【恢复】Redo日志文件丢失的恢复
第一章 Redo文件丢失的恢复

1.1 online redolog file 丢失
联机Redo日志是Oracle数据库中比较核心的文件,当Redo日志文件异常之后,数据库就无法正常启动,而且有丢失据的风险,强烈建议在条件允许的情况下,对Redo日志进行多路镜像。需要注意的是,RMAN不能备份联机Redo日志文件。所以,联机Redo日志一旦出现故障,则只能进行清除日志了。清除日志文件即表明可以重用该文件。
1.1.1 数据库归档/非归档模式下inactive redo异常ORA-00316 ORA-00327
1.1.1.1 例一
SQL> startup mount
ORACLE instance started.
Total System Global Area 260046848 bytes
Fixed Size 1266896 bytes
Variable Size 83888944 bytes
Database Buffers 167772160 bytes
Redo Buffers 7118848 bytes
Database mounted.
SQL> alter database open;
alter database open
*
ERROR at line 1:
ORA-00316: log 2 of thread 1, type in header is not log file
ORA-00312: online log 2 thread 1: '/u01/oracle/oradata/XFF/redo02.log'
SQL> col member for a40
SQL> set lines 120
SQL> SELECT thread#,
2 a.sequence#,
3 a.group#,
4 TO_CHAR (first_change#, '9999999999999999') "SCN",
5 a.status,
6 MEMBER
7 FROM v$log a, v$logfile b
8 WHERE a.group# = B.GROUP#
9 ORDER BY a.sequence# DESC;
THREAD# SEQUENCE# GROUP# SCN STATUS MEMBER
---------- ---------- ---------- ----------------- ---------------- -----------------------------------
1 15 3 665697 CURRENT /u01/oracle/oradata/XFF/redo03.log
1 14 2 645619 INACTIVE /u01/oracle/oradata/XFF/redo02.log
1 13 1 625540 INACTIVE /u01/oracle/oradata/XFF/redo01.log
SQL> ALTER DATABASE CLEAR LOGFILE GROUP 2;
Database altered.
SQL> alter database open;
alter database open
*
ERROR at line 1:
ORA-00327: log 2 of thread 1, physical size less than needed
ORA-00312: online log 2 thread 1: '/u01/oracle/oradata/XFF/redo02.log'
SQL> alter database drop logfile group 2;
Database altered.
SQL> alter database open;
Database altered.
SQL> alter database add logfile group 2 ('/u01/oracle/oradata/XFF/redo02.log') size 50M reuse;
Database altered.
1.1.1.2 例二
[oracle@orcltest ~]$ sqlplus / as sysdba
SQL*Plus: Release 11.2.0.3.0 Production on Wed May 6 13:46:16 2015
Copyright (c) 1982, 2011, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
SQL> col member for a50
SQL> set lines 120
SQL> SELECT thread#,
2 a.sequence#,
3 a.group#,
4 TO_CHAR (first_change#, '9999999999999999') "SCN",
5 a.status,
6 MEMBER
7 FROM v$log a, v$logfile b
8 WHERE a.group# = B.GROUP#
9 ORDER BY a.sequence# DESC;
THREAD# SEQUENCE# GROUP# SCN STATUS MEMBER
---------- ---------- ---------- ----------------- ---------------- --------------------------------------------------
1 16 3 1209020 CURRENT /u02/app/oracle/oradata/oratest/redo03.log
1 15 1 1209017 INACTIVE /u02/app/oracle/oradata/oratest/redo01.log
1 14 2 1209012 INACTIVE /u02/app/oracle/oradata/oratest/redo02.log
SQL> ! rm -rf /u02/app/oracle/oradata/oratest/redo01.log
SQL>
SQL> startup force;
ORACLE instance started.
Total System Global Area 409194496 bytes
Fixed Size 2228864 bytes
Variable Size 297799040 bytes
Database Buffers 100663296 bytes
Redo Buffers 8503296 bytes
Database mounted.
ORA-03113: end-of-file on communication channel
Process ID: 15390
Session ID: 125 Serial number: 5
SQL>
SQL> exit
Disconnected from Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
告警日志:
Errors in file /u02/app/oracle/diag/rdbms/oratest/oratest/trace/oratest_lgwr_15484.trc:
ORA-00313: open failed for members of log group 1 of thread 1
ORA-00312: online log 1 thread 1: '/u02/app/oracle/oradata/oratest/redo01.log'
ORA-27037: unable to obtain file status
Linux-x86_64 Error: 2: No such file or directory
Additional information: 3
[oracle@orcltest ~]$ sqlplus / as sysdba
SQL*Plus: Release 11.2.0.3.0 Production on Wed May 6 13:48:39 2015
Copyright (c) 1982, 2011, Oracle. All rights reserved.
Connected to an idle instance.
SQL> startup mount;
ORACLE instance started.
Total System Global Area 409194496 bytes
Fixed Size 2228864 bytes
Variable Size 297799040 bytes
Database Buffers 100663296 bytes
Redo Buffers 8503296 bytes
Database mounted.
SQL> alter database clear logfile group 1;
Database altered.
SQL> alter database open;
Database altered.
SQL> col member for a50
SQL> set lines 120
SQL> SELECT thread#,
2 a.sequence#,
3 a.group#,
4 TO_CHAR (first_change#, '9999999999999999') "SCN",
5 a.status,
6 MEMBER
7 FROM v$log a, v$logfile b
8 WHERE a.group# = B.GROUP#
9 ORDER BY a.sequence# DESC;
THREAD# SEQUENCE# GROUP# SCN STATUS MEMBER
---------- ---------- ---------- ----------------- ---------------- --------------------------------------------------
1 17 1 1229024 CURRENT /u02/app/oracle/oradata/oratest/redo01.log
1 16 3 1209020 INACTIVE /u02/app/oracle/oradata/oratest/redo03.log
1 14 2 1209012 INACTIVE /u02/app/oracle/oradata/oratest/redo02.log
SQL>
1.1.2 正常关闭数据库current redo异常ORA-00316 ORA-01623
1.1.2.1 例一
SQL> alter database open;
alter database open
*
ERROR at line 1:
ORA-00316: log 1 of thread 1, type in header is not log file
ORA-00312: online log 1 thread 1: '/u01/oracle/oradata/XFF/redo01.log'
SQL> SELECT thread#,
2 a.sequence#,
3 a.group#,
4 TO_CHAR (first_change#, '9999999999999999') "SCN",
5 a.status,
6 MEMBER
7 FROM v$log a, v$logfile b
8 WHERE a.group# = B.GROUP#
9 ORDER BY a.sequence# DESC;
THREAD# SEQUENCE# GROUP# SCN STATUS MEMBER
---------- ---------- ---------- ----------------- ---------------- ----------------------------------
1 16 1 685918 CURRENT /u01/oracle/oradata/XFF/redo01.log
1 15 3 665697 INACTIVE /u01/oracle/oradata/XFF/redo03.log
1 0 2 0 UNUSED /u01/oracle/oradata/XFF/redo02.log
SQL> ALTER DATABASE CLEAR LOGFILE GROUP 1;
ALTER DATABASE CLEAR LOGFILE GROUP 1
*
ERROR at line 1:
ORA-00316: log 1 of thread 1, type 0 in header is not log file
ORA-00312: online log 1 thread 1: '/u01/oracle/oradata/XFF/redo01.log'
SQL> ALTER DATABASE drop logfile group 1;
ALTER DATABASE drop logfile group 1
*
ERROR at line 1:
ORA-01623: log 1 is current log for instance XFF (thread 1) - cannot drop
ORA-00312: online log 1 thread 1: '/u01/oracle/oradata/XFF/redo01.log'
SQL> recover database until cancel;
Media recovery complete.
SQL> alter database open resetlogs;
Database altered.
1.1.2.2 例二
[oracle@orcltest ~]$ sqlplus / as sysdba
SQL*Plus: Release 11.2.0.3.0 Production on Wed May 6 13:52:49 2015
Copyright (c) 1982, 2011, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
SQL> col member for a50
SQL> set lines 120
SQL> SELECT thread#,
2 a.sequence#,
3 a.group#,
4 TO_CHAR (first_change#, '9999999999999999') "SCN",
5 a.status,
6 MEMBER
7 FROM v$log a, v$logfile b
8 WHERE a.group# = B.GROUP#
9 ORDER BY a.sequence# DESC;
THREAD# SEQUENCE# GROUP# SCN STATUS MEMBER
---------- ---------- ---------- ----------------- ---------------- --------------------------------------------------
1 20 1 1229346 CURRENT /u02/app/oracle/oradata/oratest/redo01.log
1 19 3 1229343 INACTIVE /u02/app/oracle/oradata/oratest/redo03.log
1 18 2 1229340 INACTIVE /u02/app/oracle/oradata/oratest/redo02.log
SQL> ! rm -rf /u02/app/oracle/oradata/oratest/redo01.log
SQL> shutdown immediate;
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup
ORACLE instance started.
Total System Global Area 409194496 bytes
Fixed Size 2228864 bytes
Variable Size 297799040 bytes
Database Buffers 100663296 bytes
Redo Buffers 8503296 bytes
Database mounted.
ORA-03113: end-of-file on communication channel
Process ID: 15837
Session ID: 125 Serial number: 5
SQL>
SQL> exit
Disconnected from Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
告警日志:
Errors in file /u02/app/oracle/diag/rdbms/oratest/oratest/trace/oratest_ora_15949.trc:
ORA-00313: open failed for members of log group 1 of thread
ORA-00312: online log 1 thread 1: '/u02/app/oracle/oradata/oratest/redo01.log'
Wed May 06 13:53:47 2015
ARC1 started with pid=21, OS id=15976
USER (ospid: 15949): terminating the instance due to error 313
System state dump requested by (instance=1, osid=15949), summary=[abnormal instance termination].
System State dumped to trace file /u02/app/oracle/diag/rdbms/oratest/oratest/trace/oratest_diag_15919.trc
Dumping diagnostic data in directory=[cdmp_20150506135347], requested by (instance=1, osid=15949), summary=[abnormal instance termination].
Instance terminated by USER, pid = 15949
[oracle@orcltest ~]$ sqlplus / as sysdba
SQL*Plus: Release 11.2.0.3.0 Production on Wed May 6 13:54:28 2015
Copyright (c) 1982, 2011, Oracle. All rights reserved.
Connected to an idle instance.
SQL> startup mount;
ORACLE instance started.
Total System Global Area 409194496 bytes
Fixed Size 2228864 bytes
Variable Size 297799040 bytes
Database Buffers 100663296 bytes
Redo Buffers 8503296 bytes
Database mounted.
SQL> ALTER DATABASE CLEAR LOGFILE GROUP 1;
ALTER DATABASE CLEAR LOGFILE GROUP 1
*
ERROR at line 1:
ORA-00350: log 1 of instance oratest (thread 1) needs to be archived
ORA-00312: online log 1 thread 1: '/u02/app/oracle/oradata/oratest/redo01.log'
SQL> ALTER DATABASE CLEAR UNARCHIVED LOGFILE GROUP 1;
Database altered.
SQL> ALTER DATABASE OPEN;
Database altered.
