spark累加器、广播变量
一言以蔽之:
累加器就是只写变量 通常就是做事件统计用的 因为rdd是在不同的excutor去执行的 你在不同excutor中累加的结果 没办法汇总到一起 这个时候就需要累加器来帮忙完成
广播变量是只读变量 正常的话我们在driver定义一个变量 需要序列化 才能在excutor端使用 而且是每个task都需要传输一次 这样如果我们定义的对象很大的话 就会产生大量的IO 如果你把这个大对象定义成广播变量的话 我们只需要每个excutor发送一份就可以 如果task需要时 只需要从excutor拉取就可以了。可以减轻集群driver和executor间的通信压力,节省集群资源。
Spark两种共享变量:广播变量(broadcast variable)与累加器(accumulator),广播变量常用来高效分发较大的对象,而累加器用来对信息进行聚合。
共享变量出现的原因:通常在向 Spark 传递函数时,比如使用map或reduce传条件或变量时,在driver端定义变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,更新这些副本的值driver端的对应变量并不会随之更新。Spark 的两个共享变量,广播变量与累加器分别为变量提供广播与聚合功能,突破了变量不能共享的限制。

2、广播变量的使用原则
不能将RDD用做变量广播出去,RDD是不存储数据的,可以将RDD的结果广播出去。
广播变量只能在Driver端定义,不能在Executor端定义,Executor端只能使用。
广播变量的值只能在Driver端修改,在Executor端不能修改
3、广播变量使用方法
(1) 通过SparkContext.Broadcast[T] 创建一个变量v,并进行广播,广播变量以序列化形式缓存。
如scala方式:val broadCast = sc.broadcast(T) 对T进行广播,T可以是任何能被序列化的类型
(2) 通过 broadCast.value 属性访问该对象的值,而不能直接访问T
(3) 当要更新广播变量时候,通过broadCast.unpersist()方法清除广播变量,之后可重新广播
4、广播变量使用场景
日常工作中对来访url、ip等过滤业务,就可以使用广播变量
112.168.102.71
19.18.172.75
12.16.72.20
100.20.13.4
8.8.8.8
102.168.17.205
202.102.12.74
114.114.114.114
object FilterIP {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("broadcast");
conf.setMaster("local");
val sc = new SparkContext(conf);
val lineRdd = sc.textFile("./ip_list.txt");//外部数据源,从别的数据源读取
//使用广播变量时,driver第一次向executor发送task时候,发送blackList,缓存到blockmanager,以后不会再发送
val blackList = List[String]("8.8.8.8","114.114.114.114");//过滤黑名单ip,从别的数据源读取
//在driver端进行广播blackList
val broadCast = sc.broadcast(blackList);
//在executor端用broadCast.value获取blackList的值
val filterRdd =lineRdd.filter(ip =>{ !broadCast.value.contains(ip)})
filterRdd.foreach(ip =>{
println(ip)
//处理其他业务
})
}
}
112.168.102.71
19.18.172.75
12.16.72.20
100.20.13.4
102.168.17.205
202.102.12.74
使用spark广播变量时候,在输出结果是看不到有什么变化,但这种变化是内在的,可以减轻集群driver和executor间的通信压力,节省集群资源。
Spark累加器
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext object FilterIP {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("broadcast");
conf.setMaster("local"); val sc = new SparkContext(conf); val lineRdd = sc.textFile("./ip_list.txt");//外部数据源,从别的数据源读取
var sum = ;
val blackList = List[String]("8.8.8.8","114.114.114.114");//过滤黑名单ip,从别的数据源读取
//在driver端进行广播blackList
val broadCast = sc.broadcast(blackList);
val filterRdd =lineRdd.filter(ip =>{ broadCast.value.contains(ip)})
filterRdd.foreach(ip =>{
sum+=;
println("executor sum="+sum)
})
//打印出非法ip的访问数量
