如何确定垃圾?JVM GC ?
如何确定垃圾?
正文
如何确定垃圾?
前面已经提到 JVM 可以采用 引用计数法 与 可达性分析算法 来确定需要回收的垃圾,我们来具体看一下这两种算法:
- 引用计数法
该方法实现为:给每个对象添加一个引用计数器,每当有一个地方引用它时,引用计数值就+1,当引用失效时,引用计数值就-1,任何时刻引用计数值为0的对象就可以被回收,当一个对象被垃圾收集器收集时,被它引用的对象引用计数值就-1,所以在这种方法中一个对象被垃圾收集会导致后续其他对象的垃圾收集行动。
优点:简单、高效;
缺点:当两个对象相互引用的时候就无法回收,导致内存泄漏。
- 可达性分析法
为了解决对象间相互引用问题,Java 采用了可达性分析法,基本实现思路为:通过一系列 "GC Roots" 对象作为起点,从这些节点开始向下搜索,搜索所走过的路径称为引用链,当一个对象到 "GC Roots" 没有任何引用链相连时,则称该对象是不可达的,此时,该对象还处于缓刑阶段,要真正宣判一个对象为可回收对象,至少要经历两次标记过程。
哪些对象可以作为 "GC Roots" ?
1、通过System Class Loader或者Boot Class Loader加载的class对象
2、处于激活状态的线程
3、栈中的对象
4、JNI栈中的对象
5、JNI中的全局对象
6、正在被用于同步的各种锁对象
7、JVM自身持有的对象,比如系统类加载器等
垃圾回收算法
通过上面面试者的回答,我们已经知道垃圾收集算法主要包括:复制算法、标记清除算法、标记整理算法、分代回收算法,我们来具体看一下:
- 复制算法
该方法实现为:将内存分为大小相等的两块,每次只使用其中一块,当这一块内存满了后将存活的对象复制到另一块上去,把已使用的内存清掉。如图所示:
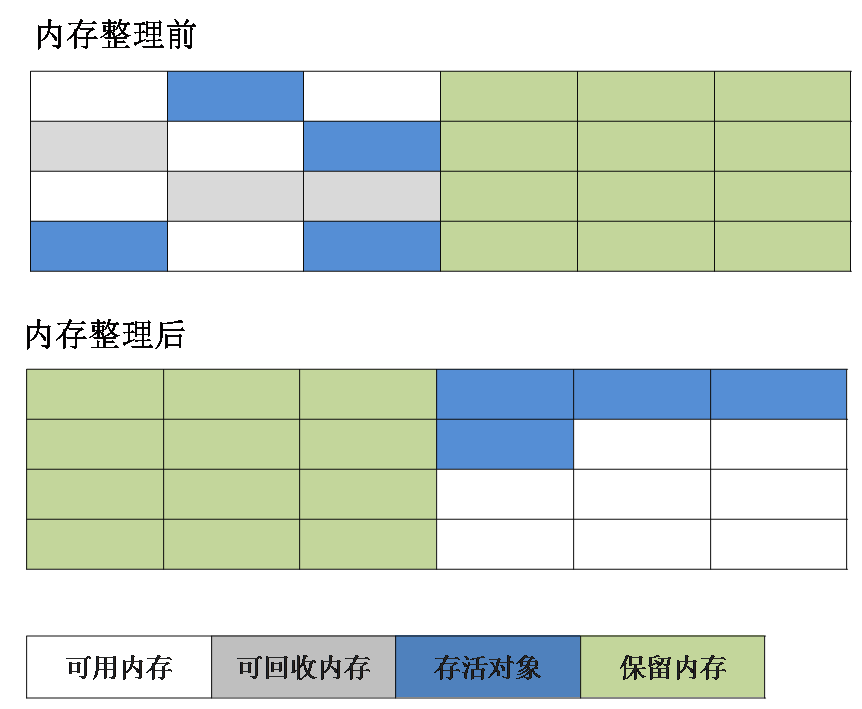
优点:简单、高效、不会产生内存碎片;
缺点:可用内存减少为原来的一半,造成内存浪费。
- 标记清除算法
该方法实现分为两个阶段,标注和清除,标记阶段找到所有可访问的对象,做个标记 ;清除阶段遍历堆,把未被标记的对象回收。如图所示:
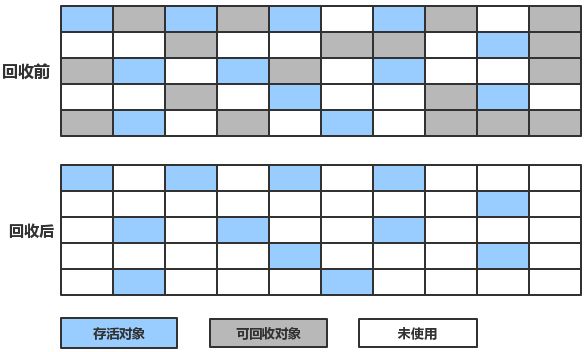
缺点:碎片化严重。
- 标记整理算法
该方法不直接对可回收对象进行清理,而是让所有可用的对象都向一端移动,然后直接清理掉边界外的对象,解决了标记清除算法带来的碎片化问题。如图所示:
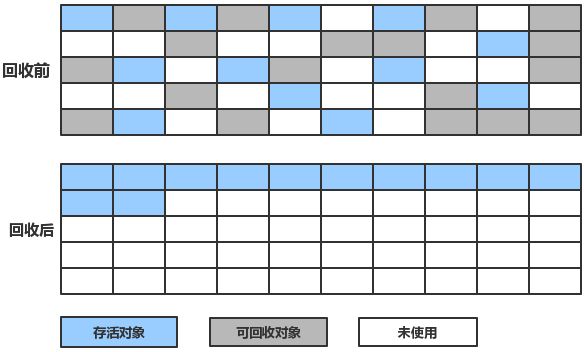
- 分代回收算法
分代回收算法是目前大部分 JVM 所采用的方法,其核心思想是根据对象存活的生命周期不同,将内存划分为不同的区域,一般情况下将 GC 堆划分为新生代和老年代;老年代的特点是:对象生命周期较长,每次垃圾回收时只有少量对象需要被回收;新生代的特点是:对象大部分朝生夕死,生命周期短,每次垃圾回收时都有大量对象需要被回收;因此,可以根据不同区域选择不同的算法,使垃圾回收更加合理、高效,如:新生代采用效率较高的复制算法,老年代采用不会产生内存碎片,也不会发生内存浪费的标记整理算法。
垃圾收集器
常用的垃圾收集器都有哪些呢?我们来具体看一下:
- Serial 垃圾收集器
Serial 曾经是 JDK1.3.1 之前新生代唯一的垃圾收集器;Serial 是一个单线程的收集器,在进行垃圾收集的同时,必须暂停其他所有的工作线程,直到垃圾收集结束;但同时 Serial 也是简单高效的,对于限定单个 CPU 环境来说,没有线程交互的开销,可以获得最高的单线程垃圾收集效率。