SQL> col member for a50
SQL> set lines 120
SQL> SELECT thread#,
2 a.sequence#,
3 a.group#,
4 TO_CHAR (first_change#, '9999999999999999') "SCN",
5 a.status,
6 MEMBER
7 FROM v$log a, v$logfile b
8 WHERE a.group# = B.GROUP#
9 ORDER BY a.sequence# DESC;
THREAD# SEQUENCE# GROUP# SCN STATUS MEMBER
---------- ---------- ---------- ----------------- ---------------- --------------------------------------------------
1 21 2 1229347 CURRENT /u02/app/oracle/oradata/oratest/redo02.log
1 19 3 1229343 INACTIVE /u02/app/oracle/oradata/oratest/redo03.log
1 0 1 1229346 UNUSED /u02/app/oracle/oradata/oratest/redo01.log
SQL>
1.1.3 数据库异常关闭current/active redo异常ORA-00316 ORA-01624 ORA-01194
SQL> alter database open;
alter database open
*
ERROR at line 1:
ORA-00316: log 1 of thread 1, type 0 in header is not log file
ORA-00312: online log 1 thread 1: '/u01/oracle/oradata/XFF/redo01.log'
SQL> SELECT thread#,
2 a.sequence#,
3 a.group#,
4 TO_CHAR (first_change#, '9999999999999999') "SCN",
5 a.status,
6 MEMBER
7 FROM v$log a, v$logfile b
8 WHERE a.group# = B.GROUP#
9 ORDER BY a.sequence# DESC;
THREAD# SEQUENCE# GROUP# SCN STATUS MEMBER
---------- ---------- ---------- ----------------- ---------------- -----------------------------------
1 8 2 686310 CURRENT /u01/oracle/oradata/XFF/redo02.log
1 7 1 686294 ACTIVE /u01/oracle/oradata/XFF/redo01.log
1 6 3 686289 INACTIVE /u01/oracle/oradata/XFF/redo03.log
SQL> ALTER DATABASE CLEAR LOGFILE GROUP 1;
ALTER DATABASE CLEAR LOGFILE GROUP 1
*
ERROR at line 1:
ORA-01624: log 1 needed for crash recovery of instance XFF (thread 1)
ORA-00312: online log 1 thread 1: '/u01/oracle/oradata/XFF/redo01.log'
SQL> ALTER DATABASE drop logfile group 1;
ALTER DATABASE drop logfile group 1
*
ERROR at line 1:
ORA-01624: log 1 needed for crash recovery of instance XFF (thread 1)
ORA-00312: online log 1 thread 1: '/u01/oracle/oradata/XFF/redo01.log'
SQL> recover database until cancel;
ORA-00279: change 686294 generated at 04/20/2013 01:37:16 needed for thread 1
ORA-00289: suggestion : /u01/oracle/oracle/product/10.2.0/db_1/dbs/arch1_7_813202529.dbf
ORA-00280: change 686294 for thread 1 is in sequence #7
Specify log: {=suggested | filename | AUTO | CANCEL}
/u01/oracle/oradata/XFF/redo01.log
ORA-00308: cannot open archived log '/u01/oracle/oradata/XFF/redo01.log'
ORA-27047: unable to read the header block of file
Additional information: 2
Specify log: {=suggested | filename | AUTO | CANCEL}
cancel
ORA-01547: warning: RECOVER succeeded but OPEN RESETLOGS would get error below
ORA-01194: file 1 needs more recovery to be consistent
ORA-01110: data file 1: '/u01/oracle/oradata/XFF/system01.dbf'
ORA-01112: media recovery not started
SQL> alter database open resetlogs;
alter database open resetlogs
*
ERROR at line 1:
ORA-01194: file 1 needs more recovery to be consistent
ORA-01110: data file 1: '/u01/oracle/oradata/XFF/system01.dbf'
SQL> alter system set "_allow_resetlogs_corruption"=true scope=spfile;
System altered.
SQL> shutdown immediate;
ORA-01109: database not open
Database dismounted.
ORACLE instance shut down.
SQL> startup mount;
ORACLE instance started.
Total System Global Area 260046848 bytes
Fixed Size 1266896 bytes
Variable Size 83888944 bytes
Database Buffers 167772160 bytes
Redo Buffers 7118848 bytes
Database mounted.
SQL> recover database until cancel;
ORA-00279: change 686294 generated at 04/20/2013 01:37:16 needed for thread 1
ORA-00289: suggestion : /u01/oracle/oracle/product/10.2.0/db_1/dbs/arch1_7_813202529.dbf
ORA-00280: change 686294 for thread 1 is in sequence #7
Specify log: {=suggested | filename | AUTO | CANCEL}
cancel
ORA-01547: warning: RECOVER succeeded but OPEN RESETLOGS would get error below
ORA-01194: file 1 needs more recovery to be consistent
ORA-01110: data file 1: '/u01/oracle/oradata/XFF/system01.dbf'
ORA-01112: media recovery not started
SQL> alter database open resetlogs;
Database altered.
在这样的情况下,数据库异常关闭,current/active redo异常,通过使用隐含参数可能可以侥幸的恢复数据库,但是也可能导致数据丢失.这里因为是模拟情况,无业务所以在很多较为繁忙的业务系统中,使用隐含参数resetlogs过程中可能还会遇到如下很多常见的错误,进一步增加了恢复难度。
current/active redo异常后附带其他错误
ORA-600[2662]
Wed Dec 07 13:02:49 2011
SMON: enabling cache recovery
Errors in file d:\app\administrator\diag\rdbms\hzyl\hzyl\trace\hzyl_ora_3388.trc (incident=216664):
ORA-00600: 内部错误代码, 参数: [2662], [2], [1153862134], [2], [1153864845], [12582921], [], []
Incident details in: d:\app\administrator\diag\rdbms\hzyl\hzyl\incident\incdir_216664\hzyl_ora_3388_i216664.trc
Errors in file d:\app\administrator\diag\rdbms\hzyl\hzyl\trace\hzyl_ora_3388.trc:
ORA-00600: 内部错误代码, 参数: [2662], [2], [1153862134], [2], [1153864845], [12582921], [], []
Error 600 happened during db open, shutting down database
USER (ospid: 3388): terminating the instance due to error 600
ORA-00600[4000]
Thu Feb 28 19:29:10 2013
SMON: enabling cache recovery
Thu Feb 28 19:29:11 2013
Errors in file /u1/PROD/prodora/db/tech_st/10.2.0/admin/PROD_oracle/udump/prod_ora_20989.trc:
ORA-00600: internal error code, arguments: [4000], [50], [], [], [], [], [], []
Thu Feb 28 19:29:13 2013
Incremental checkpoint up to RBA [0x1.3.0], current log tail at RBA [0x1.3.0]
Thu Feb 28 19:29:13 2013
Errors in file /u1/PROD/prodora/db/tech_st/10.2.0/admin/PROD_oracle/udump/prod_ora_20989.trc:
ORA-00704: bootstrap process failure
ORA-00704: bootstrap process failure
ORA-00600: internal error code, arguments: [4000], [50], [], [], [], [], [], []
ORA-00704 ORA-00604 ORA-01555
Fri May 4 21:04:21 2012
select ctime, mtime, stime from obj$ where obj# = :1
Fri May 4 21:04:21 2012
Errors in file /oracle/admin/standdb/udump/perfdb_ora_1286288.trc:
ORA-00704: bootstrap process failure
ORA-00704: bootstrap process failure
ORA-00604: error occurred at recursive SQL level 1
ORA-01555: snapshot too old: rollback segment number 40 with name "_SYSSMU40$" too small
Error 704 happened during db open, shutting down database
USER: terminating instance due to error 704
Instance terminated by USER, pid = 1286288
ORA-1092 signalled during: alter database open resetlogs...
current/active redo异常还可能报如下错误
redo文件损坏报错
Started redo scan
Errors in file d:\app\administrator\diag\rdbms\hzyl\hzyl\trace\hzyl_ora_2960.trc (incident=214262):
ORA-00353: 日志损坏接近块 12014 更改 9743799889 时间 12/05/2011 09:21:11
ORA-00312: 联机日志 3 线程 1: 'R:\ORADATA\HZYL\REDO03.LOG'
Incident details in: d:\app\administrator\diag\rdbms\hzyl\hzyl\incident\incdir_214262\hzyl_ora_2960_i214262.trc
Aborting crash recovery due to error 368
Errors in file d:\app\administrator\diag\rdbms\hzyl\hzyl\trace\hzyl_ora_2960.trc:
ORA-00368: 重做日志块中的校验和错误
ORA-00353: 日志损坏接近块 12014 更改 9743799889 时间 12/05/2011 09:21:11
ORA-00312: 联机日志 3 线程 1: 'R:\ORADATA\HZYL\REDO03.LOG'
ORA-368 signalled during: ALTER DATABASE OPEN...
redo文件被其他实例占用报错
Wed May 16 17:03:11 2012
Started redo scan
Wed May 16 17:03:11 2012
Errors in file /oracle/admin/odsdb/udump/odsdb1_ora_2040024.trc:
ORA-00305: log 14 of thread 1 inconsistent; belongs to another database
ORA-00312: online log 14 thread 1: '/dev/rods_redo1_2_2'
ORA-00305: log 14 of thread 1 inconsistent; belongs to another database
ORA-00312: online log 14 thread 1: '/dev/rods_redo1_2_1'
ORA-305 signalled during: ALTER DATABASE OPEN...
存储整体异常
Mon Oct 17 09:35:09 2011
Errors in file /oracle/app/admin/orcl/bdump/orcl2_lgwr_348814.trc:
ORA-00340: IO error processing online log 4 of thread 2
ORA-00345: redo log write error block 6732 count 2
ORA-00312: online log 4 thread 2: '/dev/rredo21'
ORA-27063: number of bytes read/written is incorrect
IBM AIX RISC System/6000 Error: 6: No such device or address
Additional information: -1
Additional information: 1024
Mon Oct 17 09:35:09 2011
LGWR: terminating instance due to error 340
存储IO异常
Fri Feb 21 08:44:42 2014
Thread 1 advanced to log sequence 591 (LGWR switch)
Current log# 1 seq# 591 mem# 0: J:\ORADATA\ORCL\REDO01.LOG
Fri Feb 21 15:31:20 2014
Errors in file c:\oracle\product\10.2.0\admin\orcl\bdump\orcl_lgwr_10312.trc:
ORA-00316: log 1 of thread 1, type 286 in header is not log file
ORA-00312: online log 1 thread 1: 'J:\ORADATA\ORCL\REDO01.LOG'
使用_disable_logging参数
Sat May 14 23:16:49 2005
Errors in file d:\oracle\admin\rman\bdump\rman_arc0_736.trc:
ORA-16038: log 3 sequence# 72 cannot be archived
ORA-00354: corrupt redo log block header
ORA-00312: online log 3 thread 1: 'D:\ORACLE\ORADATA\RMAN\REDO03.LOG'
1.1.3.1 current状态日志丢失
SQL> select * from v$version;
BANNER
----------------------------------------------------------------
Oracle Database 10g Enterprise Edition Release 10.2.0.4.0 - 64bi
PL/SQL Release 10.2.0.4.0 - Production
CORE 10.2.0.4.0 Production
TNS for Linux: Version 10.2.0.4.0 - Production
NLSRTL Version 10.2.0.4.0 - Production
SQL> archive log list;
Database log mode Archive Mode
Automatic archival Enabled
Archive destination USE_DB_RECOVERY_FILE_DEST
Oldest online log sequence 5
Next log sequence to archive 7
Current log sequence 7
SQL> select * from v$log;
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIM
---------- ---------- ---------- ---------- ---------- --- ---------------- ------------- ---------
1 1 7 52428800 1 NO CURRENT 661005 11-MAR-15
2 1 5 52428800 1 YES INACTIVE 660997 11-MAR-15
3 1 6 52428800 1 YES INACTIVE 660999 11-MAR-15
SQL> ho ls /u03/app/oracle/oradata/ora1024g/redo01.log
ls: cannot access /u03/app/oracle/oradata/ora1024g/redo01.log: No such file or directory
SQL> shutdown abort;
ORACLE instance shut down.
SQL> startup
ORACLE instance started.
Total System Global Area 448790528 bytes
Fixed Size 2084616 bytes
Variable Size 130023672 bytes
Database Buffers 310378496 bytes
Redo Buffers 6303744 bytes
Database mounted.
