。因此,CLIQUE采用了一种简单的贪心方法。它从一个任意稠密单元开始,找出覆盖该单元的最大区域,然后在尚未被覆盖的剩余的稠密单元上继续这一过程。当所有稠密单元都被覆盖时,贪心方法终止。
简单说:
对每个属性进行 N等分, 整个数据空间就被划分为一个超长方体集合, 对每个单元进行数据点计数, 大于某个阈值 S 的单元称为稠密单元, 然后对稠密单元进行连接就构成类. 不同于其它方法, 它可以自动地识别嵌入在数据子空间中的类
子空间聚类与基于降维的聚类对比
子空间聚类从某种程度上来讲与基于降维的聚类有些类似,但后者是通过直接的降维来对高维数据进行预处理,即在降维之后的某一个特定的低维空间中进行聚类处理;而前者是把高维数据划分成若干不同的子空间,再根据需要在不同的子空间中寻求数据的聚类。
子空间聚类算法拓展了特征选择的任务,尝试在相同数据集的不同子空间上发现聚类。和特征选择一样,子空间聚类需要使用一种搜索策略和评测标准来筛选出需要聚类的簇,不过考虑到不同簇存在于不同的子空间,需要对评测标准做一些限制。
3)聚类有效性,是对量化评估方法的研究;
基于降维的聚类从根本上说都是以数据之间的距离 或相似度评价为聚类依据,当数据的维数不是很高时,这些方法效果较好,但当数据维度增高,聚类处理将很难达到预期的 效果。 原因在于:
a)在一个很高维的空间中定义一个距离度量本身就是一个很困难的事情;
b)基于距离的方法通常需要计算各个聚类之间的距离均值,当数据的维度很高时,不同聚类之间的距离差异将会变得很小。
4)聚类结果表示方法;
5)高维数据索引结构;
6)高维离群点的研究
笔记︱多种常见聚类模型以及分群质量评估(聚类注意事项、使用技巧)
一、聚类分析的距离问题
聚类分析的目的就是让类群内观测的距离最近,同时不同群体之间的距离最大。
1.样本聚类距离以及标准化
几种常见的距离,欧氏距离、绝对值距离、明氏距离、马氏距离。与前面不同的是,概率分布的距离衡量,K-L距离代表P、Q概率分布差的期望。
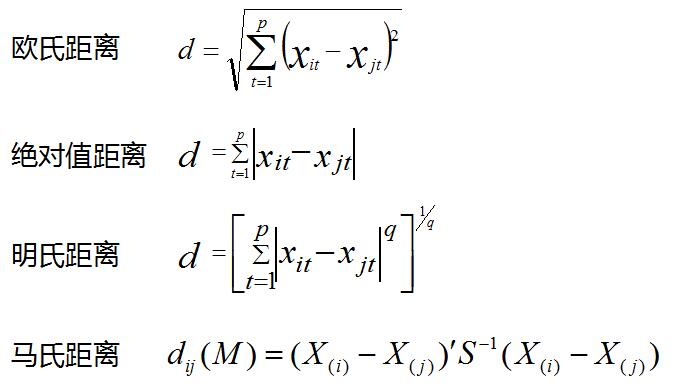

一般来说,聚类分析的数据都会进行标准化,标准化是因为聚类数据会受数据的量纲影响。
在以上的几个距离明氏距离受量纲影响较大。马氏距离受量纲影响较小
还有cos(余弦相似性)余弦值的范围在[-1,1]之间,值越趋近于1,代表两个向量的方向越趋近于0,他们的方向更加一致。相应的相似度也越高(cos距离可以用在文本挖掘,文本词向量距离之上)。
几种标准化的方法,有规范化、标准化(R语言︱数据规范化、归一化)
2.不同类型变量距离计算
算法杂货铺——k均值聚类(K-means)
1、标量:欧几里得距离 曼哈顿距离 闵可夫斯基距离 标准化
标量也就是无方向意义的数字,也叫标度变量。现在先考虑元素的所有特征属性都是标量的情况。例如,计算X={2,1,102}和Y={1,3,2}的相异度。一种很自然的想法是用两者的欧几里得距离来作为相异度,欧几里得距离的定义如下:
