RabbitMQ学习记录1
前言
我是在解决分布式事务的一致性问题时了解到RabbitMQ的,当时主要是要基于RabbitMQ来实现我们分布式系统之间对有事务可靠性要求的系统间通信的。关于分布式事务一致性问题及其常见的解决方案,可以看我另一篇博客。提到RabbitMQ,不难想到的几个关键字:消息中间件、消息队列。而消息队列不由让我想到,当时在大学学习操作系统这门课,消息队列不难想到生产者消费者模式。(PS:操作系统这门课程真的很好也很重要,其中的一些思想在我工作的很长一段一时间内给了我很大帮助和启发,给我提供了许多解决问题的思路。强烈建议每一个程序员都去学一学操作系统!)
一 消息中间件
1.1 简介
消息中间件也可以称消息队列,是指用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息队列模型,可以在分布式环境下扩展进程的通信。当下主流的消息中间件有RabbitMQ、Kafka、ActiveMQ、RocketMQ等。其能在不同平台之间进行通信,常用来屏蔽各种平台协议之间的特性,实现应用程序之间的协同。其优点在于能够在客户端和服务器之间进行同步和异步的连接,并且在任何时刻都可以将消息进行传送和转发。是分布式系统中非常重要的组件,主要用来解决应用耦合、异步通信、流量削峰等问题。
2.2 作用
消息中间件几大主要作用如下:
- 解耦
- 冗余(存储)
- 扩展性
- 削峰
- 可恢复性
- 顺序保证
- 缓冲
- 异步通信
2.3 消息中间件的两种模式
2.3.1 P2P模式
P2P模式包含三个角色:消息队列(Queue),发送者(Sender),接收者(Receiver)。每个消息都被发送到一个特定的队列,接收者从队列中获取消息。队列保留着消息,直到他们被消费或超时。
P2P的特点:
- 每个消息只有一个消费者(Consumer)(即一旦被消费,消息就不再在消息队列中)
- 发送者和接收者之间在时间上没有依赖性,也就是说当发送者发送了消息之后,不管接收者有没有正在运行它不会影响到消息被发送到队列
- 接收者在成功接收消息之后需向队列应答成功
- 如果希望发送的每个消息都会被成功处理的话,那么需要P2P模式
2.3.2 Pub/Sub模式
Pub/Sub模式包含三个角色主题(Topic),发布者(Publisher),订阅者(Subscriber) 。多个发布者将消息发送到Topic,系统将这些消息传递给多个订阅者。
Pub/Sub的特点
- 每个消息可以有多个消费者
- 发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息。
- 为了消费消息,订阅者必须保持运行的状态。
- 如果希望发送的消息可以不被做任何处理、或者只被一个消息者处理、或者可以被多个消费者处理的话,那么可以采用Pub/Sub模型。
2.4 常用中间件介绍与对比
Kafka是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache定级项目。Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输。0.8版本开始支持复制,不支持事务,对消息的重复、丢失、错误没有严格要求,适合产生大量数据的互联网服务的数据收集业务。
RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。AMQP协议更多用在企业系统内,对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。
RocketMQ是阿里开源的消息中间件,它是纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。RocketMQ思路起源于Kafka,但并不是Kafka的一个Copy,它对消息的可靠传输及事务性做了优化,目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景。
RabbitMQ比Kafka可靠,kafka更适合IO高吞吐的处理,一般应用在大数据日志处理或对实时性(少量延迟),可靠性(少量丢数据)要求稍低的场景使用,比如ELK日志收集。
二 RabbitMQ了解
2.1 简介