ORA-00313: open failed for members of log group 1 of thread 1
ORA-00312: online log 1 thread 1: '/u03/app/oracle/oradata/ora1024g/redo01.log'
ORA-27037: unable to obtain file status
Linux-x86_64 Error: 2: No such file or directory
Additional information: 3
SQL> ALTER DATABASE CLEAR LOGFILE GROUP 1;
ALTER DATABASE CLEAR LOGFILE GROUP 1
*
ERROR at line 1:
ORA-01624: log 1 needed for crash recovery of instance ora1024g (thread 1)
ORA-00312: online log 1 thread 1: '/u03/app/oracle/oradata/ora1024g/redo01.log'
SQL> ALTER DATABASE CLEAR UNARCHIVED LOGFILE GROUP 1;
ALTER DATABASE CLEAR UNARCHIVED LOGFILE GROUP 1
*
ERROR at line 1:
ORA-01624: log 1 needed for crash recovery of instance ora1024g (thread 1)
ORA-00312: online log 1 thread 1: '/u03/app/oracle/oradata/ora1024g/redo01.log'
SQL> alter system set "_allow_resetlogs_corruption"=true scope=spfile;
System altered.
SQL> recover database using backup controlfile;
ORA-00279: change 662207 generated at 03/12/2015 10:08:02 needed for thread 1
ORA-00289: suggestion :
/u03/app/oracle/flash_recovery_area/ORA1024G/archivelog/2015_03_12/o1_mf_1_7_%u_.arc
ORA-00280: change 662207 for thread 1 is in sequence #7
Specify log: {=suggested | filename | AUTO | CANCEL}
ORA-00308: cannot open archived log
'/u03/app/oracle/flash_recovery_area/ORA1024G/archivelog/2015_03_12/o1_mf_1_7_%u_.arc'
ORA-27037: unable to obtain file status
Linux-x86_64 Error: 2: No such file or directory
Additional information: 3
SQL> startup mount force;
ORACLE instance started.
Total System Global Area 409194496 bytes
Fixed Size 2228864 bytes
Variable Size 297799040 bytes
Database Buffers 100663296 bytes
Redo Buffers 8503296 bytes
Database mounted.
SQL> alter database open resetlogs;
alter database open resetlogs
*
ERROR at line 1:
ORA-01113: file 1 needs media recovery
ORA-01110: data file 1: '/u03/app/oracle/oradata/ora1024g/system01.dbf'
SQL> shutdown immediate;
ORA-01109: database not open
Database dismounted.
ORACLE instance shut down.
SQL> startup
ORACLE instance started.
Total System Global Area 448790528 bytes
Fixed Size 2084616 bytes
Variable Size 130023672 bytes
Database Buffers 310378496 bytes
Redo Buffers 6303744 bytes
Database mounted.
ORA-01589: must use RESETLOGS or NORESETLOGS option for database open
SQL> alter database open resetlogs;
alter database open resetlogs
*
ERROR at line 1:
ORA-01092: ORACLE instance terminated. Disconnection forced
SQL> startup force;
ORA-24324: service handle not initialized
ORA-01041: internal error. hostdef extension doesn't exist
SQL> exit
Disconnected from Oracle Database 10g Enterprise Edition Release 10.2.0.4.0 - 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
[oracle@rhel6_lhr ~]$ sqlplus / as sysdba
SQL*Plus: Release 10.2.0.4.0 - Production on Thu Mar 12 10:20:50 2015
Copyright (c) 1982, 2007, Oracle. All Rights Reserved.
Connected to an idle instance.
SQL> startup
ORACLE instance started.
Total System Global Area 448790528 bytes
Fixed Size 2084616 bytes
Variable Size 130023672 bytes
Database Buffers 310378496 bytes
Redo Buffers 6303744 bytes
Database mounted.
Database opened.
SQL> alter system reset "_allow_resetlogs_corruption" scope=spfile sid='*';
System altered.
SQL> archive log list;
Database log mode Archive Mode
Automatic archival Enabled
Archive destination USE_DB_RECOVERY_FILE_DEST
Oldest online log sequence 1
Next log sequence to archive 2
Current log sequence 2
SQL>
重做日志文件在数据库中是要求最高的组件,首先其对磁盘的IO要求极高,其次一旦CURRENT组发生故障,数据库会立即崩溃,并且100%会发生数据丢失,所以ORACLE建议至少每个组需要两个成员,并且在数据库运行过程中日志文件会一直被锁定,以防不测。
Redo log的恢复分为两种:CURRENT 和 非CURRENT
3.1 CURRENT 情况
造成redo 损坏,很多情况是与突然断电有关。这种情况下是比较麻烦的。
(1)如果有归档和备份,可以用不完全恢复。
SQL>startup mount;
SQL>recover database until cancel; 先选择auto,尽量恢复可以利用的归档日志,然后重新执行:
SQL>recover database until cancel; 这次输入cancel,完成不完全恢复,
用resetlogs打开数据:
SQL>alter database open resetlogs; 打开数据库
(2)强制恢复, 这种方法可能会导致数据不一致
sql>startup mount;
sql>alter system set "_allow_resetlogs_corruption"=true scope=spfile;
sql>recover database until cancel;
sql>alter database open resetlogs;
运气好的话,数据库能正常打开,但是由于使用_allow_resetlogs_corruption方式打开,会造成数据的丢失,且数据库的状态不一致。因此,这种情况下Oracle建议通过EXP方式导出数据库。重建新数据库后,再导入。
redo 的损坏,一般还容易伴随以下2种错误:ORA-600[2662](SCN有关)和 ORA-600[4000](回滚段有关)。
metalink上的两篇文章介绍了两种情况的处理方法:
TECH: Summary For Forcing The Database Open With `_ALLOW_RESETLOGS_CORRUPTION` with Automatic Undo Management [ID 283945.1]
http://blog.csdn.net/tianlesoftware/archive/2010/12/29/6106083.aspx
ORA-600 [2662] Block SCN is ahead of Current SCN [ID 28929.1]
http://blog.csdn.net/tianlesoftware/archive/2010/12/29/6106130.aspx
这两种情况下的恢复有点复杂,回头单独做个测试,在补充进来。
3.2 非CURRENT 情况
这种情况下的恢复比较简单,因为redo log 是已经完成归档或者正在归档。 没有正在使用。可以通过v$log 查看redo log 的状态。
(1)如果STATUS是INACTIVE,则表示已经完成了归档,直接清除掉这个redo log即可。
SQL>startup mount;
SQL> alter database clear logfile group 3 ;
SQL>alter database open;
(2)如果STATUS 是ACTIVE ,表示正在归档, 此时需要使用如下语句:
SQL>startup mount;
SQL> alter database clear unarchived logfile group 3 ;
SQL>alter database open;
current online log 损坏有两种恢复方法:
(1)如果有归档和备份,可以用不完全恢复。
SQL>startup mount;
SQL>recover database until cancel; 先选择auto,尽量恢复可以利用的归档日志,然后重新执行:
SQL>recover database until cancel; 这次输入cancel,完成不完全恢复,
用resetlogs打开数据:
SQL>alter database open resetlogs; 打开数据库
(2)强制恢复, 这种方法可能会导致数据不一致
sql>startup mount;
sql>alter system set "_allow_resetlogs_corruption"=true scope=spfile;
sql>recover database until cancel;
sql>alter database open resetlogs;
这里主要看2点:
(1)使用了_allow_resetlogs_corruption 参数
(2)这种情况下,可能会报ORA-600[2662](SCN有关)和 ORA-600[4000](回滚段有关)的错误。
使用_allow_resetlogs_corruption参数,强制的打开数据库,可能会导致逻辑的坏块,从而影响数据字典。 所以,即使使用该参数正常打开后,也需要做的一个操作:逻辑导出数据。 重建实例,导入实例。 消除逻辑坏块的可能性。
如果使用_allow_resetlogs_corruption参数启动报了undo segment的错误而无法启动,处理方法参考第二节中undo 的处理情况。 只要DB 能正常open,就导出数据,重建实例,在导入。
1.1.4 其他

以下命令需要在sqlplus中执行:

Which of the following does the recover command not do? 下列哪项是恢复命令不能做?
A. Restore archived redo logs.还原归档重做日志。
B. Apply archived redo logs.
C. Restore incremental backups.
D. Apply incremental backups.
E. Restore datafile images.
The recover command does not restore datafile images. It does restore and apply archived redo logs and incremental backup images during the recovery process.
Answer: A
Which statement about recovering from the loss of a redo log group is true? 有关重做日志组的损失中恢复,哪种说法是真的?
A. If the lost redo log group is ACTIVE, you should first attempt to clear the log file. B.
If the lost redo log group is CURRENT, you must clear the log file.
C. If the lost redo log group is ACTIVE, you must restore, perform cancel-based incomplete recovery, and
open the database using the RESETLOGS option.
D. If the lost redo log group is CURRENT, you must restore, perform cancel-based incomplete recovery, and
open the database using the RESETLOGS option. 如果丢失的重做日志组是最新的,你必须恢复,执行基于
取消的不完全恢复,并使用重置日志选项打开数据库。
Answer: D
1.1.4.1 联机重做日志文件的恢复(online redo log )
当数据库置为mount状态,且将要转换为open状态时,数据文件,联机日志文件被打开,因此联机日志的丢失可以在mount状态完成
恢复步骤
a. 启动到mount状态(startup mount force)
b. 还原数据库(restore database)
c. 恢复数据库(recover database)
下面对删除日志并进行恢复
lion@ORCL> select * from tb2;
ID NAME
---------- ---------------
2 Jackson
lion@ORCL> select current_scn from v$database; --查看数据库当前的SCN
CURRENT_SCN
-----------
1020638
lion@ORCL> insert into tb2 select 1,'Johnson' from dual; --为表tb2新增一条记录
lion@ORCL> commit;
lion@ORCL> select current_scn from v$database; --数据库当前的SCN发生了变化为
CURRENT_SCN
-----------
1020685
lion@ORCL> select file#, checkpoint_change# from v$datafile_header; --数据文件头部的checkpoint_change
FILE# CHECKPOINT_CHANGE#
---------- ------------------
1 1020368
2 1020368
3 1020368
4 1020368
5 1020368
6 1020368
lion@ORCL> ho rm -f $ORACLE_BASE/oradata/orcl/*.log --删除所有的日志文件 */
lion@ORCL> insert into tb2 select 2,'wilson' from dual; --为表插入新记录
lion@ORCL> commit;
lion@ORCL> select current_scn from v$database; --数据库当前的SCN发生了变化为
CURRENT_SCN
-----------
1020708
lion@ORCL> alter system archive log current; --对日志进行归档时提示错误发生
alter system archive log current
*
ERROR at line 1:
ORA-16038: log 1 sequence# 1 cannot be archived
ORA-00312: online log 1 thread 1: '/u01/oracle/oradata/orcl/redo01.log'
lion@ORCL> conn / as sysdba
sys@ORCL> startup mount force;
[oracle@oradb ~]$ uniread rman target / catalog rman/rman@asmdb --退出RMAN后并重新连接
RMAN> run {
2> allocate channel ch1 device type disk;
3> restore database;
4> recover database;
5> release channel ch1;}
RMAN-06054: media recovery requesting unknown log: thread 1 seq 1 lowscn 1020365
sys@ORCL> recover database until cancel; --回到SQLPlus直接使用until cancel来进行恢复
sys@ORCL> alter database open resetlogs; --执行opensetlogs打开数据库
sys@ORCL> select * from lion.tb2; --在日志未完成自动归档前,删除日志的后数据全部丢失
ID NAME
---------- ---------------
2 Jackson
Which are the correct steps, in order , to deal with the loss of an online redo log if the database has not yet
crashed? 如果数据库尚未崩溃,哪些是按顺序的正确步骤,以处理联机重做日志的丢失?
a. Issue a checkpoint.
b. Shut down the database.
c. Issue an alter database open command to open the database.
d. Startup mount the database.
e. Issue an alter database clear logfile command.
f. Recover all database datafiles.
a.发出一个检查点。
b.关闭数据库。
d.启动挂载数据库。
e.发出改变数据库清除日志文件命令。
c.发出改变数据库打开命令来打开数据库。
A. a, b, c, d
B. b, d, e, c
C. a, b, d, e, c 阿扁得逞
D. b, f, d, f, c
E. b, d, a, c
Answer: C
The database is running in the ARCHIVELOG mode. It has three redo log groups with one member each. One of the redo log groups has become corrupted. You have issued the following command during the recovery of a damaged redo log file: 数据库运行在归档记录模式。它每一个成员都有三个重做日志组。重做日
志组之一已损坏。损坏的重做日志文件的恢复过程中,您已发出以下命令:
ALTER DATABASE CLEAR UNARCHIVED LOGFILE GROUP 3; 改变数据库清除未归档日志文件组3;
Which action should you perform immediately after using this command?
