linux内核数据结构之kfifo
1、前言
最近项目中用到一个环形缓冲区(ring buffer),代码是由linux内核的kfifo改过来的。缓冲区在文件系统中经常用到,通过缓冲区缓解cpu读写内存和读写磁盘的速度。例如一个进程A产生数据发给另外一个进程B,进程B需要对进程A传的数据进行处理并写入文件,如果B没有处理完,则A要延迟发送。为了保证进程A减少等待时间,可以在A和B之间采用一个缓冲区,A每次将数据存放在缓冲区中,B每次冲缓冲区中取。这是典型的生产者和消费者模型,缓冲区中数据满足FIFO特性,因此可以采用队列进行实现。Linux内核的kfifo正好是一个环形队列,可以用来当作环形缓冲区。生产者与消费者使用缓冲区如下图所示:
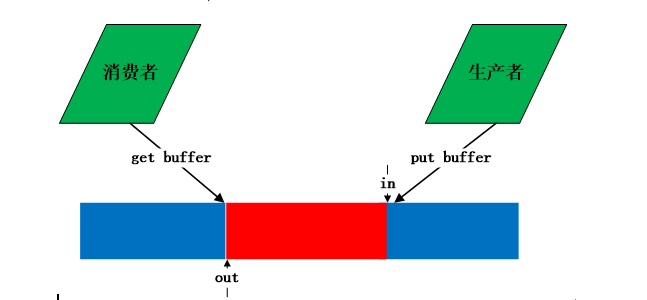
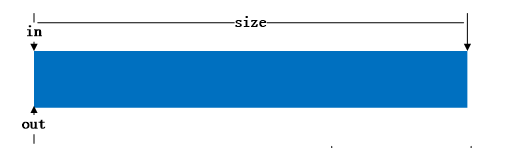
环形缓冲区的详细介绍及实现方法可以参考http://en.wikipedia.org/wiki/Circular_buffer,介绍的非常详细,列举了实现环形队列的几种方法。环形队列的不便之处在于如何判断队列是空还是满。维基百科上给三种实现方法。
2、linux 内核kfifo
kfifo设计的非常巧妙,代码很精简,对于入队和出对处理的出人意料。首先看一下kfifo的数据结构:
struct kfifo {
unsigned char *buffer; /* the buffer holding the data */
unsigned int size; /* the size of the allocated buffer */
unsigned int in; /* data is added at offset (in % size) */
unsigned int out; /* data is extracted from off. (out % size) */
spinlock_t *lock; /* protects concurrent modifications */
};
kfifo提供的方法有:
//根据给定buffer创建一个kfifo
struct kfifo *kfifo_init(unsigned char *buffer, unsigned int size,
gfp_t gfp_mask, spinlock_t *lock);
//给定size分配buffer和kfifo
struct kfifo *kfifo_alloc(unsigned int size, gfp_t gfp_mask,
spinlock_t *lock);
//释放kfifo空间
void kfifo_free(struct kfifo *fifo)
//向kfifo中添加数据
unsigned int kfifo_put(struct kfifo *fifo,
const unsigned char *buffer, unsigned int len)
//从kfifo中取数据
unsigned int kfifo_put(struct kfifo *fifo,
const unsigned char *buffer, unsigned int len)
//获取kfifo中有数据的buffer大小
unsigned int kfifo_len(struct kfifo *fifo)
定义自旋锁的目的为了防止多进程/线程并发使用kfifo。因为in和out在每次get和out时,发生改变。初始化和创建kfifo的源代码如下:
struct kfifo *kfifo_init(unsigned char *buffer, unsigned int size,
gfp_t gfp_mask, spinlock_t *lock)
{
struct kfifo *fifo;
/* size must be a power of 2 */
BUG_ON(!is_power_of_2(size));
fifo = kmalloc(sizeof(struct kfifo), gfp_mask);
if (!fifo)
return ERR_PTR(-ENOMEM);
fifo->buffer = buffer;
fifo->size = size;
fifo->in = fifo->out = ;
fifo->lock = lock; return fifo;
}
struct kfifo *kfifo_alloc(unsigned int size, gfp_t gfp_mask, spinlock_t *lock)
{
unsigned char *buffer;
struct kfifo *ret;
if (!is_power_of_2(size)) {
BUG_ON(size > 0x80000000);
size = roundup_pow_of_two(size);
}
buffer = kmalloc(size, gfp_mask);
if (!buffer)
return ERR_PTR(-ENOMEM);
ret = kfifo_init(buffer, size, gfp_mask, lock); if (IS_ERR(ret))
kfree(buffer);