RabbitMQ是流行的开源消息队列系统。RabbitMQ是AMQP(高级消息队列协议)的标准实现。支持多种客户端,如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP等,支持AJAX,持久化。用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。是使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正是如此,使的它变的非常重量级,更适合于企业级的开发。同时实现了一个Broker构架,这意味着消息在发送给客户端时先在中心队列排队。对路由(Routing),负载均衡(Load balance)或者数据持久化都有很好的支持。其主要特点如下:
- 可靠性
- 灵活的路由
- 扩展性
- 高可用性
- 多种协议
- 多语言客户端
- 管理界面
- 插件机制
2.2 概念
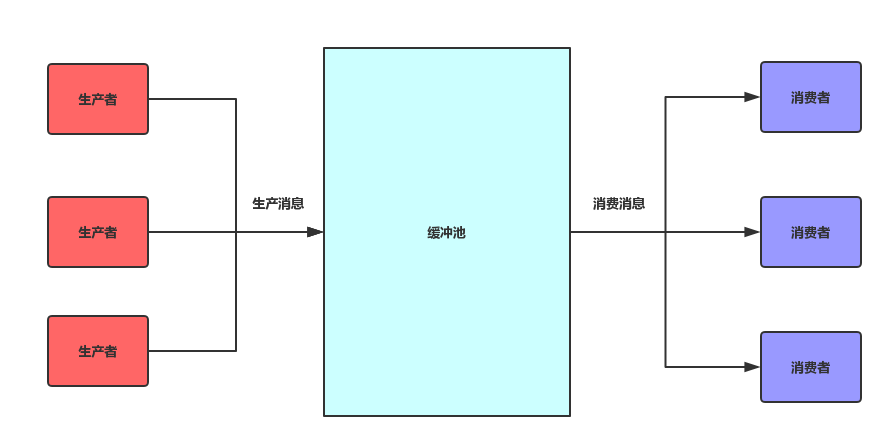
RabbitMQ从整体上来看是一个典型的生产者消费者模型,主要负责接收、存储和转发消息。其整体模型架构如下图所示:
我们先来看一个RabbitMQ的运转流程,稍后会对这个流程中所涉及到的一些概念进行详细的解释。
生产者:
(1)生产者连接到RabbitMQ Broker,建立一个连接( Connection)开启一个信道(Channel)
(2)生产者声明一个交换器,并设置相关属性,比如交换机类型、是否持久化等
(3)生产者声明一个队列井设置相关属性,比如是否排他、是否持久化、是否自动删除等
(4)生产者通过路由键将交换器和队列绑定起来
(5)生产者发送消息至RabbitMQ Broker,其中包含路由键、交换器等信息。
(6)相应的交换器根据接收到的路由键查找相匹配的队列。
(7)如果找到,则将从生产者发送过来的消息存入相应的队列中。
(8)如果没有找到,则根据生产者配置的属性选择丢弃还是回退给生产者
(9)关闭信道。
(10)关闭连接。'
消费者:
(1)消费者连接到RabbitMQ Broker ,建立一个连接(Connection),开启一个信道(Channel) 。
(2)消费者向RabbitMQ Broker 请求消费相应队列中的消息,可能会设置相应的回调函数,
(3)等待RabbitMQ Broker 回应并投递相应队列中的消息,消费者接收消息。
(4)消费者确认(ack) 接收到的消息。
(5)RabbitMQ 从队列中删除相应己经被确认的消息。
(6)关闭信道。
(7)关闭连接。
2.2.1 信道
这里我们主要讨论两个问题:
为何要有信道?
主要原因还是在于TCP连接的"昂贵"性。无论是生产者还是消费者,都需要和RabbitMQ Broker 建立连接,这个连接就是一条TCP 连接。而操作系统对于TCP连接的创建于销毁是非常昂贵的开销。假设消费者要消费消息,并根据服务需求合理调度线程,若只进行TCP连接,那么当高并发的时候,每秒可能都有成千上万的TCP连接,不仅仅是对TCP连接的浪费,也很快会超过操作系统每秒所能建立连接的数量。如果能在一条TCP连接上操作,又能保证各个线程之间的私密性就完美了,于是信道的概念出现了。
信道为何?
信道是建立在Connection 之上的虚拟连接。当应用程序与Rabbit Broker建立TCP连接的时候,客户端紧接着可以创建一个AMQP 信道(Channel) ,每个信道都会被指派一个唯一的D。RabbitMQ 处理的每条AMQP 指令都是通过信道完成的。信道就像电缆里的光纤束。一条电缆内含有许多光纤束,允许所有的连接通过多条光线束进行传输和接收。
2.2.2 生产者消费者
关于生产者消费者我们需要了解几个概念:
- Producer:生产者,即消息投递者一方。
- 消息:消息一般分两个部分:消息体(payload)和标签。标签用来描述这条消息,如:一个交换器的名称或者一个路由Key,Rabbit通过解析标签来确定消息的去向,payload是消息内容可以使一个json,数组等等。
- Consumer:消费者,就是接收消息的一方。消费者订阅RabbitMQ的队列,当消费者消费一条消息时,只是消费消息的消息体。在消息路由的过程中,会丢弃标签,存入到队列中的只有消息体。
- Broker:消息中间件的服务节点。
2.2.3 队列、交换器、路由key、绑定
从RabbitMQ的运转流程我们可以知道生产者的消息是发布到交换器上的。而消费者则是从队列上获取消息的。那么消息到底是如何从交换器到队列的呢?我们先具体了解一下这几个概念。
Queue:队列,是RabbitMQ的内部对象,用于存储消息。RabbitMQ中消息只能存储在队列中。生产者投递消息到队列,消费者从队列中获取消息并消费。多个消费者可以订阅同一个队列,这时队列中的消息会被平均分摊(轮询)给多个消费者进行消费,而不是每个消费者都收到所有的消息进行消费。(注意:RabbitMQ不支持队列层面的广播消费,如果需要广播消费,可以采用一个交换器通过路由Key绑定多个队列,由多个消费者来订阅这些队列的方式。)