你在使用此命令后应立即执行哪一个活动?
A. You should perform a log switch
B. You should make a backup of the database你应该做一个数据库备份
C. You should switch the database to the NONARCHIVELOG mode
D. You should shut down the database instance and perform a complete database recovery
Answer: B
As soon as you discover that you have lost an online redo log, if the database is still functioning, what
should be your first action?
A. Shut down the database
B. Clear the online redo log
C. Back up the database
D. Checkpoint the database
E. Call Oracle support
Answer: D
1.1.4.2 Loss of a Redo Log File
If a member of a redo log file group is lost and if the group still has at least one member, note the following results:
1. Normal operation of the instance is not affected.
2. You receive a message in the alert log notifying you that a member cannot be found.
3. You can restore the missing log file by dropping the lost redo log member and adding a new member.
4. If the group with the missing log file has been archived you can clear the log group to re-create the missing file.
一、 第一种办法
Recovering from the loss of a single redo log group member should not affect the running instance.
To perform this recovery:
1.Determine whether there is a missing log file by examining the alert log.
2.Restore the missing file by first dropping the lost redo log member:
SQL> ALTER DATABASE DROP LOGFILE MEMBER'+DATA/orcl/onlinelog/group_1.261.691672257';
Then add a new member to replace the lost red log member:
SQL> ALTER DATABASE ADD LOGFILE MEMBER '+DATA' TO GROUP 2;
Enterprise Manager can also be used to drop and re-create the log file member.
Note: If using OMF for your redo log files and you use the above syntax to add a new redo log member to an existing group, that new redo log member file will not be an OMF file. If you want to ensure that the new redo log member is an OMF file, then the easiest recovery option would be to create a new redo log group and then drop the redo log group that had the missing redo log member.
3.If the media failure is due to the loss of a disk drive or controller, rename the missing file.
4.If the group has already been archived, or if you are in NOARCHIVELOG mode, you may choose to solve the problem by clearing the log group to re-create the missing file or files. Select the appropriate group and then select the Clear Logfile action. You can also clear the affected group manually with the following command:
SQL> ALTER DATABASE CLEAR LOGFILE GROUP #;




二、 第二种办法
执行:alter database clear logfile group 1;
ALTER DATABASE CLEAR UNARCHIVED LOGFILE GROUP 1;
3.Your database is in ARCHIVELOG mode.You have two online redo log groups,each of which contains one redo member.When you attempt to start the database,you receive the following errors:
ORA-00313:open failed for members of log group 1 of thread 1
ORA-00312:online log 1 thread 1:'D:\REDO01.LOG'
You discover that the online redo log file of the current redo group is corrupted.
Which statement should you use to resolve this issue?
A.ALTER DATABASE DROP LOGFILE GROUP 1;
B.ALTER DATABASE CLEAR LOGFILE GROUP 1;
C.ALTER DATABASE CLEAR UNARCHIVED LOGFILE GROUP 1;
D.ALTER DATABASE DROP LOGFILE MEMBER'D:\REDO01.LOG';
Answer:C
(答案解析:
参考:http://docs.oracle.com/cd/E11882_01/backup.112/e10642/osadvsce.htm#BRADV90052
[oracle@rtest~]$oerr ora 313
00313,00000,"open failed for members of log group%s of thread%s"
//*Cause:The online log cannot be opened.May not be able to find file.
//*Action:See accompanying errors and make log available.
[oracle@rtest~]$oerr ora 312
00312,00000,"online log%s thread%s:'%s'"
//*Cause:This message reports the filename for details of another message.
//*Action:Other messages will accompany this message.See the
//associated messages for the appropriate action to take.
你的数据库在归档记录模式。你有两个在线重做日志组,其中每个都包含一个重做成员。当您尝试启动数据库时,您会收到以下错误:
ORA-00313:线程1日志组1成员打开失败
ORA-00312:联机日志1线程1:'D:\REDO01.LOG
你发现当前的重做组联机重做日志文件被损坏。你应该使用哪种说法来解决这个问题?
Clearing Inactive,Unarchived Redo
Clearing a not-yet-archived redo log allows it to be reused without archiving it.This action makes backups unusable if they were started before the last change in the log,unless the file was taken offline before the first change in the log.Hence,if you need the cleared log file for recovery of a backup,then you cannot recover that backup.Clearing a not-yet-archived-redo-log,prevents complete recovery from backups due to the missing log.
To clear an inactive,online redo log group that has not been archived:
If the database is shut down,then start a new instance and mount the database:
SQL>STARTUP MOUNT
Clear the log using the UNARCHIVED keyword.
For example,to clear log group 2,issue the following SQL statement:
SQL>ALTER DATABASE CLEAR UNARCHIVED LOGFILE GROUP 2;)
A database has three online redo log groups with one member each. A redo log member with the
status ACTICE is damages while the database is running.
What is the first step you should take to solve this problem?
A.Attempt to Issue a checkpoint.
B.Restart the database using the RESETLOGS option.
C.Drop the redo log number and create it in a different location.
D.Perform and incomplete recovery up to the most recent available redo log.
Answer:A
题目解答 注意在runing 且first
1.1.4.3 Loss of a Redo Log Group
Recovering from the Loss of a Redo Log Group
If you have lost an entire redo log group, then all copies of the log files for that group are unusable or gone.
The simplest case is where the redo log group is in the INACTIVE state. That means it is not currently being written to, and it is no longer needed for instance recovery. If the problem is temporary, or you are able to fix the media, then the database continues to run normally, and the group is reused when enough log switch events occur. Otherwise, if the media cannot be fixed, you can clear the log file. When you clear a log file, you are indicating that it can be reused.
If the redo log group in question is ACTIVE, then, even though it is not currently being written to, it is still needed for instance recovery. If you are able to perform a checkpoint, then the log file group is no longer needed for instance recovery, and you can proceed as if the group were in the inactive state.
If the log group is in the CURRENT state, then it is, or was, being actively written to at the time of the loss. You may even see the LGWR process fail in this case. If this happens, the instance crashes. Your only option at this point is to restore from backup, perform cancel-based point-in-time recovery, and then open the database with the RESETLOGS option.

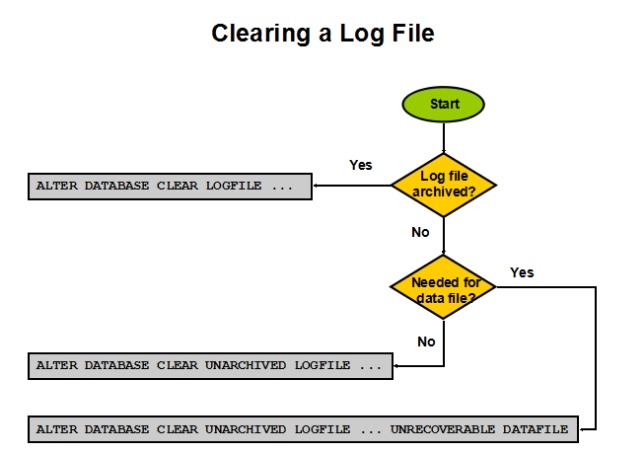
Clearing a Log File
Clear a log file using this command:
ALTER DATABASE CLEAR [UNARCHIVED] LOGFILE GROUP
[UNRECOVERABLE DATAFILE]
When you clear a log file, you are indicating that it can be reused. If the log file has already been archived, the simplest form of the command can be used. Use the following query to determine which log groups have been archived:
SQL> SELECT GROUP#, STATUS, ARCHIVED FROM V$LOG;
For example, the following command clears redo log group 3, which has already been archived:
SQL> ALTER DATABASE CLEAR LOFGILE GROUP 3;
If the redo log group has not been archived, then you must specify the UNARCHIVED keyword. This forces you to acknowledge that it is possible that there are backups that rely on that redo log for recovery, and you have decided to forgo that recovery opportunity. This may be satisfactory for you, especially if you take another backup right after you correct the redo log group problem; you then no longer need that redo log file.
It is possible that the redo log is required to recover a data file that is currently offline.
ocp
A database is running In ARCHIVBXXMS mode. It has two online redo log groups and each group has one member.A LGWR Input/output (I/O) fells due to permanent media failure that has resulted In the loss of redo log file and the LWGR terminates causing the instance to crash. The steps to recover from the loss of a current redo log group member in the random order are as follow.
1) Restore the corrupted redo log group.
2) Restore from a whole database backup.
3) Perform incomplete recovery.
4) Relocate by renaming the member of the damaged online redo log group to a new location.
5) Open the database with the RESETLOGS option.
6) Restart the database instance.
7) Issue a checkpoint and clear the log.
Identify the option with the correct sequential steps to accomplish the task efficiently.
A. 1, 3, 4, and 5
B. 7, 3, 4. and 5
C. 2, 3, 4, and 5
D. 7, 4, 3. and 5
E. Only 6 is required
Answer: C
解答:
To recover from loss of an active online redo log group in ARCHIVELOG mode:
1. Begin incomplete media recovery, recovering up through the log before the damaged log.
2. Ensure that the current name of the lost redo log can be used for a newly created file.
If not, then rename the members of the damaged online redo log group to a new location. For example, enter:
3. ALTER DATABASE RENAME FILE "/disk1/oradata/trgt/redo01.log" TO "/tmp/redo01.log";
4. ALTER DATABASE RENAME FILE "/disk1/oradata/trgt/redo02.log" TO "/tmp/redo02.log";
5. Open the database using the RESETLOGS option:
6. ALTER DATABASE OPEN RESETLOGS;
先不完全恢复在更改日志路径后打开数据库 所以 后面为3,4,5到底是还原备份还是清空日志呢?
Losing an Active Online Redo Log Group
If the database is still running and the lost active redo log is not the current log, then issue the ALTER SYSTEM CHECKPOINT statement. If the operation is successful, then the active redo log becomes inactive, and you can follow the procedure in "Losing an Inactive Online Redo Log Group". If the operation is unsuccessful, or if your database has halted, then perform one of procedures in this section, depending on the archiving mode.
The current log is the one LGWR is currently writing to. If a LGWR I/O operation fails, then LGWR terminates and the instance fails. In this case, you must restore a backup, perform incomplete recovery, and open the database with the RESETLOGS option.
所以先还原备份但如果数据库没有关闭情况下,可以执行switch logfile后触发ckpt 然后在clear的。 很明显7 不需要
SQL> ALTER DATABASE CLEAR logfile group 1;
ALTER DATABASE CLEAR logfile group 1
*
ERROR at line 1:
ORA-00350: log 1 of instance oratest (thread 1) needs to be archived
ORA-00312: online log 1 thread 1: '/u02/app/oracle/oradata/oratest/redo01.log'
SQL> ALTER DATABASE CLEAR unarchived logfile group 1;
Database altered.
