ELK - logstash 多个配置文件及模板的使用
目录
- 前言
- 多配置文件的实现方式
- 为logstash 增加模板
- 将 logstash 作为服务启动
1. 前言
在使用 logstash 编写多个配置文件,写入到 elasticsearch 时,会出现数据写入混乱的问题,举例来说:
多个配置文件中规则如下:
A -> es-logstash-A
B -> es-logstash-B A 写入到 es-logstash-A 索引中
B 写入到 es-logstash-B 索引中
然而当 logstash 服务运行起来的时候并不是这样的,可能出现如下想象:
A-> es-logstash-A
B-> es-logstash-A
究其原因,是因为 logstash 运行起来的时候,会将所有的配置文件合并执行。因此,每个 input 的数据都必须有一个唯一的标识,在 filter 和 output 时,通过这个唯一标识来实现过滤或者存储到不同的索引。
2. 多配置文件的实现方式
如上所说,写入需要唯一标识,在logstash 中唯一标识推荐使用 type 或 tags 字段,然后通过 if 条件判断来实现。
首先来看下面一个示例:
在 /etc/logstash/conf.d 目录下有这样两个配置文件 [1.conf a.conf ]
[root@192.168.118.14 /etc/logstash/conf.d]#ls
1.conf a.conf 1.conf
input {
file {
path => "/data/log/1.log"
start_position => "beginning"
sincedb_path => "/tmp/1_progress"
}
} output {
elasticsearch {
hosts => ["192.168.118.14"]
index => "1-log-%{+YYYY.MM.dd}"
}
} a.conf
input {
file {
path => "/data/log/a.log"
start_position => "beginning"
sincedb_path => "/tmp/a_progress"
}
} output {
elasticsearch {
hosts => ["192.168.118.14"]
index => "a-log-%{+YYYY.MM.dd}"
}
} /data/log/a.log
[root@192.168.118.14 ~]#cat /data/log/a.log
a /data/log/1.log
[root@192.168.118.14 ~]#cat /data/log/1.log
1
这两个配置很简单,规则:
- 1.conf 读取 /data/log/1.log 写入到 1-log-[date] 索引
- a.conf 读取 /data/log/a.log 写入到 a-log-[date] 索引
两个日志文件,都只有 1 行日志记录。
正确的结果是 生成两个索引,每个索引里只有一条记录。
接下来启动服务查看,多配置文件 命令启动方式如下:
正确的启动方式:
[root@192.168.118.14 ~]#logstash -f /etc/logstash/conf.d/
错误的启动方式:
[root@192.168.118.14 ~]#logstash -f /etc/logstash/conf.d/*
启动成功后,通过 elasticsearch-head 查看 索引及数据
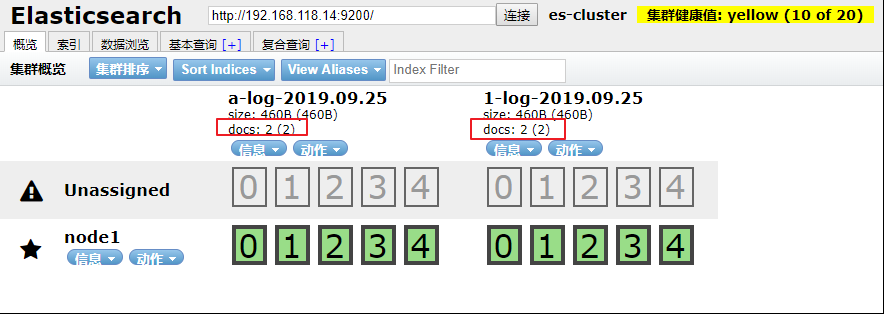
发现每个 索引里却有 2 条记录,这不符合正常的逻辑,查看数据发现,每个索引里都是 1.log 和 a.log 的数据总和。
这也证明了 logstash 在写入数据的时候,是将所有的配置文件合并在一起的,运行起来数据写入就会混乱。要解决这种混乱就需要通过唯一标识和if 判断,logstash配置文件调整如下:
1.conf
input {
file {
path => "/data/log/1.log"
start_position => "beginning"
sincedb_path => "/tmp/1_progress"
type => "1-log"
}
} output {
if [type] == "1-log" {
elasticsearch {
hosts => ["192.168.118.14"]
index => "1-log-%{+YYYY.MM.dd}"
}
}
} a.conf
input {
file {
path => "/data/log/a.log"
start_position => "beginning"
sincedb_path => "/tmp/a_progress"
type => "a-log"
}
} output {
if [type] == "a-log" {
elasticsearch {
hosts => ["192.168.118.14"]
index => "a-log-%{+YYYY.MM.dd}"
}
}
}
上面修改的部分, input 里 增加了 type 字段,定义了唯一标识而在 output 中 通过if判断唯一标识来做响应的写入操作。
启动服务:
[root@192.168.118.14 ~]#logstash -f /etc/logstash/conf.d/
通过 elasticsearch-head 查看:

这次就完全符合预期的标准了。
3. 为logstash 增加模板
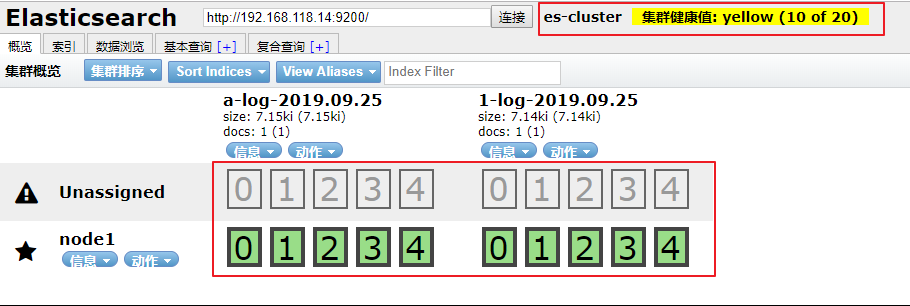
通过 elasticsearch-head 查看到 elasticsearch 默认是通过分片入库的,而且默认是 5 个主分片,5 个备份分片。 当作为日志存储时,数据可能没那么重要,不需要做 elasticsearch 的集群,但是也不想看到这些告警信息,这时候就需要 模板 了。
这里直接提供一个模板样本,可以直接使用。
{
"template" : "*", "version" : ,
"settings" : {