Exchange:交换器。在RabbitMQ中,生产者并非直接将消息投递到队列中。真实情况是,生产者将消息发送到Exchange(交换器),由交换器将消息路由到一个或多个队列中。如果路由不到,或返回给生产者,或直接丢弃,或做其它处理。
RoutingKey:路由Key。生产者将消息发送给交换器的时候,一般会指定一个RoutingKey,用来指定这个消息的路由规则。这个路由Key需要与交换器类型和绑定键(BindingKey)联合使用才能最终生效。在交换器类型和绑定键固定的情况下,生产者可以在发送消息给交换器时通过指定RoutingKey来决定消息流向哪里。
Binding:RabbitMQ通过绑定将交换器和队列关联起来,在绑定的时候一般会指定一个绑定键,这样RabbitMQ就可以指定如何正确的路由到队列了。
从这里我们可以看到在RabbitMQ中交换器和队列实际上可以是一对多,也可以是多对多关系。交换器和队列就像我们关系数据库中的两张表。他们同归BindingKey做关联(多对多关系表)。在我们投递消息时,可以通过Exchange和RoutingKey(对应BindingKey)就可以找到相对应的队列。
RabbitMQ主要有四种类型的交换器:
fanout:扇形交换器,它会把发送到该交换器的消息路由到所有与该交换器绑定的队列中。如果使用扇形交换器,则不会匹配路由Key。

direct:direct交换器,会把消息路由到RoutingKey与BindingKey完全匹配的队列中。

topic:完全匹配BindingKey和RoutingKey的direct交换器 有些时候并不能满足实际业务的需求。topic 类型的交换器在匹配规则上进行了扩展,它与direct 类型的交换器相似,也是将消息路由到BindingKey 和RoutingKey 相匹配的队
列中,但这里的匹配规则有些不同,它约定:- RoutingKey 为一个点号"."分隔的字符串(被点号"."分隔开的每一段独立的字符
串称为一个单词)λ,如"hs.rabbitmq.client","com.rabbit.client"等。 - BindingKey 和RoutingKey 一样也是点号"."分隔的字符串;
- BindingKey 中可以存在两种特殊字符串"*"和"#",用于做模糊匹配,其中"*"用于匹配一个单词,"#"用于匹配多规格单词(可以是零个)。
- RoutingKey 为一个点号"."分隔的字符串(被点号"."分隔开的每一段独立的字符

如图:
· 路由键为" apple.rabbit.client" 的消息会同时路由到Queuel 和Queue2;
· 路由键为" orange.mq.client" 的消息只会路由到Queue2 中:
· 路由键为" apple.mq.demo" 的消息只会路由到Queue2 中:
· 路由键为" banana.rabbit.demo" 的消息只会路由到Queuel 中:
· 路由键为" apple.orange.banana" 的消息将会被丢弃或者返回给生产者因为它没有匹配任何路由键。
- header:headers 类型的交换器不依赖于路由键的匹配规则来路由消息,而是根据发送的消息内容中
的headers 属性进行匹配。在绑定队列和交换器时制定一组键值对, 当发送消息到交换器时,
RabbitMQ 会获取到该消息的headers (也是一个键值对的形式) ,对比其中的键值对是否完全
匹配队列和交换器绑定时指定的键值对,如果完全匹配则消息会路由到该队列,否则不会路由
到该队列。(注:该交换器类型性能较差且不实用,因此一般不会用到)。
了解了上面的概念,我们再来思考消息是如何从交换器到队列的。首先Rabbit在接收到消息时,会解析消息的标签从而得到消息的交换器与路由key信息。然后根据交换器的类型、路由key以及该交换器和队列的绑定关系来决定消息最终投递到哪个队列里面。
出 处:https://www.cnblogs.com/hunternet/p/9668851.html
RabbitMQ学习记录1的更多相关文章
- 【RabbitMQ学习记录】- 消息队列存储机制源码分析
本文来自 网易云社区 . RabbitMQ在金融系统,OpenStack内部组件通信和通信领域应用广泛,它部署简单,管理界面内容丰富使用十分方便.笔者最近在研究RabbitMQ部署运维和代码架构,本篇 ...