其意义就是两个元素在欧氏空间中的集合距离,因为其直观易懂且可解释性强,被广泛用于标识两个标量元素的相异度。将上面两个示例数据代入公式,可得两者的欧氏距离为:
除欧氏距离外,常用作度量标量相异度的还有曼哈顿距离和闵可夫斯基距离,两者定义如下:
曼哈顿距离:
闵可夫斯基距离:
欧氏距离和曼哈顿距离可以看做是闵可夫斯基距离在p=2和p=1下的特例。另外这三种距离都可以加权,这个很容易理解,不再赘述。
下面要说一下标量的规格化问题。上面这样计算相异度的方式有一点问题,就是取值范围大的属性对距离的影响高于取值范围小的属性。例如上述例子中第三个属性的取值跨度远大于前两个,这样不利于真实反映真实的相异度,为了解决这个问题,一般要对属性值进行规格化。所谓规格化就是将各个属性值按比例映射到相同的取值区间,这样是为了平衡各个属性对距离的影响。通常将各个属性均映射到[0,1]区间,映射公式为:
其中max(ai)和min(ai)表示所有元素项中第i个属性的最大值和最小值。例如,将示例中的元素规格化到[0,1]区间后,就变成了X’={1,0,1},Y’={0,1,0},重新计算欧氏距离约为1.732。
2、二元变量:相同序位同值属性的比例 Jaccard系数
所谓二元变量是只能取0和1两种值变量,有点类似布尔值,通常用来标识是或不是这种二值属性。对于二元变量,上一节提到的距离不能很好标识其相异度,我们需要一种更适合的标识。一种常用的方法是用元素相同序位同值属性的比例来标识其相异度。
设有X={1,0,0,0,1,0,1,1},Y={0,0,0,1,1,1,1,1},可以看到,两个元素第2、3、5、7和8个属性取值相同,而第1、4和6个取值不同,那么相异度可以标识为3/8=0.375。一般的,对于二元变量,相异度可用“取值不同的同位属性数/单个元素的属性位数”标识。
上面所说的相异度应该叫做对称二元相异度。现实中还有一种情况,就是我们只关心两者都取1的情况,而认为两者都取0的属性并不意味着两者更相似。例如在根据病情对病人聚类时,如果两个人都患有肺癌,我们认为两个人增强了相似度,但如果两个人都没患肺癌,并不觉得这加强了两人的相似性,在这种情况下,改用“取值不同的同位属性数/(单个元素的属性位数-同取0的位数)”来标识相异度,这叫做非对称二元相异度。如果用1减去非对称二元相异度,则得到非对称二元相似度,也叫Jaccard系数,是一个非常重要的概念。
3、分类变量
分类变量是二元变量的推广,类似于程序中的枚举变量,但各个值没有数字或序数意义,如颜色、民族等等,对于分类变量,用“取值不同的同位属性数/单个元素的全部属性数”来标识其相异度。
4、序数变量:转成标量
序数变量是具有序数意义的分类变量,通常可以按照一定顺序意义排列,如冠军、亚军和季军。对于序数变量,一般为每个值分配一个数,叫做这个值的秩,然后以秩代替原值当做标量属性计算相异度。
5、向量:余弦相似度
对于向量,由于它不仅有大小而且有方向,所以闵可夫斯基距离不是度量其相异度的好办法,一种流行的做法是用两个向量的余弦度量,其度量公式为:
其中||X||表示X的欧几里得范数。要注意,余弦度量度量的不是两者的相异度,而是相似度!
