使用SAXReader对XML进行操作
该例子主要使用SAXReader对XML进行操作,browse.xml是Ango框架里面的XML文件
采用两种方法,第一种的全部是iterator,另外一种采用了部分的for each
代码如下
- private void doBrowse(ServletContextEvent sce) {
- HashMap<String,BrowseBean1> map1 = new HashMap<String,BrowseBean1>();
- SAXReader saxReader = new SAXReader();
- Document document = null;
- // xml文件位置
- String path = this.getClass().getResource("/").getPath();
- //String pString = this.getClass().getResource(pString).getPath();
- String filePath = path.substring(0, path.length()- "classes/".length())+"browse.xml";
- //logger.warn(path);
- //logger.warn(filePath);
- try {
- document = saxReader.read(new File(URLDecoder.decode(filePath, "utf-8")));
- } catch (UnsupportedEncodingException e) {
- // 路径中文解码错误
- e.printStackTrace();
- } catch (DocumentException e) {
- e.printStackTrace();
- logger.warn("查询操作的xml文档异常");
- }
- List list = document.selectNodes("/BrowseElements/element/@flag");
- //logger.warn(list);
- Iterator iter = list.iterator();
- /**
- * 自己写的方法,里面没有全部使用迭代器,用的for each 循环 start
- */
- while(iter.hasNext()){
- Attribute attribute = (Attribute) iter.next();
- String flag = attribute.getValue();
- List listTemp1 = document.selectNodes("/BrowseElements/element[@flag='"
- + flag + "']/@pageSize");
- Iterator iterTemp1 = listTemp1.iterator();
- int pageSize = 0;
- while (iterTemp1.hasNext()) {
- Attribute attribute1 = (Attribute) iterTemp1.next();
- pageSize = Integer.parseInt(attribute1.getValue());
- }
- BrowseBean1 browseBean1 = new BrowseBean1();
- browseBean1.setPageSize(pageSize);
- List listTemp2 = document.selectNodes("/BrowseElements/element[@flag='"
- + flag + "']/sql/@value");
- LinkedHashMap<String,BrowseBean2> map2 = new LinkedHashMap<String,BrowseBean2>();
- for(Object ob : listTemp2){
- //System.out.println(ob);
- String value = ((Attribute) ob).getValue();
- //System.out.println(value);
- BrowseBean2 browseBean2 = new BrowseBean2();
- List listTemp3 = document.selectNodes("/BrowseElements/element[@flag='"
- + flag + "']/sql[@value='"+value+"']/@key");
- for(Object ob1 : listTemp3){
- String key = ((Attribute) ob1).getValue();
- browseBean2.setKey(key);
- //System.out.println(key);
- }
- List listTemp4 = document.selectNodes("/BrowseElements/element[@flag='"
- + flag + "']/sql[@value='"+value+"']/struct");
- ArrayList<StructBean> struct = new ArrayList<StructBean>();
- for(Object ob2 : listTemp4){
- StructBean structBean = new StructBean();
- String structValueString = ((Element) ob2).getText();
- String sessionString = ((Element) ob2).attributeValue("session");
- String requestString = ((Element) ob2).attributeValue("request");
- structBean.setStructValue(structValueString);
- structBean.setSession(sessionString);
- structBean.setRequest(requestString);
- struct.add(structBean);
- }
- browseBean2.setStruct(struct);
- List listTemp5 = document.selectNodes("/BrowseElements/element[@flag='"
- + flag + "']/sql[@value='"+value+"']/param");
- ArrayList<ParamBean> param = new ArrayList<ParamBean>();
- for(Object ob3 : listTemp5){
- ParamBean paramBean = new ParamBean();
- String paramValue = ((Element) ob3).getText();
- String notNull = ((Element) ob3).attributeValue("notNull");
- String session = ((Element) ob3).attributeValue("session");
- String request = ((Element) ob3).attributeValue("request");
