131.005 Unsupervised Learning - Cluster | 非监督学习 - 聚类
@(131 - Machine Learning | 机器学习)
零、 Goal
- How Unsupervised Learning fills in that model gap from the original Machine Learning work flow
2.How to compare different models developed using Unsupervised Learning for their relative strengths and relative disadvantages
3.Understand the different kinds of conclusions that Unsupervised Learning can generate ,the different kinds of problems that is addresses(解决) and how it differs from Supervised Learning
一、K-Means Clustering
key notion —— Center
1.1 Step
- Step1 Assign
- Step2 Optimize
minimize the total quadratic distance of the cluster center to the points
1.2 Play a game
Visualizing K-Means Clustering
1.3 Clustering in Sklearn
http://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
1.4 K-Means 的局限
Will output for any fixed training set always be the same ?——NO
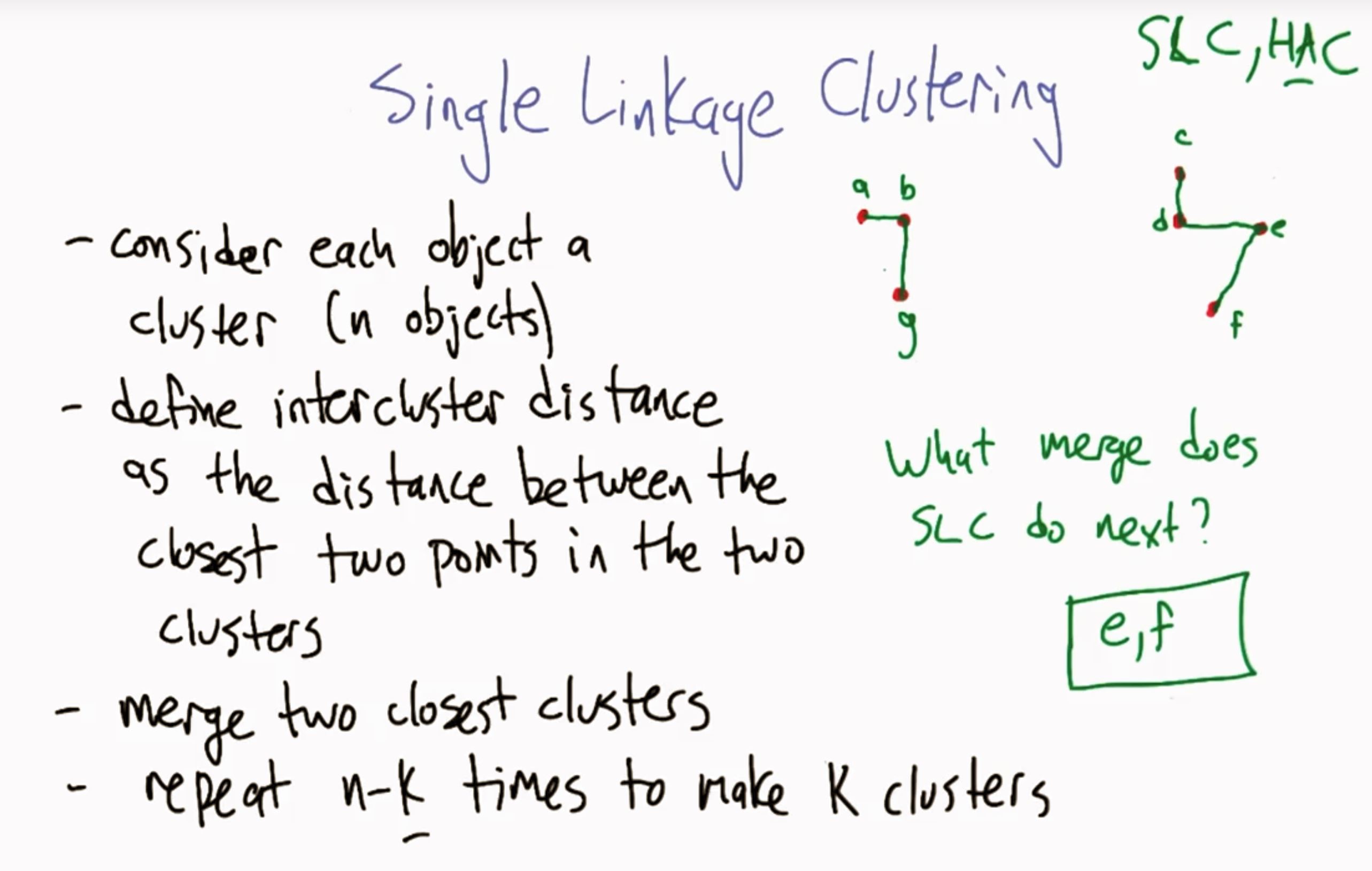
二、Single Linkage Clustering | 単连锁聚类(SLC)
key notion —— Link
- HAC —— Hierarchical agglomorative cluster 层次聚类算法
- iterate 迭代
- Farther —— physical distance (实际距离)
- Further —— metaphysical or metaphorical distans (抽象/比喻距离)
2.1 SLC 时间复杂度
\[ O(n^3)\]
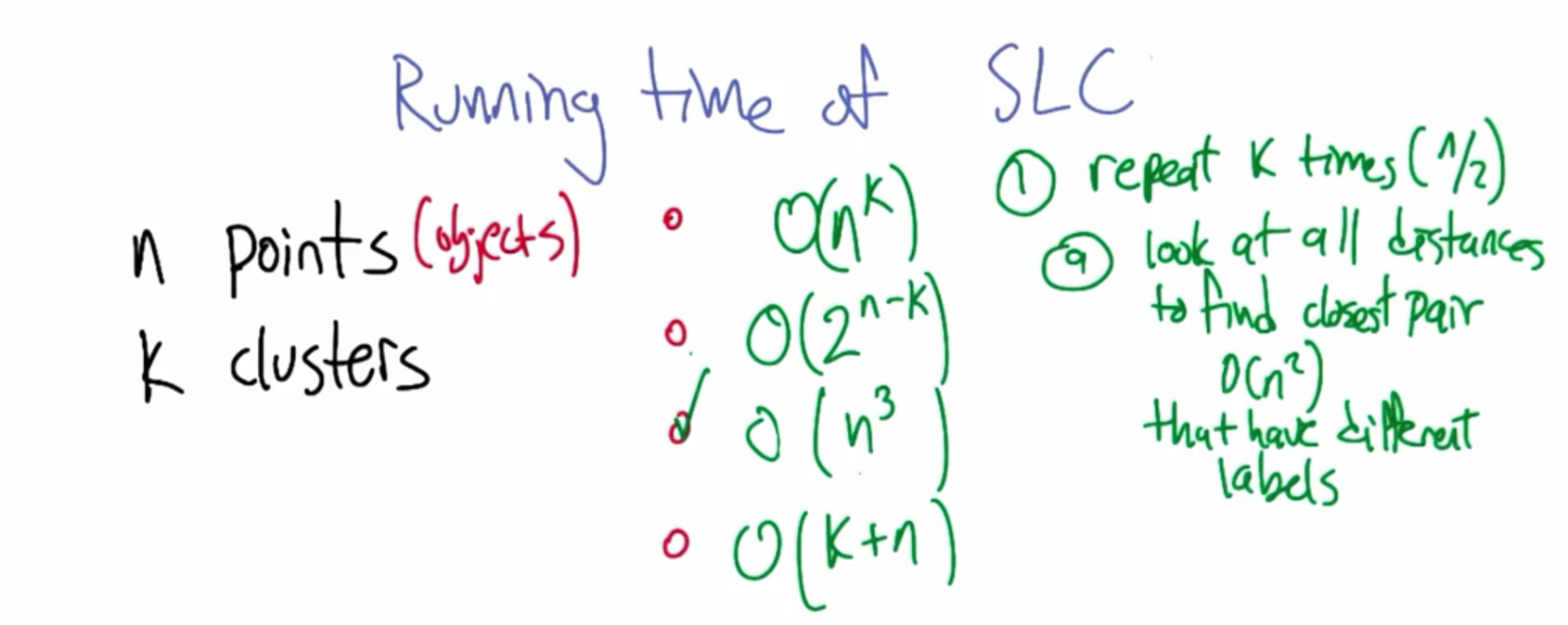
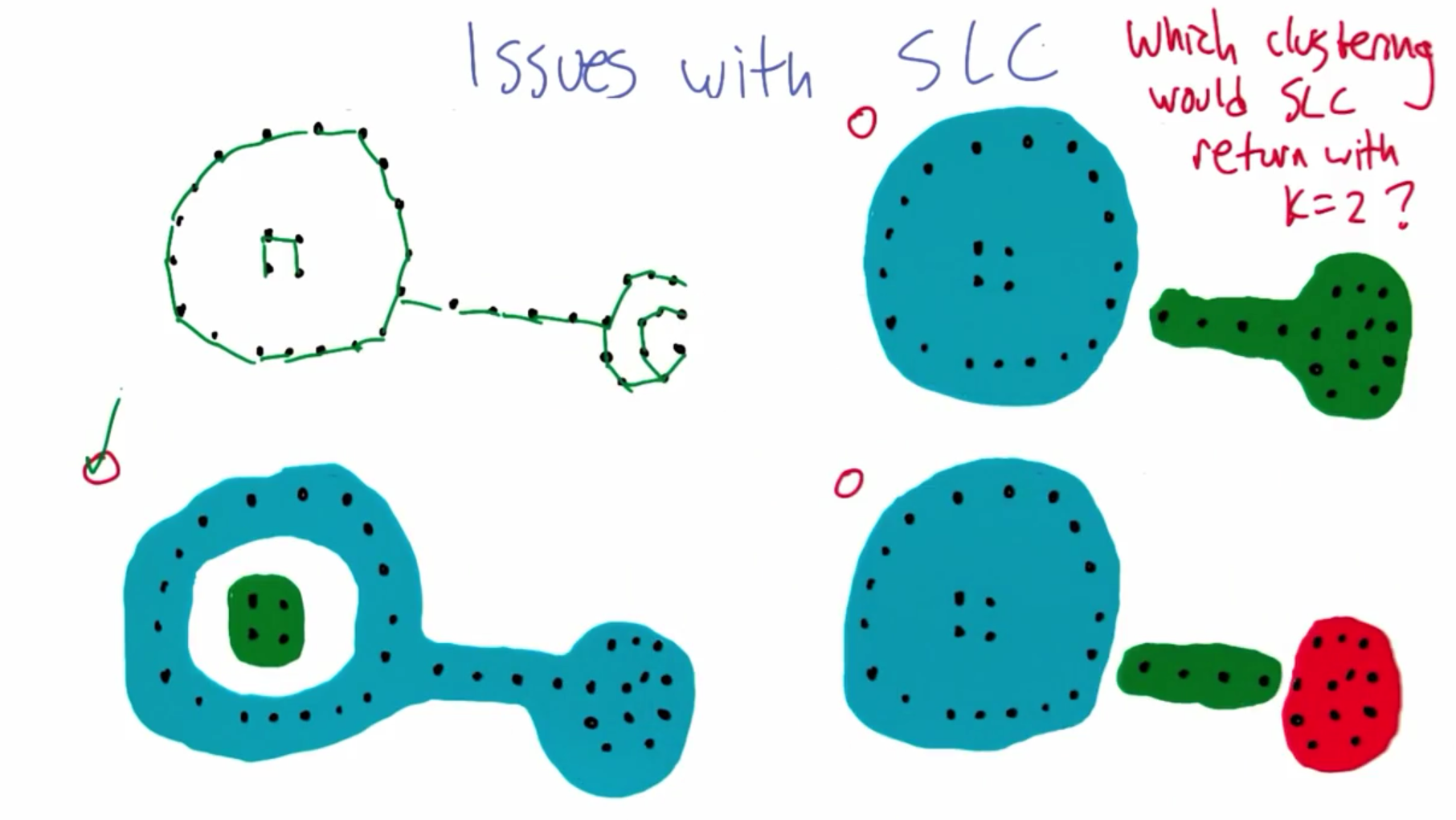
2.2 SLC 问题
三、Soft Clustering | 软聚类
the data point can be shared
- 聚类之——“软硬”之别
聚类分析如果按照隶属度的取值范围可以分为两类,一类叫硬聚类算法,另一类就是模糊聚类算法。隶属度的概念是从模糊集理论里引申出来的。
