flink ETL数据处理
Flink ETL 实现数据清洗

一:需求(针对算法产生的日志数据进行清洗拆分)
1. 算法产生的日志数据是嵌套json格式,需要拆分
2.针对算法中的国家字段进行大区转换
3.最后把不同类型的日志数据分别进行储存
二:整体架构
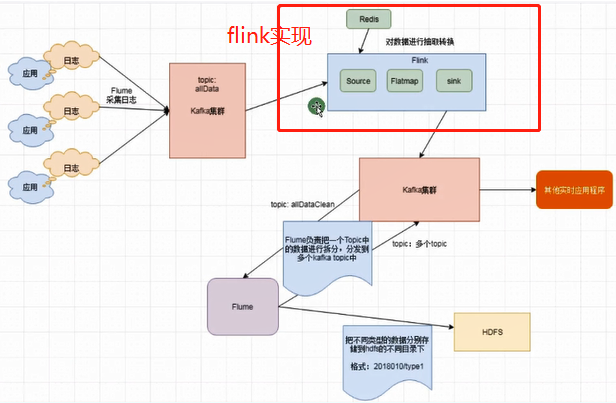
这里演示处理从rabbitmq来的数据 进行数据处理 然后发送到rabbitmq

自定义redistSource flink没有redis的source
package com.yw.source; import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.exceptions.JedisConnectionException; import java.util.HashMap;
import java.util.Map; /**
* redis中进行数据初始化
* <p>
* 在reids中保存国家和大区关系
* hset areas AREA_IN IN
* hset areas AREA_US US
* hset areas AREA_CT TW,HK
* hset areas AREA_AR PK,KW,SA
*
*
* @Auther: YW
* @Date: 2019/6/15 10:23
* @Description:
*/
public class MyRedisSource implements SourceFunction<HashMap<String, String>> {
private final Logger LOG = LoggerFactory.getLogger(MyRedisSource.class); private boolean isRuning = true;
private Jedis jedis = null;
private final long SLEEP = 60000;
private final long expire = 60; @Override
public void run(SourceContext<HashMap<String, String>> ctx) throws Exception {
this.jedis = new Jedis("localhost", 6397);
// 存储国家和地区关系
HashMap<String, String> map = new HashMap<>();
while (isRuning) {
try {
map.clear(); // 老数据清除
Map<String, String> areas = jedis.hgetAll("areas");
for (Map.Entry<String, String> entry : areas.entrySet()) {
String key = entry.getKey();
String value = entry.getValue();
String[] splits = value.split(",");
for (String split : splits) {
map.put(split, key);
}
}
if (map.size() > 0) {
// map >0 数据发送出去
ctx.collect(map);
}else {
LOG.warn("获取数据为空!");
}
// 歇6秒
Thread.sleep(SLEEP);
} catch (JedisConnectionException e) {
LOG.error("redis连接异常 重新连接",e.getCause());
// 如果连接异常 重新连接
jedis = new Jedis("localhost", 6397);
}catch (Exception e){
LOG.error("redis Source其他异常",e.getCause());
} }
} @Override
public void cancel() {
isRuning = false;
while (jedis != null) {
jedis.close();
}
}
}
DataClean数据处理
package com.yw; import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.rabbitmq.client.AMQP;
import com.yw.source.MyRedisSource;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoFlatMapFunction;
import org.apache.flink.streaming.connectors.rabbitmq.RMQSink;
import org.apache.flink.streaming.connectors.rabbitmq.RMQSinkPublishOptions;
import org.apache.flink.streaming.connectors.rabbitmq.RMQSource;
import org.apache.flink.streaming.connectors.rabbitmq.common.RMQConnectionConfig;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.util.Collector; import java.util.HashMap; /**
* @Auther: YW
* @Date: 2019/6/15 10:09
* @Description:
*/
public class DataClean {
// 队列名
public final static String QUEUE_NAME = "two.aa.in"; public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 一分钟 checkpoint
env.enableCheckpointing(60000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(30000); // enableCheckpointing最小间隔时间(一半)
env.getCheckpointConfig().setCheckpointTimeout(10000);// 超时时间
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); final RMQConnectionConfig rmqConf = new RMQConnectionConfig.Builder().setHost("127.0.0.1").setPort(5672).setVirtualHost("/").setUserName("guest").setPassword("guest").build();
// 获取mq数据
DataStream<String> data1 = env.addSource(new RMQSource<String>(rmqConf, QUEUE_NAME, false, new SimpleStringSchema())).setParallelism(1);
//{"dt":"2019-06-10","countryCode":"US","data":[{"type":"s1","score":0.3,"level":"A"},{"type":"s2","score":0.1,"level":"B"},{"type":"s3","score":0.2,"level":"C"}]}
DataStreamSource<HashMap<String, String>> mapData = env.addSource(new MyRedisSource());
// connect可以连接两个流
DataStream<String> streamOperator = data1.connect(mapData).flatMap(new CoFlatMapFunction<String, HashMap<String, String>, String>() {
// 保存 redis返回数据 国家和大区的映射关系