return ret;
}
在kfifo_init和kfifo_calloc中,kfifo->size的值总是在调用者传进来的size参数的基础上向2的幂扩展,这是内核一贯的做法。这样的好处不言而喻--对kfifo->size取模运算可以转化为与运算,如:kfifo->in % kfifo->size 可以转化为 kfifo->in & (kfifo->size – 1)
kfifo的巧妙之处在于in和out定义为无符号类型,在put和get时,in和out都是增加,当达到最大值时,产生溢出,使得从0开始,进行循环使用。put和get代码如下所示:
static inline unsigned int kfifo_put(struct kfifo *fifo,
const unsigned char *buffer, unsigned int len)
{
unsigned long flags;
unsigned int ret;
spin_lock_irqsave(fifo->lock, flags);
ret = __kfifo_put(fifo, buffer, len);
spin_unlock_irqrestore(fifo->lock, flags);
return ret;
} static inline unsigned int kfifo_get(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned long flags;
unsigned int ret;
spin_lock_irqsave(fifo->lock, flags);
ret = __kfifo_get(fifo, buffer, len);
//当fifo->in == fifo->out时,buufer为空
if (fifo->in == fifo->out)
fifo->in = fifo->out = ;
spin_unlock_irqrestore(fifo->lock, flags);
return ret;
} unsigned int __kfifo_put(struct kfifo *fifo,
const unsigned char *buffer, unsigned int len)
{
unsigned int l;
//buffer中空的长度
len = min(len, fifo->size - fifo->in + fifo->out);
/*
* Ensure that we sample the fifo->out index -before- we
* start putting bytes into the kfifo.
*/
smp_mb();
/* first put the data starting from fifo->in to buffer end */
l = min(len, fifo->size - (fifo->in & (fifo->size - )));
memcpy(fifo->buffer + (fifo->in & (fifo->size - )), buffer, l);
/* then put the rest (if any) at the beginning of the buffer */
memcpy(fifo->buffer, buffer + l, len - l); /*
* Ensure that we add the bytes to the kfifo -before-
* we update the fifo->in index.
*/
smp_wmb();
fifo->in += len; //每次累加,到达最大值后溢出,自动转为0
return len;
} unsigned int __kfifo_get(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned int l;
//有数据的缓冲区的长度
len = min(len, fifo->in - fifo->out);
/*
* Ensure that we sample the fifo->in index -before- we
* start removing bytes from the kfifo.
*/
smp_rmb();
/* first get the data from fifo->out until the end of the buffer */
l = min(len, fifo->size - (fifo->out & (fifo->size - )));
memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - )), l);
/* then get the rest (if any) from the beginning of the buffer */
memcpy(buffer + l, fifo->buffer, len - l);
/*
* Ensure that we remove the bytes from the kfifo -before-
* we update the fifo->out index.
