20-hadoop-pagerank的计算
转: http://www.cnblogs.com/rubinorth/p/5799848.html
参考尚学堂视频
1, 概念( 来自百度百科)
PageRank是Google专有的算法,用于衡量特定网页相对于搜索引擎索引中的其他网页而言的重要程度。它由Larry Page 和 Sergey Brin在20世纪90年代后期发明。PageRank实现了将链接价值概念作为排名因素。

), 入链 == 投票 让链接投票, 到一个页面的超链(入链)就是一次投票 ), 入链数量越多, pr值越高 ), 入链质量越高, pr值越高
收敛计算
), 初始值
每个页面初始pr值相同
), 迭代递归(收敛)
不断的重复计算, 最后pr值趋于稳定, 就是收敛
a), 绝对收敛: 每个页面的pr值和上一次的pr值相同
b), 相对收敛: 所有页面和上一次的计算pr平均差值小于收敛差值(0.0001)
c), 百分比页面(%) 和上一次计算值相同
修正的pr计算公式
由于一些页面出链为0, 对其他网页没有贡献, 于是设定所有网页都有出链, 即他自己, 因为增加阻尼系数q, 一般为 0.85
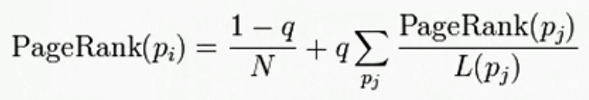
详细推导请转大牛网页: http://www.cnblogs.com/rubinorth/p/5799848.html
3, hadoop实现
1), 定义node
package com.wenbronk.pagerank; import java.io.IOException;
import java.util.Arrays; import org.apache.commons.lang.StringUtils; /**
* pageRank 工具代码
*
* @author root
*
*/
public class Node {
/** 初始值 */
private Double pageRank = 1d;
/** 出链 */
private String[] adjacentNodeNames;
public static final char fieldSeparator = '\t'; public Double getPageRank() {
return pageRank;
} public Node setPageRank(Double pageRank) {
this.pageRank = pageRank;
return this;
} public String[] getAdjacentNodeNames() {
return adjacentNodeNames;
} public Node setAdjacentNodeNames(String[] adjacentNodeNames) {
this.adjacentNodeNames = adjacentNodeNames;
return this;
} public boolean containsAdjacentNodes() {
return adjacentNodeNames != null && adjacentNodeNames.length > ;
} @Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(pageRank); if (getAdjacentNodeNames() != null) {
sb.append(fieldSeparator).append(StringUtils.join(getAdjacentNodeNames(), fieldSeparator));
}
return sb.toString();
} // value =1.0 B D
public static Node fromMR(String value) throws IOException {
String[] parts = StringUtils.splitPreserveAllTokens(value, fieldSeparator);
if (parts.length < ) {
throw new IOException("Expected 1 or more parts but received " + parts.length);
}
Node node = new Node().setPageRank(Double.valueOf(parts[]));
if (parts.length > ) {
node.setAdjacentNodeNames(Arrays.copyOfRange(parts, , parts.length));
}
return node;
} }
2, mapper
package com.wenbronk.pagerank; import java.io.IOException; import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; /**
* map
* @author wenbronk
*/
public class PageRankMapper extends Mapper<Text, Text, Text, Text> { /**
* 输入为 A: B D 第一次 A: 1 B D
*/
@Override
protected void map(Text key, Text value, Mapper<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
// 计算的次数, 通过context传入
int runCount = context.getConfiguration().getInt("runCount", );
String key_ = key.toString();
Node node = null; if (runCount == ) {
node = Node.fromMR("1.0\t" + value.toString());
} else {
node = Node.fromMR(value.toString());
}
// 有出链
if (node.containsAdjacentNodes()) {
Double outValue = node.getPageRank() / node.getAdjacentNodeNames().length; // 输出 A: 1.0 B D, 输出原始值
context.write(new Text(key_), new Text(node.toString()));
for (int i = ; i < node.getAdjacentNodeNames().length; i++) {
String outKey = node.getAdjacentNodeNames()[i];
// 输出 B: 0.5; D: 0.5;