private HashMap<String, String> allMap = new HashMap<String, String>(); // flatMap1 处理rabbitmq的数据
@Override
public void flatMap1(String value, Collector<String> out) throws Exception {
JSONObject jsonObject = JSONObject.parseObject(value);
String countryCode = jsonObject.getString("countryCode");
String dt = jsonObject.getString("dt");
// 获取大区
String area = allMap.get(countryCode);
JSONArray jsonArray = jsonObject.getJSONArray("data");
for (int i = 0; i < jsonArray.size(); i++) {
JSONObject jsonObject1 = jsonArray.getJSONObject(i);
jsonObject1.put("area", area);
jsonObject1.put("dt", dt);
out.collect(jsonObject1.toJSONString());
}
} // 处理redis的返回的map类型的数据
@Override
public void flatMap2(HashMap<String, String> value, Collector<String> out) throws Exception {
this.allMap = value;
}
});
streamOperator.addSink(new RMQSink<String>(rmqConf, new SimpleStringSchema(), new RMQSinkPublishOptions<String>() {
@Override
public String computeRoutingKey(String s) {
return "CC";
} @Override
public AMQP.BasicProperties computeProperties(String s) {
return null;
} @Override
public String computeExchange(String s) {
return "test.flink.output";
}
}));
data1.print();
env.execute("etl");
}
}
rabbitmq 模拟数据
package com.yw; import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory; import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Random; /**
* @Auther: YW
* @Date: 2019/6/5 14:57
* @Description:
*/
public class RabbitMQProducerUtil {
public final static String QUEUE_NAME = "two.aa.in"; public static void main(String[] args) throws Exception {
//创建连接工厂
ConnectionFactory factory = new ConnectionFactory(); //设置RabbitMQ相关信息
factory.setHost("127.0.0.1");
factory.setUsername("guest");
factory.setPassword("guest");
factory.setVirtualHost("/");
factory.setPort(5672); //创建一个新的连接
Connection connection = factory.newConnection();
//创建一个通道
Channel channel = connection.createChannel();
// 声明一个队列
// channel.queueDeclare(QUEUE_NAME, false, false, false, null);
//发送消息到队列中
String message = "{\"dt\":\""+getCurrentTime()+"\",\"countryCode\":\""+getCountryCode()+"\"," +
"{\"type\":\""+getType()+"\",\"score\":"+getScore()+"\"level\":\""+getLevel()+"\"}," +
"{\"type\":\""+getType()+"\",\"score\":"+getScore()+"\"level\":\""+getLevel()+"\"}," +
"{\"type\":\""+getType()+"\",\"score\":"+getScore()+"\"level\":\""+getLevel()+"\"}]}"; //我们这里演示发送一千条数据
for (int i = 0; i < 20; i++) {
channel.basicPublish("", QUEUE_NAME, null, (message + i).getBytes("UTF-8"));
System.out.println("Producer Send +'" + message);
} //关闭通道和连接
channel.close();
connection.close();
} public static String getCurrentTime() {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
return sdf.format(new Date());
} public static String getCountryCode() {
String[] types={"US","TN","HK","PK","KW","SA","IN"};
Random random = new Random();
int i = random.nextInt(types.length);
return types[i];
} public static String getType() {
String[] types={"s1","s2","s3","s4","s5"};
Random random = new Random();
int i = random.nextInt(types.length);
return types[i];
} public static String getScore() {
String[] types={"0.1","0.2","0.3","0.4","0.5"};
Random random = new Random();
int i = random.nextInt(types.length);
return types[i];
}
public static String getLevel() {
String[] types={"A","B","C","D","E"};
Random random = new Random();
int i = random.nextInt(types.length);
return types[i];
}
}
redis 初始化数据
* hset areas AREA_IN IN
* hset areas AREA_US US
* hset areas AREA_CT TW,HK
* hset areas AREA_AR PK,KW,SA

------------最后运行DataClean------------

flink ETL数据处理的更多相关文章
- Spark与Flink大数据处理引擎对比分析!
大数据技术正飞速地发展着,催生出一代又一代快速便捷的大数据处理引擎,无论是Hadoop.Storm,还是后来的Spark.Flink.然而,毕竟没有哪一个框架可以完全支持所有的应用场景,也就说明不可能 ...