*/
smp_mb();
fifo->out += len; //每次累加,到达最大值后溢出,自动转为0
return len;
}
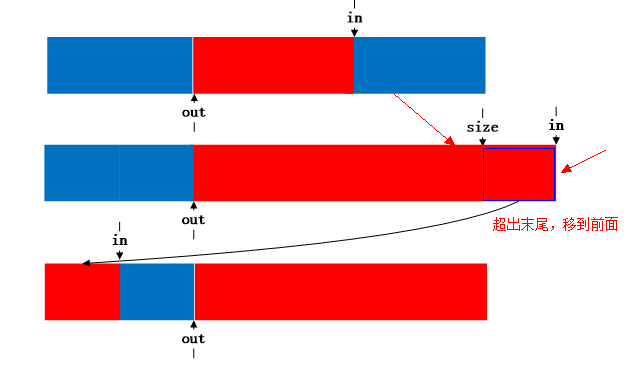
put和get在调用__put和__get过程都进行加锁,防止并发。从代码中可以看出put和get都调用两次memcpy,这针对的是边界条件。例如下图:蓝色表示空闲,红色表示占用。
(1)空的kfifo,
(2)put一个buffer后

(3)get一个buffer后

(4)当此时put的buffer长度超出in到末尾长度时,则将剩下的移到头部去
3、测试程序
仿照kfifo编写一个ring_buffer,现有线程互斥量进行并发控制。设计的ring_buffer如下所示:
/**@brief 仿照linux kfifo写的ring buffer
*@atuher Anker date:2013-12-18
* ring_buffer.h
* */ #ifndef KFIFO_HEADER_H
#define KFIFO_HEADER_H #include <inttypes.h>
#include <string.h>
#include <stdlib.h>
#include <stdio.h>
#include <errno.h>
#include <assert.h> //判断x是否是2的次方
#define is_power_of_2(x) ((x) != 0 && (((x) & ((x) - 1)) == 0))
//取a和b中最小值
#define min(a, b) (((a) < (b)) ? (a) : (b)) struct ring_buffer
{
void *buffer; //缓冲区
uint32_t size; //大小
uint32_t in; //入口位置
uint32_t out; //出口位置
pthread_mutex_t *f_lock; //互斥锁
};
//初始化缓冲区
struct ring_buffer* ring_buffer_init(void *buffer, uint32_t size, pthread_mutex_t *f_lock)
{
assert(buffer);
struct ring_buffer *ring_buf = NULL;
if (!is_power_of_2(size))
{
fprintf(stderr,"size must be power of 2.\n");
return ring_buf;
}
ring_buf = (struct ring_buffer *)malloc(sizeof(struct ring_buffer));
if (!ring_buf)
{
fprintf(stderr,"Failed to malloc memory,errno:%u,reason:%s",
errno, strerror(errno));
return ring_buf;
}
memset(ring_buf, , sizeof(struct ring_buffer));
ring_buf->buffer = buffer;
ring_buf->size = size;
ring_buf->in = ;
ring_buf->out = ;
ring_buf->f_lock = f_lock;
return ring_buf;
}
//释放缓冲区
void ring_buffer_free(struct ring_buffer *ring_buf)
{
if (ring_buf)
{
if (ring_buf->buffer)
{
free(ring_buf->buffer);
ring_buf->buffer = NULL;
}
free(ring_buf);
ring_buf = NULL;
}
} //缓冲区的长度
uint32_t __ring_buffer_len(const struct ring_buffer *ring_buf)
{
return (ring_buf->in - ring_buf->out);
} //从缓冲区中取数据
uint32_t __ring_buffer_get(struct ring_buffer *ring_buf, void * buffer, uint32_t size)
{
assert(ring_buf || buffer);
uint32_t len = ;
size = min(size, ring_buf->in - ring_buf->out);
/* first get the data from fifo->out until the end of the buffer */
len = min(size, ring_buf->size - (ring_buf->out & (ring_buf->size - )));
memcpy(buffer, ring_buf->buffer + (ring_buf->out & (ring_buf->size - )), len);
/* then get the rest (if any) from the beginning of the buffer */
memcpy(buffer + len, ring_buf->buffer, size - len);
ring_buf->out += size;
return size;
}
//向缓冲区中存放数据
uint32_t __ring_buffer_put(struct ring_buffer *ring_buf, void *buffer, uint32_t size)
{
assert(ring_buf || buffer);
uint32_t len = ;
size = min(size, ring_buf->size - ring_buf->in + ring_buf->out);
/* first put the data starting from fifo->in to buffer end */
len = min(size, ring_buf->size - (ring_buf->in & (ring_buf->size - )));