context.write(new Text(outKey), new Text(outValue + ""));
}
} } }
3, reducer
package com.wenbronk.pagerank; import java.io.IOException; import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; /**
*
* @author wenbronk
*/
public class PageRankReducer extends Reducer<Text, Text, Text, Text>{ /**
* map 传入的数据
* 实现pageRank的算法
*/
@Override
protected void reduce(Text arg0, Iterable<Text> arg1, Reducer<Text, Text, Text, Text>.Context arg2)
throws IOException, InterruptedException { Double sum = 0d; // 原始值
Node sourceNode = null;
for (Text text : arg1) {
Node node = Node.fromMR(text.toString());
if (node.containsAdjacentNodes()) {
sourceNode = node;
}else {
sum += node.getPageRank();
}
}
// 0.85 为公式阻尼系数
Double newPR = ( - 0.85) / 4.0 + (0.85 * sum); // 原始值比较, 扩大倍数, 根据收敛值确定(0.001, 就是1000)
Double d = Math.abs((newPR - sourceNode.getPageRank()) * 1000.0);
System.err.println(d);
// 计数器, 确定最后停止标准
arg2.getCounter(Counter.Counter).increment(d.intValue()); sourceNode.setPageRank(newPR);
arg2.write(arg0, new Text(sourceNode.toString()));
} }
4, 需要用到hadoop的计数器, 定义一个枚举
package com.wenbronk.pagerank;
public enum Counter {
Counter
}
5, 执行类
package com.wenbronk.pagerank; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
*
* @author root
*/
public class PageRankMain { public static void main(String[] args) { double d =0.001; Configuration config = new Configuration();
config.set("fs.default", "hdfs://192.168.208.106:8020");
config.set("yarn.resourcemanager.hostname", "192.168.208.106"); int runCount = ;
while (true) {
runCount ++;
try {
config.setInt("runCount", runCount);
Job job = Job.getInstance(config);
job.setJobName("newPr" + runCount);
job.setJarByClass(PageRankMain.class);
job.setMapperClass(PageRankMapper.class);
job.setReducerClass(PageRankReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setInputFormatClass(KeyValueTextInputFormat.class); Path inputPath = new Path("E:\\sxt\\1-MapReduce\\data\\pagerank.txt");
if (runCount > ) {
inputPath = new Path("E:\\sxt\\1-MapReduce\\data\\pagerank" + (runCount - ));
}
FileInputFormat.addInputPath(job, inputPath); Path outPath = new Path("E:\\sxt\\1-MapReduce\\data\\pagerank" + runCount);
FileSystem fileSystem = FileSystem.get(config);
if (fileSystem.exists(outPath)) {
fileSystem.delete(outPath);
}
FileOutputFormat.setOutputPath(job, outPath);
boolean flag = job.waitForCompletion(true); if (flag) {
// hadoop自己的计数器, 使用枚举作为标记
long value = job.getCounters().findCounter(Counter.Counter).getValue();
// 根据pagerank公式, 除以4, 缩小1000倍
double avg = value / (4.0 * );
if (avg < d) {
break;
}
}
}catch (Exception e) {
e.printStackTrace();
}
}
} }
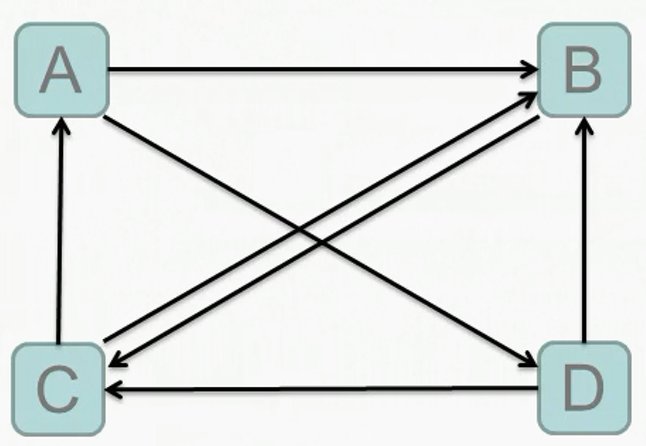
最后, 还有初始文档
A B D
B C
C A B
D B C
注: java的类型转换, 除以int或者乘int类型的结果都将是int类型, 导致reduce失败
20-hadoop-pagerank的计算的更多相关文章
- 简单的java Hadoop MapReduce程序(计算平均成绩)从打包到提交及运行
[TOC] 简单的java Hadoop MapReduce程序(计算平均成绩)从打包到提交及运行 程序源码 import java.io.IOException; import java.util. ...
- Hadoop 实现 TF-IDF 计算
学习Hadoop 实现TF-IDF 算法,使用的是CDH5.13.1 VM版本,Hadoop用的是2.6.0的jar包,Maven中增加如下即可 <dependency> <grou ...