"index.refresh_interval" : "5s",
"number_of_shards": ,
"number_of_replicas":
},
"mappings" : {
"_default_" : {
"dynamic_templates" : [{
"message_field" : {
"path_match" : "message", "match_mapping_type" : "string", "mapping" : {
"type" : "text", "norms" : false
}
}
}, {
"string_fields" : {
"match" : "*", "match_mapping_type" : "string", "mapping" : {
"type" : "text", "norms" : false, "fields" : {
"keyword" : {
"type" : "keyword", "ignore_above" :
}
}
}
}
}],
"properties" : {
"@timestamp" : {
"type" : "date"
}, "@version" : {
"type" : "keyword"
}, "geoip" : {
"dynamic" : true, "properties" : {
"ip" : {
"type" : "ip"
}, "location" : {
"type" : "geo_point"
}, "latitude" : {
"type" : "half_float"
}, "longitude" : {
"type" : "half_float"
}
}
}
}
}
}
}
template.json
放置在这里目录里:
[root@192.168.118.14 ~]#ls /etc/logstash/template/template.json
"number_of_shards": 3,
"number_of_replicas": 0
这一部分就是定义 主分片 和 复制分片的,可以适当的调整。
"properties" : {
"@timestamp" : {
"type" : "date"
}, "@version" : {
"type" : "keyword"
}, "geoip" : {
"dynamic" : true, "properties" : {
"ip" : {
"type" : "ip"
}, "location" : {
"type" : "geo_point"
}, "latitude" : {
"type" : "half_float"
}, "longitude" : {
"type" : "half_float"
}
}
}
}
当要使用地图定位客户端位置的时候,这一段就必须加上, location 的type 的必须是 geo_point
为 logstash 配置文件添加模板配置,如下:
a.conf
input {
file {
path => "/data/log/a.log"
start_position => "beginning"
sincedb_path => "/tmp/a_progress"
type => "a-log"
}
} output {
if [type] == "a-log" {
elasticsearch {
hosts => ["192.168.118.14"]
index => "a-log-%{+YYYY.MM.dd}"
template => "/etc/logstash/template/template.json"
template_overwrite => "true"
}
}
} 1.conf
input {
file {
path => "/data/log/1.log"
start_position => "beginning"
sincedb_path => "/tmp/1_progress"
type => "1-log"
}
} output {
if [type] == "1-log" {
elasticsearch {
hosts => ["192.168.118.14"]
index => "1-log-%{+YYYY.MM.dd}"
template => "/etc/logstash/template/template.json"
template_overwrite => "true"
}
}
}
启动服务
[root@192.168.118.14 ~]#logstash -f /etc/logstash/conf.d/
通过 elasticsearch-head 查看集群状态及索引分片:
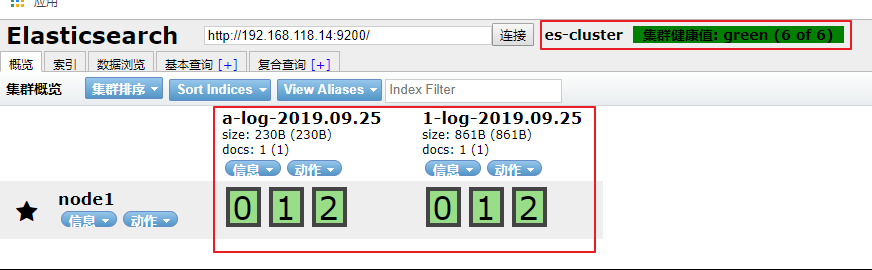
ok,新增的模板已经生效。尝试为不同的索引添加不同的模板结果出现各种问题,因此创建一个通用的模板。
4. 将 logstash 作为服务启动
在上面的启动中,都是直接通过命令 logstash 来启动的,其实可以通过修改 logstash.service 启动脚本来启动服务。
修改如下:
[root@192.168.118.14 ~]#vim /etc/systemd/system/logstash.service
…
ExecStart=/usr/share/logstash/bin/logstash "--path.settings" "/etc/logstash" "-f" "/etc/logstash/conf.d"
…
启动服务:
[root@192.168.118.14 ~]#systemctl daemon-reload
[root@192.168.118.14 ~]#systemctl start logstash
ELK - logstash 多个配置文件及模板的使用的更多相关文章
- [elk]logstash的最佳实战-项目实战
重点参考: http://blog.csdn.net/qq1032355091/article/details/52953837 不得不说这是一个伟大的项目实战,是正式踏入logstash门槛的捷径 ...
