Kafka集群部署 (守护进程启动)
1、Kafka集群部署
1.1集群部署的基本流程
下载安装包、解压安装包、修改配置文件、分发安装包、启动集群
1.2集群部署的基础环境准备
安装前的准备工作(zk集群已经部署完毕)
关闭防火墙
chkconfig iptables off && setenforce 0 创建用户
groupadd kafka && useradd kafka && usermod -a -G kafka kafka 创建工作目录并赋权
mkdir -p /home/tuzq/software/kafka mkdir -p /home/tuzq/software/kafka/servers chmod 755 -R /home/tuzq/software/kafka
切换到kafka用户下
su kafka (本次实验,笔者使用root用户,即模拟在root下的安装。实际生产环境安装时请在指定用户下安装)
1.3 Kafka集群部署
1.3.1、下载安装包
http://kafka.apache.org/downloads.html
在linux中使用wget命令下载
wget http://mirrors.hust.edu.cn/apache/kafka/0.8.2.2/kafka_2.11-0.8.2.2.tgz1.3.2、解压安装包
tar -zxvf /home/tuzq/software/kafka_2.11-0.9.0.1.tgz -C /home/tuzq/software/kafka/servers/
cd /home/tuzq/software/kafka/servers/
ln -s kafka_2.11-0.9.0.1 kafka修改kafka的环境变量
vim /etc/profile
在文件的最底部写上:
#set kafka env
export KAFKA_HOME=/home/tuzq/software/kafka/servers/kafka
export PATH=$PATH:$KAFKA_HOME/bin保存,然后执行:
source /etc/profile1.3.3、修改配置文件
[root@hadoop1 kafka]# cp /home/tuzq/software/kafka/servers/kafka/config/server.properties
/home/tuzq/software/kafka/servers/kafka/config/server.properties.bak
[root@hadoop1 kafka]# vim /home/tuzq/software/kafka/servers/kafka/config/server.properties输入以下内容:
#broker的全局唯一编号,不能重复
broker.id=0
##用来监听链接的端口,producer或consumer将在此端口建立连接
port=9092
# 处理网络请求的线程数量
num.network.threads=3
# 用来处理磁盘IO的现成数量
num.io.threads=8
# 接受套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接受套接字的缓冲区大小
socket.receive.buffer.bytes=102400