- String drop = ((Element) ob3).attributeValue("drop");
- String timeStart = ((Element) ob3).attributeValue("timeStart");
- String timeEnd = ((Element) ob3).attributeValue("timeEnd");
- paramBean.setParamValue(paramValue);
- paramBean.setNotNull(notNull);
- paramBean.setSession(session);
- paramBean.setRequest(request);
- paramBean.setDrop(drop);
- paramBean.setTimeStart(timeStart);
- paramBean.setTimeEnd(timeEnd);
- param.add(paramBean);
- //System.out.println(paramBean.getDrop());
- if(((Element) ob3).getText()==null||"".equals(((Element) ob3).getText())){
- System.out.println("该<element>paramBean为空,即不需要参数");
- //节点类似<param></param>,这样空的才行,但是实际上如果不需要传参数的话,根本就不用写<param>这个节点,那这个判断有点问题
- }else{
- System.out.println("paramValue为:"+paramBean.getParamValue());
- }
- }
- browseBean2.setParam(param);
- List listTemp6 = document.selectNodes("/BrowseElements/element[@flag='"
- + flag + "']/sql[@value='"+value+"']/title");
- ArrayList<String> title = new ArrayList<String>();
- for(Object ob4 : listTemp6){
- String titleString = ((Element) ob4).getText();
- title.add(titleString);
- //System.out.println(titleString);
- //System.out.println(title);
- }
- browseBean2.setTitle(title);
- List listTemp7 = document.selectNodes("/BrowseElements/element[@flag='"
- + flag + "']/sql[@value='"+value+"']/output");
- ArrayList<String> output = new ArrayList<String>();
- for(Object ob5 : listTemp7){
- output.add(((Element) ob5).getText());
- }
- browseBean2.setOutput(output);
- map2.put(value, browseBean2);
- }
- browseBean1.setMap(map2);
- map1.put(flag, browseBean1);
- System.out.println("遍历完browse.xml中的一个<element></element>");
- }
- /**
- * 自己写的方法,里面没有全部使用迭代器,用的for each 循环 end
- */
- /**
- * Ango框架写法,全部使用iterator start
- */
- while (iter.hasNext()) {
- Attribute attribute = (Attribute) iter.next();
- String flag = attribute.getValue();
- System.out.println(flag);
- List listTemp1 = document.selectNodes("/BrowseElements/element[@flag='"
- + flag + "']/@pageSize");
- Iterator iterTemp1 = listTemp1.iterator();
- int pageSize = 0;
- while (iterTemp1.hasNext()) {
- Attribute attribute1 = (Attribute) iterTemp1.next();
- pageSize = Integer.parseInt(attribute1.getValue());
- }
- BrowseBean1 browseBean1 = new BrowseBean1();
- browseBean1.setPageSize(pageSize);
- List listTemp2 = document.selectNodes("/BrowseElements/element[@flag='"
- + flag + "']/sql/@value");
- Iterator iterTemp2 = listTemp2.iterator();
- LinkedHashMap<String,BrowseBean2> map2 = new LinkedHashMap<String,BrowseBean2>();
- while (iterTemp2.hasNext()) {
- Attribute attribute2 = (Attribute) iterTemp2.next();
- String value = attribute2.getValue();
- BrowseBean2 browseBean2 = new BrowseBean2();
- List listTemp3 = document.selectNodes("/BrowseElements/element[@flag='"
- + flag + "']/sql[@value='"+value+"']/@key");
- Iterator iterTemp3 = listTemp3.iterator();
- while (iterTemp3.hasNext()) {
- Attribute attribute3 = (Attribute) iterTemp3.next();
- String key = attribute3.getValue();
- browseBean2.setKey(key);
- }
- List listTemp4 = document.selectNodes("/BrowseElements/element[@flag='"
- + flag + "']/sql[@value='"+value+"']/struct");
- Iterator iterTemp4 = listTemp4.iterator();
- ArrayList<StructBean> struct = new ArrayList<StructBean>();