SQL> ALTER DATABASE CLEAR unarchived logfile group 2;
Database altered.
SQL> ALTER DATABASE CLEAR unarchived logfile group 3;
Database altered.
SQL>
1.1.4.4 loss all online redo logs
You have lost all your online redo logs. As a result, your database has crashed. You have tried to restart the database and clear the online redo log files, but when you try to open the database you get the following error.
SQL> startup
ORACLE instance started.
Total System Global Area 167395328 bytes
Fixed Size 1298612 bytes
Variable Size 142610252 bytes
Database Buffers 20971520 bytes
Redo Buffers 2514944 bytes
Database mounted.
ORA-00313: open failed for members of log group 2 of thread 1
ORA-00312: online log 2 thread 1: ,,/oracle01/oradata/orcl/redo02a.log
ORA-27037: unable to obtain file status Linux Error: 2: No such file or directory
Additional information: 3
ORA-00312: online log 2 thread 1: ,,/oracle01/oradata/orcl/redo02.log
ORA-27037: unable to obtain file
status Linux Error: 2: No such file or directory Additional information: 3
SQL> alter database clear logfile group 2;
alter database clear logfile group 2
* ERROR at line 1:
ORA-01624: log 2 needed for crash recovery of instance orcl (thread 1) ORA-00312: online log 2 thread
1: ,,/oracle01/oradata/orcl/redo02.log ORA-00312: online log 2 thread
1: ,,/oracle01/oradata/orcl/redo02a.log
What steps must you take to resolve the error?
A. Issue the recover database redo logs command.
B. Issue the Startup Mount command to mount the database.
C. Restore the last full database backup.
D. Perform a point-in-time recovery, applying all archived redo logs that are available.
E. Restore all archived redo logs generated during and after the last full database backup.
F. Open the database using the alter database open resetlogs command.
G. Issue the alter database open command.
A. b, a, f
B. e, b, a, f
C.e, b, a, g
D.b, a, g
E. c, e, b, d, f
Answer: E
You are trying to recover your database. During the recovery process, you receive the following error:
ORA-00279: change 5033391 generated at 08/17/2008 06:37:40 needed for thread 1ORA-00289:
suggestion:
/oracle01/flash_recovery_area/ORCL/archivelog/2008_08_17
/o1_mf_1_11_%u_.arc
ORA-00280: change 5033391 for thread 1 is in sequence #11
ORA-00278: log
file ,,/oracle01/flash_recovery_area/ORCL/archivelog/2008_08_17
/o1_mf_1_10_4bj6wnqm_.arc no longer needed for this recovery Specify log:
{=suggested | filename | AUTO | CANCEL}
ORA-00308: cannot open archived log
,,/oracle01/flash_recovery_area/ORCL/archivelog/2008_08_17
/o1_mf_1_11_%u_.arc
ORA-27037: unable to obtain file status Linux Error: 2: No such file or directory Additional information: 3
How do you respond to this error? (Choose two.)
A. Restore the archived redo log that is missing and attempt recovery again.
B. Recovery is complete and you can open the database.
C. Recovery needs redo that is not available in any archived redo log. Attempt to apply an online redo log if available.
D. Recover the entire database and apply all archived redo logs again.
E. Recovery is not possible because an archived redo log has been lost.
Answer: AC
1.1.4.5 数据库未挂掉的情况下的恢复
参考:【RMAN】rm -rf 误操作的恢复过程----数据库在无备份且open情况下的恢复
1.2 恢复archivelog介绍
Given the following RMAN commands, choose the option that reflects the order required to restore your currently operational ARCHIVELOG-mode database.
A. restore database;
B. recover database;
C. shutdown immediate
D. startup
E. restore archivelog all;
F. alter database open
A. a, b, c, d, e, f
B. c, b, a, d, e, f
C. c, b, a, d, f
D. c, a, b, d
E. c, a, e, b, d, f
Answer: E
还原归档日志通常情况下是Oracle在recover时自动完成的。当数据库出现问题,但不需要restore只需recover时,发现要用到的archivelog已经备份并删除了,因为我们备份archivelog一般是采用delete input的,这时先需要restore archivelog,然后才能做recover,下面介绍一下restore archivelog的用法:
restore archivelog后面可以跟的参数有"all, from, high, like, logseq, low, scn, sequence, time, until"
1.2.1 恢复归档
备份所有归档日志文件
RMAN> backup archivelog all delete input;
1.2.1.1 restore archivelog 的各种选项
1.恢复全部归档日志文件
RMAN> restore archivelog all;
2.只恢复5到8这四个归档日志文件
RMAN> restore archivelog from logseq 5 until logseq 8;
3.恢复从第5个归档日志起
RMAN> restore archivelog from logseq 5;
4.恢复7天内的归档日志
RMAN> restore archivelog from time 'sysdate-7';
5. sequence between 写法
RMAN> restore archivelog sequence between 1 and 3;
6.恢复到哪个日志文件为止
RMAN> restore archivelog until logseq 3;
7.从第五个日志开始恢复
RMAN> restore archivelog low logseq 5;
8.到第5个日志为止
RMAN> restore archivelog high logseq 5;
恢复指定的archivelog:restore archivelog sequence 18;
--若归档日志不在本地,则需要恢复相应的归档日志到本地目录。
run {allocate channel ci type disk;
set archivelog destination to '/tmp';
restore archvielog from logseq xxx until logseq xxx;
release channel ci;
};
1.列出已经备份的archivelog
list backup of archivelog all;
2.预览恢复出程,但不真正恢复,可以在你执行恢复前先看看恢复过程,也可以验证一下你的语法是否写对
restore archivelog all preview; 即在你要执行的restore archivelog命令后加preview
restore archivelog sequence 18 preview;
3.恢复指定时间范围的archivelog
3.1 显示2008-08-13 10:00:00到2008-08-13 11:00:00之间的archivelog
list backup of archivelog time between "to_date('2008-08-13 10:00:00','yyyy-mm-dd hh24:mi:ss')" and "to_date('2008-08-13 11:00:00','yyyy-mm-dd hh24:mi:ss')";
3.2 预览恢复2008-08-13 10:00:00到2008-08-13 11:00:00之间的archivelog
restore archivelog time between "to_date('2008-08-13 10:00:00','yyyy-mm-dd hh24:mi:ss')" and "to_date('2008-08-13 11::00','yyyy-mm-dd hh24:mi:ss')" preview;
3.3 真正恢复2008-08-13 10:00:00到2008-08-13 11:00:00之间的archivelog
restore archivelog time between "to_date('2008-08-13 10:00:00','yyyy-mm-dd hh24:mi:ss')" and "to_date('2008-08-13 11::00','yyyy-mm-dd hh24:mi:ss')"
4.恢复指定的archivelog
restore archivelog sequence 18;
恢复sequence为18的archivelog
5.restore archivelog like恢复模糊查询出来的archivelog,这个只能用于通过catalog的备份,用nocatalog的会报错
restore archivelog like '%18%';
6.恢复指定sequence范围的archivelog
restore archivelog from sequence 18 until sequence 20;
或restore archivelog low sequence 18 high sequence 20;
或restore archivelog low logseq 18 high logseq 20;
restore archivelog from logseq 5;
7.指定archivelog的恢复目的地,如你想把archivelog恢复到一个临时目录时有用,但这个必须包含在run{}里面才能用
set archivelog destination to 'e:\temp';
以上基本上可以解决你恢复archivelog的需求,我是在10.2.0.4版本中测试通过的---------------------------------------------
以下部分是在本人正式环境中遇到的实际情况,非转载:
备份日志中有以下内容:
通道 t1: 正在指定备份集中的存档日志
输入存档日志线程 =1 序列 =18070 记录 ID=35794 时间戳=671966051
输入存档日志线程 =1 序列 =18071 记录 ID=35796 时间戳=671966351
输入存档日志线程 =1 序列 =18072 记录 ID=35798 时间戳=671966652
输入存档日志线程 =1 序列 =18073 记录 ID=35800 时间戳=671966952
输入存档日志线程 =1 序列 =18074 记录 ID=35802 时间戳=671967249
输入存档日志线程 =1 序列 =18075 记录 ID=35804 时间戳=671967550
输入存档日志线程 =1 序列 =18076 记录 ID=35806 时间戳=671967850
输入存档日志线程 =1 序列 =18077 记录 ID=35808 时间戳=671968151
输入存档日志线程 =1 序列 =18078 记录 ID=35810 时间戳=671968451
单独恢复18071 到18076
rman> run
{ allocate channel t1 type 'sbt_tape' parms 'ENV=(tdpo_optfile=/usr/tivoli/tsm/client/oracle/bin64/tdpo.opt)';
restore archivelog from logseq 18071 until logseq 18076 ;
release channel t1;
}
1.备份所有归档日志文件
RMAN> backup archivelog all delete input;
Starting backup at 02-JUN-08
current log archived
using channel ORA_DISK_1
skipping archive log file D:\ARCHPAUL\ARC00001.001; already backed up 1 time(s)
skipping archive log file D:\ARCHPAUL\PUBTEST_1_2.DBF; already backed up 1 time(
s)
skipping archive log file D:\ARCHPAUL\PUBTEST_1_3.DBF; already backed up 1 time(
s)
skipping archive log file D:\ARCHPAUL\PUBTEST_1_4.DBF; already backed up 1 time(
s)
skipping archive log file D:\ARCHPAUL\PUBTEST_1_5.DBF; already backed up 1 time(
s)
skipping archive log file D:\ARCHPAUL\PUBTEST_1_6.DBF; already backed up 1 time(
s)
skipping archive log file D:\ARCHPAUL\PUBTEST_1_7.DBF; already backed up 1 time(
s)
skipping archive log file D:\ARCHPAUL\PUBTEST_1_8.DBF; already backed up 1 time(
s)
skipping archive log file D:\ARCHPAUL\PUBTEST_1_9.DBF; already backed up 1 time(
s)
skipping archive log file D:\ARCHPAUL\PUBTEST_1_10.DBF; already backed up 1 time
(s)
skipping archive log file D:\ARCHPAUL\PUBTEST_1_11.DBF; already backed up 1 time
(s)
skipping archive log file D:\ARCHPAUL\PUBTEST_1_12.DBF; already backed up 1 time
(s)
channel ORA_DISK_1: starting archive log backupset
channel ORA_DISK_1: specifying archive log(s) in backup set
input archive log thread=1 sequence=13 recid=128 stamp=656353510
channel ORA_DISK_1: starting piece 1 at 02-JUN-08
channel ORA_DISK_1: finished piece 1 at 02-JUN-08
piece handle=D:\BACKUP\2QJHUA76_1_1 comment=NONE
channel ORA_DISK_1: backup set complete, elapsed time: 00:00:02
channel ORA_DISK_1: deleting archive log(s)
archive log filename=D:\ARCHPAUL\PUBTEST_1_13.DBF recid=128 stamp=656353510
channel ORA_DISK_1: deleting archive log(s)
archive log filename=D:\ARCHPAUL\ARC00001.001 recid=116 stamp=656352824
archive log filename=D:\ARCHPAUL\PUBTEST_1_2.DBF recid=117 stamp=656353339
archive log filename=D:\ARCHPAUL\PUBTEST_1_3.DBF recid=118 stamp=656353340
archive log filename=D:\ARCHPAUL\PUBTEST_1_4.DBF recid=119 stamp=656353340
archive log filename=D:\ARCHPAUL\PUBTEST_1_5.DBF recid=120 stamp=656353369
archive log filename=D:\ARCHPAUL\PUBTEST_1_6.DBF recid=121 stamp=656353370
archive log filename=D:\ARCHPAUL\PUBTEST_1_7.DBF recid=122 stamp=656353375
archive log filename=D:\ARCHPAUL\PUBTEST_1_8.DBF recid=123 stamp=656353376
archive log filename=D:\ARCHPAUL\PUBTEST_1_9.DBF recid=124 stamp=656353382
archive log filename=D:\ARCHPAUL\PUBTEST_1_10.DBF recid=125 stamp=656353384
archive log filename=D:\ARCHPAUL\PUBTEST_1_11.DBF recid=126 stamp=656353386
archive log filename=D:\ARCHPAUL\PUBTEST_1_12.DBF recid=127 stamp=656353465
Finished backup at 02-JUN-08
Starting Control File and SPFILE Autobackup at 02-JUN-08
piece handle=D:\BACKUP\C-799229701-20080602-0C comment=NONE
Finished Control File and SPFILE Autobackup at 02-JUN-08
第二: restore archivelog 的各种选项
1.restore archivelog all 恢复全部归档日志文件
RMAN> restore archivelog all;
Starting restore at 02-JUN-08
using channel ORA_DISK_1
channel ORA_DISK_1: starting archive log restore to default destination
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=1
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=2
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=3
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=4
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=5
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=6
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=7
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=8
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=9
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=10
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=11
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=12
channel ORA_DISK_1: restored backup piece 1
piece handle=D:\BACKUP\2OJHUA5Q_1_1 tag=TAG20080602T162426 params=NULL
channel ORA_DISK_1: restore complete