传统硬聚类算法隶属度只有两个值 0 和 1。也就是说一个样本只能完全属于某一个类或者完全不属于某一个类。举个例子,把温度分为两类,大于10度为热,小于或者等于10度为冷,这就是典型的“硬隶属度”概念。那么不论是5度还是负100度都属于冷这个类,而不属于热这个类的。
模糊集里的隶属度是一个取值在[0 1]区间内的数。一个样本同时属于所有的类,但是通过隶属度的大小来区分其差异。比如5度,可能属于冷这类的隶属度值为0.7,而属于热这个类的值为0.3。这样做就比较合理,硬聚类也可以看做模糊聚类的一个特例。
一些仅为个人倾向的分析(不严谨或不尽规范):所谓的动态模糊分析法我在文献里很少见到好像并不主流,似乎没有专门的这样一种典型聚类算法,可能是个别人根据自己需要设计并命名的一种针对模糊聚类的改进方法。有把每个不同样本加权的,权值自己确定,这样就冠以“动态"二字,这都是作者自己起的。也有别的也叫”动态“的,可能也不一样,似乎都是个别人自己提出的。
四、Expectation Maximization | 期望最大化
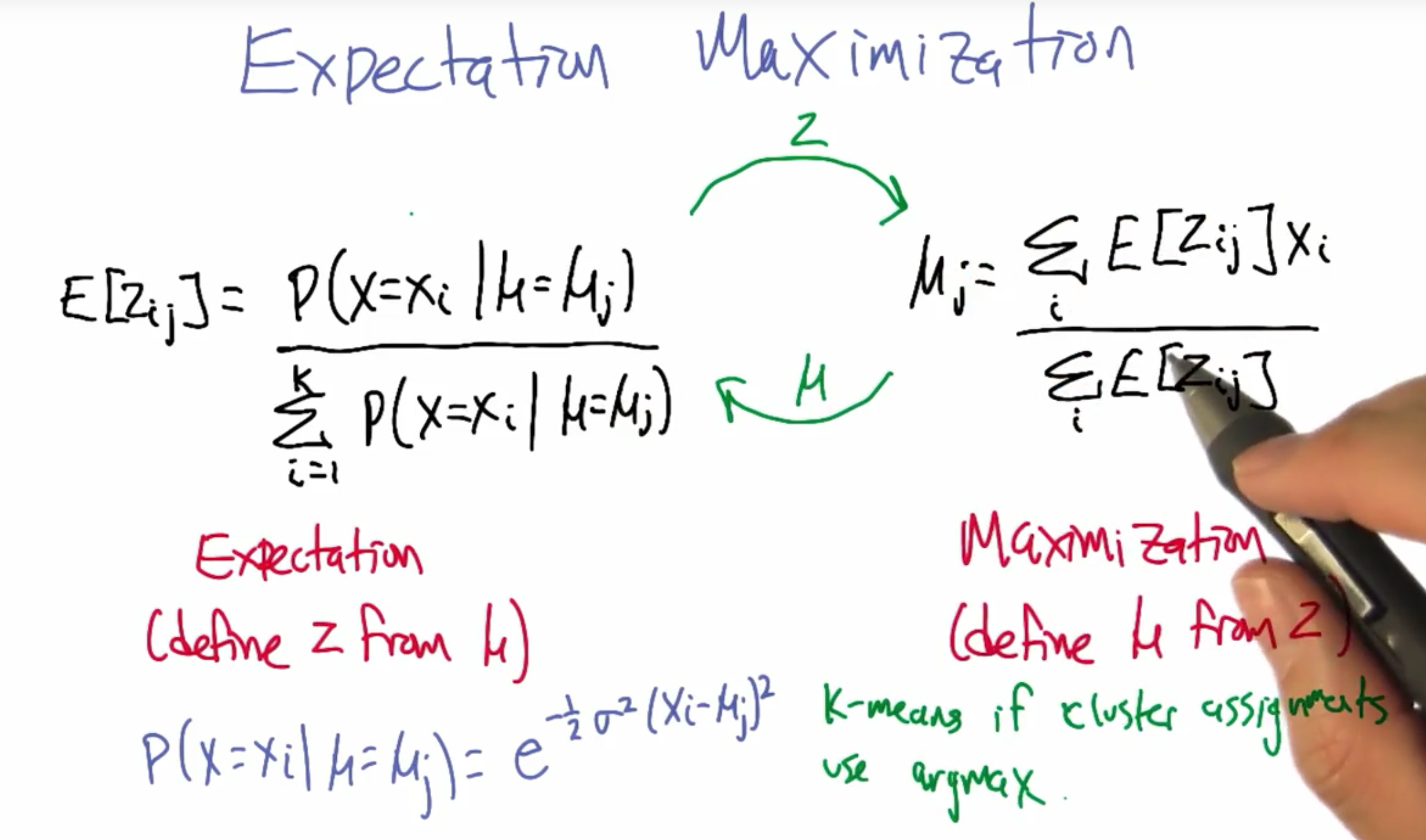
p.s. 因为对于每一项集群上的概率分布,我们都很想了解。所以左侧的总和应与变量 j 相关,而不是 i 。 抱歉!- Michael。
五、聚类属性
- Richness丰富性
- Scale invariance 比例不变性
- consistency 一致性
###不可能定理
But 没有一个算法可以同时满足三个属性——Kleinberg has proved it