- while (iterTemp4.hasNext()) {
- Element element = (Element) iterTemp4.next();
- StructBean structBean = new StructBean();
- structBean.setStructValue(element.getText());
- structBean.setSession(element.attributeValue("session"));
- structBean.setRequest(element.attributeValue("request"));
- struct.add(structBean);
- }
- browseBean2.setStruct(struct);
- List listTemp5 = document.selectNodes("/BrowseElements/element[@flag='"
- + flag + "']/sql[@value='"+value+"']/param");
- Iterator iterTemp5 = listTemp5.iterator();
- ArrayList<ParamBean> param = new ArrayList<ParamBean>();
- while (iterTemp5.hasNext()) {
- Element element = (Element) iterTemp5.next();
- ParamBean paramBean = new ParamBean();
- paramBean.setParamValue(element.getText());
- paramBean.setNotNull(element.attributeValue("notNull"));
- paramBean.setSession(element.attributeValue("session"));
- paramBean.setRequest(element.attributeValue("request"));
- paramBean.setDrop(element.attributeValue("drop"));
- paramBean.setTimeStart(element.attributeValue("timeStart"));
- paramBean.setTimeEnd(element.attributeValue("timeEnd"));
- param.add(paramBean);
- }
- browseBean2.setParam(param);
- List listTemp6 = document.selectNodes("/BrowseElements/element[@flag='"
- + flag + "']/sql[@value='"+value+"']/title");
- Iterator iterTemp6 = listTemp6.iterator();
- ArrayList<String> title = new ArrayList<String>();
- while (iterTemp6.hasNext()) {
- Element element = (Element) iterTemp6.next();
- title.add(element.getText());
- }
- browseBean2.setTitle(title);
- List listTemp7 = document.selectNodes("/BrowseElements/element[@flag='"
- + flag + "']/sql[@value='"+value+"']/output");
- Iterator iterTemp7 = listTemp7.iterator();
- ArrayList<String> output = new ArrayList<String>();
- while (iterTemp7.hasNext()) {
- Element element = (Element) iterTemp7.next();
- output.add(element.getText());
- }
- browseBean2.setOutput(output);
- map2.put(value, browseBean2);
- }
- browseBean1.setMap(map2);
- map1.put(flag, browseBean1);
- }
- /**
- * Ango框架写法,全部使用iterator end
- */
- ServletContext sc = sce.getServletContext();
- sc.setAttribute("adubBrowse", map1);
- logger.info("====================browse.xml已更新完毕====================");
- }
XML结构如下:
- <?xml version="1.0" encoding="UTF-8"?>
- <BrowseElements><!-- xmlns="http://www.w3school.com.cn" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.w3school.com.cn browse.xsd" -->
- <element flag="browse_code" pageSize="100" description="获取代码表">
- <!-- sql语句必须保证正确 -->
- <sql value="select * from code where `table` = ?">
- <param>table</param>
- <title>代码编号</title>
- <title>代码内容</title>
- <title>权重1</title>
- <title>权重2</title>
- <title>备注</title>
- <output>id</output>
- <output>content</output>
- <output>weight1</output>
- <output>weight2</output>
- <output>note</output>
- <output>column</output>
- <output>table</output>
- </sql>
- </element>
- <element flag="browse_teacherInformation" pageSize="10" description="对教师进行查询">
- <!-- sql语句必须保证正确 -->
- <sql value="select * from teacher_info where id like ? and name like ? and college=? " description="浏览教师">
- <param>id</param>
- <param>name</param>
- <param drop="true1" session="true">college</param>
- <title>职工号</title>
- <title>教师姓名</title>
- <title>性别</title>
- <title>所属单位</title>
- <title>来校日期</title>