channel ORA_DISK_1: starting archive log restore to default destination
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=13
channel ORA_DISK_1: restored backup piece 1
piece handle=D:\BACKUP\2QJHUA76_1_1 tag=TAG20080602T162510 params=NULL
channel ORA_DISK_1: restore complete
Finished restore at 02-JUN-08
RMAN>
2.只恢复 5到8这四个归档日志文件
RMAN> restore archivelog from logseq 5 until logseq 8;
Starting restore at 02-JUN-08
using channel ORA_DISK_1
channel ORA_DISK_1: starting archive log restore to default destination
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=5
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=6
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=7
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=8
channel ORA_DISK_1: restored backup piece 1
piece handle=D:\BACKUP\2OJHUA5Q_1_1 tag=TAG20080602T162426 params=NULL
channel ORA_DISK_1: restore complete
Finished restore at 02-JUN-08
3.恢复从第5个归档日志起
RMAN> restore archivelog from logseq 5;
Starting restore at 02-JUN-08
using channel ORA_DISK_1
channel ORA_DISK_1: starting archive log restore to default destination
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=5
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=6
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=7
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=8
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=9
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=10
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=11
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=12
channel ORA_DISK_1: restored backup piece 1
piece handle=D:\BACKUP\2OJHUA5Q_1_1 tag=TAG20080602T162426 params=NULL
channel ORA_DISK_1: restore complete
channel ORA_DISK_1: starting archive log restore to default destination
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=13
channel ORA_DISK_1: restored backup piece 1
piece handle=D:\BACKUP\2QJHUA76_1_1 tag=TAG20080602T162510 params=NULL
channel ORA_DISK_1: restore complete
Finished restore at 02-JUN-08
RMAN>
4.恢复7天内的归档日志
RMAN> restore archivelog from time 'sysdate-7';
Starting restore at 02-JUN-08
using channel ORA_DISK_1
channel ORA_DISK_1: starting archive log restore to default destination
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=1
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=2
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=3
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=4
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=5
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=6
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=7
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=8
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=9
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=10
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=11
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=12
channel ORA_DISK_1: restored backup piece 1
piece handle=D:\BACKUP\2OJHUA5Q_1_1 tag=TAG20080602T162426 params=NULL
channel ORA_DISK_1: restore complete
channel ORA_DISK_1: starting archive log restore to default destination
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=13
channel ORA_DISK_1: restored backup piece 1
piece handle=D:\BACKUP\2QJHUA76_1_1 tag=TAG20080602T162510 params=NULL
channel ORA_DISK_1: restore complete
Finished restore at 02-JUN-08
RMAN>
5. sequence between 写法
RMAN> restore archivelog sequence between 1 and 3;
Starting restore at 02-JUN-08
allocated channel: ORA_DISK_1
channel ORA_DISK_1: sid=10 devtype=DISK
channel ORA_DISK_1: starting archive log restore to default destination
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=1
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=2
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=3
channel ORA_DISK_1: restored backup piece 1
piece handle=D:\BACKUP\2OJHUA5Q_1_1 tag=TAG20080602T162426 params=NULL
channel ORA_DISK_1: restore complete
Finished restore at 02-JUN-08
6.恢复到哪个日志文件为止
RMAN> restore archivelog until logseq 3;
Starting restore at 02-JUN-08
using channel ORA_DISK_1
channel ORA_DISK_1: starting archive log restore to default destination
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=1
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=2
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=3
channel ORA_DISK_1: restored backup piece 1
piece handle=D:\BACKUP\2OJHUA5Q_1_1 tag=TAG20080602T162426 params=NULL
channel ORA_DISK_1: restore complete
Finished restore at 02-JUN-08
6.从第五个日志开始恢复
RMAN> restore archivelog low logseq 5;
Starting restore at 02-JUN-08
using channel ORA_DISK_1
channel ORA_DISK_1: starting archive log restore to default destination
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=5
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=6
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=7
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=8
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=9
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=10
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=11
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=12
channel ORA_DISK_1: restored backup piece 1
piece handle=D:\BACKUP\2OJHUA5Q_1_1 tag=TAG20080602T162426 params=NULL
channel ORA_DISK_1: restore complete
channel ORA_DISK_1: starting archive log restore to default destination
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=13
channel ORA_DISK_1: restored backup piece 1
piece handle=D:\BACKUP\2QJHUA76_1_1 tag=TAG20080602T162510 params=NULL
channel ORA_DISK_1: restore complete
Finished restore at 02-JUN-08
RMAN>
7.到第5个日志为止
RMAN> restore archivelog high logseq 5;
Starting restore at 02-JUN-08
allocated channel: ORA_DISK_1
channel ORA_DISK_1: sid=14 devtype=DISK
channel ORA_DISK_1: starting archive log restore to default destination
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=1
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=2
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=3
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=4
channel ORA_DISK_1: restoring archive log
archive log thread=1 sequence=5
channel ORA_DISK_1: restored backup piece 1
piece handle=D:\BACKUP\2OJHUA5Q_1_1 tag=TAG20080602T162426 params=NULL
channel ORA_DISK_1: restore complete
Finished restore at 02-JUN-08
如果想改变恢复到另外路径下则可用下面语句
set archivelog destination to 'd:\backup';
RMAN> run
2> {allocate channel ci type disk;
3> set archivelog destination to 'd:\backup';
4> restore archivelog all;
5> release channel ci;
6> }
allocated channel: ci
channel ci: sid=10 devtype=DISK
executing command: SET ARCHIVELOG DESTINATION
Starting restore at 02-JUN-08
channel ci: starting archive log restore to user-specified destination
archive log destination=d:\backup
channel ci: restoring archive log
archive log thread=1 sequence=1
channel ci: restoring archive log
archive log thread=1 sequence=2
channel ci: restoring archive log
archive log thread=1 sequence=3
channel ci: restoring archive log
archive log thread=1 sequence=4
channel ci: restoring archive log
archive log thread=1 sequence=5
channel ci: restoring archive log
archive log thread=1 sequence=6
channel ci: restoring archive log
archive log thread=1 sequence=7
channel ci: restoring archive log
archive log thread=1 sequence=8
channel ci: restoring archive log
archive log thread=1 sequence=9
channel ci: restoring archive log
archive log thread=1 sequence=10
channel ci: restoring archive log
archive log thread=1 sequence=11
channel ci: restoring archive log
archive log thread=1 sequence=12
channel ci: restored backup piece 1
piece handle=D:\BACKUP\2OJHUA5Q_1_1 tag=TAG20080602T162426 params=NULL
channel ci: restore complete
channel ci: starting archive log restore to user-specified destination
archive log destination=d:\backup
channel ci: restoring archive log
archive log thread=1 sequence=13
channel ci: restored backup piece 1
piece handle=D:\BACKUP\2QJHUA76_1_1 tag=TAG20080602T162510 params=NULL
channel ci: restore complete
Finished restore at 02-JUN-08
released channel: ci
--------------------------------------------------------------------------------------------
Oracle数据库使用RMAN备份的时候,会把归档日志压成备份集(backup set),而有时候我们为了恢复数据的需要可能需要从这些备份集中解析出归档日志(archive log),这时可以用restore这个命令。
该命令的参数可以用SCN、SEQUENCE、TIME等,也可以附加preview参数先查看计划,该参数和list backup of archivelog是等效的。
1、根据时间查看需要的备份集:
ERPDB1@/orabak>rman target /
RMAN> list backup of archivelog time between "to_date('2009-06-24 08:00:00','yyyy-mm-dd hh24:mi:ss')" and "to_date('2009-06-24 13:00','yyyy-mm-dd hh24:mi:ss')";
以下是示例,并非原来的文件列表:
BS Key Size Device Type Elapsed Time Completion Time
------- ---------- ----------- ------------ ---------------
18021 104.97M DISK 00:00:25 02-APR-10
BP Key: 21243 Status: AVAILABLE Compressed: YES Tag: TAG20100402T213015
Piece Name: /orabak/arch/CNDERPDB_arch_20100402_715296294_18088_1
List of Archived Logs in backup set 18021
Thrd Seq Low SCN Low Time Next SCN Next Time
---- ------- ---------- --------- ---------- ---------
1 130930 12425302024 02-APR-10 12425464067 02-APR-10
1 130931 12425464067 02-APR-10 12425612482 02-APR-10
1 130932 12425612482 02-APR-10 12425741312 02-APR-10
1 130933 12425741312 02-APR-10 12425903002 02-APR-10
1 130934 12425903002 02-APR-10 12426033120 02-APR-10
1 130935 12426033120 02-APR-10 12426231614 02-APR-10
1 130936 12426231614 02-APR-10 12426258334 02-APR-10
或者用preview查看:
RMAN> restore archivelog time between "to_date('2009-06-24 08:00:00','yyyy-mm-dd hh24:mi:ss')" and "to_date('2009-06-24 13:00','yyyy-mm-dd hh24:mi:ss')" preview;
也可以先指定时间格式,然后就可以不用to_date函数了:
RMAN> SQL 'ALTER SESSION SET NLS_DATE_FORMAT="YYYY-MM-DD:HH24:MI:SS"';
RMAN> restore archivelog time between '2009-06-24 09:00:00' and '2009-06-24 12:00:00' preview;
2、把备份集文件COPY到默认的归档路径中
我这里是/orabak/arch,从第一步文件列表的Piece Name也可以看出来归档的路径。
否则在restore过程中会报以下错误:
channel ORA_DISK_1: reading from backup piece /orabak/arch/ERPDB_arch_20090624_690383375_14453_1
ORA-19870: error reading backup piece /orabak/arch/ERPDB_arch_20090624_690383375_14453_1
ORA-19505: failed to identify file "/orabak/arch/ERPDB_arch_20090624_690383375_14453_1"
ORA-27037: unable to obtain file status
IBM AIX RISC System/6000 Error: 2: No such file or directory
Additional information: 3
3、执行restore命令,一般如果是临时需要这些文件,可以指定归档日志恢复到其他的目录,这时必须用run命令:
RMAN> run {
2> set archivelog destination to '/orabak/testarch';
3> SQL 'ALTER SESSION SET NLS_DATE_FORMAT="YYYY-MM-DD:HH24:MI:SS"';
4> restore archivelog time between '2009-06-24 09:00:00' and '2009-06-24 12:10:00';
5> }
executing command: SET ARCHIVELOG DESTINATION
using target database control file instead of recovery catalog
sql statement: ALTER SESSION SET NLS_DATE_FORMAT="YYYY-MM-DD:HH24:MI:SS"
Starting restore at 29-JUN-09
allocated channel: ORA_DISK_1
......