- 1.Rabbitmq学习记录《本质介绍,协议AMQP分析》
1.RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现. RabbitMQ的优势-: 除了Qpid,RabbitMQ是唯一一个实现了AMQP ...
- RabbitMQ 学习记录
rabbit mq知识点:1.消费时可以通过acknowledge设定消费是否成功,消费不成功时在server端requeue2.需要注意两个持久化:queue持久化和消息持久化(通过代码设定,默认即 ...
- RabbitMQ上手记录–part 2 - 安装RabbitMQ
上一篇<<RabbitMQ 上手记录-part 1>>介绍了一些基础知识,整理了一些基础概念.接下来整理一些安装步骤和遇到的问题. 我在CentOS7和Ubuntu16.4上都 ...
- RabbitMQ学习系列二-C#代码发送消息
RabbitMQ学习系列二:.net 环境下 C#代码使用 RabbitMQ 消息队列 http://www.80iter.com/blog/1437455520862503 上一篇已经讲了Rabbi ...
- Redis总结(五)缓存雪崩和缓存穿透等问题 Web API系列(三)统一异常处理 C#总结(一)AutoResetEvent的使用介绍(用AutoResetEvent实现同步) C#总结(二)事件Event 介绍总结 C#总结(三)DataGridView增加全选列 Web API系列(二)接口安全和参数校验 RabbitMQ学习系列(六): RabbitMQ 高可用集群
Redis总结(五)缓存雪崩和缓存穿透等问题 前面讲过一些redis 缓存的使用和数据持久化.感兴趣的朋友可以看看之前的文章,http://www.cnblogs.com/zhangweizhon ...
- 官网英文版学习——RabbitMQ学习笔记(一)认识RabbitMQ
鉴于目前中文的RabbitMQ教程很缺,本博主虽然买了一本rabbitMQ的书,遗憾的是该书的代码用的不是java语言,看起来也有些不爽,且网友们不同人学习所写不同,本博主看的有些地方不太理想,为此本 ...
- RabbitMQ学习系列(四): 几种Exchange 模式
上一篇,讲了RabbitMQ的具体用法,可以看看这篇文章:RabbitMQ学习系列(三): C# 如何使用 RabbitMQ.今天说些理论的东西,Exchange 的几种模式. AMQP协议中的核心思 ...
- RabbitMQ学习系列(三): C# 如何使用 RabbitMQ
上一篇已经讲了Rabbitmq如何在Windows平台安装,还不了解如何安装的朋友,请看我前面几篇文章:RabbitMQ学习系列一:windows下安装RabbitMQ服务 , 今天就来聊聊 C# 实 ...
随机推荐
- [RN] React Native 幻灯片效果 Banner
[RN] React Native 幻灯片效果 Banner 1.定义Banner import React, {Component} from 'react'; import {Image, Scr ...
- video.js学习笔记
video.js学习笔记获取用户观看时长
- 自助法(Bootstraping)
自助法(Bootstraping)是另一种模型验证(评估)的方法(之前已经介绍过单次验证和交叉验证:验证和交叉验证(Validation & Cross Validation)).其以自助采样 ...
- 作业——10 分布式文件系统HDFS 练习
作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3292 利用Shell命令与HDFS进行交互 以”./bin/dfs ...
- [Web 安全] WASC 和 OWASP两个web安全方面组织机构介绍
copy from : http://blog.sina.com.cn/s/blog_70b7aab9010126mn.html WASC 和 OWASP.这两个组织在呼吁企业加强应用安全意识和指导 ...
- IDEA2019.2中文字体变粗缺字等问题
idea的中文字体渲染问题 IDEA 2018.2升级到 IDEA 2019.2,中文字体渲染问题修改一下备用字体就可以共需要修改两处:1.Setting -> Editor -> Fon ...
- Nginx访问路径添加密码保护
创建口令文件 用openssl命令创建口令 openssl passwd -apr1 会产生一个hash口令, 然后和用户名一起, 以[用户名]:[hash口令]的格式写入文本文件即可 例如创建一个名 ...
- NPOI导出EXCEL样式
public void Export(DataRequest<ExportModel> request, DataResponse<dynamic> response) { t ...
- EasyNVR网页H5无插件播放摄像机视频功能二次开发之直播通道接口保活示例代码
背景需求 随着雪亮工程.明厨亮灶.手机看店.智慧幼儿园监控等行业开始将传统的安防摄像头进行互联网.微信直播,我们知道摄像头直播的春天了.将安防摄像头或NVR上的视频流转成互联网直播常用的RTMP.HT ...
- 查看rpm包spec文件
$ rpm --scripts -qp kernel-2.6.32-431.el6.x86_64.rpm