- 基于docker构建flink大数据处理平台
https://www.cnblogs.com/1ssqq1lxr/p/10417005.html 由于公司业务需求,需要搭建一套实时处理数据平台,基于多方面调研选择了Flink. 初始化Swarm环 ...
- 基于Broadcast 状态的Flink Etl Demo
接上文: [翻译]The Broadcast State Pattern(广播状态) 最近尝试了一下Flink 的 Broadcase 功能,在Etl,流表关联场景非常适用:一个流数据量大,一个流数据 ...
- Flink学习笔记-新一代Flink计算引擎
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink入门介绍
什么是Flink Apache Flink是一个分布式大数据处理引擎,可以对有限数据流和无限数据流进行有状态计算.可部署在各种集群环境,对各种大小的数据规模进行快速计算. Flink特性 支持高吞吐. ...
- 深度介绍Flink在字节跳动数据流的实践
本文是字节跳动数据平台开发套件团队在1月9日Flink Forward Asia 2021: Flink Forward 峰会上的演讲分享,将着重分享Flink在字节跳动数据流的实践. 字节跳动数据流 ...
- 带你玩转Flink流批一体分布式实时处理引擎
摘要:Apache Flink是为分布式.高性能的流处理应用程序打造的开源流处理框架. 本文分享自华为云社区<[云驻共创]手把手教你玩转Flink流批一体分布式实时处理引擎>,作者: 萌兔 ...
- Flink基础概念入门
Flink 概述 什么是 Flink Apache Apache Flink 是一个开源的流处理框架,应用于分布式.高性能.高可用的数据流应用程序.可以处理有限数据流和无限数据,即能够处理有边界和无边 ...
- ETL的经验总结
ETL的考虑 做数据仓库系统,ETL是关键的一环.说大了,ETL是数据整合解决方案,说小了,就是倒数据的工具.回忆一下工作这么些年来,处理数据迁移.转换的工作倒还真的不少.但是那些工作基 ...
随机推荐
- 使用for循环签到嵌套制作直角三角形
注意代码的运行顺序: for(i = 0 ; i<9 ; i++){ for(j = 0 ; j<i-1 ; j++){ document.write("*")//** ...
- pgloader 学习(一)支持的特性
pgloader 是一个不错的多种格式数据同步到pg 的工具,pgloader 使用postrgresql 的copy 协议进行高效的数据同步处理 特性 加载文件到内容pg 多种数据源格式的支持 cs ...
- 前端微信小程序资讯类仿今日头条微信小程序
需求描述及交互分析设计思路和相关知识点新闻频道滑动效果设计首页新闻内容设计首页新闻详情页设计我的界面列表式导航设计系统设置二级界面设计 设计思路(1)设计底部标签导航,准备好底部标签导航的图标和建立相 ...
- 初识 Python 作业及默写
1.简述变量量命名规范 2.name = input(“>>>”) name变量是什么数据类型? 3.if条件语句的基本结构? 4.用print打印出下面内容: 文能提笔安天下, 武 ...
- linux(deepin) 下隐藏firefox标题栏
1. 右上角菜单 -> 定制 -> 左下角 "标题栏" 取消打钩 2. 如果上面无法解决,在firefox的启动前插入一个环境变量,具体修改 /usr/share/ap ...
- 【洛谷】P1449 后缀表达式
P1449 后缀表达式 分析: 简单的模拟题. 熟练容器stack的话很容易解决. stack,栈,有先进后出的特性. 比如你有一个箱子,你每放进第一个数时,就往箱底放,放第二个数时就在第一个数的上面 ...
- 【软工实践】Beta冲刺(5/5)
链接部分 队名:女生都队 组长博客: 博客链接 作业博客:博客链接 小组内容 恩泽(组长) 过去两天完成了哪些任务 描述 将数据分析以可视化形式展示出来 新增数据分析展示等功能API 服务器后端部署, ...
- tomcat的CATALINA_HOME环境变量可以不用设置
不配置tomcat的环境变量也是可以运行的 用记事本打开tomcat/bin目录下面的startup.bat 在文本的前一部分有下面的脚本代码rem Guess CATALINA_HOME if no ...
- mariadb 10.2/mysql 8.0实现递归
借助mysql 8.0的cte(它是iso sql标准的一部分),可以实现递归,mariadb 10.2.2开始支持递归cte,如下: +----+----------+--------------+ ...
- Android中Activity的启动模式(LaunchMode)和使用场景
一.为什么需要启动模式在Android开发中,我们都知道,在默认的情况下,如果我们启动的是同一个Activity的话,系统会创建多个实例并把它们一一放入任务栈中.当我们点击返回(back)键,这些Ac ...