分布式锁实践(一)-Redis编程实现总结
写在最前面
我在之前总结幂等性的时候,写过一种分布式锁的实现,可惜当时没有真正应用过,着实的心虚啊。正好这段时间对这部分实践了一下,也算是对之前填坑了。
分布式锁按照网上的结论,大致分为三种:1、数据库乐观锁; 2、基于Redis的分布式锁;3.、基于ZooKeeper的分布式锁;
关于乐观锁的实现其实在之前已经讲的很清楚了,有兴趣的移步:使用mysql乐观锁解决并发问题 。今天先简单总结下redis的实现方法,后面详细研究过ZooKeeper的实现原理后再具体说说ZooKeeper的实现。
为什么需要分布式锁?
在传统单体应用单机部署的情况下,可以使用Java并发相关的锁,如ReentrantLcok或synchronized进行互斥控制。但是,随着业务发展的需要,原单体单机部署的系统,渐渐的被部署在多机器多JVM上同时提供服务,这使得原单机部署情况下的并发控制锁策略失效了,为了解决这个问题就需要一种跨JVM的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题。
分布式锁的实现条件
1、互斥性,和单体应用一样,要保证任意时刻,只能有一个客户端持有锁
2、可靠性,要保证系统的稳定性,不能产生死锁
3、一致性,要保证锁只能由加锁人解锁,不能产生A的加锁被B用户解锁的情况
Redis分布式锁的实现
Redis实现分布式锁不同的人可能有不同的实现逻辑,但是核心就是下面三个方法。
SETNX
SETNX key val
当且仅当key不存在时,set一个key为val的字符串,返回1;若key存在,则什么都不做,返回0。
Expire
expire key timeout
为key设置一个超时时间,单位为second,超过这个时间锁会自动释放,避免死锁。
Delete
delete key
删除key
获取锁
首先讲一个目前网上应用最多的一种实现
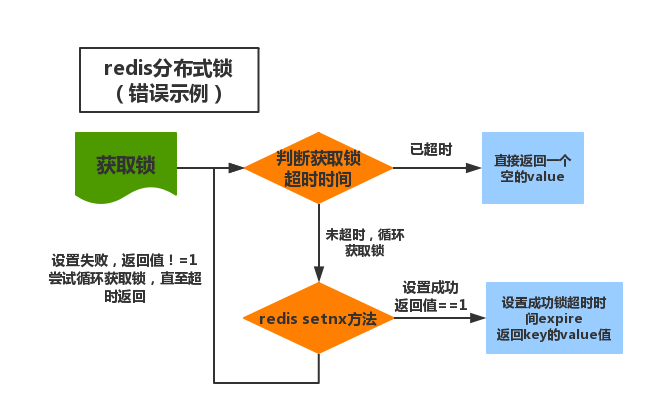
实现思路:
1.获取锁的时候,使用setnx加锁,并使用expire命令为锁添加一个超时时间,超过该时间则自动释放锁以免产生死锁,锁的value值为一个随机生成的UUID,通过此在释放锁的时候进行判断。
2.获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁。
3.释放锁的时候,通过UUID判断是不是该锁,若是该锁,则执行delete进行锁释放。
public String getRedisLock(Jedis jedis, String lockKey, Long acquireTimeout, Long timeOut) {
try {
// 定义 redis 对应key 的value值(uuid) 作用 释放锁 随机生成value,根据项目情况修改
String identifierValue = UUID.randomUUID().toString();
// 定义在获取锁之后的超时时间
int expireLock = (int) (timeOut / 1000);// 以秒为单位
// 定义在获取锁之前的超时时间
//使用循环机制 如果没有获取到锁,要在规定acquireTimeout时间 保证重复进行尝试获取锁
// 使用循环方式重试的获取锁
Long endTime = System.currentTimeMillis() + acquireTimeout;
while (System.currentTimeMillis() < endTime) {
// 获取锁
// 使用setnx命令插入对应的redislockKey ,如果返回为1 成功获取锁
if (jedis.setnx(lockKey, identifierValue) == 1) {
// 设置对应key的有效期
jedis.expire(lockKey, expireLock);
return identifierValue;