# 请求套接字的缓冲区的大小
socket.request.max.bytes=104857600
# kafka运行日志存放的路径
log.dirs=/home/tuzq/software/kafka/servers/logs/kafka
# topic在当前broker上的分片个数
num.partitions=2
# 用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
# segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#滚动生成新的segment文件的最大时间
log.roll.hours=168
# 日志文件中每个segment的大小,默认为1G
log.segment.bytes=1073741824
# 周期性检查文件的时间,这里是300秒,即5分钟
log.retention.check.interval.ms=300000
##日志清理是否打开
log.cleaner.enable=true
#broker需要使用zookeeper保存meta数据
zookeeper.connect=hadoop11:2181,hadoop12:2181,hadoop13:2181
# zookeeper链接超时时间
zookeeper.connection.timeout.ms=6000
# partition buffer中,消息的条数达到阈值,将触发flush到磁盘
log.flush.interval.messages=10000
# 消息buffer的时间,达到阈值,将触发flush到磁盘
log.flush.interval.ms=3000
#删除topic需要server.properties中设置delete.topic.enable=true否则只是标记删除
delete.topic.enable=true
#此处的host.name为本机IP(重要),如果不改,则客户端会抛出:Producer connection to localhost:9092 unsuccessful 错误! (如果是hadoop2机器,下面配置成hadoop2)
host.name=hadoop1
#外网访问配置(如果是hadoop2的,下面是192.168.106.92)
advertised.host.name=192.168.106.911.3.4、分发安装包
将包分发到hadoop2和hadoop3上
[root@hadoop1 software]# pwd
/home/tuzq/software
[root@hadoop1 software]# scp -r kafka root@hadoop2:$PWD
[root@hadoop1 software]# scp -r kafka root@hadoop3:$PWD然后分别在hadoop1机器上创建软连
[root@hadoop2 software]# cd /home/tuzq/software/kafka/servers/
[root@hadoop2 servers]# ls
kafka kafka_2.11-0.9.0.1
[root@hadoop2 servers]# rm -rf kafka
