python爬虫1
1 网页结构
html:超文本标记语言------->类似人的鼻子耳朵,长在那里,大体骨架就是那个样子
css:层叠样式表------->这个是外观的深化,比如贴个双眼皮,橙色眼睛。。。
js:动态脚本语言----->人的技能,跳舞rap
学习网站:w3cshool
2 requests使用
(1)开发环境使用pycharm
(2)爬虫基本原理
request---->向服务器发送访问的请求
responce---->服务器收到用户请求以后,会验证请求的有效性然后向用户发送响应的内容。客户端收到响应并显示出来。
(3)get post请求方式
get:
post:
使用有道翻译网页作为案例,http://fanyi.youdao.com/,按F12进入开发者模式,单击network,此时为空。
在输入框中输入"中国你好"单击翻译
单击network---->XHR找到翻译数据
查看请求方式为post,并可以加那个headers中的URL复制出来,因为post需要自己构建请求头
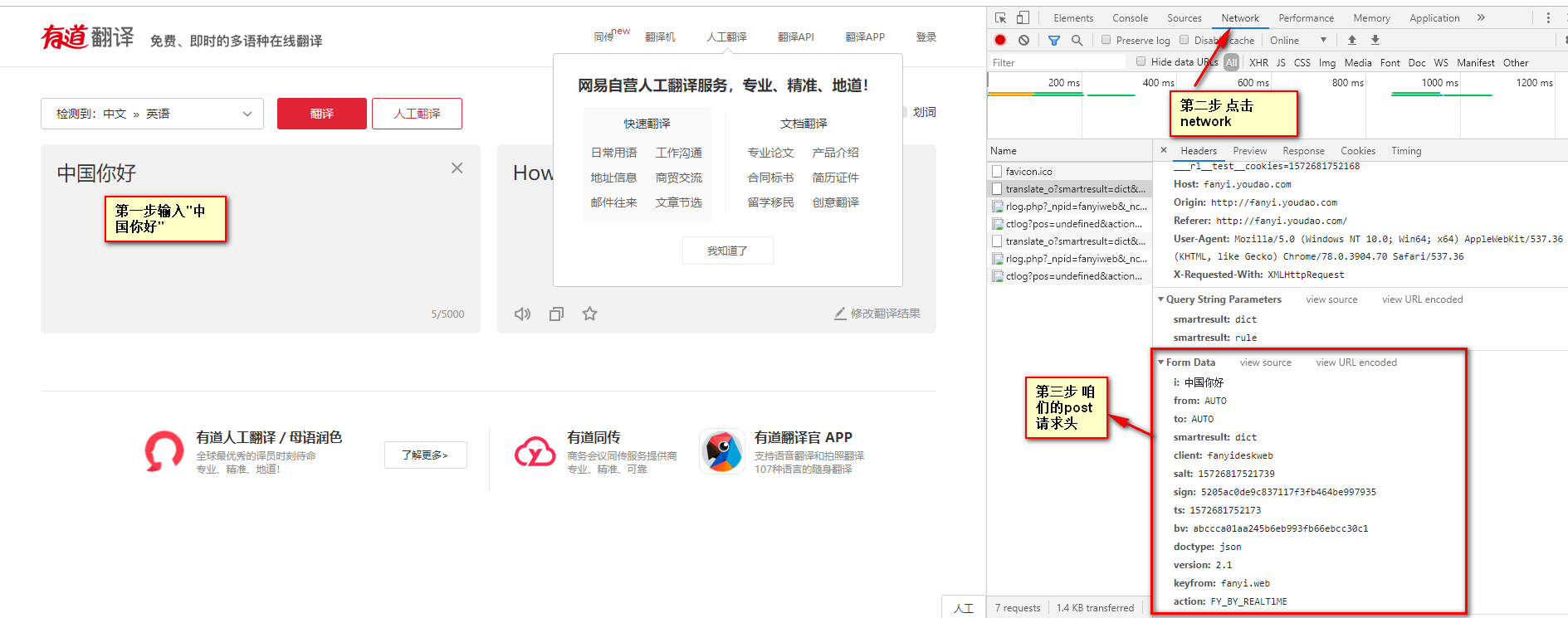
使用request.post抓取有道翻译的结果
import requests
import json
def get_translate_date(word=None):
url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
Form_data = {'i':word, 'from':'AUTO','to': 'AUTO','smartresult': 'dict', 'client':'fanyideskweb',
'salt':'','sign':'78181ebbdcb38de9b4a3f4cd1d38816b','doctype':'json',
'version': '2.1','keyfrom':'fanyi.web','action':'FY_BY_CLICKBUTTION','typoResult':'false'} response = requests.post(url, data=Form_data) # 请求表单数据
content = json.loads(response.text) # 将JSON格式字符串转字典
print(content)
print(content['translateResult'][0][0]['tgt']) # 打印翻译后的数据
if __name__ == '__main__':
get_translate_date('中国你好')
3 使用beautiful soup解析网页
通过requests可以抓取网页源码并解析提取数据,beautiful soup被移植到bs4库中,也就是安装它需要先安装bs4.官方中文文档https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
(1)打开网页
(2)筛选路径soup.select()
随便选择一句话----->右击检查(右侧弹出开发者界面)----->右击左边高亮数据------>选择copy----->选择copy selector
(3)引入re库
https://docs.python.org/zh-cn/3/library/re.html re中文官网
(4)最终代码
import requests
from bs4 import BeautifulSoup
import re url="http://www.cntour.cn/"
strhtml=requests.get(url)
soup=BeautifulSoup(strhtml.text,'lxml')# 通过lxml解析后转换为树形结构,每个节点都是对象
data=soup.select("#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a")
print(data)
for item in data:
result={
'title':item.get_text(),#连接在<a>标签中用get_text
'link':item.get('href'),#在<a>href属性用get
'ID':re.findall('\d+',item.get('href'))#\d表示匹配数字 +表示匹配前一个字符1次或者多次
}
print(result)
(5)最后结果
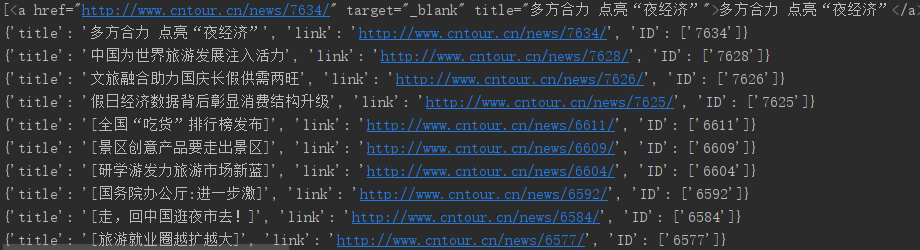
完事!
python爬虫1的更多相关文章
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
- python爬虫学习(7) —— 爬取你的AC代码