}
}
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
这种实现方法也是目前应用最多的实现,我一直以为这确实是正确的。然而由于这是两条Redis命令,不具有原子性,如果程序在执行完setnx()之后突然崩溃,导致锁没有设置过期时间。那么还是会发生死锁的情况。网上之所以有人这样实现,是因为低版本的jedis并不支持多参数的set()方法。
当然这种情况Jedis的设计者也显然想到了,新版的Jedis可以同时set多个参数,具体实现如下:
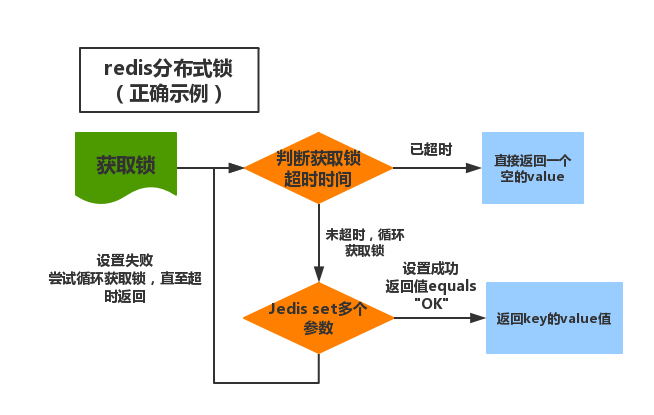
实现思路:
基本上和原来的逻辑类似,只是将setnx和expire的操作合并为一步,改为使用新的set多参的方法。
set(final String key, final String value, final String nxxx, final String expx,final long time)
key和value自然不用多说。
nxxx参数只可以传String 类型的NX(仅在不存在的情况下设置)和XX(和普通的set操作一样会做更新操作)两种。
expx是指到期时间单位,可传参数为EX (秒)和 PX (毫秒)
time就是具体的过期时间了,单位为前面expx所指定的。
然后我们对上面的代码进行改造如下:
/**
* @param acquireTimeout
* 在获取锁之前的超时时间
* @param timeOut
* 在获取锁之后的超时时间
*/
public String getRedisLock(Jedis jedis, String lockKey, Long acquireTimeout, Long timeOut) {
try {
// 定义 redis 对应key 的value值(uuid) 作用 释放锁 随机生成value,根据项目情况修改
String identifierValue = UUID.randomUUID().toString();
// 定义在获取锁之前的超时时间
//使用循环机制 如果没有获取到锁,要在规定acquireTimeout时间 保证重复进行尝试获取锁
// 使用循环方式重试的获取锁
Long endTime = System.currentTimeMillis() + acquireTimeout;
while (System.currentTimeMillis() < endTime) {
// 获取锁
// set使用NX参数的方式就等同于 setnx()方法,成功返回OK.PX以毫秒为单位
if ("OK".equals(jedis.set(lockKey, lockKey, "NX", "PX", timeOut))) {
return identifierValue;
}
} } catch (Exception e) {
e.printStackTrace();
}
return null;
}
好了,获取锁的操作基本上就上面这些,有同学可能要问,为什么不直接返回一个Boolean型的true或false呢?
正如我前面所说的,要保证解锁的一致性,所以就需要通过value值来保证解锁人就是加锁人,而不能直接返回true或false了。
下面在说下解锁的过程。
释放锁
还是先举一个错误的例子:
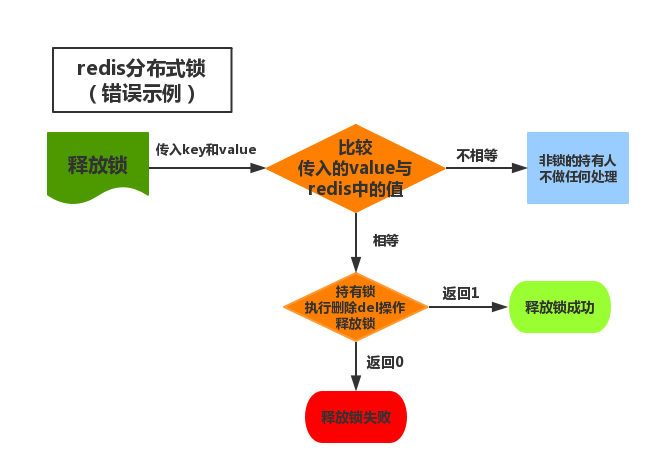
实现思路:
释放锁的时候,通过传入key和加锁时返回的value值,判断传入的value是否和key从redis中取出的相等。相等则证明解锁人就是加锁人,执行delete释放锁的操作。
// 释放redis锁
public void unRedisLock(Jedis jedis, String lockKey, String identifierValue) {
try {
// 如果该锁的id 等于identifierValue 是同一把锁情况才可以删除