println("driver sum="+sum)
}
}
输出:
executor sum=
executor sum= driver sum=
可以看到在driver端sum仍然是0,这并不是我们想要的结果。原来sum在各个节点的executor中累加的同时,driver端的sum最后并不会更新,导致sum最终仍然是0。
spark的累加器就是解决此类问题而出现的,其提供了聚合功能,把各个节点上的executor对变量的累加结果聚合到driver端, 最终统计出我们想要的结果。spark的累加器充分彰显的分布式计算的特性。
2、累加器使用原则
累加器在Driver端定义赋初始值,累加器只能在Driver端读取,在Excutor端更新。
3、累加器的使用方法
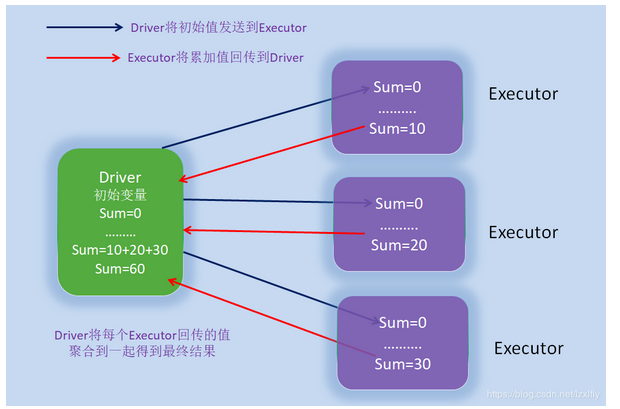
(1) 通过sparkContext.longAccumulator()或sparkContext.doubleAccumulator()来累积long或double类型的值来创建数字累加器
如scala方式:var accumulator=sc.longAccumulator("accumulator");
(2) 在executor端通过accumulator.add(1)进行累加后并回传到driver
4、累加器的使用场景
如对非法来访Ip的统计
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext object FilterIP {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("broadcast");
conf.setMaster("local"); val sc = new SparkContext(conf); val lineRdd = sc.textFile("./ip_list.txt");//外部数据源,从别的数据源读取
//spark2.0.0中sc.accumulator(0)不被推荐,用如下方式初始值,默认0
val accumulator=sc.longAccumulator("accumulator"); val blackList = List[String]("8.8.8.8","114.114.114.114");//过滤黑名单ip,从别的数据源读取
//在driver端进行广播blackList
val broadCast = sc.broadcast(blackList);
val filterRdd =lineRdd.filter(ip =>{ broadCast.value.contains(ip)})
filterRdd.foreach(ip =>{
accumulator.add();
})
//打印出非法ip的访问数量
println("driver sum="+accumulator.value)
}
}
输出:
driver sum=

————————————————
版权声明:本文为CSDN博主「LiryZlian」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lzxlfly/article/details/86366722
————————————————
版权声明:本文为CSDN博主「LiryZlian」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lzxlfly/article/details/86366722
import org.apache.spark.SparkConfimport org.apache.spark.SparkContext object FilterIP { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("broadcast"); conf.setMaster("local"); val sc = new SparkContext(conf); val lineRdd = sc.textFile("./ip_list.txt");//外部数据源,从别的数据源读取 //spark2.0.0中sc.accumulator(0)不被推荐,用如下方式初始值,默认0 val accumulator=sc.longAccumulator("accumulator"); val blackList = List[String]("8.8.8.8","114.114.114.114");//过滤黑名单ip,从别的数据源读取 //在driver端进行广播blackList val broadCast = sc.broadcast(blackList); val filterRdd =lineRdd.filter(ip =>{ broadCast.value.contains(ip)}) filterRdd.foreach(ip =>{ accumulator.add(1); }) //打印出非法ip的访问数量 println("driver sum="+accumulator.value) }}
spark累加器、广播变量的更多相关文章
- 【Spark篇】---Spark中广播变量和累加器
一.前述 Spark中因为算子中的真正逻辑是发送到Executor中去运行的,所以当Executor中需要引用外部变量时,需要使用广播变量. 累机器相当于统筹大变量,常用于计数,统计. 二.具体原理 ...