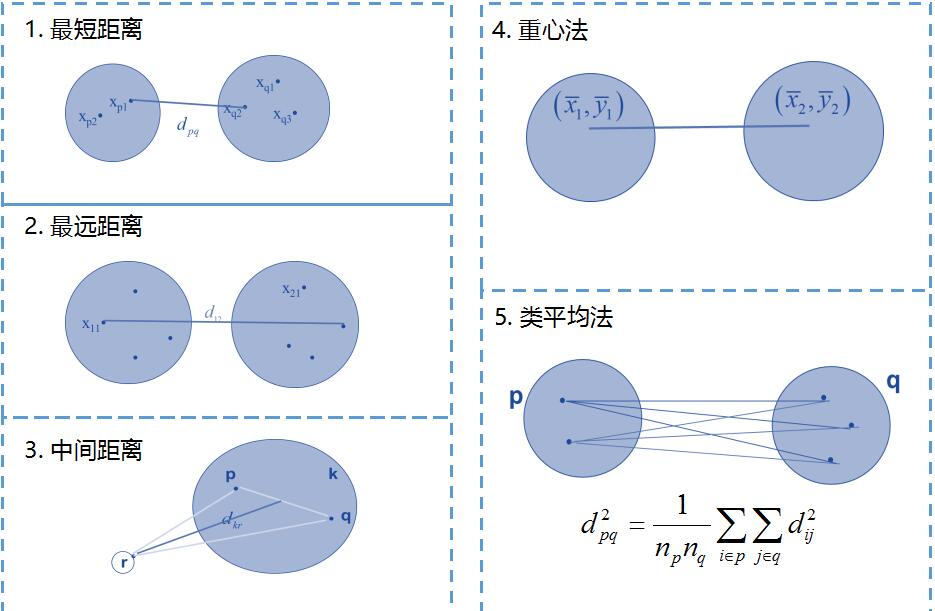
3.群体聚类距离
前面是样本之间的距离,如果是一个点集,群落,如何定义群体距离。一般有以下几种距离。
二.EM聚类
KMEANS注意点
1.K均值聚类算法对离群值最敏感,因为它使用集群数据点的平均值来查找集群的中心。
在数据包含异常值、数据点在数据空间上的密度扩展具有差异、数据点为非凹形状的情况下,K均值聚类算法的运行结果不佳。
2.K均值对簇中心初始化非常敏感。
高斯混合模型聚类算法
- 猜测有几个类别,既有几个高斯分布。
- 针对每一个高斯分布,随机给其均值和方差进行赋值。
- 针对每一个样本,计算其在各个高斯分布下的概率。
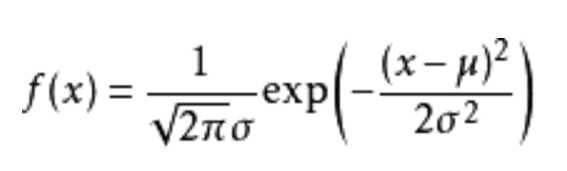
注:当高斯混合模型的特征值维数大于一维时,在计算加权的时候还要计算协方差,即要考虑不同维度之间的相互关联。
- 分类受初始值的影响
- 可能限于局部最优解
- 类别的个数只能靠猜测 (有K越大MAP最大后验概率越大的趋势)
- K-means是硬分类,要么属于这类,要么属于那类,而高斯混合式软分类,一个样本60%属于A,40% 属于B。
- 多维的时候高斯混合在计算均值和方差时使用了协方差,应用了不同维度之间的相互约束关系。
三.常见聚类模型的比较
|
K-means |
层次聚类 |
EM模型聚类 |
|
|
优点 |
属于快速聚类,计算效率高 |
1、能够展现数据层次结构,易于理解 2、可以基于层次事后再选择类的个数(根据数据选择类,但是数据量大,速度慢) |
相比其他方法能够拟合多种形状的类 |
|
缺点 |
1、需要实现指定类的个数(需要指定类) 2、有时会不稳定,陷入局部收敛 |
1、计算量比较大,不适合样本量大的情形 2、较多用于宏观综合评价 |
需要事先指定类的个数和初始分布 |
分群指标详细说明:7.9 聚类模型评估
四.聚类分群的数量如何确定?分群效果如何评价?
没有固定标准,一般会3-10分群。或者用一些指标评价,然后交叉验证不同群的分群指标。
一般的指标:轮廓系数silhouette(-1,1之间,值越大,聚类效果越好)(fpc包),兰德指数rand;R语言中有一个包用30种方法来评价不同类的方法(NbClust),但是速度较慢。既可以确定分群数量,也可以评价聚类质量
商业上的指标:分群结果的覆盖率;分群结果的稳定性;分群结果是否从商业上易于理解和执行
1 . 兰德指数 需要标签
兰德指数(Rand index)需要给定实际类别信息$C$,假设$K$是聚类结果,$a$表示在$C$与$K$中都是同类别的元素对数,$b$表示在$C$与$K$中都是不同类别的元素对数,则兰德指数为:
${\rm RI}=\frac{a+b}{C_2^{n_{\rm samples}}}$,
对于以上公式,
- 分子:属性一致的样本数,即同属于这一类或都不属于这一类。a是真实在同一类、预测也在同一类的样本数;b是真实在不同类、预测也在不同类的样本数;
- 分母:任意两个样本为一类有多少种组合,是数据集中可以组成的总元素对数;
- RI取值范围为[0,1],值越大意味着聚类结果与真实情况越吻合。
