Zookeeper的典型应用场景(转)
在寒假前,完成了Zookeeper系列的前5篇文章,主要是分布式的相关理论,包括CAP,BASE理论,分布式数据一致性算法:2PC,3PC,Paxos算法,Zookeeper的相关基本特性,ZAB协议。今天,完成Zookeeper系列的最后一篇也是最为重要的内容:Zookeeper的典型应用场景的介绍,我们只有知道zk怎么用,用在哪,我们才能真正掌握Zookeeper这个优秀的分布式协调框架。
首先,我们要知道,Zookeeper是一个具有高可用、高性能和具有分布式数据一致性的分布式数据管理及协调框架,是基于对ZAB算法的实现,基于这样的特性,使ZK成为解决分布式一致性问题的利器,同时Zookeeper提供了丰富的节点类型和Watcher监听机制,通过这两个特点,可以非常方便的构建一系列分布式系统中都会涉及的核心功能: 如:数据发布/订阅,负载均衡,命名服务,分布式协调/通知,集群管理,Master选举,分布式锁,分布式队列等。这一篇,将针对这些分布式应用场景来做介绍,并介绍Zookeeper在现在的大型分布式系统中的作为核心组件的实际应用。
数据发布与订阅(配置中心)
数据发布/订阅系统,即配置中心。需要发布者将数据发布到Zookeeper的节点上,供订阅者进行数据订阅,进而达到动态获取数据的目的,实现配置信息的集中式管理和数据的动态更新(可以把我们知道RPC的注册中心看成是此场景的应用)。
发布/订阅一般有两种设计模式:推模式和拉模式,服务端主动将数据更新发送给所有订阅的客户端称为推模式;客户端主动请求获取最新数据称为拉模式,Zookeeper采用了推拉相结合的模式,客户端向服务端注册自己需要关注的节点,一旦该节点数据发生变更,那么服务端就会向相应的客户端推送Watcher事件通知,客户端接收到此通知后,主动到服务端获取最新的数据。
若将配置信息存放到Zookeeper上进行集中管理,在通常情况下,应用在启动时会主动到Zookeeper服务端上进行一次配置信息的获取,同时,在指定节点上注册一个Watcher监听,这样在配置信息发生变更,服务端都会实时通知所有订阅的客户端,从而达到实时获取最新配置的目的。
注意:对于像Dubbo这样的RPC框架来说,zk将作为其注册中心,客户端第一次通过向zk集群获得服务的地址,然后会存储在本地,下一次进行调用时就不会再次去zk集群中查询,而是直接使用本地存储的地址,只有当服务地址变更时,才会通知客户端再次获取。
在平时的开发中,经常会碰到这样的需求:系统中需要使用一些通用的配置信息,例如:机器列表信息,数据库的配置信息(比如:要实现数据库的切换的应用场景),运行时的开关配置等。这些全局配置信息通常有3个特性:数据量通常比较小;数据内容在运行时会发生动态变化;集群中各机器共享、配置一致。假设,我们的集群规模很大,且配置信息经常变更,所以通过存储本地配置文件或内存变量的形式实现都很困难,所以我们使用zk来做一个全局配置信息的管理。
负载均衡
负载均衡是一种相当常见的计算机网络技术,用来对多个计算机、网络连接、CPU、磁盘驱动或其他资源进行分配负载,以达到优化资源使用、最大化吞吐率、最小化响应时间和避免过载的目的。通常负载均衡可以分为硬件(F5)和软件(Nginx)负载均衡两类。Zookeeper也可以作为实现软负载均衡的一种方式。
分布式系统为了保证可用性,通常通过副本的方式来对数据和服务进行部署,而对于客户端吧来说,只需要在这样对等的服务提供方式中选择一个来执行相关的业务逻辑,怎么选,这就是负载均衡的应用。
比如,典型的需要负载均衡的DNS(Domain Name System)服务,我们可以用zookeeper实现动态的DNS方案,可以参考《从Paxos到Zookeeper》这本书对于用zk实现动态DNS的方案P167。
zk实现负载均衡就是通过watcher机制和临时节点判断哪些节点宕机来获得可用的节点实现的:
ZooKeeper会维护一个树形的数据结构,类似于Windows资源管理器目录,其中EPHEMERAL类型的节点会随着创建它的客户端断开而被删除,利用这个特性很容易实现软负载均衡。
基本原理是,每个应用的Server启动时创建一个EPHEMERAL节点,应用客户端通过读取节点列表获得可用服务器列表,并订阅节点事件,有Server宕机断开时触发事件,客户端监测到后把该Server从可用列表中删除。
消息中间件中发布者和订阅者的负载均衡,linkedin开源的KafkaMQ和阿里开源的MetaQ都是通过zookeeper来做到生产者、消费者的负载均衡。