- <output>id</output>
- <output>name</output>
- <output>sex</output>
- <output>college</output>
- <output>arrive_time</output>
- </sql>
- </element>
- <element flag="browse_adminTeacherInformation" pageSize="10" description="对所有教师进行查询">
- <!-- sql语句必须保证正确 -->
- <sql value="select * from teacher_info where id like ? and name like ? and college like ? " description="浏览教师">
- <param>id</param>
- <param>name</param>
- <param>college</param>
- <title>序号</title>
- <title>职工号</title>
- <title>教师姓名</title>
- <title>性别</title>
- <title>所属单位</title>
- <title>来校日期</title>
- <output>id</output>
- <output>name</output>
- <output>sex</output>
- <output>college</output>
- <output>arrive_time</output>
- </sql>
- </element>
- <element flag="browse_teacherPassword" pageSize="10" description="对教师密码进行模糊查询">
- <!-- sql语句必须保证正确 -->
- <sql value="select teacher_info.*,teacher_login.* from teacher_info ,teacher_login,admin_login where teacher_info.id=teacher_login.username and teacher_info.id like ? and teacher_info.name like ? and admin_login.username=? and teacher_info.college=? ORDER BY id DESC" description="查询教师密码">
- <param>id</param>
- <param>name</param>
- <param session="true" drop="true">userName</param>
- <param session="true" drop="true">college</param>
- <title>教师姓名</title>
- <title>职工号</title>
- <title>性别</title>
- <title>密码</title>
- <output>name</output>
- <output>id</output>
- <output>sex</output>
- <output>password</output>
- </sql>
- </element>
- <element flag="browse_administrator_teacherPassword" pageSize="10" description="对所有教师密码进行模糊查询">
- <!-- sql语句必须保证正确 -->
- <sql value="select teacher_info.*,teacher_login.* from teacher_info ,teacher_login,admin_login where teacher_info.college like ? and teacher_info.id=teacher_login.username and teacher_info.id like ? and teacher_info.name like ? and admin_login.username=? ORDER BY id DESC" description="查询所有教师密码">
- <param>college</param>
- <param>id</param>
- <param>name</param>
- <param session="true" drop="true">userName</param>
- <title>教师姓名</title>
- <title>职工号</title>
- <title>性别</title>
- <title>密码</title>
- <title>所属单位</title>
- <output>name</output>
- <output>id</output>
- <output>sex</output>
- <output>password</output>
- <output>college</output>
- </sql>
- </element>
- <element flag="browseNews" pageSize="10" description="对信息进行模糊查询">
- <!-- sql语句必须保证正确 -->
- <sql value="select * from news" description="信息查询">
- <param></param>
- <title>标题</title>
- <title>发布时间</title>
- <title>审核状态</title>
- <output>title</output>
- <output>publishTime</output>
- <output>status</output>
- <output>id</output>
- </sql>
- </element>
- <element flag="getNews" pageSize="10" description="对信息进行模糊查询">
- <!-- sql语句必须保证正确 -->
- <sql value="select * from news where status = 1 limit 5" description="信息查询">
- <output>id</output>
- <output>title</output>
- <output>publishTime</output>
- </sql>
- </element>
- </BrowseElements>
各类javaBean属性如下:
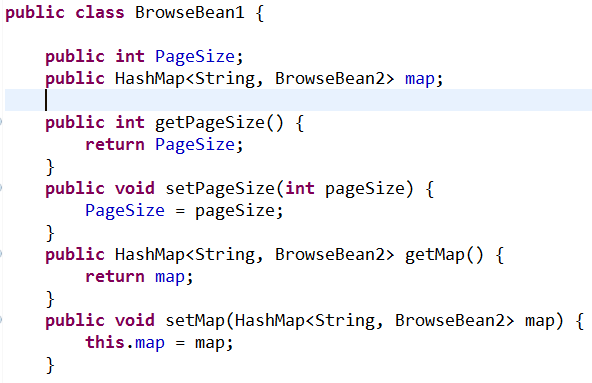
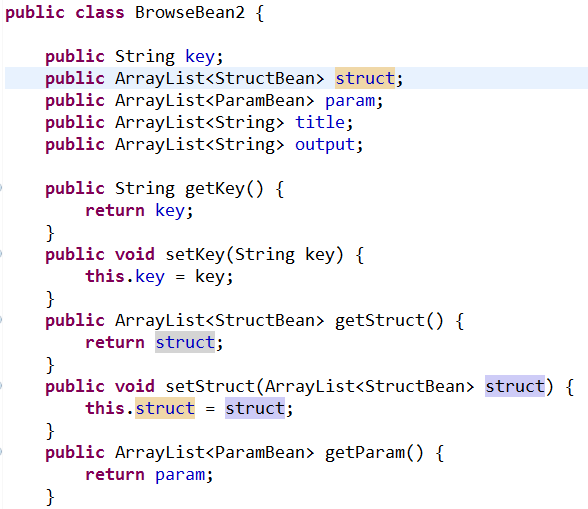
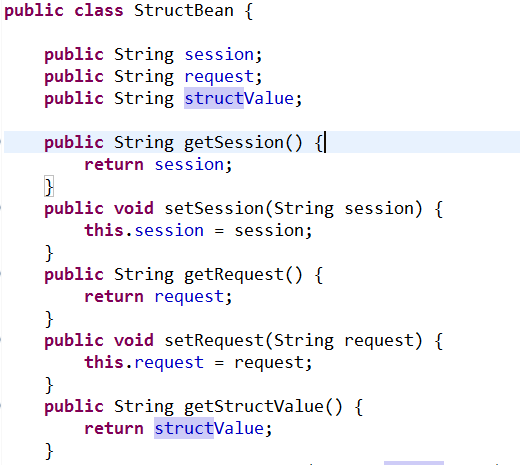
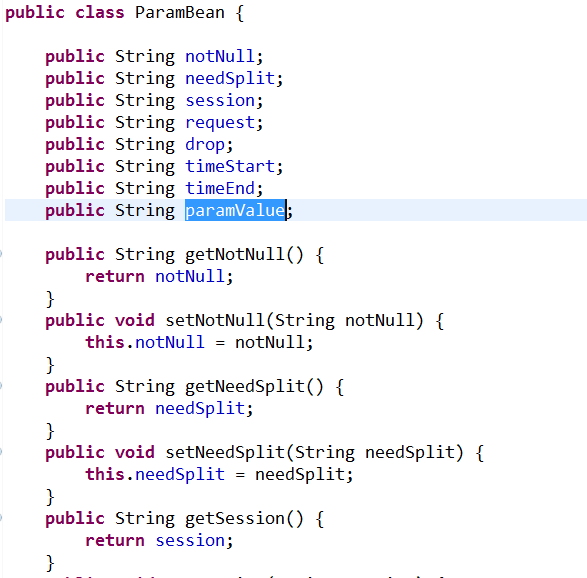
使用SAXReader对XML进行操作的更多相关文章
- VS2012 Unit Test —— 我对IdleTest库动的大手术以及对Xml相关操作进行测试的方式
[1]我的IdleTest源码地址:http://idletest.codeplex.com/ [2]IdleTest改动说明:2013年10月份在保持原有功能的情况下对其动了较大的手术,首先将基本的 ...
