Hive的一些理解
首先谈一下关于hive和hbase的区别的疑问(完全不是一个东西):
本质上来说hive和hbase没什么关系,虽然都是表,查数据等,但是他们根本就不是一个层面的东西
hive就是一个rapduce的一个包装,hive就是将编写的sql转换成mapreduce任务
而hbase是什么呢?可以理解为是hdfs的一个包装,本质是数据存储的,一个nosql数据库,部署与hdfs之上的,目的是克服hdfs在随机读写上的缺点
你非得问hive和hbase有什么区别,那就相当于问mapreduce和hdfs有什么区别,所有谈他们的区别完全没有任何的意义
引入Hive原因:
– 对存在HDFS上的文件或HBase中的表进行查询时,是要手工写一堆MapReduce代码
– 对于统计任务,只能由动MapReduce的程序员才能搞定
Hive基于一个统一的查询分析层,通过SQL语句的方式对HDFS上的数据进行查询、统计和分析
由此可以看出来hive适合做数据查询、统计和分析,使用SQL语句(但是,hive的sql并不是一个标准的sql,只是类似于一个标准的sql,但不等价于一个标准的sql)对HDFS进行查询(mapreduce也是对HDFS进行查询等工作,所以hive本身并不会存储数据)
Hive到底是什么?
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为mapreduce任务进行运行。
Hive中的表是纯逻辑表,就只是表的定义等,即表的元数据。本质就是Hadoop的目录/文件,达到了元数据与数据存储分离的目的
Hive本身不存储数据,它完全依赖HDFS和MapReduce
Hive的内容是读多写少,不支持对数据的改写和删除(0.14版本以后支持更新,但是得开启,默认关闭。由此可见hive不适合更新,因为hdfs也不适合修改!hdfs数据要修改,要么就是删除,要么就是追加,考虑到性能,大数据不建议频繁修改和删除)
Hive中没有定义专门的数据格式,由用户指定,需要指定三个属性:
– 列分隔符 : 空格, \t , \001
– 行分隔符: \n
– 读取文件数据的方法: TextFile ,SquenceFile,RCFile
TextFile(优点:可读性好。缺点:占内存空间,磁盘开销大)--------python,Streaming开发一般是这种格式
SquenceFile(二进制,是hadoop提供的一种二进制文件,<key,value>形式序列化到文件中,Java Writeable接口进行序列化和反序列化)------java开发一般是这种格式
RCFile(是Hive专门推出的,一种面向列的数据格式)---------实际上在mapreduce的map阶段远程拷贝的时候,本质是拷贝block,但是block依然是整个的数据,block没办法具体区分哪一个列,读过来就是全读,所以性能并不一定比TextFile好
为什么选择hive?
看一个wordcount
select word,count(*) form (select exploed(sentence, ' ') as word form article) t group by word
一行sql实现了一个单词计数,大量节省开发和学习成本,而且便于修改
Hive 中 的 sql 与传统 sql 区 别:

函数:
UDF:直接应用于select语句,通常查询的时候,需要对字段做一些格式化处理(例如:大小写转换,比如表里都是小写,但是就想显示全是大写)
特点:一进一出,一对一的关系
UDAF:多对一的关系,通常用于group by阶段
UDTP:一对多
读时模式:只有hive读的时候才会检查,解析字段和schema(数据结构的表达)
优点:load data非常迅速,因为在写的过程中不需要解析数据
写时模式:
优点:读的时候会得到优化
缺点:写的慢,需要建立一些索引,压缩,数据一致性,字段检查等...
与传统关系数据特点比较:
hive和关系数据库存储文件的系统不同,hive使用的是hadoop的HDFS(hadoop的分布式文件系统),关系数据库则是服务器本地的文件系统
hive使用的计算模型是mapreduce,而关系数据库则是自己设计的计算模型
关系数据库都是为实时查询的业务进行设计的,而hive则是为海量数据做数据挖掘设计的,实时性很差
Hive很容易扩展自己的存储能力和计算能力,这个是继承hadoop的,而关系数据库在这个方面要比数据库差很多
Hive体系架构:
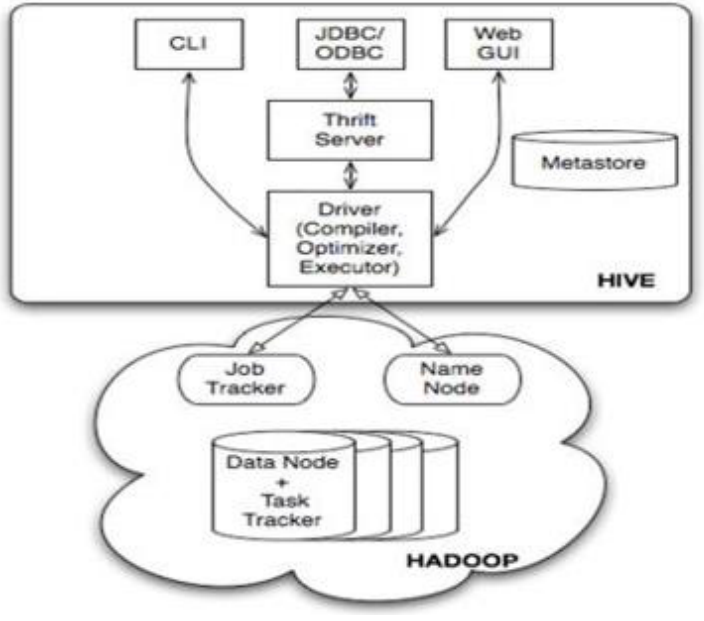
分为三个部分:
用户接口:
CLI:client(Hive 的客户端,用户连接至 Hive Server,一般是linux下)进行交互执行sql,直接与Driver进行交互。