命名服务
命名服务是分步实现系统中较为常见的一类场景,分布式系统中,被命名的实体通常可以是集群中的机器、提供的服务地址或远程对象等,通过命名服务,客户端可以根据指定名字来获取资源的实体、服务地址和提供者的信息,最常见的就是RPC 框架的服务地址列表的命名。Zookeeper也可帮助应用系统通过资源引用的方式来实现对资源的定位和使用,广义上的命名服务的资源定位都不是真正意义上的实体资源,在分布式环境中,上层应用仅仅需要一个全局唯一的名字。Zookeeper可以实现一套分布式全局唯一ID的分配机制。(用UUID的方式的问题在于生成的字符串过长,浪费存储空间且字符串无规律不利于开发调试)
通过调用Zookeeper节点创建的API接口就可以创建一个顺序节点,并且在API返回值中会返回这个节点的完整名字,利用此特性,可以生成全局ID,其步骤如下
1. 客户端根据任务类型,在指定类型的任务下通过调用接口创建一个顺序节点,如"job-"。
2. 创建完成后,会返回一个完整的节点名,如"job-00000001"。
3. 客户端拼接type类型和返回值后,就可以作为全局唯一ID了,如"type2-job-00000001"。
阿里巴巴集团开源的分布式服务框架Dubbo中使用ZooKeeper来作为其命名服务,维护全局的服务地址列表。在Dubbo实现中:
服务提供者在启动的时候,向ZK上的指定节点/dubbo/${serviceName}/providers目录下写入自己的URL地址,这个操作就完成了服务的发布。
服务消费者启动的时候,订阅/dubbo/${serviceName}/providers目录下的提供者URL地址,并向/dubbo/${serviceName}/consumers目录下写入自己的URL地址。
注意,所有向ZK上注册的地址都是临时节点,这样就能够保证服务提供者和消费者能够自动感应资源的变化。另外,Dubbo还有针对服务粒度的监控,方法是订阅/dubbo/${serviceName}目录下所有提供者和消费者的信息。
分布式协调/通知.
Zookeeper中特有的Watcher注册于异步通知机制,能够很好地实现分布式环境下不同机器,甚至不同系统之间的协调与通知,从而实现对数据变更的实时处理。通常的做法是不同的客户端都对Zookeeper上的同一个数据节点进行Watcher注册,监听数据节点的变化(包括节点本身和子节点),若数据节点发生变化,那么所有订阅的客户端都能够接收到相应的Watcher通知,并作出相应处理。
在绝大多数分布式系统中,系统机器间的通信无外乎心跳检测、工作进度汇报和系统调度。这三种类型的机器通信方式都可以使用zookeeper来实现:
① 心跳检测,不同机器间需要检测到彼此是否在正常运行,可以使用Zookeeper实现机器间的心跳检测,基于其临时节点特性(临时节点的生存周期是客户端会话,客户端若当即后,其临时节点自然不再存在),可以让不同机器都在Zookeeper的一个指定节点下创建临时子节点,不同的机器之间可以根据这个临时子节点来判断对应的客户端机器是否存活。通过Zookeeper可以大大减少系统耦合。
② 工作进度汇报,通常任务被分发到不同机器后,需要实时地将自己的任务执行进度汇报给分发系统,可以在Zookeeper上选择一个节点,每个任务客户端都在这个节点下面创建临时子节点,这样不仅可以判断机器是否存活,同时各个机器可以将自己的任务执行进度写到该临时节点中去,以便中心系统能够实时获取任务的执行进度。
③ 系统调度,Zookeeper能够实现如下系统调度模式:分布式系统由控制台和一些客户端系统两部分构成,控制台的职责就是需要将一些指令信息发送给所有的客户端,以控制他们进行相应的业务逻辑,后台管理人员在控制台上做一些操作,实际上就是修改Zookeeper上某些节点的数据,Zookeeper可以把数据变更以时间通知的形式发送给订阅客户端。
集群管理
Zookeeper的两大特性(节点特性和watcher机制):
· 客户端如果对Zookeeper的数据节点注册Watcher监听,那么当该数据及诶单内容或是其子节点列表发生变更时,Zookeeper服务器就会向订阅的客户端发送变更通知。
· 对在Zookeeper上创建的临时节点,一旦客户端与服务器之间的会话失效,那么临时节点也会被自动删除。