[root@hadoop2 servers]# ln -s kafka_2.11-0.9.0.1 kafka
[root@hadoop2 servers]#在hadoop2上修改配置
[root@hadoop3 servers]# cd /home/tuzq/software/kafka/servers/
[root@hadoop3 servers]# ls
kafka kafka_2.11-0.9.0.1
[root@hadoop3 servers]# rm -rf kafka
[root@hadoop3 servers]# ls
kafka_2.11-0.9.0.1
[root@hadoop3 servers]# ln -s kafka_2.11-0.9.0.1 kafka
[root@hadoop3 servers]# ls
kafka kafka_2.11-0.9.0.1
[root@hadoop3 servers]#修改kafka的环境变量
vim /etc/profile
在文件的最底部写上:
#set kafka env
export KAFKA_HOME=/home/tuzq/software/kafka/servers/kafka
export PATH=$PATH:$KAFKA_HOME/bin保存,然后执行:
source /etc/profile1.3.5、再次修改配置文件(重要)
依次修改各服务器上配置文件的的broker.id,分别是0,1,2不得重复。
1.3.6、启动集群(注意在三台服务器上都要执行下面的命令)
依次在各节点上启动kafka
cd $KAFKA_HOME
bin/kafka-server-start.sh config/server.properties
让kafka后台运行:
[root@hadoop1 kafka]# bin/kafka-server-start.sh config/server.properties 1>/dev/null 2>&1 &
[1] 9412
[root@hadoop1 kafka]# jps
4624 DataNode
4241 DFSZKFailoverController
9475 Jps
9412 Kafka
5093 NodeManager
3981 JournalNode
4974 ResourceManager
4095 NameNode
[root@hadoop1 kafka]#从上面可以看出有一个kafka进程 9412 Kafka
停止kafka的命令:
[root@hadoop1 kafka]# bin/kafka-server-stop.sh config/server.propertieskafka-broker配置文件
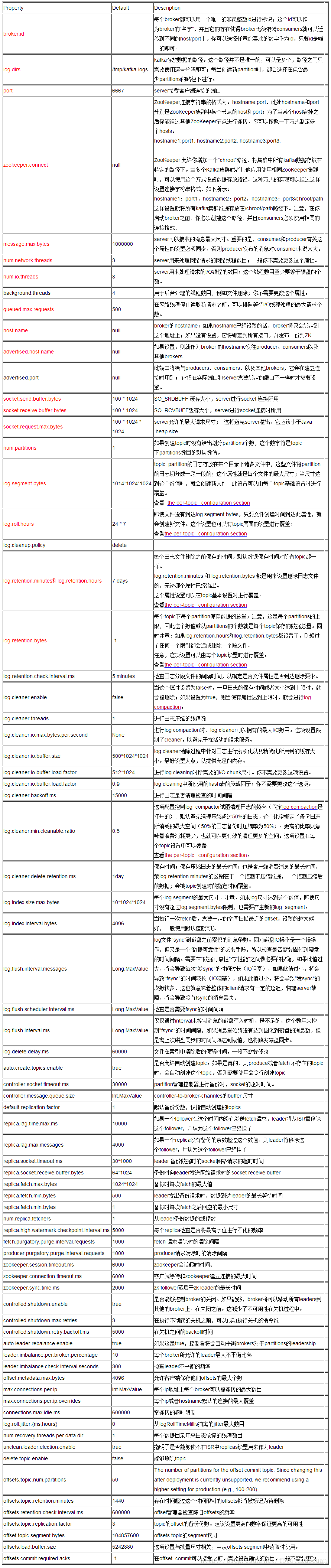
kafka-producer配置文件

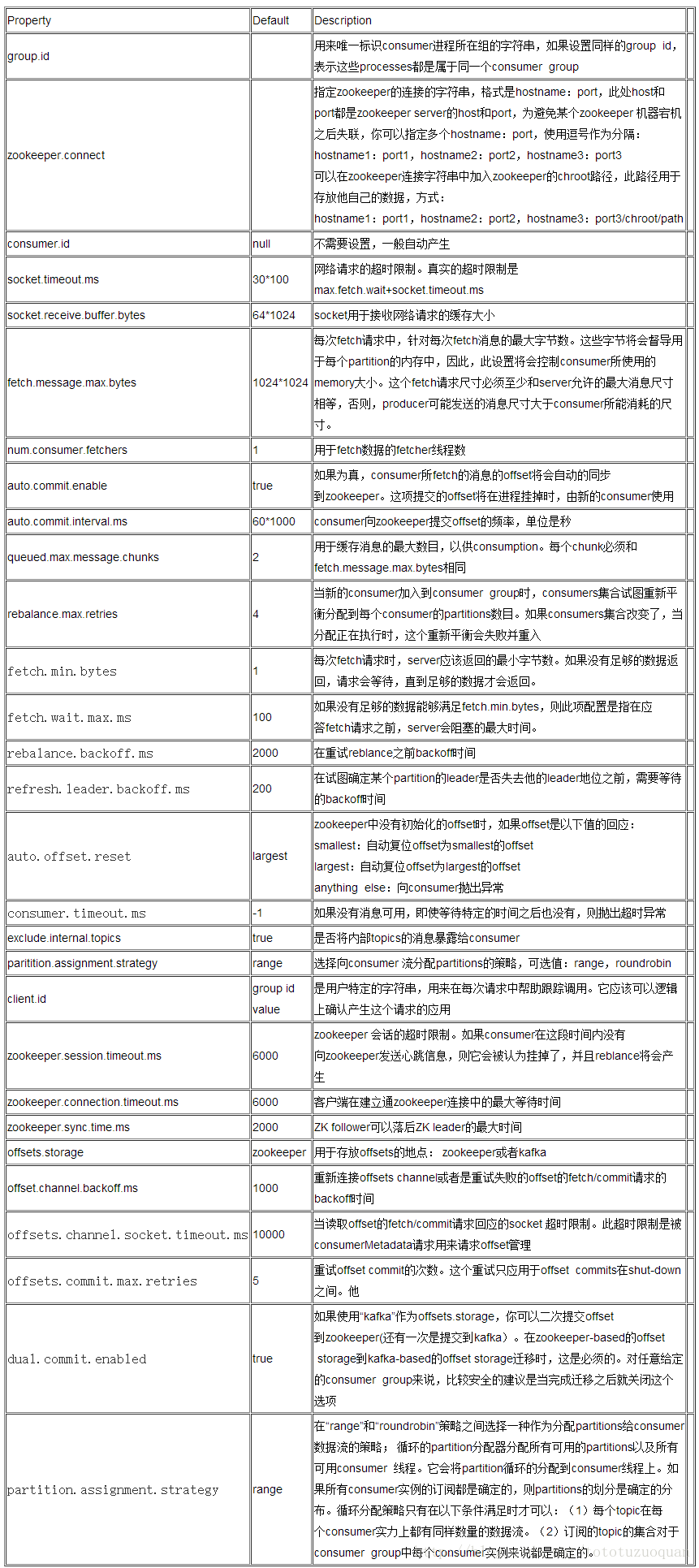
kafka-consumer配置文件
Kafka集群部署 (守护进程启动)的更多相关文章
- 分布式消息系统之Kafka集群部署
一.kafka简介 kafka是基于发布/订阅模式的一个分布式消息队列系统,用java语言研发,是ASF旗下的一个开源项目:类似的消息队列服务还有rabbitmq.activemq.zeromq:ka ...