上一篇文章中,我们介绍了python爬虫利器--requests,并且拿HDU做了小测试. 这篇文章,我们来爬取一下自己AC的代码. 1 确定ac代码对应的页面 如下图所示,我们一般情况可以通过该顺序 ...
- python爬虫学习(6) —— 神器 Requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 H ...
- 批量下载小说网站上的小说(python爬虫)
随便说点什么 因为在学python,所有自然而然的就掉进了爬虫这个坑里,好吧,主要是因为我觉得爬虫比较酷,才入坑的. 想想看,你可以批量自动的采集互联网上海量的资料数据,是多么令人激动啊! 所以我就被 ...
- python 爬虫(二)
python 爬虫 Advanced HTML Parsing 1. 通过属性查找标签:基本上在每一个网站上都有stylesheets,针对于不同的标签会有不同的css类于之向对应在我们看到的标签可能 ...
- Python 爬虫1——爬虫简述
Python除了可以用来开发Python Web之后,其实还可以用来编写一些爬虫小工具,可能还有人不知道什么是爬虫的. 一.爬虫的定义: 爬虫——网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区 ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- [python]爬虫学习(一)
要学习Python爬虫,我们要学习的共有以下几点(python2): Python基础知识 Python中urllib和urllib2库的用法 Python正则表达式 Python爬虫框架Scrapy ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
随机推荐
- 读取yaml文件小方法
def read_inf(inf_path): '''读取指定路径配置文件''' try: import yaml fr = open(inf_path) fy = yaml.load(fr) fr. ...
- c++中关联容器set的使用
c++中set的用法 #include<iostream> #include<vector> #include<algorithm> #include<set ...
- 基于虚拟机+Ubuntu1604的ROS-kinetic配置流程
简单记录一下配置的过程 先换源,以阿里源为例 备份原有源 sudo cp /etc/apt/sources.list /etc/apt/sources_init.list 编辑源文件 sudo ged ...
- freemarker使用shiro标签(spring boot)
freemarker使用shiro标签(spring boot) 2018年07月03日 14:20:37 niu_sayok 阅读数:348更多 个人分类: freeMarkerShiro 首先 ...
- 20199302《Linux内核原理与分析》第十二周作业
ShellShock攻击实验 什么是ShellShock? Shellshock,又称Bashdoor,是在Unix中广泛使用的Bash shell中的一个安全漏洞,首次于2014年9月24日公开.许 ...
- 封装原生promise函数
阿里面试题: 手动封装promise函数 <!DOCTYPE html> <html lang="en"> <head> <meta ch ...
- jaeger使用yugabyte作为后端存储的尝试以及几个问题
前边写过使用scylladb 做为jaeger 的后端存储,还是一个不错选择的包括性能以及 兼容性,对于 yugabyte 当前存在兼容性的问题,需要版本的支持,或者尝试进行一些变动 create 语 ...
- HTML Meta标签和link标签
一.meta 标签 name属性主要用于描述网页,对应于content(网页内容) 1.<meta name="Generator" contect="" ...
- 洛谷 P1474 货币系统 Money Systems 题解
P1474 货币系统 Money Systems 题目描述 母牛们不但创建了它们自己的政府而且选择了建立了自己的货币系统.由于它们特殊的思考方式,它们对货币的数值感到好奇. 传统地,一个货币系统是由1 ...
- Awesome Go精选的Go框架,库和软件的精选清单.A curated list of awesome Go frameworks, libraries and software
Awesome Go financial support to Awesome Go A curated list of awesome Go frameworks, libraries a ...