机器在线率有较高要求的场景,能够快速对集群中机器变化作出响应。这样的场景中,往往有一个监控系统,实时检测集群机器是否存活。过去的做法通常是:监控系统通过某种手段(比如ping)定时检测每个机器,或者每个机器自己定时向监控系统汇报“我还活着”。这种做法可行,但是存在两个比较明显的问题:
1. 集群中机器有变动的时候,牵连修改的东西比较多。
2. 有一定的延时。
利用ZooKeeper有两个特性,就可以实时另一种集群机器存活性监控系统。可以实现集群机器存活监控系统,若监控系统在/clusterServers节点上注册一个Watcher监听,那么但凡进行动态添加机器的操作,就会在/clusterServers节点下创建一个临时节点:/clusterServers/[Hostname],这样,监控系统就能够实时监测机器的变动情况。
下面通过分布式日志收集系统的典型应用来学习Zookeeper如何实现集群管理。
分布式日志收集系统的核心工作就是收集分布在不同机器上的系统日志,在典型的日志系统架构设计中,整个日志系统会把所有需要收集的日志机器分为多个组别,每个组别对应一个收集器,这个收集器其实就是一个后台机器,用于收集日志,对于大规模的分布式日志收集系统场景,通常需要解决两个问题:
· 变化的日志源机器
· 变化的收集器机器
无论是日志源机器还是收集器机器的变更,最终都可以归结为如何快速、合理、动态地为每个收集器分配对应的日志源机器。
① 注册收集器机器,在Zookeeper上创建一个节点作为收集器的根节点,例如/logs/collector的收集器节点,每个收集器机器启动时都会在收集器节点下创建自己的节点,如/logs/collector/[Hostname]
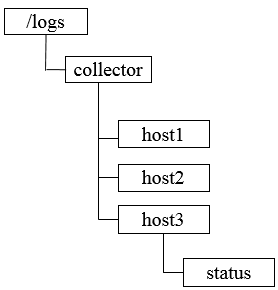
② 任务分发,所有收集器机器都创建完对应节点后,系统根据收集器节点下子节点的个数,将所有日志源机器分成对应的若干组,然后将分组后的机器列表分别写到这些收集器机器创建的子节点,如/logs/collector/host1(持久节点)上去。这样,收集器机器就能够根据自己对应的收集器节点上获取日志源机器列表,进而开始进行日志收集工作。
③ 状态汇报,完成任务分发后,机器随时会宕机,所以需要有一个收集器的状态汇报机制,每个收集器机器上创建完节点后,还需要再对应子节点上创建一个状态子节点,如/logs/collector/host/status(临时节点),每个收集器机器都需要定期向该结点写入自己的状态信息,这可看做是心跳检测机制,通常收集器机器都会写入日志收集状态信息,日志系统通过判断状态子节点最后的更新时间来确定收集器机器是否存活。
④ 动态分配,若收集器机器宕机,则需要动态进行收集任务的分配,收集系统运行过程中关注/logs/collector节点下所有子节点的变更,一旦有机器停止汇报或有新机器加入,就开始进行任务的重新分配,此时通常由两种做法:
· 全局动态分配,当收集器机器宕机或有新的机器加入,系统根据新的收集器机器列表,立即对所有的日志源机器重新进行一次分组,然后将其分配给剩下的收集器机器。
· 局部动态分配,每个收集器机器在汇报自己日志收集状态的同时,也会把自己的负载汇报上去,如果一个机器宕机了,那么日志系统就会把之前分配给这个机器的任务重新分配到那些负载较低的机器,同样,如果有新机器加入,会从那些负载高的机器上转移一部分任务给新机器。
Master选举
在分布式系统中,Master往往用来协调集群中其他系统单元,具有对分布式系统状态变更的决定权,如在读写分离的应用场景中,客户端的写请求往往是由Master来处理,或者其常常处理一些复杂的逻辑并将处理结果同步给其他系统单元。利用Zookeeper的一致性,能够很好地保证在分布式高并发情况下节点的创建一定能够保证全局唯一性,即Zookeeper将会保证客户端无法重复创建一个已经存在的数据节点(由其分布式数据的一致性保证)。
首先创建/master_election/2016-11-12节点,客户端集群每天会定时往该节点下创建临时节点,如/master_election/2016-11-12/binding,这个过程中,只有一个客户端能够成功创建,此时其变成master,其他节点都会在节点/master_election/2016-11-12上注册一个子节点变更的Watcher,用于监控当前的Master机器是否存活,一旦发现当前Master挂了,其余客户端将会重新进行Master选举。
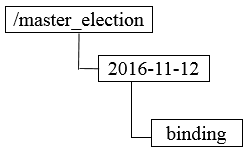