- hadoop输入分片计算(Map Task个数的确定)
作业从JobClient端的submitJobInternal()方法提交作业的同时,调用InputFormat接口的getSplits()方法来创建split.默认是使用InputFormat的子类 ...
- 一文理解Hadoop分布式存储和计算框架入门基础
@ 目录 概述 定义 发展历史 发行版本 优势 生态项目 架构 组成模块 HDFS架构 YARN架构 部署 部署规划 前置条件 部署步骤 下载文件(三台都执行) 创建目录(三台都执行) 配置环境变量( ...
- Hadoop中MapReduce计算框架以及HDFS可以干点啥
我准备学习用hadoop来实现下面的过程: 词频统计 存储海量的视频数据 倒排索引 数据去重 数据排序 聚类分析 ============= 先写这么多
- PageRank在Hadoop和spark下的实现以及对比
关于PageRank的地位,不必多说. 主要思想:对于每个网页,用户都有可能点击网页上的某个链接,例如 A:B,C,D B:A,D C:AD:B,C 由这个我们可以得到网页的转移矩阵 A ...
- 大数据技术之_19_Spark学习_05_Spark GraphX 应用解析 + Spark GraphX 概述、解析 + 计算模式 + Pregel API + 图算法参考代码 + PageRank 实例
第1章 Spark GraphX 概述1.1 什么是 Spark GraphX1.2 弹性分布式属性图1.3 运行图计算程序第2章 Spark GraphX 解析2.1 存储模式2.1.1 图存储模式 ...
- 数据挖掘之权重计算(PageRank)
刘 勇 Email:lyssym@sina.com 简介 鉴于在Web抓取服务和文本挖掘之句子向量中对权重值的计算需要,本文基于MapReduce计算模型实现了PageRank算法.为验证本文算法 ...
- 大数据实时计算工程师/Hadoop工程师/数据分析师职业路线图
http://edu.51cto.com/roadmap/view/id-29.html http://my.oschina.net/infiniteSpace/blog/308401 大数据实时计算 ...
- 吴裕雄--天生自然HADOOP学习笔记:hadoop集群实现PageRank算法实验报告
实验课程名称:大数据处理技术 实验项目名称:hadoop集群实现PageRank算法 实验类型:综合性 实验日期:2018年 6 月4日-6月14日 学生姓名 吴裕雄 学号 15210120331 班 ...
随机推荐
- Simultaneous Localization and Mapping Technology Based on Project Tango
Abstract: Aiming at the problem of system error and noise in simultaneous localization and mapping ( ...
- eclipse查看方法被那些代码调用open call hierarchy
当我们编写的代码量十分巨大,项目十分复杂的时候,想要查找某一个方法都被其他那些代码调用了是一件十分困难的事,然后Eclipse提供了十分方便的方法用于查看方法都被那些代码调用了. 方法一: 选中要查看 ...
- Establish a website in 5 minutes
$sudo apt-get update //update $sudo apt-get install tasksel ...
- OC语言-block and delegate
参考博客 OC语言BLOCK和协议 iOS Block iOS Block循环引用精讲 iOS之轻松上手block 深入浅出Block的方方面面 Block apple官方参考 1.定义一个block ...
- html,css,jquery,JavaScript
1.全选 (当点击checkall按钮时,选中所有checkbox用prop全选上)function checkAll() { $(':checkbox').prop('checked', true) ...
- 数字证书管理工具openssl和keytool的区别
1. 用SSL进行双向身份验证意思就是在客户机连接服务器时,链接双方都要对彼此的数字证书进行验证,保证这是经过授权的才能够连接(我们链接一般的SSL时采用的是单向验证,客户机只验证服务器的证书,服务器 ...
- centos下添加git
CentOS中yum里没有Git,需要手动安装. 首先需要安装git的依赖包 yum install curl yum install curl-devel yum install zlib-deve ...
- Delphi IDHTTP控件:GET/POST 请求
Delphi IDHTTP控件:GET/POST 请求 最近一直在使用IDHTTP,下面是一些关于 GET.POST 请求基本使用方法的代码 一.GET 请求 1 procedure GetDem ...
- zabbix_server 报警
---恢复内容开始--- 记一个zabbix报警. zabbxi版本 zabbix_server监控报警 zabbix busy unreachable poller processes mor ...
- Spark技术的总结 以及同storm,Flink技术的对比
spark总结 1.Spark的特点: 高可伸缩性 高容错 基于内存计算 支持多种语言:java,scala,python,R 高质量的算法,比MapReduce快100倍 多种调度引擎:可以运行于Y ...