memcpy(ring_buf->buffer + (ring_buf->in & (ring_buf->size - )), buffer, len);
/* then put the rest (if any) at the beginning of the buffer */
memcpy(ring_buf->buffer, buffer + len, size - len);
ring_buf->in += size;
return size;
} uint32_t ring_buffer_len(const struct ring_buffer *ring_buf)
{
uint32_t len = ;
pthread_mutex_lock(ring_buf->f_lock);
len = __ring_buffer_len(ring_buf);
pthread_mutex_unlock(ring_buf->f_lock);
return len;
} uint32_t ring_buffer_get(struct ring_buffer *ring_buf, void *buffer, uint32_t size)
{
uint32_t ret;
pthread_mutex_lock(ring_buf->f_lock);
ret = __ring_buffer_get(ring_buf, buffer, size);
//buffer中没有数据
if (ring_buf->in == ring_buf->out)
ring_buf->in = ring_buf->out = ;
pthread_mutex_unlock(ring_buf->f_lock);
return ret;
} uint32_t ring_buffer_put(struct ring_buffer *ring_buf, void *buffer, uint32_t size)
{
uint32_t ret;
pthread_mutex_lock(ring_buf->f_lock);
ret = __ring_buffer_put(ring_buf, buffer, size);
pthread_mutex_unlock(ring_buf->f_lock);
return ret;
}
#endif
采用多线程模拟生产者和消费者编写测试程序,如下所示:
/**@brief ring buffer测试程序,创建两个线程,一个生产者,一个消费者。
* 生产者每隔1秒向buffer中投入数据,消费者每隔2秒去取数据。
*@atuher Anker date:2013-12-18
* */
#include "ring_buffer.h"
#include <pthread.h>
#include <time.h> #define BUFFER_SIZE 1024 * 1024 typedef struct student_info
{
uint64_t stu_id;
uint32_t age;
uint32_t score;
}student_info; void print_student_info(const student_info *stu_info)
{
assert(stu_info);
printf("id:%lu\t",stu_info->stu_id);
printf("age:%u\t",stu_info->age);
printf("score:%u\n",stu_info->score);
} student_info * get_student_info(time_t timer)
{
student_info *stu_info = (student_info *)malloc(sizeof(student_info));
if (!stu_info)
{
fprintf(stderr, "Failed to malloc memory.\n");
return NULL;
}
srand(timer);
stu_info->stu_id = + rand() % ;
stu_info->age = rand() % ;
stu_info->score = rand() % ;
print_student_info(stu_info);
return stu_info;
} void * consumer_proc(void *arg)
{
struct ring_buffer *ring_buf = (struct ring_buffer *)arg;
student_info stu_info;
while()
{
sleep();
printf("------------------------------------------\n");
printf("get a student info from ring buffer.\n");
ring_buffer_get(ring_buf, (void *)&stu_info, sizeof(student_info));
printf("ring buffer length: %u\n", ring_buffer_len(ring_buf));
print_student_info(&stu_info);
printf("------------------------------------------\n");
}
return (void *)ring_buf;
} void * producer_proc(void *arg)
{
time_t cur_time;
struct ring_buffer *ring_buf = (struct ring_buffer *)arg;
while()
{
time(&cur_time);
srand(cur_time);
int seed = rand() % ;
printf("******************************************\n");
student_info *stu_info = get_student_info(cur_time + seed);
printf("put a student info to ring buffer.\n");
ring_buffer_put(ring_buf, (void *)stu_info, sizeof(student_info));