另外,这种场景演化一下,就是动态Master选举。这就要用到?EPHEMERAL_SEQUENTIAL类型节点的特性了。
上文中提到,所有客户端创建请求,最终只有一个能够创建成功。在这里稍微变化下,就是允许所有请求都能够创建成功,但是得有个创建顺序,于是所有的请求最终在ZK上创建结果的一种可能情况是这样:/currentMaster/{sessionId}-1 ,?/currentMaster/{sessionId}-2,?/currentMaster/{sessionId}-3 ….. 每次选取序列号最小的那个机器作为Master,如果这个机器挂了,由于他创建的节点会马上小时,那么之后最小的那个机器就是Master了。
其在实际中应用有:
· 在搜索系统中,如果集群中每个机器都生成一份全量索引,不仅耗时,而且不能保证彼此之间索引数据一致。因此让集群中的Master来进行全量索引的生成,然后同步到集群中其它机器。另外,Master选举的容灾措施是,可以随时进行手动指定master,就是说应用在zk在无法获取master信息时,可以通过比如http方式,向一个地方获取master。
在Hbase中,也是使用ZooKeeper来实现动态HMaster的选举。在Hbase实现中,会在ZK上存储一些ROOT表的地址和 HMaster的地址,HRegionServer也会把自己以临时节点(Ephemeral)的方式注册到Zookeeper中,使得HMaster可以随时感知到各个HRegionServer的存活状态,同时,一旦HMaster出现问题,会重新选举出一个HMaster来运行,从而避免了 HMaster的单点问题。
分布式锁
分布式锁用于控制分布式系统之间同步访问共享资源的一种方式,可以保证不同系统访问一个或一组资源时的一致性,主要分为排它锁和共享锁。排它锁又称为写锁或独占锁,若事务T1对数据对象O1加上了排它锁,那么在整个加锁期间,只允许事务T1对O1进行读取和更新操作,其他任何事务都不能再对这个数据对象进行任何类型的操作,直到T1释放了排它锁。
① 获取锁,在需要获取排它锁时,所有客户端通过调用接口,在/exclusive_lock节点下创建临时子节点/exclusive_lock/lock。Zookeeper可以保证只有一个客户端能够创建成功,没有成功的客户端需要注册/exclusive_lock节点监听。
② 释放锁,当获取锁的客户端宕机或者正常完成业务逻辑都会导致临时节点的删除,此时,所有在/exclusive_lock节点上注册监听的客户端都会收到通知,可以重新发起分布式锁获取。
共享锁又称为读锁,若事务T1对数据对象O1加上共享锁,那么当前事务只能对O1进行读取操作,其他事务也只能对这个数据对象加共享锁,直到该数据对象上的所有共享锁都被释放。(控制时序)
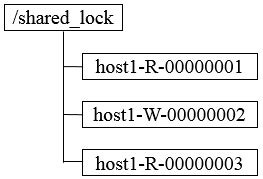
① 获取锁,在需要获取共享锁时,所有客户端都会到/shared_lock下面创建一个临时顺序节点,如果是读请求,那么就创建例如/shared_lock/host1-R-00000001的节点,如果是写请求,那么就创建例如/shared_lock/host2-W-00000002的节点。
② 判断读写顺序,不同事务可以同时对一个数据对象进行读写操作,而更新操作必须在当前没有任何事务进行读写情况下进行,通过Zookeeper来确定分布式读写顺序,大致分为四步。
1. 创建完节点后,获取/shared_lock节点下所有子节点,并对该节点变更注册监听。
2. 确定自己的节点序号在所有子节点中的顺序。
3. 对于读请求:若没有比自己序号小的子节点或所有比自己序号小的子节点都是读请求,那么表明自己已经成功获取到共享锁,同时开始执行读取逻辑,若有写请求,则需要等待。对于写请求:若自己不是序号最小的子节点,那么需要等待。
4. 接收到Watcher通知后,重复步骤1。
③ 释放锁,其释放锁的流程与独占锁一致。
上述共享锁的实现方案,可以满足一般分布式集群竞争锁的需求,但是如果机器规模扩大会出现一些问题,下面着重分析判断读写顺序的步骤3。
针对如上图所示的情况进行分析
1. host1首先进行读操作,完成后将节点/shared_lock/host1-R-00000001删除。
2. 余下4台机器均收到这个节点移除的通知,然后重新从/shared_lock节点上获取一份新的子节点列表。
3. 每台机器判断自己的读写顺序,其中host2检测到自己序号最小,于是进行写操作,余下的机器则继续等待。
4. 继续...