if (jedis.get(lockKey).equals(identifierValue)) {
jedis.del(lockKey);
}
} catch (Exception e){
e.printStackTrace();
}
}
看着好像没啥问题哈。然而仔细想想又总感觉哪里不对。
如果在执行jedis.del(lockKey)操作之前,刚好锁的过期时间到了,而这个时候又有别的客户端取到了锁,我们在此时执行删除操作,不是又不符合一致性的要求了吗。
然后我们修改为下述方案:
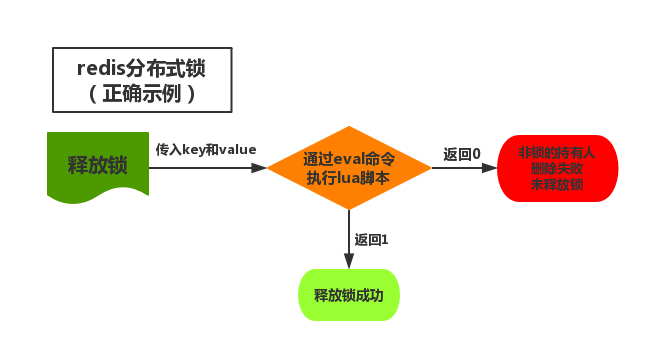
修改后的代码为:
public void unRedisLock(Jedis jedis, String lockKey, String identifierValue) {
try {
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
Long result = (Long) jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(identifierValue));
//0释放锁失败。1释放成功
if (1 == result) {
//如果你想返回删除成功还是失败,可以在这里返回
System.out.println(result+"释放锁成功");
}
if (0 == result){
System.out.println(result+"释放锁失败");
}
} catch (Exception e){
e.printStackTrace();
}
}
实现思路:
我们将Lua代码传到jedis.eval()方法里,并使参数KEYS[1]赋值为lockKey,ARGV[1]赋值为identifierValue。eval()方法是将Lua代码交给Redis服务端执行。
那么这段Lua代码的功能是什么呢?其实很简单,首先获取锁对应的value值,检查是否与identifierValue相等,如果相等则删除锁(解锁)。那么为什么要使用Lua语言来实现呢?因为要确保上述操作是原子性的。
那么为什么执行eval()方法可以确保原子性?源于Redis的特性,因为Redis是单线程,在eval命令执行Lua代码的时候,Lua代码将被当成一个命令去执行,并且直到eval命令执行完成,Redis才会执行其他命令。
总结
本文对Redis实现分布式锁做了比较详细的总结。我个人也对上述代码做了实践检验。其实我在使用时,一直用的错误的案例。直到看到园友Ruthless的一篇文章才晓得稀疏平常的写法竟然漏洞百出,感谢博客园,感谢Ruthless。编码是在现实生活中最容易产生成就感的工作,在学习过程中更要时刻保持着质疑精神,多思考多验证。
最后附上Ruthless的原文链接:https://www.cnblogs.com/linjiqin/p/8003838.html
分布式锁实践(一)-Redis编程实现总结的更多相关文章
- Springboot分布式锁实践(redis)
springboot2本地锁实践一文中提到用Guava Cache实现锁机制,但在集群中就行不通了,所以我们还一般要借助类似Redis.ZooKeeper 之类的中间件实现分布式锁,下面我们将利用自定 ...
- redis分布式锁实践
分布式锁在多实例部署,分布式系统中经常会使用到,这是因为基于jvm的锁无法满足多实例中锁的需求,本篇将讲下redis如何通过Lua脚本实现分布式锁,不同于网上的redission,完全是手动实现的 我 ...
- 分布式锁实践(二)-ZooKeeper实现总结
写在最前面 前几周写了篇 利用Redis实现分布式锁 ,今天简单总结下ZooKeeper实现分布式锁的过程.其实生产上我只用过Redis或者数据库的方式,之前还真没了解过ZooKeeper怎么实现分布 ...