printf("ring buffer length: %u\n", ring_buffer_len(ring_buf));
printf("******************************************\n");
sleep();
}
return (void *)ring_buf;
} int consumer_thread(void *arg)
{
int err;
pthread_t tid;
err = pthread_create(&tid, NULL, consumer_proc, arg);
if (err != )
{
fprintf(stderr, "Failed to create consumer thread.errno:%u, reason:%s\n",
errno, strerror(errno));
return -;
}
return tid;
}
int producer_thread(void *arg)
{
int err;
pthread_t tid;
err = pthread_create(&tid, NULL, producer_proc, arg);
if (err != )
{
fprintf(stderr, "Failed to create consumer thread.errno:%u, reason:%s\n",
errno, strerror(errno));
return -;
}
return tid;
} int main()
{
void * buffer = NULL;
uint32_t size = ;
struct ring_buffer *ring_buf = NULL;
pthread_t consume_pid, produce_pid; pthread_mutex_t *f_lock = (pthread_mutex_t *)malloc(sizeof(pthread_mutex_t));
if (pthread_mutex_init(f_lock, NULL) != )
{
fprintf(stderr, "Failed init mutex,errno:%u,reason:%s\n",
errno, strerror(errno));
return -;
}
buffer = (void *)malloc(BUFFER_SIZE);
if (!buffer)
{
fprintf(stderr, "Failed to malloc memory.\n");
return -;
}
size = BUFFER_SIZE;
ring_buf = ring_buffer_init(buffer, size, f_lock);
if (!ring_buf)
{
fprintf(stderr, "Failed to init ring buffer.\n");
return -;
}
#if 0
student_info *stu_info = get_student_info();
ring_buffer_put(ring_buf, (void *)stu_info, sizeof(student_info));
stu_info = get_student_info();
ring_buffer_put(ring_buf, (void *)stu_info, sizeof(student_info));
ring_buffer_get(ring_buf, (void *)stu_info, sizeof(student_info));
print_student_info(stu_info);
#endif
printf("multi thread test.......\n");
produce_pid = producer_thread((void*)ring_buf);
consume_pid = consumer_thread((void*)ring_buf);
pthread_join(produce_pid, NULL);
pthread_join(consume_pid, NULL);
ring_buffer_free(ring_buf);
free(f_lock);
return ;
}
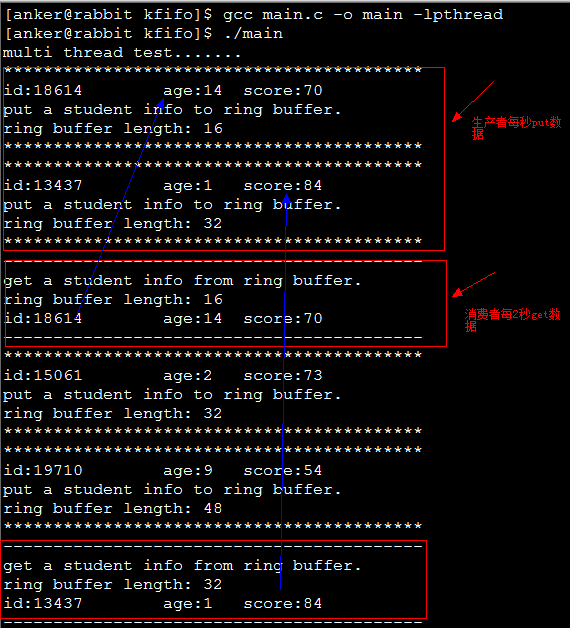
测试结果如下所示:
4、参考资料
http://blog.csdn.net/linyt/article/details/5764312
http://en.wikipedia.org/wiki/Circular_buffer
http://yiphon.diandian.com/post/2011-09-10/4918347
linux内核数据结构之kfifo的更多相关文章
- linux内核数据结构之kfifo【转】
1.前言 最近项目中用到一个环形缓冲区(ring buffer),代码是由linux内核的kfifo改过来的.缓冲区在文件系统中经常用到,通过缓冲区缓解cpu读写内存和读写磁盘的速度.例如一个进程A产 ...
- Linux内核数据结构之kfifo详解
本文分析的原代码版本: 2.6.24.4 kfifo的定义文件: kernel/kfifo.c kfifo的头文件: include/linux/kfifo.h kfifo是内核里面的一个First ...
- linux内核数据结构之链表
linux内核数据结构之链表 1.前言 最近写代码需用到链表结构,正好公共库有关于链表的.第一眼看时,觉得有点新鲜,和我之前见到的链表结构不一样,只有前驱和后继指针,而没有数据域.后来看代码注释发现该 ...
- Linux内核结构体--kfifo 环状缓冲区
转载链接:http://blog.csdn.net/yusiguyuan/article/details/41985907 1.前言 最近项目中用到一个环形缓冲区(ring buffer),代码是由L ...
- Linux 内核数据结构:Linux 双向链表
Linux 内核提供一套双向链表的实现,你可以在 include/linux/list.h 中找到.我们以双向链表着手开始介绍 Linux 内核中的数据结构 ,因为这个是在 Linux 内核中使用最为 ...