可以看到,host1客户端在移除自己的共享锁后,Zookeeper发送了子节点更变Watcher通知给所有机器,然而除了给host2产生影响外,对其他机器没有任何作用。大量的Watcher通知和子节点列表获取两个操作会重复运行,这样会造成系能鞥影响和网络开销,更为严重的是,如果同一时间有多个节点对应的客户端完成事务或事务中断引起节点小时,Zookeeper服务器就会在短时间内向其他所有客户端发送大量的事件通知,这就是所谓的羊群效应。
可以有如下改动来避免羊群效应。
1. 客户端调用create接口常见类似于/shared_lock/[Hostname]-请求类型-序号的临时顺序节点。
2. 客户端调用getChildren接口获取所有已经创建的子节点列表(不注册任何Watcher)。
3. 如果无法获取共享锁,就调用exist接口来对比自己小的节点注册Watcher。对于读请求:向比自己序号小的最后一个写请求节点注册Watcher监听。对于写请求:向比自己序号小的最后一个节点注册Watcher监听。
4. 等待Watcher通知,继续进入步骤2。
此方案改动主要在于:每个锁竞争者,只需要关注/shared_lock节点下序号比自己小的那个节点是否存在即可。
分布式队列
分布式队列可以简单分为先入先出队列模型和等待队列元素聚集后统一安排处理执行的Barrier模型。
① FIFO先入先出,先进入队列的请求操作先完成后,才会开始处理后面的请求。FIFO队列就类似于全写的共享模型,所有客户端都会到/queue_fifo这个节点下创建一个临时节点,如/queue_fifo/host1-00000001。

创建完节点后,按照如下步骤执行。
1. 通过调用getChildren接口来获取/queue_fifo节点的所有子节点,即获取队列中所有的元素。
2. 确定自己的节点序号在所有子节点中的顺序。
3. 如果自己的序号不是最小,那么需要等待,同时向比自己序号小的最后一个节点注册Watcher监听。
4. 接收到Watcher通知后,重复步骤1。
② Barrier分布式屏障,最终的合并计算需要基于很多并行计算的子结果来进行,开始时,/queue_barrier节点已经默认存在,并且将结点数据内容赋值为数字n来代表Barrier值,之后,所有客户端都会到/queue_barrier节点下创建一个临时节点,例如/queue_barrier/host1。
创建完节点后,按照如下步骤执行。
1. 通过调用getData接口获取/queue_barrier节点的数据内容,如10。
2. 通过调用getChildren接口获取/queue_barrier节点下的所有子节点,同时注册对子节点变更的Watcher监听。
3. 统计子节点的个数。
4. 如果子节点个数还不足10个,那么需要等待。
5. 接受到Wacher通知后,重复步骤3
上边我们介绍了Zookeeper的典型的应用场景。zookeeper已经被广泛应用于越来越多的大型分布式系统中了,其中包括:Dubbo的注册中心,HDFS的namenode和YARN框架的ResourceManager的HA(用zookeeper解决单点问题实现HA),HBase,Kafka等大数据和分布式系统框架中。我们可以学习这些内容时,注意一下Zookeeper的具体的应用实现。
————————————————
版权声明:本文为CSDN博主「冷面寒枪biu」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u013679744/article/details/79371022
Zookeeper的典型应用场景(转)的更多相关文章
- 从Paxos到ZooKeeper-三、ZooKeeper的典型应用场景
ZooKeeper是一个典型的发布/订阅模式的分布式数据管理与协调框架,开发人员可以使用它来进行分布式数据的发布与订阅.另一方面,通过对ZooKeeper中丰富的数据节点类型进行交叉使用,配合Watc ...
- ZooKeeper的典型应用场景
<从Paxos到Zookeeper 分布式一致性原理与实践>读书笔记 本文:总结脑图地址:脑图 前言 所有的典型应用场景,都是利用了ZK的如下特性: 强一致性:在高并发情况下,能够保证节点 ...
- Zookeeper 的典型应用场景 ?