- ParNew 垃圾收集器
ParNew 是 Serial 多线程版,也使用复制算法,除了使用多线程进行垃圾收集之外,其余的行为和 Serial 收集器完全一样。
- Parallel Scavenge 收集器
Parallel Scavenge 是一个新生代垃圾收集器,同样使用复制算法,也是一个多线程的垃圾收集器,它重点关注的是程序达到一个可控制的吞吐量(吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间)),高吞吐量可以最高效率地利用 CPU 时间,尽快地完成程序的运算任务,主要适用于在后台运算而不需要太多交互的任务。
- Serial Old 收集器
Serial Old 是 Serial 垃圾收集器老年代版本,它是个单线程的,使用标记整理算法的收集器。
- Parallel Old 收集器
Parallel Old 收集器是 Parallel Scavenge 的老年代版本,它是多线程的,使用标记整理算法,在 JDK1.6 开始提供使用。
- CMS 收集器
CMS 是一种老年代垃圾收集器,其主要目标是获取最短垃圾回收停顿时间,和其它老年代使用标记整理算法不同,它使用多线程的标记清除算法;其运作过程比较复杂,整个过程分为6个步骤,包括:初始标记(CMS initial mark)、并发标记(CMS concurrent mark)、并发预清理(CMS-concurrent-preclean)、重新标记(CMS remark)、并发清除(CMS concurrent sweep)、并发重置(CMS-concurrent-reset),其中初始标记、重新标记这两个步骤仍然需要暂停其它工作线程,初始标记仅仅只是标记一下 "GC Roots" 能直接关联到的对象,速度很快,并发标记阶段就是进行 "GC Roots" 追踪的过程,而重新标记阶段则是为了修正并发标记期间,因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段稍长一些,但远比并发标记的时间短。
- G1 收集器
G1 是 JVM 垃圾收集器理论进一步发展的产物,相比与 CMS 收集器,G1 基于标记整理算法,不会产生内存碎片;其次,还可以非常精确控制停顿时间,在不牺牲吞吐量前提下,实现低停顿垃圾回收;G1 收集器避免全区域垃圾收集,它把堆内存划分为大小固定的几个独立区域,并且跟踪这些区域的垃圾收集进度,同时在后台维护一个优先级列表,每次根据所允许的收集时间,优先回收垃圾最多的区域;区域划分和优先级区域回收机制,确保 G1 收集器可以在有限时间获得最高的垃圾收集效率。
如何确定垃圾?JVM GC ?的更多相关文章
- 【转载】Java性能优化之JVM GC(垃圾回收机制)
文章来源:https://zhuanlan.zhihu.com/p/25539690 Java的性能优化,整理出一篇文章,供以后温故知新. JVM GC(垃圾回收机制) 在学习Java GC 之前,我 ...
- 性能测试三十五:jvm垃圾回收-GC
垃圾回收-GC 三个问题 哪些内存需要回收? 什么时候回收? 如何回收? YoungGC和FullGC: 新生代引发的GC叫YoungGC 老年代引发的GC叫FullGC FullGC会引起整个Jvm ...