- Linux 内核数据结构:双向链表
Linux 内核提供一套双向链表的实现,你可以在 include/linux/list.h 中找到.我们以双向链表着手开始介绍 Linux 内核中的数据结构 ,因为这个是在 Linux 内核中使用最为 ...
- linux内核数据结构学习总结
目录 . 进程相关数据结构 ) struct task_struct ) struct cred ) struct pid_link ) struct pid ) struct signal_stru ...
- linux内核数据结构--进程相关
linux里面,有一个结构体task_struct,也叫“进程描述符”的数据结构,它包含了与进程相关的所有信息,它非常复杂,每一个字段都可能与一个功能相关,所以大部分细节不在我的研究范围之内,在这篇文 ...
- linux内核数据结构之链表【转】
转自:http://www.cnblogs.com/Anker/p/3475643.html 1.前言 最近写代码需用到链表结构,正好公共库有关于链表的.第一眼看时,觉得有点新鲜,和我之前见到的链表结 ...
随机推荐
- 在SQL2008查找某数据库中的列是否存在某个值
在SQL2008查找某数据库中的列是否存在某个值 --SQL2008查找某数据库中的列是否存在某个值 create proc spFind_Column_In_DB ( @type int,--类型: ...
- 使用 .NET WinForm 开发所见即所得的 IDE 开发环境,实现不写代码直接生成应用程序
直接切入正题,这是我09年到11年左右业余时间编写的项目,最初的想法很简单,做一个能拖拖拽拽就直接生成应用程序的工具,不用写代码,把能想到的业务操作全部封装起来,通过配置的方式把这些业务操作组织起来运 ...
- 基于netty http协议栈的轻量级流程控制组件的实现
今儿个是冬至,所谓“冬大过年”,公司也应景五点钟就放大伙儿回家吃饺子喝羊肉汤了,而我本着极高的职业素养依然坚持留在公司(实则因为没饺子吃没羊肉汤喝,只能呆公司吃食堂……).趁着这一个多小时的时间,想跟 ...
- 微软新神器-Power BI横空出世,一个简单易用,还用得起的BI产品,你还在等什么???
在当前互联网,由于大数据研究热潮,以及数据挖掘,机器学习等技术的改进,各种数据可视化图表层出不穷,如何让大数据生动呈现,也成了一个具有挑战性的可能,随之也出现了大量的商业化软件.今天就给大家介绍一款逆 ...
- Spring resource bundle多语言,单引号format异常
Spring resource bundle多语言,单引号format异常 前言 十一假期被通知出现大bug,然后发现是多语言翻译问题.法语中有很多单引号,单引号在format的时候出现无法匹配问题. ...
- C# 对象实例化 用json保存 泛型类 可以很方便的保存程序设置
用于永久化对象,什么程序都行,依赖NewtonSoft.用于json序列化和反序列化. using Newtonsoft.Json; using System; using System.Collec ...
- 通过自定义特性,使用EF6拦截器完成创建人、创建时间、更新人、更新时间的统一赋值(使用数据库服务器时间赋值,接上一篇)
目录: 前言 设计(完成扩展) 实现效果 扩展设计方案 扩展后代码结构 集思广益(问题) 前言: 在上一篇文章我写了如何重建IDbCommandTreeInterceptor来实现创建人.创建时间.更 ...
- .NET设计模式访问者模式
一.访问者模式的定义: 表示一个作用于某对象结构中的各元素的操作.它使你可以在不改变各元素类的前提下定义作用于这些元素的新操作. 二.访问者模式的结构和角色: 1.Visitor 抽象访问者角色,为该 ...
- CSS3 @keyframes 动画
CSS3的@keyframes,它可以取代许多网页动画图像,Flash动画,和JAVAScripts. CSS3的动画属性 下面的表格列出了 @keyframes 规则和所有动画属性: 浏览器支持 表 ...
- redis大幅性能提升之使用管道(PipeLine)和批量(Batch)操作
前段时间在做用户画像的时候,遇到了这样的一个问题,记录某一个商品的用户购买群,刚好这种需求就可以用到Redis中的Set,key作为productID,value 就是具体的customerid集合, ...