- zookeeper集群+kafka集群 部署
zookeeper集群 +kafka 集群部署 1.Zookeeper 概述: Zookeeper 定义 zookeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目 Zooke ...
- kafka 集群部署 多机多broker模式
kafka 集群部署 多机多broker模式 环境IP : 172.16.1.35 zookeeper kafka 172.16.1.36 zookeeper kafka 172.16 ...
- Zookeeper+Kafka集群部署(转)
Zookeeper+Kafka集群部署 主机规划: 10.200.3.85 Kafka+ZooKeeper 10.200.3.86 Kafka+ZooKeeper 10.200.3.87 Kaf ...
- 3、Kafka集群部署
Kafka集群部署 1)解压安装包 [ip101]$ tar -zxvf kafka_2.11-0.11.0.0.tgz -C /opt/app/ 2)修改解压后的文件名称 [ip101]$ mv k ...
- Zookeeper+Kafka集群部署
Zookeeper+Kafka集群部署 主机规划: 10.200.3.85 Kafka+ZooKeeper 10.200.3.86 Kafka+ZooKeeper 10.200.3.87 Kaf ...
- Kafka集群部署以及使用
Kafka集群部署 部署步骤 hadoop102 hadoop103 hadoop104 zk zk zk kafka kafka kafka http://kafka.apache.org/down ...
- 4 kafka集群部署及kafka生产者java客户端编程 + kafka消费者java客户端编程
本博文的主要内容有 kafka的单机模式部署 kafka的分布式模式部署 生产者java客户端编程 消费者java客户端编程 运行kafka ,需要依赖 zookeeper,你可以使用已有的 zo ...
- 基于Centos7xELK+Kafka集群部署方案
本次集群部署使用ELK版本统一为6.8.10,kafka为2.12-2.51 均可在官网下载 elasticsearch下载地址:https://www.elastic.co/cn/downloads ...
随机推荐
- apache -- xampp配置虚拟主机
<VirtualHost *:80> ServerName www.myblog.com DocumentRoot "F:/Code/myblog"<Direct ...
- 常用Javascript函数与原型功能收藏
// 重复字符串 String.prototype.repeat = function(n) { return new Array(n+1).join(this); } // 替换全部 String. ...
- jQuery-替换和删除元素
1.replaceWith方法 用提供的内容替换集合中所有匹配的元素并且返回被替换元素的集合 参数类型说明: 1)普通字符串(可包含各种html标签) 2)jQuery对象 ①使用$函数创建的新元素( ...
- 做BS开发,你应该知道的一些东西
界面和用户体验(Interface and User Experience) 知道各大浏览器执行Web标准的情况,保证你的站点在主要浏览器上都能正常运行.你至少要测试以下引擎:Gecko(用于Fire ...
- 你真的了解HTML吗?–雅虎面试题
http://helloweb.wang/jingyan~jiqiao/589.html
- easyui-textbox 只读设置取消
<script> $(function () { $("#txt_beginAmount").attr('readonly', true); $("#txt_ ...
- POJ 1018 Communication System(树形DP)
Description We have received an order from Pizoor Communications Inc. for a special communication sy ...
- nohub和重定向文件
1.如果使用远程连接的Linux的方式并想后台运行执行如下命令: 格式:nohup <程序名> & 比如:nohup /usr/local/collection/bin/start ...
- 如何让windows启动后,自动加载一个DLL
在以下注册表项中找到下面的位置: HKEY_LOCAL_MACHINE\Software\Microsoft\Windows NT\CurrentVersion\Windows\AppInit_DLL ...
- Angular基础---->AngularJS的使用(一)
AngularJS主要用于构建单页面的Web应用.它通过增加开发人员和常见Web应用开发任务之间的抽象级别,使构建交互式的现代Web应用变得更加简单.今天,我们就开始Angular环境的搭建和第一个实 ...