对于随机结果,RI并不能保证分数接近零。为了实现“在聚类结果随机产生的情况下,指标应该接近零”,调整兰德系数(Adjusted rand index)被提出,它具有更高的区分度:
${\rm ARI}=\frac{{\rm RI}-E[{\rm RI}]}{\max({\rm RI})-E[{\rm RI}]}$,
具体计算方式参见Adjusted Rand index。
ARI取值范围为$[-1,1]$,值越大意味着聚类结果与真实情况越吻合。从广义的角度来讲,ARI衡量的是两个数据分布的吻合程度。
2. 互信息 需要标签、先验知识
互信息(Mutual Information)也是用来衡量两个数据分布的吻合程度。假设$U$与$V$是对$N$个样本标签的分配情况,则两种分布的熵(熵表示的是不确定程度)分别为:
$H(U)=\sum\limits_{i=1}^{|U|}P(i)\log (P(i)), H(V)=\sum\limits_{j=1}^{|V|}P'(j)\log (P'(j))$,
其中$P(i)=|U_i|/N,P'(j)=|V_j|/N$。$U$与$V$之间的互信息(MI)定义为:
${\rm MI}(U,V)=\sum\limits_{i=1}^{|U|}\sum\limits_{j=1}^{|V|}P(i,j)\log\left ( \frac{P(i,j)}{P(i)P'(j)}\right )$,
其中$P(i,j)=|U_i\bigcap V_j|/N$。标准化后的互信息(Normalized mutual information)为:
${\rm NMI}(U,V)=\frac{{\rm MI}(U,V)}{\sqrt{H(U)H(V)}}$。
与ARI类似,调整互信息(Adjusted mutual information)定义为:
${\rm AMI}=\frac{{\rm MI}-E[{\rm MI}]}{\max(H(U), H(V))-E[{\rm MI}]}$。
利用基于互信息的方法来衡量聚类效果需要实际类别信息,MI与NMI取值范围为$[0,1]$,AMI取值范围为$[-1,1]$,它们都是值越大意味着聚类结果与真实情况越吻合。
3. 轮廓系数
轮廓系数旨在将某个对象与自己的簇的相似程度和与其他簇的相似程度进行比较。轮廓系数最高的簇的数量表示簇的数量的最佳选择。
轮廓系数(Silhouette coefficient)适用于实际类别信息未知的情况。对于单个样本,设$a$是与它同类别中其他样本的平均距离,$b$是与它距离最近不同类别中样本的平均距离,轮廓系数为:
$s=\frac{b-a}{\max(a,b)}$。
对于一个样本集合,它的轮廓系数是所有样本轮廓系数的平均值。
轮廓系数取值范围是$[-1,1]$,同类别样本越距离相近且不同类别样本距离越远,分数越高。
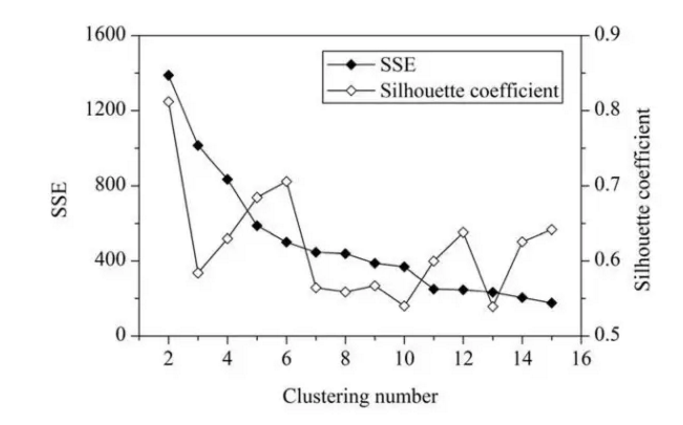
一般来说,平均轮廓系数越高,聚类的质量也相对较好。在这,对于研究区域的网格单元,最优聚类数应该是2,这时平均轮廓系数的值最高。但是,聚类结果(k=2)的 SSE 值太大了。当 k=6 时,SEE 的值会低很多,但此时平均轮廓系数的值非常高,仅仅比 k=2 时的值低一点。因此,k=6 是最佳的选择。
五、kmeans时候出现的超级大群现象,如何解决?