- 分布式锁的实现(redis)
1.单机锁 考虑在并发场景并且存在竞态的状况下,我们就要实现同步机制了,最简单的同步机制就是加锁. 加锁可以帮我们锁住资源,如内存中的变量,或者锁住临界区(线程中的一段代码),使得同一个时刻只有一个线 ...
- 基于zookeeper实现分布式锁和基于redis实现分布所的区别
1,实现方式不同 zookeeper实现分布式锁:通过创建一个临时节点,创建的成功节点的服务则抢占到分布式锁,可做业务逻辑.当业务逻辑完成,连接中断,节点消失,继续下一轮的锁的抢占. redis实现分 ...
- Redis、Zookeeper实现分布式锁——原理与实践
Redis与分布式锁的问题已经是老生常谈了,本文尝试总结一些Redis.Zookeeper实现分布式锁的常用方案,并提供一些比较好的实践思路(基于Java).不足之处,欢迎探讨. Redis分布式锁 ...
- Redis分布式锁 (图解-秒懂-史上最全)
文章很长,而且持续更新,建议收藏起来,慢慢读! 高并发 发烧友社群:疯狂创客圈(总入口) 奉上以下珍贵的学习资源: 疯狂创客圈 经典图书 : 极致经典 + 社群大片好评 < Java 高并发 三 ...
- 4、redis 分布式锁
1. 前言 关于分布式锁的实现,目前常用的方案有以下三类: 数据库乐观锁: 基于分布式缓存实现的锁服务,典型代表有 Redis 和基于 Redis 的 RedLock: 基于分布式一致性算法实现的锁服 ...
- 【连载】redis库存操作,分布式锁的四种实现方式[一]--基于zookeeper实现分布式锁
一.背景 在电商系统中,库存的概念一定是有的,例如配一些商品的库存,做商品秒杀活动等,而由于库存操作频繁且要求原子性操作,所以绝大多数电商系统都用Redis来实现库存的加减,最近公司项目做架构升级,以 ...
随机推荐
- [原][osgearth]设置OE的高程,高度场的数据。修改设置高度值
; row < hf->getNumRows(); ++row ) { ; col < hf->getNumColumns(); ++col ) { float val = h ...
- mysql之innodb的锁分类介绍
一.innodb行锁分类 record lock:记录锁,也就是仅仅锁着单独的一行 gap lock:区间锁,仅仅锁住一个区间(注意这里的区间都是开区间,也就是不包括边界值. next-key loc ...
- Java Spring-AspectJ
2017-11-10 21:25:02 Spring的AspectJ的AOPAspectJ 是一个面向切面的框架,它扩展了 Java 语言. AspectJ 定义了 AOP 语法所以它有一个专门的编译 ...
- C#用大石头Xcode做数据底层注意事项
1.记得添加XCode.dll 和NewLife.Core.dll 2.记得把程序的框架改为 .net Framework4
- php-----utf8和gbk相互转换
utf8转换为gbk <?php header("Content-type:text/html;charset=UTF-8"); echo $str= '你好,这里是utf8 ...
- 最全Python内置函数
内置函数的基本使用 abs的使用: 取绝对值 absprint(abs(123))print(abs(-123)) result:123123 all的使用: 循环参数,如果每个元素都为真的情况下,那 ...
- K-Means算法的收敛性和如何快速收敛超大的KMeans?
不多说,直接上干货! 面试很容易被问的:K-Means算法的收敛性. 在网上查阅了很多资料,并没有看到很清晰的解释,所以希望可以从K-Means与EM算法的关系,以及EM算法本身的收敛性证明中找到蛛丝 ...
- java并发编程:线程安全管理类--原子操作类--AtomicInteger
在java并发编程中,会出现++,--等操作,但是这些不是原子性操作,这在线程安全上面就会出现相应的问题.因此java提供了相应类的原子性操作类. 1.AtomicInteger
- 非ie浏览器必备函数常识
场景描述: 我们都知道IE浏览器和非IE浏览器都有很多功能一样但写法不同,或者各自都有一些自己独特的方法,那么为了保持兼容性和便于编写,我们可以通过这两个方法给非IE浏览器的对象增加自己没有,但IE有 ...
- Jquery倒计时源码分享
在静态页添加显示倒计时的容器,并引用下面脚本,代入时间参数即可使用. timeoutDate——到期时间,时间格式为2014/01/01或2014/1/1 D——天 H——小时 M——分钟 S——秒 ...