- sql server中对xml进行操作
一.前言 SQL Server 2005 引入了一种称为 XML 的本机数据类型.用户可以创建这样的表,它在关系列之外还有一个或多个 XML 类型的列:此外,还允许带有变量和参数.为了更好地支持 XM ...
- 对XML的操作
对XML的操作主要使用到的语法示例: using System.Xml; private static string XmlMarketingStaff = AppDomain.CurrentDoma ...
- Xml通用操作类
using System; using System.Collections.Generic; using System.IO; using System.Text; using System.Xml ...
- C# XML流操作简单实例
这里我们先介绍操作XML文件的两个对象:XmlTextReader和XmlTextWriter打开和读取Xml文件使用到的对象就是XmlTextReader对象.下面的例子打开了与程序在同一路径下的一 ...
- SQL Server 2008 对XML 数据类型操作
原文 http://www.cnblogs.com/qinjian123/p/3240702.html 一.前言 从 SQL Server 2005 开始,就增加了 xml 字段类型,也就是说可以直接 ...
- 我来讲讲在c#中怎么进行xml文件操作吧,主要是讲解增删改查!
我把我写的四种方法代码贴上来吧,照着写没啥问题. 注: <bookstore> <book> <Id>1</Id> <tate>2010-1 ...
- 由“Jasperrpeorts 4.1.2升级到5.1.2对flex项目的解析”到AS3 带命名空间的XML的操作
原文同步至:http://www.waylau.com/from-jasperrpeorts-4-1-2-upgraded-to-5-1-2-parsing-of-flex-projects-to-t ...
- 使用dom4j中SAXReader解析xml数据
public ApiConfig(String configFilePath) throws DocumentException{ SAXReader reader = new SAXReader() ...
随机推荐
- Windows 下升级 node & npm 到最新版本
查询 Node 的安装目录where node 升级 Node:在官网下载最新的安装包,直接安装即可.https://nodejs.org/ 升级 npmnpm install -g npm 使用 n ...
- c# 用XmlWriter写xml序列化
using System.Text; using System.Xml; using System.Xml.Schema; using System.Xml.Serialization; using ...
- python三大器之装饰器的练习
装饰器 加载顺序从下至上 执行顺序从上至下 ''' 多层装饰器 ''' def deco1(func): #func=deco2 def wrapper1(*args, **kwargs): '''t ...
- 『Go基础』第4节 VS Code配置Go语言开发环境
VS Code 是微软开源的一款编辑器, 本文主要介绍如何使用VS Code搭建Go语言的开发环境. 下载与安装VS Code 官方下载地址: https://code.visualstudio.co ...
- 【转】基于FPGA的Sobel边缘检测的实现
前面我们实现了使用PC端上位机串口发送图像数据到VGA显示,通过MATLAB处理的图像数据直接是灰度图像,后面我们在此基础上修改,从而实现,基于FPGA的动态图片的Sobel边缘检测.中值滤波.Can ...
- git 学习笔记 ---撤销修改
自然,你是不会犯错的.不过现在是凌晨两点,你正在赶一份工作报告,你在readme.txt中添加了一行: $ cat readme.txt Git is a distributed version co ...
- redis的事务处理
1.redis事务可以依次执行多个命令,并且带有以下三个重要的保证: 批量操作在发送exec命令前被放入队列缓存. 收到exec命令后进入事务执行,事务中任意命令执行失败,其余的命令依然被执行. 在事 ...
- 使用二进制方式安装K8S时使用kubectl命令报错:The connection to the server localhost:8080 was refused - did you specify the right host or port?
解决思路: kubectl 默认从 ~/.kube/config 配置文件获取访问 kube-apiserver 地址.证书.用户名等信息,如果没有配置该文件,或者该文件个别参数配置出错,执行命令时出 ...
- Java8 基础数据类型包装类-Long
https://blog.csdn.net/u012562117/article/details/79023440 基础 //final修饰不可更改,每次赋值都是新建类(其中-128~127是通过L ...
- C#精粹--协变和逆变
概念 协变和逆变来源于类型和类型之间的绑定,C#4.0开始在泛型的接口和委托上支持协变和逆变,不过在这个版本之前的委托也是支持协变和逆变的.比如数组就支持协变,但是这不是一个好的特性,这C#初期版本从 ...