- ELK——Logstash 2.2 date 插件【翻译+实践】
官网地址 本文内容 语法 测试数据 可配置选项 参考资料 date 插件是日期插件,这个插件,常用而重要. 如果不用 date 插件,那么 Logstash 将处理时间作为时间戳.时间戳字段是 Log ...
- ELK logstash 处理MySQL慢查询日志(初步)
写在前面:在做ELK logstash 处理MySQL慢查询日志的时候出现的问题: 1.测试数据库没有慢日志,所以没有日志信息,导致 IP:9200/_plugin/head/界面异常(忽然出现日志数 ...
- ELK logstash geoip值为空故障排查
首先我们用的是elasticsearch+kibana+logstash+filebeat 客户端filebeat收集日志后经过服务端logstash规则处理后储存到elasticsearch中,在k ...
- 主流框架(SSH及SSM)配置文件的模板头文件
SSH三大框架整合配置头文件模板如下: 一:Spring配置文件(beans.xml)模板:<beans xmlns="http://www.springframework.or ...
- ELK(Logstash+Elasticsearch+Kibana)的原理和详细搭建
一. Elastic Stack Elastic Stack是ELK的官方称呼,网址:https://www.elastic.co/cn/products ,其作用是“构建在开源基础之上, Elast ...
- 三大框架SSH(struts2+spring+hibernate)整合时相关配置文件的模板
最近在学SSH三大框架的整合,在此对他们整合时相关配置文件做一简单的模板总结,方便以后复用! 首先是web.xml配置文件,这里面就配置一些简单的监听器.过滤器,包括spring核心配置文件appli ...
- ELK logstash 启动慢的解决方法
最近开始测试部署ELK, 在部署logstash的时候出现一个故障: logstash在第一次安装完成以后启动正常, 但是之后启动时间越来越长, 5分钟以上甚至10多分钟.以至于怀疑程序错误, 在重装 ...
- 【ELK】【docker】【elasticsearch】2.使用elasticSearch+kibana+logstash+ik分词器+pinyin分词器+繁简体转化分词器 6.5.4 启动 ELK+logstash概念描述
官网地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html#docker-cli-run-prod ...
随机推荐
- node基础学习——path的处理与路径转换
处理与转换路径path normalize该方法将非标准路径字符串转换为标准路径字符串,在转换过程中执行以下操作: ①解析路径字符串中的’..’字符串与’.’字符串,返回解析后的标准路径. ②将多个斜 ...
- python内置模块笔记(持续更新)
常用函数name = '{wh}my \t name is {name},age is {age}.' print(name.capitalize()) # 字符串的开头字母大写 print(name ...
- HTML——MP4视频不能播放
前言 HTML5中提供了video标签,但是为什么有的MP4视频可以播放,有的不能播放呢? 简介 当然是因为编码的问题咯~ 视频格式 标签属性 DOM参考 HTML 5 视频/音频参考手册 使用 &l ...
- php生成pdf,php+tcpdf生成pdf, php pdf插件
插件例子:https://tcpdf.org/examples/ 下载tcpdf插件: demo // Include the main TCPDF library (search for insta ...
- go 学习 (五):包管理
一.设置环境变量 二.启用 go modules 功能 并设置代理 https://goproxy.io/zh/ 补充: GO111MODULE 有三个值:on.off.auto GO111MODU ...
- Oracle 对比insert和delete操作产生的undo
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/wangqingxun/article/de ...
- H5视频播放小结(video.js不好用!!!)
近期在做一个H5的视频课堂,遇到了H5播放的需求,因为原生的video的样式不太理想,尤其是封面无法压住控制条,这就需要我们自定义播放控件. 于是,找了很近的插件,找到了用户比较多的video.js插 ...
- 检查cgroup v2 是否安装
cgroup 当前包含了v1, 以及v2 版本,v2 版本相比v1 在目录组织上更加清晰,管理更加方便,很多 时候我们可能需要检查我们安装的内核当前内核版本是否支持cgroup v2 文章内容来自 h ...
- Educational Codeforces Round 67
Educational Codeforces Round 67 CF1187B Letters Shop 二分 https://codeforces.com/contest/1187/submissi ...
- nodejs+nvm历史版本
官网:http://nodejs.org/dist/ 淘宝镜像:https://npm.taobao.org/mirrors/node/ nvm历史版本:https://github.com/core ...