kmeans做聚类的时候,往往会出现一个超级大群,一类样本数据很多很多,其他类别数量很少。两极分化很严重。在实际使用的时候会出现以下这几个问题:
80%的数据分布在1%的空间内,而剩下的20%的数据分布在99%的空间内。聚类时,分布在1%空间内的大部分数据会被聚为一类,剩下的聚为一类。当不断增加K值时,模型一般是对99%空间内的数据不断进行细分,因为这些数据之间的空间距离比较大。
而对分布在1%空间内的数据则很难进一步细分,或者即使细分了,也只是剥离出了外侧少量数据。下图是我们在某个项目中的聚类结果,可以看到有一类用户占了90%以上,而且随着K的增加,这类用户里只有很小一部分数据会被划分出来。
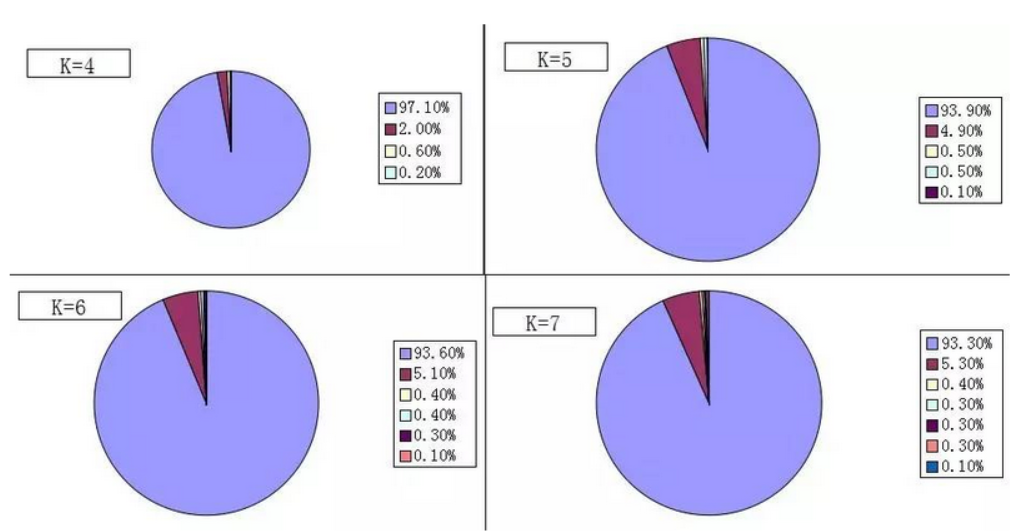
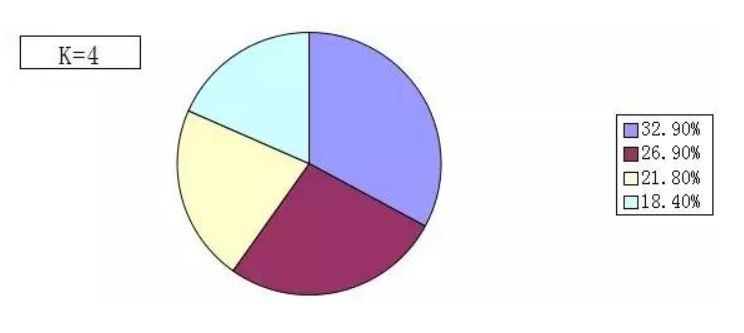
解决办法:那么为了解决这个问题,一种可行的方法是是对特征取LOG,减轻长尾问题。经过这两种方法处理后,都能较好的对玩家进行分类。下图是上图中的数据点取LOG后得到的分布图。
缺点:取LOG的方法的缺点在于,会使数据变得不直观,不好理解。
DBSCAN
k-dist
另外,DBSCAN要求用户指定一个全局参数Eps(为了减少计算量,预先确定参数 Minpts)。为了确定取值,DBSCAN计算任意对象与它的第k个最临近的对象之间的距离。然后,根据求得的距离由小到大排序,并绘出排序后的图,称做k-dist图。k-dist图中的横坐标表示数据对象与它的第k个最近的对象间的距离;纵坐标为对应于某一k-dist距离值的数据对象的个数。
R-树
为了有效地执行区域查询,DBSCAN算法使用了空间查 询R-树结构。在进行聚类前,必须建立针对所有数据的R*-树。
聚类 高维聚类 聚类评估标准 EM模型聚类的更多相关文章
- ML: 聚类算法R包 - 模型聚类
模型聚类 mclust::Mclust RWeka::Cobweb mclust::Mclust EM算法也称为期望最大化算法,在是使用该算法聚类时,将数据集看作一个有隐形变量的概率模型,并实现模型最 ...
- R_Studio(聚类)针对iris数据比较几种聚类方法优劣
聚类分析 百度百科:传送门 聚类分析指将物理或抽象对象的集合分组为由类似的对象组成的多个类的分析过程 聚类与分类的不同在于,聚类所要求划分的类是未知的 聚类分析是一种探索性的分析,在分类的过程中,人们 ...