在某种意义相互矛盾
科学素养——承认极限,不在完全不可能的事情上浪费时间
概念:聚类与分类(Classification)有别
聚类(Clustering,属无监督学习)
['klʌstərɪŋ],聚集,收集;分类归并。
聚类是指根据“物以类聚”的原理,将本身没有类别的样本聚集成不同的组,这样的一组数据对象的集合叫做簇,并且对每一个这样的簇进行描述的过程。
它的目的是使得属于同一个簇的样本之间应该彼此相似,而不同簇的样本应该足够不相似。
与分类规则不同,进行聚类前并不知道将要划分成几个组和什么样的组,也不知道根据哪些空间区分规则来定义组。
其目的旨在发现空间实体的属性间的函数关系,挖掘的知识用以属性名为变量的数学方程来表示。
当前,聚类技术正在蓬勃发展,涉及范围包括数据挖掘、统计学、机器学习、空间数据库技术、生物学以及市场营销等领域,聚类分析已经成为数据挖掘研究领域中一个非常活跃的研究课题。
常见的聚类算法包括:K-均值(K-Means)聚类算法、K-中心点聚类算法、CLARANS、BIRCH、CLIQUE、DBSCAN
就是把相似的东西分到一组。我们并不关心某一类是什么,实现的目标只是把相似的东西聚到一起。
因此,一个聚类算法通常只需要知道如何计算相似度就可以开始工作了,因此 clustering 通常并不需要使用训练数据进行学习,这在 Machine Learning 中被称作 unsupervised learning (无监督学习)。
分类(Classification ),监督学习
,则不同,对于一个 classifier ,通常需要你告诉它“这个东西被分为某某类”这样一些例子,理想情况下,一个 classifier 会从它得到的训练集中进行“学习”,从而具备对未知数据进行分类的能力,这种提供训练数据的过程通常叫做 supervised learning (监督学习)。
例:拿来一个新水果,我们按着他的特征,把他分到橘子或者香蕉那类中,叫做分类。
131.005 Unsupervised Learning - Cluster | 非监督学习 - 聚类的更多相关文章
- 如何区分监督学习(supervised learning)和非监督学习(unsupervised learning)
监督学习:简单来说就是给定一定的训练样本(这里一定要注意,样本是既有数据,也有数据对应的结果),利用这个样本进行训练得到一个模型(可以说是一个函数),然后利用这个模型,将所有的输入映射为相应的输出,之 ...
- k-means 非监督学习聚类算法
非监督学习 非监督学习没有历史样本数据和标签,直接对数据分析或得结果. k-means 使用 >>> from sklearn.cluster import KMeans >& ...
- 131.006 Unsupervised Learning - Feature Scaling | 非监督学习 - 特征缩放
@(131 - Machine Learning | 机器学习) 1 Feature Scaling transforms features to have range [0,1] according ...