JDBC:Hive提供JDBC驱动,作为JAVA的API:JDBC是通过Thrift Server来接入,然后发给Driver
GUI:通过浏览器访问 Hive
语句转换(Driver------->hive本身并不会生成mapreduce,而是通过一个执行计划来执行mapreduce(xml----->mapper,reducer模块)):
解析器:生成抽象语法树
语法分析器:验证查询语句
逻辑计划生成器(包括优化器):生成操作符树
查询计划生成器:转换为map-reduce任务
元数据:
metastore------>是一个独立的关系型数据库,默认的数据库是derby(单用户常用)。真正的生产都是远程服务模式----->mysql
数据存储:
Hive数据以文件形式存储在HDFS的指定目录下
Hive语句生成查询计划,由MapReduce调用执行
Hive数据管理:
hive的表本质就是Hadoop的目录/文件
– hive默认表存放路径一般都是在你工作目录的hive目录里面,按表名做文件夹分开,如果你有分区表的话,分区值是子文件夹,可以直接在其它的M/R job里直接应用这部分数据
Hive有四种数据模型:
数据表:
Table:内部表
External Table:外部表
分区表:
Partition
Bucket
Table:
和传统数据库概念基本一致,都是一个数据表,但是每一个table在hive中都会有一个目录来存取数据
例如: 有表user ,因为hive不存储数据,都是在hdfs上,所以路径就在/warehouse/user/(注意:user不是一个文件,是一个目录)
Partition:
相当于分桶
好处:通常查询的时候会扫描整个表的内容,那就会消耗很多的时间
例如:select xxx form table where date='2019-03-07' limit 100 通常查询时候都会有where条件,但是这样查询也会扫描8,9....等等的数据,但是8,9号的数据对我们要查的来说完全没有意义,我们只需要7号的数据
引入partition能大大优化性能,分区表需要在创建表的时候引入一个partition的分区的空间,一个表可以有一个或多个分区,然后以单独的文件夹的形式存在表的文件夹下面(wherehorse/user/partition)
通常什么字段能做为分区字段呢?
不是所有的字段都适合做分区
1.通常这个字段是经常在where条件中做过滤用的
2.取值范围有点集合的字段(假设用户名做分区,那将会有无数个小文件,然而小文件会占用namenode内存区域,关于hdfs为什么不适合大量存储小文件,如果有时间会写hdfs的内容)
假设要对一天的数据做统计:
那就按照天做分区 day=20190307 路径位置/warehouse/table/20190307/
查询的时候where条件就成了一个文件夹了,然后对里面的内容做查询就可以了,不用查询其他的天数了
当多个字段做分区的时候,会按照笛卡尔迪的形式 action=insight, day=20190307 路径/warehouse/table/insight/20190307
Bucket:
开启bucket:set hive.enforce.bucketing = true
Hive会针对某一个列进行桶的组织,通常对列值做hash
假设:想存userid,然后这张表太大了,但是又想存数据,又不想突破一张表的的上限
分库:把一张表拆分成多个表
例如:分32库,userid%32=桶号
表名:table
分库后表名:table_0,table_1,table_2,table_3......table_32
每张表都不会重复,因为按照userid做的分桶
路径/warehouse/table/partition/part-00000
bucket有什么作用呢?
1.优化查询
2.方便采样
假设两张表,id相同,分区相同,当做join的时候,只需要join目标id相同的分桶就可以,其他的桶不需要理会,性能大大优化
两个分区表做join,他会自动激活map端的 (map-side Join)
Hive的内部表和外部表:
内部表:create table
外部表:create external table
内部表和外部表的区别:
内部表删除,表结构和数据都删除
外部表删除,只删除表结构,不删除数据(删除外部表怎么恢复?重新创建表)
- 在导入数据到外部表,数据并没有移动到自己的数据仓库目录下,也就是说外部表中的数据并不是由它自己来管理的!而表则不一样;
- 在删除表的时候,Hive将会把属于表的元数据和数据全部删掉;而删除外部表的时候,Hive仅仅删除外部表的元数据,数据是不会删除的!