Finished restore at 29-JUN-09
如果我们明确要恢复哪些归档日志,可以用SEQUENCE BETWEEN integer1 AND integer2命令来操作。
同一个RUN块中允许同时出现多个SET ARCHIVELOG命令,也就是说可以通过在不同位置设置不同的归档路径的方式,将归档恢复到不同的目录,例如:
1.RMAN>RUN{
2.2>SET ARCHIVELOG DESTINATION TO'F:\ORACLE\BACKUP\ARCLOG1'; 3.3> RESTORE ARCHIVELOG SEQUENCEBETWEEN 15 AND 20;
4.4>SET ARCHIVELOG DESTINATION TO'F:\ORACLE\BACKUP\ARCLOG2'; 5.5> RESTORE ARCHIVELOG SEQUENCEBETWEEN 21 AND 30;
6.6>SET ARCHIVELOG DESTINATION TO'F:\ORACLE\BACKUP\ARCLOG3'; 7.7> RESTORE ARCHIVELOG SEQUENCEBETWEEN 31 AND 40; 8.8> }
1.2.2 我的例子
[oracle@rhel6_lhr ~]$ rman target /
Recovery Manager: Release 11.2.0.3.0 - Production on Mon Jan 5 16:09:02 2015
Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved.
connected to target database: ORCLASM (DBID=3424884828)
RUN
{
SET ARCHIVELOG DESTINATION TO '/home/oracle';
restore archivelog from time 'sysdate-1';
}
executing command: SET ARCHIVELOG DESTINATION
using target database control file instead of recovery catalog
Starting restore at 05-JAN-15
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=16 device type=DISK
channel ORA_DISK_1: starting archived log restore to user-specified destination
archived log destination=/home/oracle
channel ORA_DISK_1: restoring archived log
archived log thread=1 sequence=910
channel ORA_DISK_1: restoring archived log
archived log thread=1 sequence=911
channel ORA_DISK_1: restoring archived log
archived log thread=1 sequence=912
channel ORA_DISK_1: reading from backup piece /home/oracle/oracle_bk/orclasm/arch_ORCLASM_20150105_200_1.bak
channel ORA_DISK_1: piece handle=/home/oracle/oracle_bk/orclasm/arch_ORCLASM_20150105_200_1.bak tag=TAG20150105T120650
channel ORA_DISK_1: restored backup piece 1
channel ORA_DISK_1: restore complete, elapsed time: 00:00:15
channel ORA_DISK_1: starting archived log restore to user-specified destination
archived log destination=/home/oracle
channel ORA_DISK_1: restoring archived log
archived log thread=1 sequence=913
channel ORA_DISK_1: reading from backup piece /home/oracle/oracle_bk/orclasm/arch_ORCLASM_20150105_201_1.bak
channel ORA_DISK_1: piece handle=/home/oracle/oracle_bk/orclasm/arch_ORCLASM_20150105_201_1.bak tag=TAG20150105T120650
channel ORA_DISK_1: restored backup piece 1
channel ORA_DISK_1: restore complete, elapsed time: 00:00:01
Finished restore at 05-JAN-15
RMAN> run {
2> SET ARCHIVELOG DESTINATION TO '/home/oracle';
3> restore archivelog from time 'sysdate-1';
4> }
executing command: SET ARCHIVELOG DESTINATION
Starting restore at 05-JAN-15
using channel ORA_DISK_1
archived log for thread 1 with sequence 910 is already on disk as file /home/oracle/1_910_850260255.dbf
archived log for thread 1 with sequence 911 is already on disk as file /home/oracle/1_911_850260255.dbf
archived log for thread 1 with sequence 912 is already on disk as file /home/oracle/1_912_850260255.dbf
archived log for thread 1 with sequence 913 is already on disk as file /home/oracle/1_913_850260255.dbf
restore not done; all files read only, offline, or already restored
Finished restore at 05-JAN-15
RMAN> show all
2> ;
RMAN configuration parameters for database with db_unique_name ORCLASM are:
CONFIGURE RETENTION POLICY TO RECOVERY WINDOW OF 7 DAYS;
CONFIGURE BACKUP OPTIMIZATION ON;
CONFIGURE DEFAULT DEVICE TYPE TO DISK;
CONFIGURE CONTROLFILE AUTOBACKUP ON;
CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO '/home/oracle/oracle_bk/orclasm/control_%F.bak';
CONFIGURE DEVICE TYPE DISK PARALLELISM 1 BACKUP TYPE TO BACKUPSET; # default
CONFIGURE DATAFILE BACKUP COPIES FOR DEVICE TYPE DISK TO 1; # default
CONFIGURE ARCHIVELOG BACKUP COPIES FOR DEVICE TYPE DISK TO 1; # default
CONFIGURE CHANNEL DEVICE TYPE DISK FORMAT '/home/oracle/oracle_bk/orclasm/%U_%d.bak';
CONFIGURE MAXSETSIZE TO UNLIMITED; # default
CONFIGURE ENCRYPTION FOR DATABASE OFF; # default
CONFIGURE ENCRYPTION ALGORITHM 'AES128'; # default
CONFIGURE COMPRESSION ALGORITHM 'BASIC' AS OF RELEASE 'DEFAULT' OPTIMIZE FOR LOAD TRUE ; # default
CONFIGURE ARCHIVELOG DELETION POLICY TO BACKED UP 1 TIMES TO DISK;
CONFIGURE SNAPSHOT CONTROLFILE NAME TO '/u01/app/oracle/product/11.2.0/dbhome_1/dbs/snapcf_orclasm.f'; # default
RMAN>
RMAN> run {
2> SET ARCHIVELOG DESTINATION TO '/home/oracle';
3> restore archivelog low logseq 914;
4> }
executing command: SET ARCHIVELOG DESTINATION
Starting restore at 05-JAN-15
using channel ORA_DISK_1
archived log for thread 1 with sequence 914 is already on disk as file +FRA/orclasm/archivelog/2015_01_05/thread_1_seq_914.453.868206267
archived log for thread 1 with sequence 915 is already on disk as file +FRA/orclasm/archivelog/2015_01_05/thread_1_seq_915.435.868206269
archived log for thread 1 with sequence 916 is already on disk as file +FRA/orclasm/archivelog/2015_01_05/thread_1_seq_916.310.868206275
archived log for thread 1 with sequence 917 is already on disk as file +FRA/orclasm/archivelog/2015_01_05/thread_1_seq_917.307.868206283
archived log for thread 1 with sequence 918 is already on disk as file +FRA/orclasm/archivelog/2015_01_05/thread_1_seq_918.374.868206387
archived log for thread 1 with sequence 919 is already on disk as file +FRA/orclasm/archivelog/2015_01_05/thread_1_seq_919.361.868206393
restore not done; all files read only, offline, or already restored
Finished restore at 05-JAN-15
RMAN> backup archivelog all delete input;
Starting backup at 05-JAN-15
current log archived
using channel ORA_DISK_1
skipping archived logs of thread 1 from sequence 910 to 913; already backed up
channel ORA_DISK_1: starting archived log backup set
channel ORA_DISK_1: specifying archived log(s) in backup set
input archived log thread=1 sequence=914 RECID=914 STAMP=868206269
input archived log thread=1 sequence=915 RECID=915 STAMP=868206269
input archived log thread=1 sequence=916 RECID=916 STAMP=868206275
input archived log thread=1 sequence=917 RECID=917 STAMP=868206282
input archived log thread=1 sequence=918 RECID=918 STAMP=868206386
input archived log thread=1 sequence=919 RECID=919 STAMP=868206392
input archived log thread=1 sequence=920 RECID=920 STAMP=868206525
channel ORA_DISK_1: starting piece 1 at 05-JAN-15
channel ORA_DISK_1: finished piece 1 at 05-JAN-15
piece handle=/home/oracle/oracle_bk/orclasm/6cprvhtt_1_1_ORCLASM.bak tag=TAG20150105T162845 comment=NONE
channel ORA_DISK_1: backup set complete, elapsed time: 00:00:03
channel ORA_DISK_1: deleting archived log(s)
archived log file name=+FRA/orclasm/archivelog/2015_01_05/thread_1_seq_914.453.868206267 RECID=914 STAMP=868206269
archived log file name=+FRA/orclasm/archivelog/2015_01_05/thread_1_seq_915.435.868206269 RECID=915 STAMP=868206269
archived log file name=+FRA/orclasm/archivelog/2015_01_05/thread_1_seq_916.310.868206275 RECID=916 STAMP=868206275
archived log file name=+FRA/orclasm/archivelog/2015_01_05/thread_1_seq_917.307.868206283 RECID=917 STAMP=868206282
archived log file name=+FRA/orclasm/archivelog/2015_01_05/thread_1_seq_918.374.868206387 RECID=918 STAMP=868206386
archived log file name=+FRA/orclasm/archivelog/2015_01_05/thread_1_seq_919.361.868206393 RECID=919 STAMP=868206392
archived log file name=+FRA/orclasm/archivelog/2015_01_05/thread_1_seq_920.318.868206525 RECID=920 STAMP=868206525
channel ORA_DISK_1: deleting archived log(s)
archived log file name=/home/oracle/1_910_850260255.dbf RECID=911 STAMP=868205361
archived log file name=/home/oracle/1_911_850260255.dbf RECID=912 STAMP=868205362
archived log file name=/home/oracle/1_912_850260255.dbf RECID=910 STAMP=868205357
archived log file name=/home/oracle/1_913_850260255.dbf RECID=913 STAMP=868205368
Finished backup at 05-JAN-15
Starting Control File and SPFILE Autobackup at 05-JAN-15
piece handle=/home/oracle/oracle_bk/orclasm/control_c-3424884828-20150105-03.bak comment=NONE
Finished Control File and SPFILE Autobackup at 05-JAN-15
RMAN> run {
2> SET ARCHIVELOG DESTINATION TO '/home/oracle';
3> restore archivelog low logseq 914;}
executing command: SET ARCHIVELOG DESTINATION
Starting restore at 05-JAN-15
using channel ORA_DISK_1
channel ORA_DISK_1: starting archived log restore to user-specified destination
archived log destination=/home/oracle
channel ORA_DISK_1: restoring archived log
archived log thread=1 sequence=914
channel ORA_DISK_1: restoring archived log
archived log thread=1 sequence=915
channel ORA_DISK_1: restoring archived log
archived log thread=1 sequence=916
channel ORA_DISK_1: restoring archived log
archived log thread=1 sequence=917
channel ORA_DISK_1: restoring archived log
archived log thread=1 sequence=918
channel ORA_DISK_1: restoring archived log
archived log thread=1 sequence=919
channel ORA_DISK_1: restoring archived log
archived log thread=1 sequence=920
channel ORA_DISK_1: reading from backup piece /home/oracle/oracle_bk/orclasm/6cprvhtt_1_1_ORCLASM.bak
channel ORA_DISK_1: piece handle=/home/oracle/oracle_bk/orclasm/6cprvhtt_1_1_ORCLASM.bak tag=TAG20150105T162845
channel ORA_DISK_1: restored backup piece 1
channel ORA_DISK_1: restore complete, elapsed time: 00:00:03
Finished restore at 05-JAN-15
RMAN>
RUN
{
SET ARCHIVELOG DESTINATION TO '/tmp/';
RESTORE ARCHIVELOG SEQUENCE between 919 and 920;
}
executing command: SET ARCHIVELOG DESTINATION
Starting restore at 2015-01-20 17:09:38
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=413 device type=DISK
channel ORA_DISK_1: starting archived log restore to user-specified destination
archived log destination=/tmp/
channel ORA_DISK_1: restoring archived log
archived log thread=1 sequence=919
channel ORA_DISK_1: restoring archived log
archived log thread=1 sequence=920
channel ORA_DISK_1: reading from backup piece /home/oracle/oracle_bk/orclasm/6cprvhtt_1_1_ORCLASM.bak
channel ORA_DISK_1: piece handle=/home/oracle/oracle_bk/orclasm/6cprvhtt_1_1_ORCLASM.bak tag=TAG20150105T162845
channel ORA_DISK_1: restored backup piece 1
channel ORA_DISK_1: restore complete, elapsed time: 00:00:01
Finished restore at 2015-01-20 17:09:40
1.2.3 怎样清除v$archived_log视图中的过期信息
在操作系统上删除这些归档并不会在控制文件中有记录,所以查看v$archived_log时还会有记录,考虑用RMAN来删除:
RMAN>delete archivelog all;
之后再查看v$archived_log发现还有记录。google了下怎么解决,有三种方法。
相关阅读: Oracle手工恢复案例(非归档模式) http://www.linuxidc.com/Linux/2013-06/86718.htm
1.重建控制文件,例如 backup controlfileto trace后重建该控制文件,但要求有数据文件均存在。
2.设置control_file_record_keep_time=0 然后等待记录被重用,这样很不好。
3.使用包来清理,注意不要在生产库上这么做
PROCEDURE resetCfileSection(record_typeINbinary_integer);
– This procedure attemptsto reset the circular controlfilesection.