- 131.008 Unsupervised Learning - Principle component Analysis |PCA | 非监督学习 - 主成分分析
@(131 - Machine Learning | 机器学习) PCA是一种特征选择方法,可将一组相关变量转变成一组基础正交变量 25 PCA的回顾和定义 Demo: when to use PCA ...
- 131.007 Unsupervised Learning - Feature Selection | 非监督学习 - 特征选择
1 Why? Reason1 Knowledge Discovery (about human beings limitaitons) Reason2 Cause of Dimensionality ...
- 【Machine Learning】监督学习、非监督学习及强化学习对比
Supervised Learning Unsupervised Learning Reinforced Learning Goal: How to apply these methods How t ...
- unsupervised learning: clustering介绍
unsupervised learning 上面是监督学习与无监督学习的比较,监督学习的training set是一组带label(y)的训练集,而无监督学习不带有label(y). 上图中的监督学习 ...
- Standford机器学习 聚类算法(clustering)和非监督学习(unsupervised Learning)
聚类算法是一类非监督学习算法,在有监督学习中,学习的目标是要在两类样本中找出他们的分界,训练数据是给定标签的,要么属于正类要么属于负类.而非监督学习,它的目的是在一个没有标签的数据集中找出这个数据集的 ...
- Machine Learning——Unsupervised Learning(机器学习之非监督学习)
前面,我们提到了监督学习,在机器学习中,与之对应的是非监督学习.无监督学习的问题是,在未加标签的数据中,试图找到隐藏的结构.因为提供给学习者的实例是未标记的,因此没有错误或报酬信号来评估潜在的解决方案 ...
随机推荐
- Jenkins 插件升级时跳过 update site 的签名验证
当升级jenkins插件时,如果链接的update site用的自签名证书,可以用这个选项来启动Jenkins,来跳过签名验证: -Dhudson.model.DownloadService.noS ...
- RocketMQ学习笔记(一)eclipse版的quickstart
学而时习之,不亦说乎! 自己搭建个学习用的RocketMQ总是很麻烦,需要虚拟机环境,网络,需要安装rocketmq,启动.时间久了再去看,又不知道这个虚拟机是干嘛的了. 直接在eclipse中启动, ...
- 剑指offer——面试题32.1:分行从上到下打印二叉树
void BFSLayer(BinaryTreeNode* pRoot) { if(pRoot==nullptr) return; queue<BinaryTreeNode*> pNode ...
- 一段自用javascript代码
function jsontoarray(mjson) { var arr = []; ; for(var x in mjson.data){ arr[i] = new Array(); arr[i] ...
- (转)分布式中使用Redis实现Session共享(一)
上一篇介绍了如何使用nginx+iis部署一个简单的分布式系统,文章结尾留下了几个问题,其中一个是"如何解决多站点下Session共享".这篇文章将会介绍如何使用Redis,下一篇 ...
- Linux网络编程服务器模型选择之并发服务器(下)
前面两篇文章(参见)分别介绍了循环服务器和简单的并发服务器网络模型,我们已经知道循环服务器模型效率较低,同一时刻只能为一个客户端提供服务,而且对于TCP模型来说,还存在单客户端长久独占与服务器的连接, ...
- 【Ubuntu】安装配置apahce
安装apachesudo apt-get install apache2 安装目录 /etc/apache2配置文件 /etc/apache2/apache2.conf默认网站根目录 /var/www ...
- ubuntu设置root权限默认密码
1.默认root密码是随机的,即每次开机都有一个新的root密码.我们可以在终端输入命令 sudo passwd,然后输入当前用户的密码2.终端会提示我们输入新的密码并确认,此时的密码就是root新密 ...
- smarty 教程 及 常用点
1. 简单例子 有助回忆基本知识点 define("DIR",dirname(__FILE__)); require_once(DIR."/libs/Smarty.cla ...
- 64位使用windbg获取Shadow SSDT
首先选择一个带界面的程序explorer.exe进行附加 kd> !process explorer.exe PROCESS ffff86893dd075c0 SessionId: Cid: 0 ...