- Spark共享变量(广播变量、累加器)
转载自:https://blog.csdn.net/Android_xue/article/details/79780463 Spark两种共享变量:广播变量(broadcast variable)与 ...
- Spark学习之路 (四)Spark的广播变量和累加器
一.概述 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本.这些变量会被复制到每台机器上 ...
- Spark学习之路 (四)Spark的广播变量和累加器[转]
概述 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本.这些变量会被复制到每台机器上,并 ...
- Spark的广播变量模块
有人问我,如果让我设计广播变量该怎么设计,我想了想说,为啥不用zookeeper呢? 对啊,为啥不用zookeeper,也许spark的最初设计哲学就是尽量不使用别的组件,他有自己分布式内存文件系统, ...
- spark的广播变量
直接上代码:包含了,map,filter,persist,mapPartitions等函数 String master = "spark://192.168.2.279:7077" ...
- Spark 广播变量和累加器
Spark 的一个核心功能是创建两种特殊类型的变量:广播变量和累加器 广播变量(groadcast varible)为只读变量,它有运行SparkContext的驱动程序创建后发送给参与计算的节点.对 ...
- Spark(八)【广播变量和累加器】
目录 一. 广播变量 使用 二. 累加器 使用 使用场景 自定义累加器 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的 ...
- Spark RDD持久化、广播变量和累加器
Spark RDD持久化 RDD持久化工作原理 Spark非常重要的一个功能特性就是可以将RDD持久化在内存中.当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内 ...
- 【Spark-core学习之七】 Spark广播变量、累加器
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
随机推荐
- TestNG入门——注解之Before/After
注解是java 5新增的功能,可使用于类,方法,变量,testNG包提供的注解功能请见下表 1.@BeforeSuite or @AfterSuite 被注解的方法,将在整个测试套件之前 or 之后 ...
- CentOS7 下 yum 安装 Docker CE
前言 Docker 使用越来越多,安装也很简单,本次记录一下基本的步骤. Docker 目前支持 CentOS 7 及以后的版本,内核要求至少为 3.10. Docker 官网有安装步骤,本文只是记录 ...
- 乘法器——基于Wallace树的4位乘法器实现
博主最近在学习加法器乘法等等相关知识,在学习乘法器booth编码加Wallace树压缩时,发现在压缩部分积的时候用到了进位保留加法器(Carry Save Adder),博主对这种加法器不是很理解,而 ...
- pytest_全局变量的使用
这里重新阐述下PageObject设计模式: PageObject设计模式是selenium自动化最成熟,最受欢迎的一种模式,这里用pytest同样适用 这里直接提供代码: 全局变量 conftest ...
- jar包部署脚本
部署一个名为xxx的jar包,输出到out.log,只需要准备以下脚本start.sh #!/bin/sh echo " =====关闭Java应用======" PROCESS= ...
- pandas mode()填充nan异常问题
df.mode()return的是一个frame,因为可能存在多个总数.那么用mode()来填充nan的时候就要注意了,如果直接 df.fillna(df.mode()) 会发现还是有很多空值没有填充 ...
- 如何在ASP.NET Core Web API中使用Mini Profiler
原文如何在ASP.NET Core Web API中使用Mini Profiler 由Anuraj发表于2019年11月25日星期一阅读时间:1分钟 ASPNETCoreMiniProfiler 这篇 ...
- 浅析ajax请求json数据并用js解析(示例分析)
这应该是每个web开发的人员都应该掌握的基础技术,需要的朋友可以参考下 自从接触了jquery就喜欢上了前端开发,而且深深感受到了前端开发的强大与重要之处.同时也想为asp.net鸣不平,事实上asp ...
- RabbitMQ学习之Routing(4)
上一节,是广播日志message到很多的receivers. 这节,我们讲订阅其中的一个子集.例如,我们想可以把危机的error message导到log file.而仍然可以打印所有的log mes ...
- 字符串格式连接sqlserver数据库的字段概念解释
以连接sqlserver数据库举例说明如:“Provider=SQLOLEDB.1;Password=******;Persist Security Info=True;User ID=sa;Init ...