- Java性能优化之JVM GC(垃圾回收机制)
Java的性能优化,整理出一篇文章,供以后温故知新. JVM GC(垃圾回收机制) 在学习Java GC 之前,我们需要记住一个单词:stop-the-world .它会在任何一种GC算法中发生.st ...
- 修改Tomcat的jvm的垃圾回收GC方式为CMS
修改Tomcat的jvm的垃圾回收GC方式 cp $TOMCAT_HOME/bin/catalina.sh $TOMCAT_HOME/bin/catalina.sh.bak_20170815 vi $ ...
- Java 中级 学习笔记 2 JVM GC 垃圾回收与算法
前言 在上一节的学习中,已经了解到了关于JVM 内存相关的内容,比如JVM 内存的划分,以及JDK8当中对于元空间的定义,最后就是字符串常量池等基本概念以及容易混淆的内容,我们都已经做过一次总结了.不 ...
- JVM学习——垃圾回收GC(学习过程)
JVM学习-垃圾回收(GC) 2020年02月19日06:03:56,开始学习垃圾回收,学习资料来源(张龙老师的JVM课程) JVM内存数据区域知识复习 学习垃圾回收之前,要对JVM内部的内存区域有详 ...
- 如何避免后台IO高负载造成的长时间JVM GC停顿(转)
译者著:其实本文的中心意思非常简单,没有耐心的读者建议直接拉到最后看结论部分,有兴趣的读者可以详细阅读一下. 原文发表于Linkedin Engineering,作者 Zhenyun Zhuang是L ...
- Java 垃圾回收(GC) 泛读
Java 垃圾回收(GC) 泛读 文章地址:https://segmentfault.com/a/1190000008922319 0. 序言 带着问题去看待 垃圾回收(GC) 会比较好,一般来说主要 ...
- JVM GC机制
垃圾收集主要是针对堆和方法区进行. 回收机制: 现在的JVM基本都使用分代回收机制,把堆中内存区域分为新生代,老年代. 新生代: Eden(80%) Survivor0(10%) Survivor1( ...
- 深入浅出 JVM GC(3)
# 前言 在 深入浅出 JVM GC(2) 中,我们介绍了一些 GC 算法,GC 名词,同时也留下了一个问题,就是每个 GC 收集器的具体作用.有哪些 GC 收集器呢? Serial 串行收集器(只适 ...
随机推荐
- Centos7-安装py3
安装依赖 yum install gcc openssl-devel bzip2-devel expat-devel gdbm-devel readline-devel sqlite-devel li ...
- PHP程序员最容易犯的Mysql错误
对于大多数web应用来说,数据库都是一个十分基础性的部分.如果你在使用PHP,那么你很可能也在使用MySQL—LAMP系列中举足轻重的一份子. 对于很多新手们来说,使用PHP可以在短短几个小时之内轻松 ...
- Partition HDU - 4602 (不知道为什么被放在了FFT的题单里)
题目链接:Vjudge 传送门 相当于把nnn个点分隔为若干块,求所有方案中大小为kkk的块数量 我们把大小为kkk的块,即使在同一种分隔方案中的块 单独考虑,它可能出现的位置是在nnn个点的首.尾. ...
- dbt 0.14.0 发布
以下内容来自官方博客,新的功能还是很不错的,后边尝试使用下. 参考资料:https://blog.fishtownanalytics.com/dbt-v0-14-0-better-serving-ou ...
- MQTT 遗嘱使用
大部分人应该有这个需求: 我想让我的APP或者上位机或者网页一登录的时候获取设备的状态 在线还是离线 设备端只需要这样设置 注意:MQTT本身有遗嘱设置 所以大家可以设置遗嘱 ,注意哈,发布的主题 ...
- Codeforces & Atcoder神仙题做题记录
鉴于Codeforces和atcoder上有很多神题,即使发呆了一整节数学课也是肝不出来,所以就记录一下. AGC033B LRUD Game 只要横坐标或者纵坐标超出范围就可以,所以我们只用看其中一 ...
- Balanced Ternary String(贪心+思维)
题目链接:Balanced Ternary String 题目大意:给一个字符串,这个字符串只由0,1,2构成,然后让替换字符,使得在替换字符次数最少的前提下,使新获得的字符串中0,1,2 这三个字符 ...
- CF1221F Choose a Square(二维偏序)
由于y=x,我们可以将点对称过来,以便(x,y)(x<y) 考虑选取正方形(a,a,b,b),点集则为\((a\le x\le y\le b)\),相当于二维数点 将点按x降序,y升序排列,线段 ...
- nginx重启 平滑重启
进入 ngiinx sbin目录下./nginx -c /usr/local/nginx/conf/nginx.conf -c参数指定了要加载的nginx配置文件路径 停止操作停止操作是通过向ngin ...
- spring 整合 servlet
目的:记录spring整合 servlet过程demo.(企业实际开发中可能很少用到),融会贯通. 前言:在学习spring 过程(核心 ioc,aop,插一句 学了spring 才对这个有深刻概念, ...