Hive的数据类型:
基础类型:
• TINYINT
• SMALLINT
• INT
• BIGINT
• BOOLEAN
• FLOAT
• DOUBLE
• STRING
• BINARY(Hive 0.8.0以上才可用)
• TIMESTAMP(Hive 0.8.0以上才可用)
复合类型:
• Arrays:ARRAY<data_type>
• Maps:MAP<primitive_type, data_type>
• Structs:STRUCT<col_name: data_type[COMMENT col_comment],……>
• Union:UNIONTYPE<data_type, data_type,……>
Hive的一些理解的更多相关文章
- 对于HIVE架构的理解
1.Hive 能做什么,与 MapReduce 相比优势在哪里 关于hive这个工具,hive学习成本低,入手快,对于熟悉sql语法的人来说,操作简单,熟悉. 2.为什么说 Hive 是 Hadoo ...
- hive的简单理解--笔记
Hive的理解 数据仓库的工具 Hive仅仅是在hadoop上面包装了SQL: Hive的数据存储在hadoop上 Hive的计算由MR进行 Hive批量处理数据 Hive的特点 1 可扩展性(h ...
- hive:框架理解
1. 什么是hive •Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能. •本质是将HQL转换为MapReduce程序 2. 为什么 ...
- 037 对于HIVE架构的理解
0.发展 在hive公布源代码之后 公司又公布了presto,这个比较快,是基于内存的. impala:3s处理1PB数据. 1.Hive 能做什么,与 MapReduce 相比优势在哪里 关于hi ...
- hive的初步认识与hive的本质
Hive是什么?就从这儿开始学习.... Hive是建立在Hadoop hdfs上的数据仓库基础架构. Hive可以用来数据抽取转换加载(ETL). Hive定义了简单的类SQL查询语句,称为HQL. ...
- Hive UDAF开发详解
说明 这篇文章是来自Hadoop Hive UDAF Tutorial - Extending Hive with Aggregation Functions:的不严格翻译,因为翻译的文章示例写得比较 ...
- Hbase—学习笔记(一)
此文的目的: 1.重点理解Hbase的整体工作机制 2.熟悉编程api,能够用来写程序 1. 什么是HBASE 1.1. 概念特性 HBASE是一个数据库----可以提供数据的实时随机读写 HB ...
- 大数据核心知识点:Hbase、Spark、Hive、MapReduce概念理解,特点及机制
今天,上海尚学堂大数据培训班毕业的一位学生去参加易普软件公司面试,应聘的职位是大数据开发.面试官问了他10个问题,主要集中在Hbase.Spark.Hive和MapReduce上,基础概念.特点.应用 ...
- hdfs数据到hive中,以及hdfs数据隐身理解
hdfs数据到hive中: 假设hdfs中已存在好了数据,路径是hdfs:/localhost:9000/user/user_w/hive_g2park/user_center_enterprise_ ...
随机推荐
- MySQL crash-safe replication(1)
MySQL 5.6 对复制功能提供了新特性:slave 支持 crash-safe,可以解决之前版本中系统异常断电可能导致的 SQL thread 信息不准确的问题. 原文:Enabling cras ...
- 转:HttpModule与HttpHandler详解
ASP.NET对请求处理的过程:当请求一个*.aspx文件的时候,这个请求会被inetinfo.exe进程截获,它判断文件的后缀(aspx)之后,将这个请求转交给 ASPNET_ISAPI.dll,A ...
- Android 增加JNI
Android:JNI 与 NDK到底是什么?(含实例教学) 前言 在android开发中,使用NDK开发的需求正逐渐增大: 很多人搞不懂JNI与NDK到底是怎么回事? 今天我们先介绍JNI与NDK之 ...
- 第六次作业 orm整合 接口
结合以前一个项目,将普通的jdbc进行了相关整合,全部改写成了hibernate接口 项目名称:短视频分享平台 主要功能:用户模块:注册.登录.编辑资料.查看用户相关 分类模块:分类添加.查看 视频共 ...
- fedora安装字体
#fedora安装新字体 将自己现有的字体复制到/usr/share/fonts/自己起个名字/ 例如我要安装下载的苹果苹方字体 #cp 我这个文件夹的地址/* /usr/share/fonts/Pi ...
- MySQL并发相关的参数
1.max_connections 这个参数可提高并发连接数,即允许连接到MySQL数据库的最大数量. 如果实验MySQL过程中遇到too many connections等问题,可提高这个值,此外我 ...
- PgSQL基础之 安装postgresql数据系统
参考这位仁兄的文章,真的非常好:https://blog.csdn.net/jerry_sc/article/details/76408116#创建数据目录 后来我又自己写了一个shell脚本,来自动 ...
- node+koa中转层开发实践总结
node中转层的意义: 1.能解决前后端代码部署在不同服务器下时的跨域问题.(实现) 2.合并请求,业务逻辑处理.(实现) 3.单页应用的首屏服务端渲染.(暂未实现) 环境准备: node: ^8.1 ...
- Tensorflow Object Detection API 安装
git:https://github.com/tensorflow/models/tree/master/object_detection 中文文档:http://wiki.jikexueyuan.c ...
- 随手练——HDU 1078 FatMouse and Cheese(记忆化搜索)
http://acm.hdu.edu.cn/showproblem.php?pid=1078 题意: 一张n*n的格子表格,每个格子里有个数,每次能够水平或竖直走k个格子,允许上下左右走,每次走的格子 ...