Zookeeper 是一个典型的发布/订阅模式的分布式数据管理与协调框架,开发人员 可以使用它来进行分布式数据的发布和订阅. 通过对 Zookeeper 中丰富的数据节点进行交叉使用,配合 Watch ...
- Zookeeper 的典型应用场景 ?
Zookeeper 是一个典型的发布/订阅模式的分布式数据管理与协调框架,开发人员 可以使用它来进行分布式数据的发布和订阅. 通过对 Zookeeper 中丰富的数据节点进行交叉使用,配合 Watch ...
- Zookeeper 的典型应用场景?
Zookeeper 是一个典型的发布/订阅模式的分布式数据管理与协调框架,开发人员 可以使用它来进行分布式数据的发布和订阅. 通过对 Zookeeper 中丰富的数据节点进行交叉使用,配合 Watch ...
- ZooKeeper 典型应用场景-数据发布与订阅
ZooKeeper 是一个高可用的分布式数据管理与系统协调框架.基于对 Paxos 算法的实现,使该框架保证了分布式环境中数据的强一致性,也正是基于这样的特性,使得 ZooKeeper 可以解决很多分 ...
- ZooKeeper典型应用场景
ZooKeeper典型应用场景一览 数据发布与订阅(配置中心) 发布与订阅模型,即所谓的配置中心,顾名思义就是发布者将数据发布到ZK节点上,供订阅者动态获取数据,实现配置信息的集中式管理和动态更新.例 ...
- ZooKeeper典型应用场景一览
原文地址:http://jm-blog.aliapp.com/?p=1232 ZooKeeper典型应用场景一览 数据发布与订阅(配置中心) 发布与订阅模型,即所谓的配置中心,顾名思义就是发布者将数据 ...
- ZooKeeper典型应用场景(转)
ZooKeeper是一个高可用的分布式数据管理与系统协调框架.基于对Paxos算法的实现,使该框架保证了分布式环境中数据的强一致性,也正是基于这样的特性,使得ZooKeeper解决很多分布式问题.网上 ...
随机推荐
- 大数定律(Law of Large Numbers)
大数定律:每次从总体中随机抽取1个样本,这样抽取很多次后,样本的均值会趋近于总体的期望.也可以理解为:从总体中抽取容量为n的样本,样本容量n越大,样本的均值越趋近于总体的期望.当样本容量极大时,样本均 ...
- Shared Virtual Memory (SVM) Functions
Description Shared Virtual Memory (SVM) (Glossary): An address space exposed to both the host and th ...
- javaScript之DOM,BOM
javaScript之BOM / DOM: BOM(Browser Object Model)是指浏览器对象模型,它使 JavaScript 有能力与浏览器进行"对话". DOM ...
- ES6基础入门之let、const
作者 | Jeskson来源 | 达达前端小酒馆 01 首先呢?欢迎大家来学习ES6入门基础let,const的基础知识内容.初始ECMA Script6. ESMAScript与JavaScript ...
- https与http的区别?
https要比http更加安全一些,也就是说http协议是由ssl+http协议构建的可进行加密传输.身份验证的网络协议要比http协议安全 现在大多数的网站都逐渐用https://,因为安全问题太重 ...
- 冰多多团队-第七次scrum例会
冰多多团队-第七次Scrum会议 工作情况 团队成员 已完成任务 待完成任务 zpj 接入IAT模块 debug, IAT 牛雅哲 调研科大讯飞SDK中其他模块,寻找符合我们的需求的部分,将接口更换成 ...
- [技术博客]nginx 部署 apt 源
[技术博客] nginx 部署 apt 源 出于各种各样的原因, 有时需要自己配置apt源, 比如发布自己编写的debian软件包, 内网中只有一台电脑可以访问外网,或者在本地配置自己的apt源.我们 ...
- WPF,回车即是tab
正在做的WPF项目,客户需要在文本框里输入后按回车即跳到下一个框框,和tab一样的 上网搜索了下解决方案:如下: 在文本框外围 的grid加上KeyDown事件,代码里写上: /// <summ ...
- 今天使用Jmeter时遇到的几个问题及解决方法
JDBC Request :Cannot load JDBC driver class 'com.mysql.jdbc.Driver'解决办法 在Jmeter中run JDBC Request时,收到 ...
- notepad++去掉红色波浪线
1 在notepad++的首页上找到插件菜单,并点击打开插件设置的下拉菜单. 2 下拉菜单中有一个菜单项是DSpellCheck,这个菜单项的子项中有一项是Spell Check Document ...