– Input parameters:
– record_type
– The circular record type whose controlfile sectionisto be reset.
execute sys.dbms_backup_restore.resetCfileSection(11); ==> 清理v$ARCHIVED_LOG对应的记录
execute sys.dbms_backup_restore.resetCfileSection(28); ==>清理v$rman_status对应的记录
Removing entries in v$archived_log referencing a particluar DEST_ID [ID 845361.1]
Applies to:
Oracle Server – Enterprise Edition – Version: 10.2.0.3 and later [Release: 10.2 and later ]
Information in this document applies to any platform.
Goal
This note provides instructions on how to clear the section in the controlfile which contains data referencing v$archived_log.
For example v$archived_log may contain data from dest_id = 1 & dest_id=2.
This note will guide you through the process of only keeping entries from one distinct location
Solution
It is possible to clear different section of the controlfile.
Section 11 refers to the v$archived_log entries.
SQL>execute sys.dbms_backup_restore.resetCfileSection( 11);
This will clear all files in v$archived_log;
Then using RMAN we can catalog the DEST=1 file back in.
Assume that all archivelogs reside in /recovery_area/archives
RMAN> catalog start with '/recovery_area/archives';
This will update the controlfile with these entries only.
NOTE:
If you clear a controlfile section using undocumented event, then you also need to update high_al_recid in the node table for that database to 0 in
recovery catalog.
For 11g recovery catalog schema and above:
update node set high_al_recid = 0 where db_unique_name = '
For 10gR2 recovery catalog schema and below:
update dbinc set high_al_recid = 0 where db_name = '';
在使用RMAN命令删除归档后,查询v$archived_log视图会发现name列为空了,但其他列的信息还保留,时间长了会留下很多过期的信息,影响维护工作,需要将过期的信息删除。首先模拟下问题的出现过程:
--删除归档日志之前查看v$archived_log视图,情况正常
SQL> select dest_id,sequence#,name,blocks from v$archived_log;
DEST_ID SEQUENCE# NAME BLOCKS
---------- ---------- --------------------------------------------- ----------
1 101 /oradata/archive/orcl_1_101_851966182.arc 2730
1 102 /oradata/archive/orcl_1_102_851966182.arc 95711
1 103 /oradata/archive/orcl_1_103_851966182.arc 94813
1 104 /oradata/archive/orcl_1_104_851966182.arc 95048
1 105 /oradata/archive/orcl_1_105_851966182.arc 94677
1 106 /oradata/archive/orcl_1_106_851966182.arc 97494
1 107 /oradata/archive/orcl_1_107_851966182.arc 94300
1 108 /oradata/archive/orcl_1_108_851966182.arc 97494
--使用RAMN命令删除归档
RMAN> delete archivelog all;
--再次查询v$archived_log视图,name列为空
SQL> select dest_id,sequence#,name,blocks from v$archived_log;
DEST_ID SEQUENCE# NAME BLOCKS
---------- ---------- --------------------------------------------- ----------
1 101 2730
1 102 95711
1 103 94813
1 104 95048
1 105 94677
1 106 97494
1 107 94300
1 108 97494
出现这样的现象是因为使用RMAN命令在删除归档日志的时候不能够清楚控制文件中的内容,导致v$archived_log留下的过期的不完整信息。下面将归档信息进行清除:
--清除控制文件中关于v$archived_log的信息
SQL> execute sys.dbms_backup_restore.resetCfileSection(11);
PL/SQL procedure successfully completed.
--再次查询v$archived_log,信息已经被清除
SQL> select dest_id,sequence#,name,blocks from v$archived_log;
no rows selected
但是这样是把所有的v$archive_log信息都清除了,包括未过期的也会不清除。下面再将未过期的归档文件信息注册进来。
--我测试环境上归档日志都在/oradata/archive/中
RMAN> catalog start with '/oradata/archive/';
--再次查询v$archived_log,未被删除的归档信息可以查询到了
SQL> select dest_id,sequence#,name,blocks from v$archived_log;
DEST_ID SEQUENCE# NAME BLOCKS
---------- ---------- --------------------------------------------- ----------
1 110 /oradata/archive/orcl_1_110_851966182.arc 1
1 111 /oradata/archive/orcl_1_111_851966182.arc 2
1 109 /oradata/archive/orcl_1_109_851966182.arc 31079
About Me
...............................................................................................................................
● 本文作者:小麦苗,只专注于数据库的技术,更注重技术的运用
● 本文在itpub(http://blog.itpub.net/26736162)、博客园(http://www.cnblogs.com/lhrbest)和个人微信公众号(xiaomaimiaolhr)上有同步更新
● 本文itpub地址:http://blog.itpub.net/26736162/abstract/1/
● 本文博客园地址:http://www.cnblogs.com/lhrbest
● 本文pdf版及小麦苗云盘地址:http://blog.itpub.net/26736162/viewspace-1624453/
● 数据库笔试面试题库及解答:http://blog.itpub.net/26736162/viewspace-2134706/
● QQ群:230161599 微信群:私聊
● 联系我请加QQ好友(646634621),注明添加缘由
● 于 2017-07-01 09:00 ~ 2017-07-31 22:00 在魔都完成
● 文章内容来源于小麦苗的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
● 版权所有,欢迎分享本文,转载请保留出处
...............................................................................................................................
拿起手机使用微信客户端扫描下边的左边图片来关注小麦苗的微信公众号:xiaomaimiaolhr,扫描右边的二维码加入小麦苗的QQ群,学习最实用的数据库技术。






【恢复】Redo日志文件丢失的恢复的更多相关文章
- 关于数据库一致改关闭下redo日志文件丢失的处理办法的总结
数据库一致性关闭下redo日志文件丢失的处理办法(归档和非归档都行) 1. inactive log 在一致性关闭后删除重启时可以在mount下(不丢失数据) alter database clea ...
- oracle redo日志文件损坏恢复
参考:How to Recover from Loss Of Online Redo Log And ORA-312 And ORA-313 (Doc ID 117481.1) 在线重做日志文件丢失后 ...
- 【恢复】 Redo文件丢失的恢复
第一章 Redo文件丢失的恢复 1.1 online redolog file 丢失 联机Redo日志是Oracle数据库中比较核心的文件,当Redo日志文件异常之后,数据库就无法正常启动,而且有丢 ...
- 记录SQL Server2008日志文件损坏的恢复过程
记录SQL Server2008日志文件损坏的恢复过程: 环境: 系 统:Windows Server2003 数据库:SQL Server2008 故障原因: 通过mstsc链接同一服务器时,用户界 ...
- RMAN数据库恢复之恢复归档日志文件
恢复归档日志文件如果只是为了在恢复数据文件之后应用归档文件,那并不需要手动对归档文件进行恢复,RMAN会在RECOVER时自动对适当的归档进行恢复.单独恢复归档文件一般是有特别的需求,如创建了Data ...
- (Les16 执行数据库恢复)-重做日志文件恢复
丢失重做日志文件 丢失了重做日志文件组中的某个成员,并且组中至少还有一个成员: -不会影响实例的正常操作. -预警日志中会收到一条信息, ...
- 电脑中dll文件丢失怎么恢复?
DLL文件是Windows系统中的动态链接文件,我们在运行程序时都必须链接到dll文件,如果缺少了则无法正常运行,相信大家都会遇到dll文件缺失的情况,那么电脑中dll文件丢失怎么恢复?下面装机之家分 ...
- MySQL中的 redo 日志文件
MySQL中的 redo 日志文件 MySQL中有三种日志文件,redo log.bin log.undo log.redo log 是 存储引擎层(innodb)生成的日志,主要为了保证数据的可靠性 ...
- Oracle控制文件丢失,日志文件丢失
控制文件丢失: alter database backup controlfile to traces; shutdown immediate; @j:\db\script\orcl_ora_ctl_ ...
随机推荐
- 二分查找java实现
二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法.但是,折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列. 二分查找思路非常简单,由粗暴的遍历查找改为 ...
- Linux环境配置与项目部署
简介: Linux是一类Unix计算机操作系统的统称.Linux操作系统的内核的名字也是“Linux”.Linux操作系统也是自由软件和开放源代码发展中最著名的例子.严格来讲,Linux这个词本身只表 ...
- [RN] React Native 定义全局变量
React Native 定义全局变量 React Native全局变量的两种使用方式 一.导出和导入 // 定义的页面 global.js var global = {authorization: ...
- python3 ini文件读写
import configparser config = configparser.ConfigParser() file = 'config.ini' config.read(file) confi ...
- 紧随时代的步伐--Java8之Lambda表达式的使用
1.前言 在计算机行业,每天都会有新的技术诞生,每天都会有上百种的技术更新升级.追随时代的步伐,终生学习,才能不被社会的浪潮淘汰. 2.关于Lambda表达式 Lambda表达式是Java8新特性之一 ...
- [Gamma] 项目展示
[Gamma] 项目展示 一.工程展示 1.项目简介 定位分析 我们的目标是做一个创意分享网站,在之前的阶段中完成了大框架的搭建,并以此为基础进行界面优化与功能扩展. 典型用户 用户 面临困境 需求功 ...
- linux quota磁盘限额,引发的rename系统调用 errno:18 - Invalid cross-device link
起因: log4j日志滚动失败,debug发现jvm调用native方法rename失败,也就是系统调用rename失败. 自己写c程序系统调用rename,证实确实是这个问题. 日志打在容器里,日志 ...
- SharePoint - Another Way to Delete Site Collection
I had created a site collection. But there is a problem of web-frontend server (I did not know when ...
- Shell脚本之八 函数
一.函数定义 Linux shell 可以用户定义函数,然后在shell脚本中可以随便调用. shell中函数的定义格式如下: [ function ] funname [()] { action; ...
- [转帖]kafka 如何保证数据不丢失
kafka 如何保证数据不丢失 https://www.cnblogs.com/MrRightZhao/p/11498952.html 一般我们在用到这种消息中件的时候,肯定会考虑要怎样才能保证数 ...