- 聚类之高斯混合模型与EM算法
一.高斯混合模型概述 1.公式 高斯混合模型是指具有如下形式的概率分布模型: 其中,αk≥0,且∑αk=1,是每一个高斯分布的权重.Ø(y|θk)是第k个高斯分布的概率密度,被称为第k个分模型,参数为 ...
- PolyCluster: Minimum Fragment Disagreement Clustering for Polyploid Phasing 多聚类:用于多倍体的最小碎片不一致聚类
摘要 分型是计算生物学的一个新兴领域,在临床决策和生物医学科学中有着重要的应用. 虽然机器学习技术在许多生物医学应用中显示出巨大的潜力,但它们在分型中的用途尚未完全理解. 在本文中,我们研究了基于聚类 ...
- 聚类算法:K均值、凝聚层次聚类和DBSCAN
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- Matlab中K-means聚类算法的使用(K-均值聚类)
K-means聚类算法采用的是将N*P的矩阵X划分为K个类,使得类内对象之间的距离最大,而类之间的距离最小. 使用方法:Idx=Kmeans(X,K)[Idx,C]=Kmeans(X,K) [Idx, ...
- 常见聚类算法——K均值、凝聚层次聚类和DBSCAN比较
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- Python数模笔记-Sklearn(2)样本聚类分析
1.分类的分类 分类的分类?没错,分类也有不同的种类,而且在数学建模.机器学习领域常常被混淆. 首先我们谈谈有监督学习(Supervised learning)和无监督学习(Unsupervised ...
- 聚类:层次聚类、基于划分的聚类(k-means)、基于密度的聚类、基于模型的聚类
一.层次聚类 1.层次聚类的原理及分类 1)层次法(Hierarchicalmethods)先计算样本之间的距离.每次将距离最近的点合并到同一个类.然后,再计算类与类之间的距离,将距离最近的类合并为一 ...
随机推荐
- 最大流EK算法/DINIC算法学习
之前一直觉得很难,没学过网络流,毕竟是基础知识现在重新来看. 定义一下网络流问题,就是在一幅有向图中,每条边有两个属性,一个是cap表示容量,一个是flow 表示流过的流量.我们要求解的问题就是从S点 ...
- 使用cqlsh远程连接cassandra——设置cassandra.yaml里rpc_address和listen_address为ipv4地址即可
You need to edit cassandra.yaml on the node you are trying to connect to and set the node ip address ...
- scorm标准的LMS在客户端的运行机制
1)运行SCORM APIAdapter. 2)调用API初始化函数. 3)加载课件SCO初始化数据. 4)获取Data Model中的用户ID和用户姓名. 5)获取Data Mode ...
- 阿里maven镜像服务器配置
把下面的配置复制到 .m2/settings.xml配置文件中. <?xml version="1.0" encoding="UTF-8"?> &l ...
- jdk1.8 HashMap 实现 数组+链表/红黑树
转载至 http://www.cnblogs.com/leesf456/p/5242233.html 一.前言 在分析jdk1.8后的HashMap源码时,发现网上好多分析都是基于之前的jdk,而Ja ...
- 部署tinyproxy透明代理服务
线上需要一个https的透明代理,开始打算用nginx,调试了一段时间发现配置较复杂且没有成功.后来用的tinyproxy做的透明代理.安装配置过程就是下载.解压.编译.安装.配置.启动一波流: 安装 ...
- bzoj 4998 星球联盟
新技能 get √ :LCT 维护边双连通分量 这题题意就是动态加边,每次求边的两端是否在一个边双连通分量里,输出 "No" 或者边双连通分量的大小 可以用两个并查集分别记录连通性 ...
- MYSQL 级联 添加外键
MySQL支持外键的存储引擎只有InnoDB,在创建外键的时候,要求父表必须有对应的索引,子表在创建外键的时候也会自动创建对应的索引.在创建索引的时候,可以指定在删除.更新父表时,对子表进行的相应操作 ...
- noip济南清北冲刺班DAY1
上午 T1 立方数 题目描述 LYK定义了一个数叫“立方数”,若一个数可以被写作是一个正整数的3次方,则这个数就是立方数,例如1,8,27就是最小的3个立方数. 现在给定一个数P,LYK想要知道这个数 ...
- RESTful Get方式传参json格式后端400 解决方案
前端采用vue+axios 后端采用spring boot restful 问题: 前端get 请求需要传递array 字段值 后端由于tomcat 版本问题,不支持url接受特殊字符包括 [] {} ...